


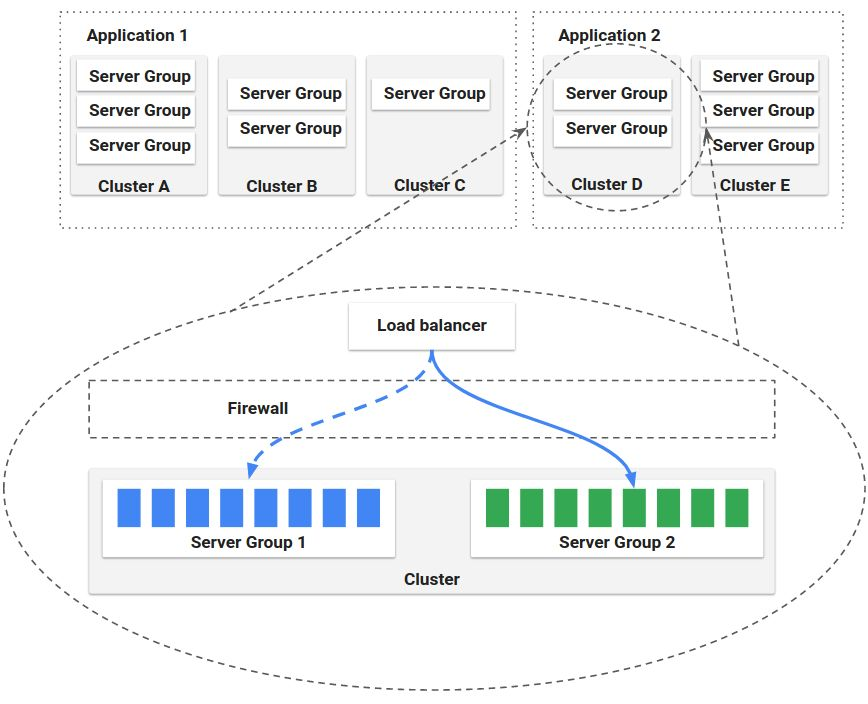
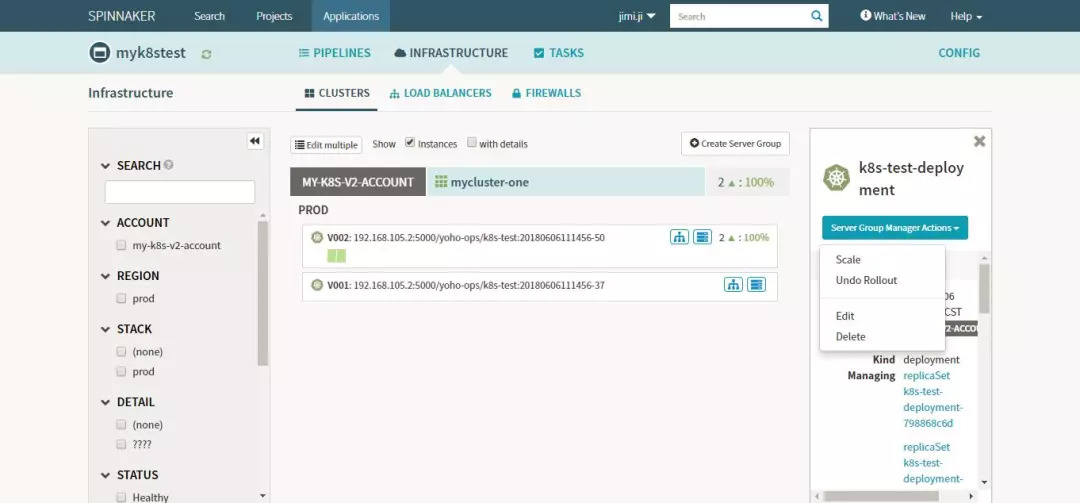
-
较强的Pipeline的能力:它的Pipeline可以复杂到无以复加,它还有很强的表达式功能(后续的操作中前面的参数均通过表达式获取)。
-
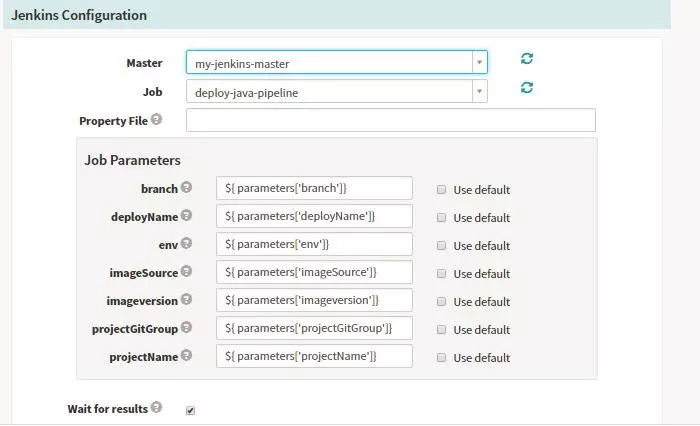
触发的方式:定时任务、人工触发、Jenkins job、Docker images,或者其他的Pipeline的步骤。
-
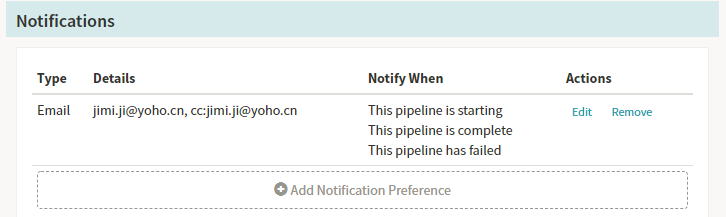
通知方式:Email、SMS or HipChat。
-
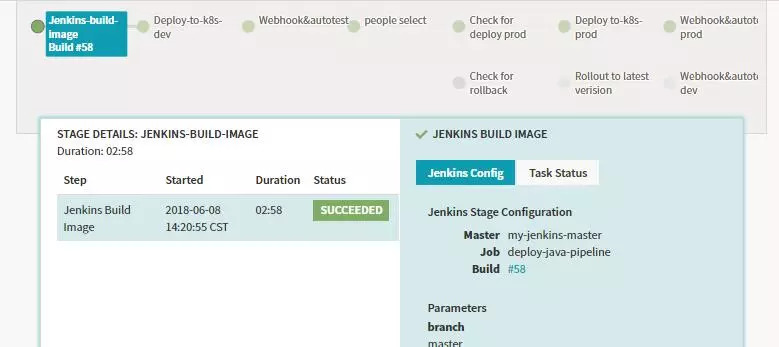
将所有的操作都融合到Pipeline中,比如回滚、金丝雀分析、关联CI等等。
-
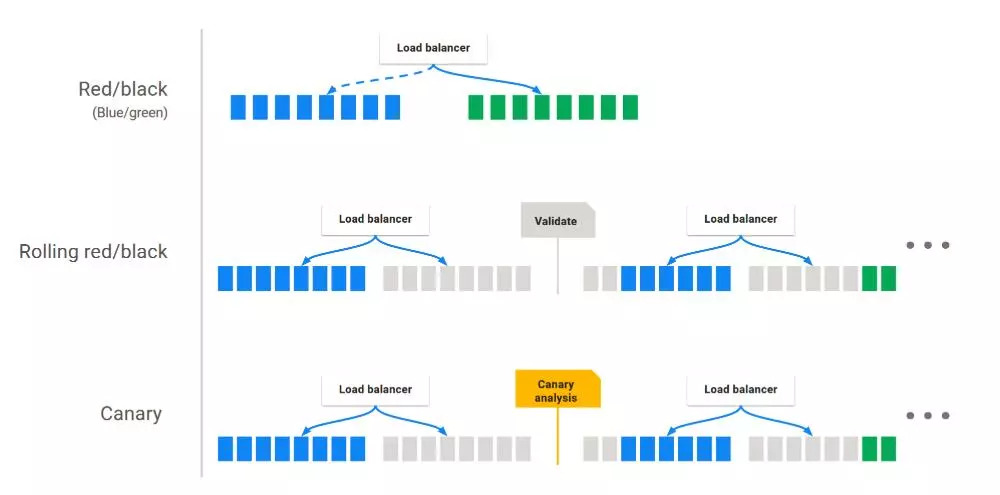
Recreate,先将所有旧的Pod停止,然后再启动新的Pod对应其中的第一种方式。
-
RollingUpdate,即滚动升级,对应下图中第二种方式。
-
Canary下面会单独的介绍其中的使用。
