

前言
本例算是聚类算法的一个实际应用:色彩量化。什么是色彩量化呢?色彩量化是矢量量化(Vector Quantization,VQ)的一种特例,所以先说说VQ。
VQ是70年代后期发展起来的一种数据压缩技术基本思想:将若干个标量数据组构成一个矢量,然后在矢量空间给以整体量化,从而压缩了数据而不损失多少信息。更简单的来说,就是用某一个值去代替某一个区间的值,这样采样得到的N个数据就可以用P个数据(P<<N)来保存,传输等。
如下图所示,在(|x|<4,|y|<4)的区间内进行点采样,可以得到无数个结果,如果根据一定的先验知识,首先建立多个离散点(第一步),离散点需要具有较低的相关度,足以代表整个取值空间。再建立码本(第二步),码本表示任意采样点对应哪个离散点。就可以将数据复杂度大大降低。
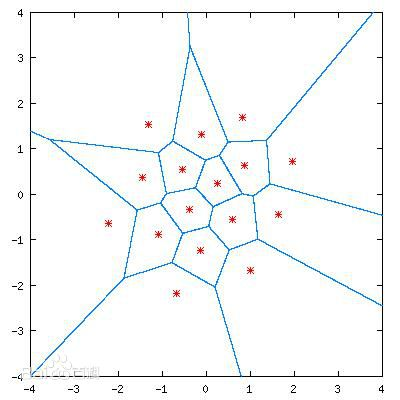
第一步常使用数据聚类算法,生成多个聚类中心;第二步常使用距离公式来确定采样点属于哪个离散点。
再回到色彩量化,彩色图像有RGB三个通道,每个通道取值通常为0~255,这样的话,一个像素点的颜色取值有2^24种,即使两个像素点只是在单个通道有一个亮度值差异(例如R197G255B25和R198G255B25),也需要保存两个色彩值,实际来说这两种色彩对我们来说基本没有区别,但是却需要花费多余的存储空间。色彩量化就是找到一些具有代表性的颜色(16,32,64种)来表示全图像,量化前每个像素需要3bit存储,量化后只需要存储其色彩标号(1bit),因此使得需要的存储空间大大减小。
代码
本例使用了一幅颐和园的彩色照片,原图具有96615种颜色,使用K-means找到n(n=64,32,16)个聚类中心作为n种颜色,再根据所有点与聚类中心的距离大小确定其属于哪一个聚类中心。
下面看看代码吧:(注:源代码中还有random选择中心,不包含数据聚类算法,我觉得意义不大,就去掉了)
print(__doc__)
import cv2
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.utils import shuffle
from time import time
n_colors = 64
# Load the Summer Palace photo
china = cv2.imread("D:\\Data\\china.jpg")
# Convert to floats instead of the default 8 bits integer coding. Dividing by
# 255 is important so that plt.imshow behaves works well on float data (need to
# be in the range [0-1])
china = np.array(china, dtype=np.float64) / 255
# Load Image and transform to a 2D numpy array.
w, h, d = original_shape = tuple(china.shape)
assert d == 3 #一定要是彩色图像,不是3会报错
image_array = np.reshape(china, (w * h, d)) #每个点作为一个样本,维数为3
print("Fitting model on a small sub-sample of the data")
t0 = time()
image_array_sample = shuffle(image_array, random_state=0)[:1000]
#将所有点打乱顺序,取前1000个点
#不使用所有点主要是为了训练模型的速度
kmeans = KMeans(n_clusters=n_colors, random_state=0).fit(image_array_sample)
print("done in %0.3fs." % (time() - t0))
# Get labels for all points
print("Predicting color indices on the full image (k-means)")
t0 = time()
labels = kmeans.predict(image_array)
print("done in %0.3fs." % (time() - t0))
def recreate_image(codebook, labels, w, h):
"""Recreate the (compressed) image from the code book & labels"""
#每个像素查询码本(对应0~63),取得其对应的像素值
d = codebook.shape[1]
image = np.zeros((w, h, d))
label_idx = 0
for i in range(w):
for j in range(h):
image[i][j] = codebook[labels[label_idx]]
label_idx += 1
return image
# Display all results, alongside original image
cv2.namedWindow('Original image (96,615 colors)')
cv2.imshow('Original image (96,615 colors)',china)
name = 'Quantized image ('+str(n_colors)+' colors, K-Means)'
cv2.namedWindow(name)
cv2.imshow(name,recreate_image(kmeans.cluster_centers_, labels, w, h))
cv2.waitKey(0)下面看看原图和n=64,32,16的结果:




可以看出,n=64时与原图并无太大差别,只是颜色鲜艳度差了些,出现了少量的块状现象,n=32,16图像质量都会再差一些。因为n=64,32,16时图像对应的存储空间大小是相同的,因此n还是大一些比较好,只是训练模型时会慢一些。
如果这篇文章对你有帮助,可以点个赞或者关注我,我会更有动力分享学习过程,谢啦~
