

2018-08-21 (gitbook 弄来进不去了,把文章挪到这里更新)。
前言
skr~~
内存空间
内存空间一个常常被前端工程师忽视的知识点。
如果想要成为一个优秀的前端儿,必须对内存空间有了解。
这个章节将会整理内存空间的部分知识点,抛砖引玉,更多的内容需要你去了解底层的知识。
一些误区
有一些常见的误区:
- 前端工程师不需要了解内存空间的知识,因为我们有 GC。
- GC 能够确保所有的 "垃圾" 都被准确的回收。
- 分不清堆栈,堆栈就代表内存空间了。
- 所有的基本类型都是存在栈中的,引用类型就是存在堆中的。
- .....
为了干掉这些误区,我们需要一步一步的学习相关的知识点。
一个问题
比如这样一个问题:
const Foo = (x, y) => {
this.x = x;
this.y = y;
}
const foo = new Foo(1, 2); // 1
const bar = Foo(1, 2); // 2
这里面的 new 的作用是什么? 第 2 个表达式与之区别?
MDN 上有答案:
new constructor([args])
new 操作符的作用是创建一个用户定义的对象类型的实例或具有构造函数的内置对象的实例
所以你可能会这样回答:
new 的作用:
- 一个继承自
Foo.prototype的新对象被创建 this绑定到新创建的对象fooconstructor构建的对象就是new操作返回的结果,或者是 第 1 步的对象。
二者的异同也就很明显了,第二个表达式只是单纯的执行了函数 Foo,并且不好的是在全局对象上绑定了 x, y 属性。
这样的结果其实忽视掉了 new 操作最重要的一个作用,就是在堆中去申请一个空间存储这个对象的实体本身。
为了理解这个,我们先认识堆栈 ( 通常所说的堆栈 = 栈,本书分开来说,避免混淆 )。
数据结构中的堆栈
堆和栈既是计算机科学中的一种数据结构。同时内存分配中也有堆、栈的说法,不要混淆了。
我们的重点是了解内存分配中的堆栈,同时简单了解一下数据结构中的堆、栈。
数据结构中的堆、栈:
- 栈是一种串列形式的特殊数据类型,特点是 LIFO(后进先出),在 JS 中可以使用数组实现一个栈结构,基本的操作有压入(push)、弹出(pop),分别对应栈顶部指针 +1、-1。
- 堆,其实就是二叉堆,是二叉树的一种。可以想象成一颗倒过来的树,根节点要么是最小的(最小堆),要么是最大的(最大堆)。并且从根节点往下只能依次增大或者减小(堆序性)。堆结构有一个经典的案例就是堆排序。
堆排序
JavaScript 实现堆排序:
const heapSort = target => {
const arr = target.slice(0);
// 交换的方法
const swap = (i, j) => {
let temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
// 确保父节点永远大于子节点
const max_heap = (start, end) => {
let dad = start;
// 左边子节点
let son = dad * 2 + 1;
if(son >= end){
return;
}
// 两个子节点中选择大的
if(son+1<end && arr[son]<arr[son+1]){
son++;
}
// 如果大于父节点,交换
if(arr[dad] <= arr[son]){
swap(dad, son);
max_heap(son, end);
}
}
let len = arr.length;
// 最后一个父节点 Math.floor(len/2)-1
for(let i = Math.floor(len/2)-1; i >= 0; i--){
max_heap(i, len);
}
for(let i = len-1; i > 0; i--){
swap(0, i);
max_heap(0, i);
}
return arr;
}
heapSort([3,5,3,0,8,0,1,5,1,6,5,4,0,8]);
//[0, 0, 0, 1, 1, 3, 3, 4, 5, 5, 5, 6, 8, 8]
内存中的堆栈
我们以 C 为例来说明,对二者进行比较分析。
首先我们得大致了解一下内存分配,通俗的说就是程序在运行的时候是拷贝在 RAM 执行,它会为之分配出一些区域比如栈区、堆区、静态区等。
内存分配策略
静态区内存分配:编译器自动完成,时机是在编译或者连接的过程中,整个运行期都会存在,比如全局变量就是存在于数据段,所以少用全局变量可以提升启动速度。