很多人都是感觉这个很难安装,其实主要的原因还是墙的问题,只要把这个解决了就会方便很多,官方的文档写的很详细,而且Spinnaker的社区也非常的活跃,有问题均可以在上面进行提问。 安装提供的方式
-
Halyard安装方式(官方推荐安装方式)
-
Helm搭建Spinnaker平台
-
Development版本安装
vim /opt/halyard/bin/halyardDEFAULT_JVM_OPTS='-Dhttp.proxyHost=192.168.102.10 -Dhttps.proxyPort=3128'18 GB of RAMA 4 core CPUUbuntu 14.04, 16.04 or 18.04-
Halyard下载以及安装。
-
选择云提供者:我选择的是Kubernetes Provider V2(Manifest Based),需要在部署Spinnaker的机器上完成Kubernetes集群的认证,以及权限管理。
-
部署的时候选择安装环境:我选择的是Debian包的方式。
-
选择存储:官方推荐使用Minio,我选择的是Minio的方式。
-
选择安装的版本:我当时最新的是V1.8.0。
-
接下来进行部署工作,初次部署时间较长,会连接代理下载对应的包。
-
全部下载与完成后,查看对应的日志,即可使用localhost:9000访问即可。
-
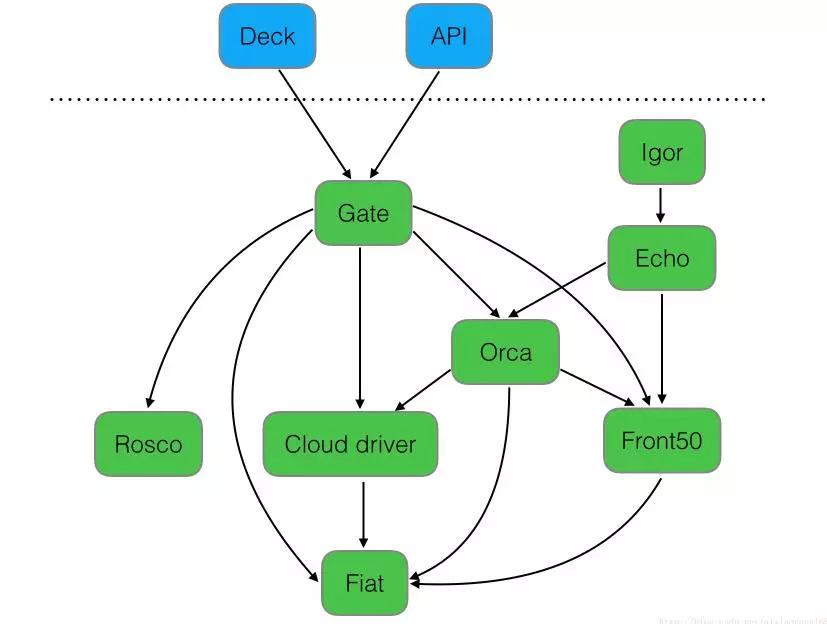
Deck:面向用户UI界面组件,提供直观简介的操作界面,可视化操作发布部署流程。
-
API:面向调用API组件,我们可以不使用提供的UI,直接调用API操作,由它后台帮我们执行发布等任务。
-
Gate:是API的网关组件,可以理解为代理,所有请求由其代理转发。
-
Rosco:是构建beta镜像的组件,需要配置Packer组件使用。
-
Orca:是核心流程引擎组件,用来管理流程。
-
Igor:是用来集成其他CI系统组件,如Jenkins等一个组件。
-
Echo:是通知系统组件,发送邮件等信息。
-
Front50:是存储管理组件,需要配置Redis、Cassandra等组件使用。
-
Cloud driver:是用来适配不同的云平台的组件,比如Kubernetes、Google、AWS EC2、Microsoft Azure等。
-
Fiat:是鉴权的组件,配置权限管理,支持OAuth、SAML、LDAP、GitHub teams、Azure groups、 Google Groups等。