动态内存分配:也叫做堆分配,就是在运行的时候由程序员自己进行空间的申请。通俗的说就是事先也不知道要多大的内存,只有运行的时候才能确定,自己去 malloc。
栈分配:效率高,大小有限,可能溢出,比如函数执行时为其形参、局部变量分配栈空间。
堆区、栈区比较
栈区是由系统自动进行分配空间的,而堆区的空间是由程序员自己通过 new、malloc 等申请的。
栈上的空间是自动分配自动回收的,所以栈上的数据的生存周期只是在函数的运行过程中,运行后就释放掉,不可以再访问。而堆上的需要程序员手动去 free 或者 delete,不然就可能导致内存泄漏。
栈空间的申请效率更高,由系统自动分配,而堆空间的申请效率较之要低效一点,因为要在空闲空间地址的链表上挨个找,找到空间大小满足的之后再从链表中移除该地址,分配给该程序,这一过程就决定了其效率肯定比不上前者了。
栈空间是高地址向低地址拓展的数据结果,是连续的内存,大小是系统定好了的,受限,有溢出的风险。堆空间是向高地址的数据结构,是不连续的,具有更灵活、自由、更大的空间(受限于 计算机系统中有效的虚拟内存)。
到这里为止基本可以解决前边说的 4 个误区,针对第 4 个误区,特地提一下,因为很多文章都直接武断的说 JS 中的基本数据类型(string, number, bool, null, undefined, symbol)是分配了栈空间的。
学习堆栈的目的是为了利用其结构特性来增强我们的代码表现,栈空间只需要简单的进行指针的上下移动就可以快速的实现内存的开辟和释放,对于局部变量这种需要快速存储和释放的数据,栈空间存储当然是最好的方式。
但是,JS 的 Closure 是一个神奇的东西,在 Closure 中的局部变量(哪怕是基本类型),因为闭包需要一直持有对其的访问,所以函数调用结束它也不应该被释放,证明它是存在于堆中的。
GC
JS 可以直接访问保存在栈中的值,而对象的堆空间却不能直接访问,只能操作其对应的保存在栈中的引用(指针、地址)。当让该引用 = null 的时候,就可能会在下一次 GC 的时候释放该空间。
上面之所以说可能会在下一次回收,就是因为确定一块内存不再使用了是很复杂的。如果没有使用了,但是也没有释放该空间,就造成了内存泄漏。
GC算法
早期的浏览器(其实我想吐槽 IE )采用的是一种叫做引用计数的算法,原理就是如果一块内存没有指针指向它,那么它就可以被回收了。但是,诸如循环引用这种情况,它就无能为力了。
function Foo(){
let a = {};
let b = {};
a.name = b;
b.name = a;
return 'cycle reference!'
}
Foo();
Foo 函数执行完毕了,a,b 其实都不需要了,但是因为循环引用的存在,引用计数算法就会认为它们不应该回收,造成了内存的泄露。
现代浏览器基本都使用了各种版本的标记清除算法
这个算法假定设置一个叫做根(root)的对象(在 JavaScript 里,根是全局对象)。定期的,垃圾回收器将从根开始,找所有从根开始引用的对象,然后找这些对象引用的对象……从根开始,垃圾回收器将找到所有可以获得的对象和所有不能获得的对象。
意思很简单,就是从根出发,不能访问到的对象给个标记,等会儿就可以释放它了。这种算法可以解决上面的循环引用的问题。
GC 在执行的时候会阻塞其他的进程,至少在 50 ms 以上(这个数据可能是瞎掰的),这在普通的web项目上还好,在游戏中或者是动画连贯要求高的项目就不能忍了 。
针对上面的问题主要有 2 种优化的方式:
- 分代 GC : 就是 Java 中的那一套,分成
young区和tenured区,多去回收前者区域的,减少每次需要遍历的数量,从而减少耗时。 - 增量 GC : 类比增量更新技术,就是一次整一点,下一次接着整。
对于浏览器环境,比如 Chrome 中,V8 中的所有的 JavaScript 对象都是通过堆来进行分配的。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,直到堆的大小超过 V8的限制为止。
它限制了堆内存在1.4G(64位),它为什么要做这个限制的原因也是因为 GC 在更大的堆内存下需要更多的耗时,而这样的阻塞是不能容忍的。
内存泄露
前边其实已经说明了什么是内存泄漏,很多前端开发者并不会去注意这个问题,但是在大型复杂项目场景下,内存泄漏是不得不重视的一个性能优化点。
首先你得学会怎么用工具去监测是否内存泄漏,请猛戳这里。
内存泄漏的可能形式多种多样,核心都在于让 GC 认为它还在使用,而实际你没用了。
内存泄漏都是堆区,栈区不会发生内存泄漏的。
这里我列举一些网上说的各种形式和解决方式,更多的案例请联系我,我好做补充。
滥用全局变量
function Foo(){
bar = 'hello world!'
}
上面会意外的在全局绑定一个 bar 属性,是不会被 GC 释放的,解决办法是 'use strict'
console
在代码中使用 console.log、console.dir 等进行调试,记录错误的对象可以将大量数据保留在内存中。
DOM( IE )
IE 对 DOM 元素使用的是引用计数的清除算法,此类场景下泄露的情况很多。
function Foo(){
let a = document.createElement('div');
let b = document.createElement('div');
a.onclick = function(){
alert( b.outerHTML );
}
return a;
}
DOM 元素 a 中引用了一个匿名函数,该函数引用了 Foo 的作用域,持有对 a,b 的访问权限,这就是循环引用,造成内存泄漏。
解决办法:
function Foo(){
let a = document.createElement('div');
let b = document.createElement('div');
a.onclick = Bar(b);
return a;
}
function Bar(b){
alert(b.outerHTML);
}
闭包
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
// 这是一个闭包,里面引用了 originalThing
// originalThing 会被挂载到当前作用域下所有闭包的作用域中
// 这里去除对 originalThing 的引用也可以避免内存泄漏
var unused = function () {
if(originalThing) {}
};
theThing = {
longStr: Date.now() + Array(1000000).join('*'),
// 这个闭包中也挂载了 originalThing
// 所以造成了循环的引用
someMethod: function () {}
};
// originalThing = null 加这一句就不会泄露了
};
setInterval(replaceThing, 100);
除了以上的场景还有很多,主需要抓住内存泄露的本质,具体问题具体分析,具体解决。当然,IE 是大坑。
另外,ES6 中的 WeakSet、WeakMap 也可以避免内存泄露,你造吗?
异常处理与堆栈追踪
首先,函数调用栈是 LIFO 的,所以我们可以判断出下面代码的调用栈:
function a(){
console.log('a');
}
function b(){
console.log('b');
a();
}
function c(){
console.log('c');
b();
}
c(); // 调用栈(从栈顶开始依次是) a -> b -> c
a 函数执行完成之后从堆栈弹出,控制流交给 b,依此类推。
我们可以使用 console.trace() 打印出堆栈记录。
function a(){
console.log('a');
console.trace();
}
function b(){
console.log('b');
a();
// console.trace(); 可以再放这里试试
}
function c(){
console.log('c');
b();
}
c();
// 打印出
//console.trace
//a @ VM2979:3
//b @ VM2979:7
//c @ VM2979:11
//(anonymous) @ VM2979:13
了解了函数调用栈以及堆栈追踪,我们再看看异常处理。
首先我们得熟悉自 ES3 时代就有的 try/catch/finally,用法和 Java 中的如出一辙,就不再赘述。
它可以嵌套,嵌套的子 try/catch 会自己捕获内部的异常,不会给外层捕获的机会,如果包裹的是一个异步的代码,熟悉事件循环机制的应该知道,当前执行栈不能捕获到marcotasks队列中的抛出异常。
// 嵌套
try{
try{
throw new Error('some error');
}catch(e){
console.log('will print!');
}
}catch(e){
console.log('never print!')
}
// 异步
try{
setTimeout(()=>{
throw new Error('some error');
}, 0)
}catch(e){
console.log('never print!');
}
解决异步代码中异常捕获的办法有很多,你可以使用 error-first 风格:
function handleAsyncError(cb){
setTimeout(() => {
try{
if(someError){
throw new Error('some error!');
}else{
cb(null, result);
}
}catch(e){
cb(e)
}
}, 0)
}
这里的 Error 对象包含 message、stack、name 等属性,其中 stack 属性中包含了错误的堆栈轨迹。而一个错误实例的堆栈轨迹包含了自构造函数之后的所有堆栈结构。
如何操作堆栈追踪呢? Node 环境提供了 Error.captureStackTrace。
该函数有两个参数,第一个参数是一个对象,用来保存堆栈记录到其 stack 属性。第二个参数表示调用堆栈的终点,也就是只会保存其之前的堆栈记录,这样可以过滤掉对用户没用的信息。
const ErrorStack = {};
function a(){
console.log('a');
Error.captureStackTrace(ErrorStack);
// Error.captureStackTrace(ErrorStack, b); 这样再试试
}
function b(){
console.log('b');
a();
}
function c(){
console.log('c');
b();
}
c();
ErrorStack.stack;
// 打印出
//"Error
// at a (<anonymous>:4:11)
// at b (<anonymous>:8:5)
// at c (<anonymous>:12:5)
// at <anonymous>:14:1"
你可能会问这玩意儿有什么鸟用,这么说吧,比如牛逼哄哄的测试框架 Chai 就是使用了上面的堆栈操作技术使堆栈跟踪更加与他们的用户相关。
编译基础
之前看过一个文章,主要阐述了为什么说懂编译原理是可以为所欲为的。
比如说他举了个例子,如何实现绕过微信小程序的审核实现热更新,这就需要懂编译原理的知识,然后让你的代码重新拥有 eval 的能力。
最后,还是那句话,前端儿真的需要懂一点点编译原理。
JavaScript 是一门解释型的语言,因此编译器的相关基础知识,我们将以 C 语言、GCC 为例。
当然,JavaScript 解释器、WebAssembly 的知识是我们需要重点关注的。
编译原理真的挺难的,所以这一部分的知识点如果有不对的地方请及时指正。
编译过程基础
我们看看 C 的编译过程,我整理了一个流程图如下:
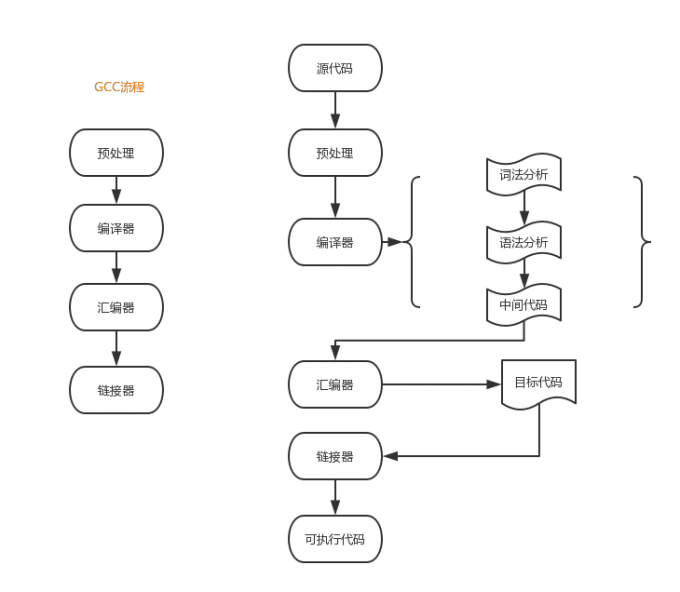
预处理:
预处理器是程序中处理输入数据,产生能用来输入到其他程序的数据的程序。
一些预处理器只能够执行相对简单的文本替换和宏展开(比如C预处理器处理 #include 等指示),而另一些则有着完全成熟的编程语言的能力。
讲道理预处理的过程应该在词法解析之前比较合适,但是实际中(比如 GCC)中是一边进行词法解析一边进行预处理的。
词法分析:
编译器中执行的过程大致包含词法分析、语法分析、中间代码的生成(这个不一定有)等。
词法分析是计算机科学中将字符序列转换为标记(token)序列的过程。一般是以一个函数的形式存在供语法分析器调用。
意思就是编译器并不能直接看出你的代码如int a = strlen("hello world!"); 是什么意思。
它只能通过状态机的方式实现一个词法分析器,然后挨个字符去读,然后根据字符的特性切换状态,比如 读到'int',就切换状态的到 Identifier(我瞎掰的一个状态,后面也是,这个看代码怎么定义了),读到 '\n' 就切换到 Normal 状态等。(这里有一个 Java 实现词法解析器的例子,可以加深认识)。
还有维基百科上的一个例子:
sum=3+2;
上面的一行代码(注意没有空格)标记化(tokenization)之后可能是这样:
| 语素 | 标记类型 |
|---|---|
| sum | 标识符 |
| = | 赋值操作符 |
| 3 | 数字 |
| + | 加法操作符 |
| 2 | 数字 |
| ; | 语句结束 |
这一过程其实非常的复杂,比如int a和int a()肯定是不一样的标记,所以自己实现起来虽然感觉上是一个循环里面包一个 switch ... case ...然后 各种正则判断,给一个状态,实际上灰常的麻烦啊!
语法分析:
经过词法分析 tokenization 之后我们得到了一些单词及其标记,但是组合起来的语法还是不清楚,这个时候就需要通过语法分析器来处理了。
可以猜想其可以采用模板匹配的方式进行简单处理:
比如 int a = 10; 的模式,可以匹配一种模板 类型 变量名 = 值
但是在如 C 这样的语言中各种语法规则,都需要完美匹配,太难了。有兴趣的可以去深挖一下如 C 语言编译器中的语法解析是如何处理的。
最终语法分析的目的是将词法分析的结果转成 AST(抽象语法树)
在计算机科学中,抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码 语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现;而类似于
if-condition-then这样的条件跳转语句,可以使用带有两个分支的节点来表示。
为什么形成树形结构,是因为更容易被计算机处理、解析性能等综合考量(这里就回忆起小组之前学习的大O了...)。
中间代码:
中间代码(IR)其实就是指将 AST 生成一个与 CPU 和语言等无关的代码(可以粗暴、抽象的理解为跨各种类型CPU、各种语言的兼容性代码)。
这一步其实可以跳过,将上面过程的结果直接丢给汇编器处理。
中间代码的作用是界定编译前端(编译器前端负责把源码转换成AST,再转成中间代码),编译后端(编译器后端负责把中间代码转换成汇编代码)。
我们举例说明,Clang 其实就是苹果公司出品的C、 C++、Objective-C和 Objective-C++编程语言的 编译器前端,而著名的 LLVM 就是 Clang 底层采用的编译后端,GCC呢,则是全端(就是活儿都干了,当然效率就比不上了)。
Clang 的目的就是输出 AST,并且编译成 LLVM Bitcode(这就是中间代码),然后 LLVM 登场,将中间代码编译成平台相关的机器语言。
汇编器:
汇编器会接收汇编代码,将它转换成二进制的机器码,生成目标文件。目标文件是分段的,比如: .rel 段: 它表示一系列重定位表。
链接器:
链接器是一个程序,将一个或多个由编译器或 汇编器生成的目标文件外加 库链接为一个可执行文件。链接器还要完成程序中各目标文件的地址空间的组织,这可能涉及重定位工作。
也就是说一个文件中可能引用了外部的文件(比如你引进去一个库,用来其某个方法),链接器的作用就是把 import someFunction 这种符号位变成该符号真正的地址空间,这就要用到汇编输出的目标文件中的重定位表,去重定位地址空间。
链接器最终的目的是输出一个可执行的文件(.exe)。
解释型&编译型:
我们都知道 JavaScript、Python 等是解释型语言,C、Java 之类是编译型语言。
如何区分呢?
最直接最常用的方式就是解释型语言是通过解释器直接撸源码解释执行,编译型语言则是通过编译器把源代码最终转成可执行代码执行的。
假如,我们实现了一门解释型语言的编译器,或者把一门编译型语言的编译器放进解释器,并把编译过程延迟到运行时执行。是不是这个界限就不存在了?
JavaScript
JavaScript 比较坑爹的是它是一门寄生语言,宿主环境提供了其解释器,比如 Chrome 的 V8。
所以各个厂商可以在 ECMAScript 规范外,用 C/CPP 额外写一些附加功能给它,比如 DOM 操作。例如 IO 操作在浏览器厂商看来没什么必要,就没提供,但是不意味着 JS 就不可以操作文件,比如 Node 作为宿主环境下,就成了 IO 密集型的。
这里提一个概念,是因为它促成了 JavaScript 如今风生水起的原因,就是 JIT(即时编译)
其实 JIT 就是一种缓存策略,就是多次执行的代码可以通过编译器编译成机器码缓存起来,下一次遇到了就不用再去解释了,从而提升了 JS 近 10倍的性能提升!目前这种技术广泛应用在 Java、Python、Ruby等语音的编译/解释执行中。
我一直就想接着抛出我们下一个知识点 -- WebAssembly。不过在这之前希望大家先了解一下 Mozilla 出的 Asm.js,以前我司前 CTO 的文章。
这一折腾的技术趋势,感觉让前端开发更加困难(因为你要学习 C/CPP),那么有什么显而易见的好处呢?
我第一个想到的就是游戏,CPP 的游戏引擎运行 JavaScript,并用 WebGL 渲染,卧槽!
你可以点击这里体验。
Asm.js
这是一个具有前瞻性的意外发现,在研究 LLVM 过程中得到的灵感启发下的产物。
通过自己实现一个编译器后端,将 C/CPP 转换成 JavaScript 的子集,也就是 Asm.js。为了转换过程的顺利,需要 Asm 与 C 保持一致的特点:
- 静态类型
- 没有自动GC
虽然对 Asm.js 并不会有太多的介绍,但是我觉得它在 WebAssembly 的竞争下依然有生存的空间,毕竟是兼容性完美。
WebAssembly 入门
什么是 WebAssembly
WebAssembly是一种新的编码方式,可以在现代的网络浏览器中运行 - 它是一种低级的类汇编语言,具有紧凑的二进制格式,可以接近原生的性能运行,并为诸如C / C ++等语言提供一个编译目标,以便它们可以在Web上运行。它也被设计为可以与JavaScript共存,允许两者一起工作。
首先最直接的感受就是,这货会非常的快、快、快!
其次还有什么特点呢?-- 高效、安全、开放、标准。
如果你了解前一节的内容 Asm.js ,你会发觉二者就是继承与优化的关系,WebAssembly 继承了 Asm.js 的思想,但是做了更快的优化,就是不再通过 LLVM 编译成一个 Asm.js 文件,而直接是后缀为 .wasm 的二进制文件,体积更小,效率更高!
总结:
WebAssembly 是一种新的编码方式,字节码技术。将 C/CPP 通过编译器前端转成 LLVM IR,然后通过编译器后端工具(这里指的是官方提供的 Emscripten)转成 .wasm 格式的文件,这个其实就是 WebAssembly 。这个文件可以理解成目标汇编语言,浏览器能够极其迅速的将其转换成机器代码执行,所以其效率惊人。可以在 MDN 学习更多的概念。
WebAssembly 实践
这里分享好几个给力的文章,依样画葫芦即可。
总的来说,这是一项创新且优秀的技术。W3C 专门成立了小组来推动这个技术的发展,可以展望未来,可以直接像引入一个 lodash 模块一下引入一个 WebAssembly 的模块,对于前端开发来说太幸福了。
弊端就是前端开发需要多掌握一门 C/CPP 了。