| 组件 | 端口 | 依赖组件 | 端口 |
| Clouddriver | 7002 | Minio | |
| Fiat | 7003 | Jenkins | |
| Front50 | 8080 | Ldap | |
| Orca | 8083 | GitHub | |
| Gate | 8084 | ||
| Rosco | 8087 | ||
| Igor | 8088 | ||
| Echo | 8089 | ||
| Deck | 9000 | ||
| Kayenta | 8090 |
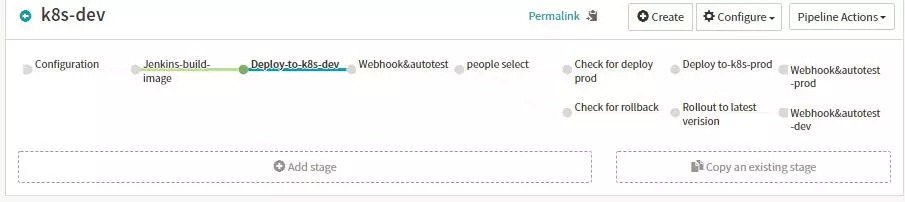
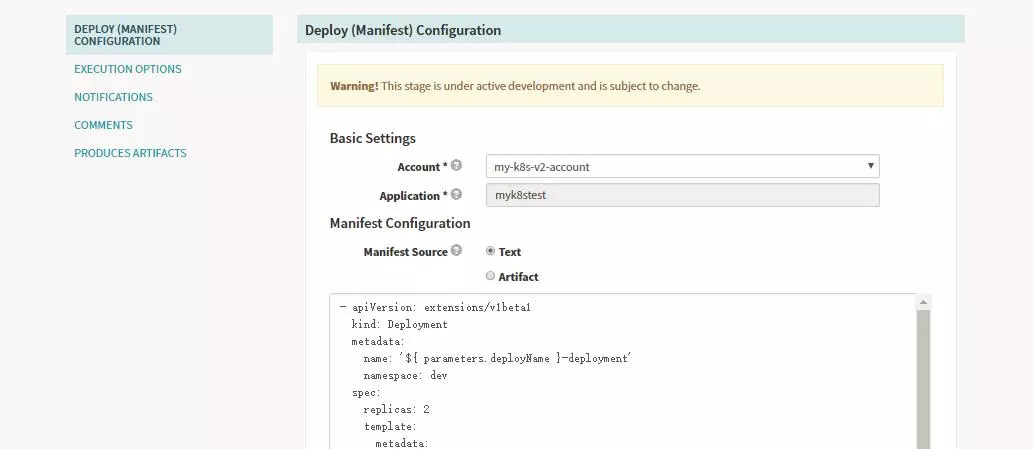
- apiVersion: extensions/v1beta1kind: Deploymentmetadata:name: '${ parameters.deployName }-deployment'namespace: devspec:replicas: 2template: metadata: labels: name: '${ parameters.deployName }-deployment' spec: containers: - image: >- 192.168.105.2:5000/${ parameters.imageSource }/${ parameters.deployName }:${ parameters.imageversion } name: '${ parameters.deployName }-deployment' ports: - containerPort: 8080 imagePullSecrets: - name: registrypullsecret- apiVersion: v1kind: Servicemetadata:name: '${ parameters.deployName }-service'namespace: devspec:ports: - port: 8080 targetPort: 8080selector: name: '${ parameters.deployName }-deployment'- apiVersion: extensions/v1beta1kind: Ingressmetadata:name: '${ parameters.deployName }-ingress'namespace: devspec:rules: - host: '${ parameters.deployName }-dev.ingress.dev.yohocorp.com' http: paths: - backend: serviceName: '${ parameters.deployName }-service' servicePort: 8080 path: /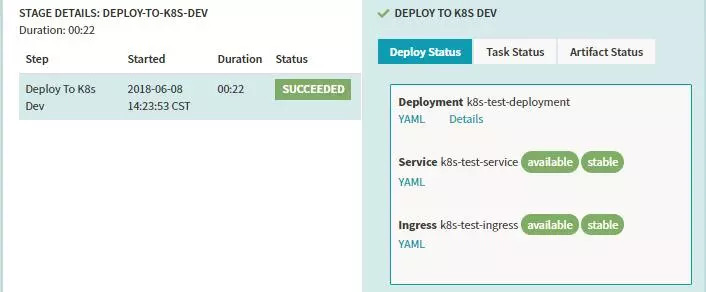
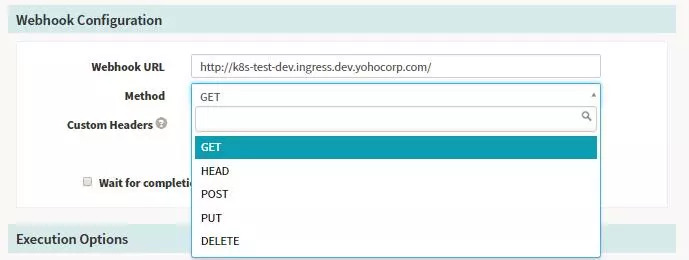
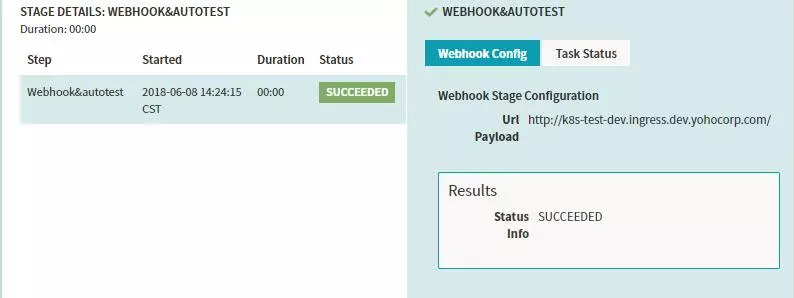
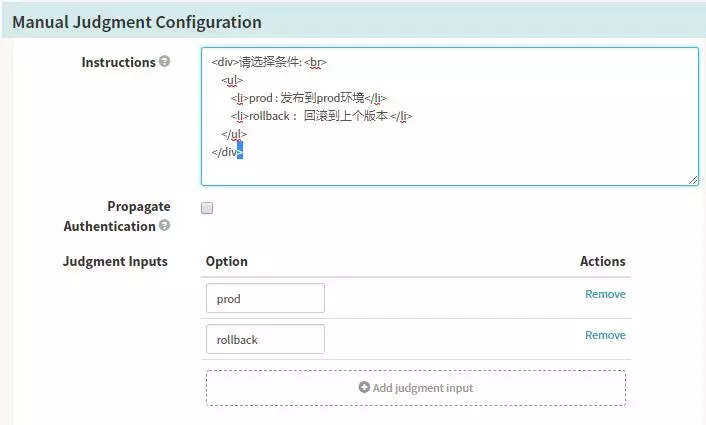
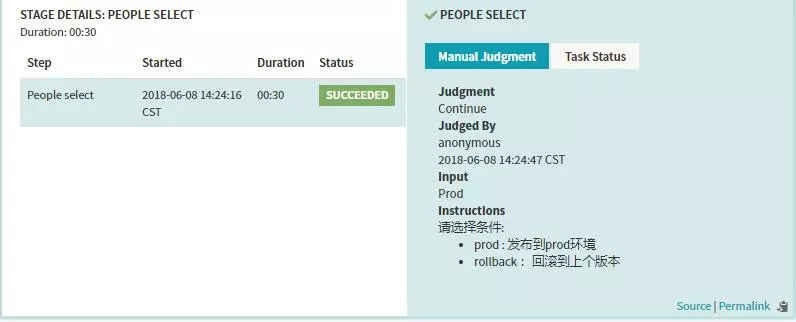
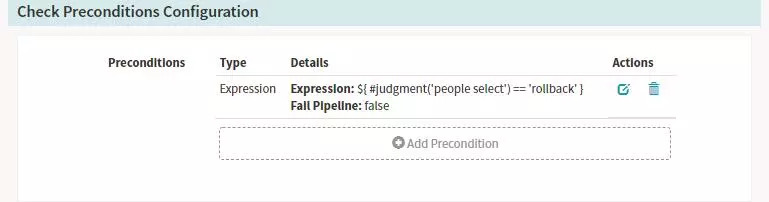
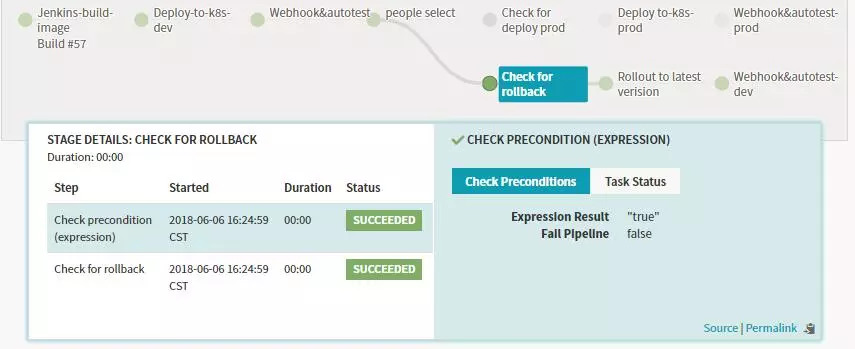
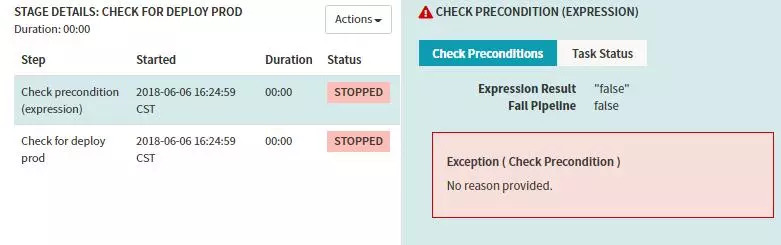
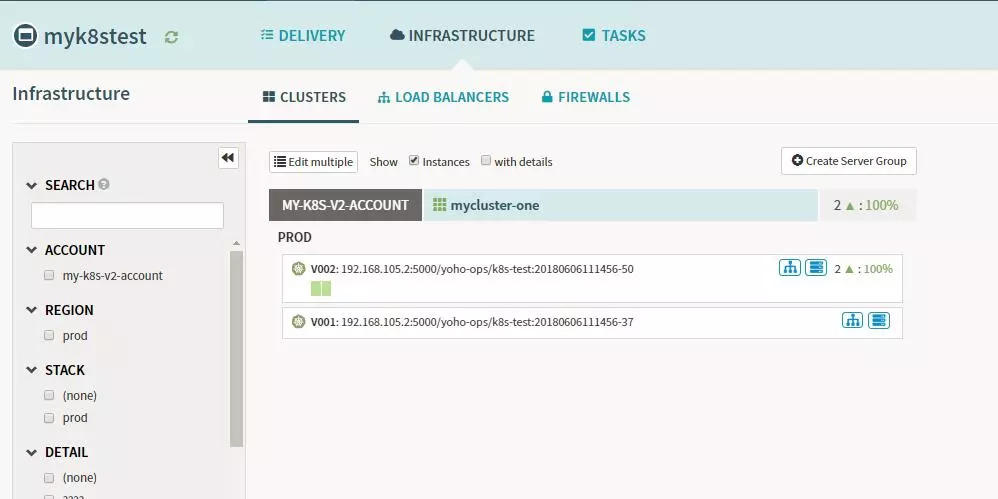
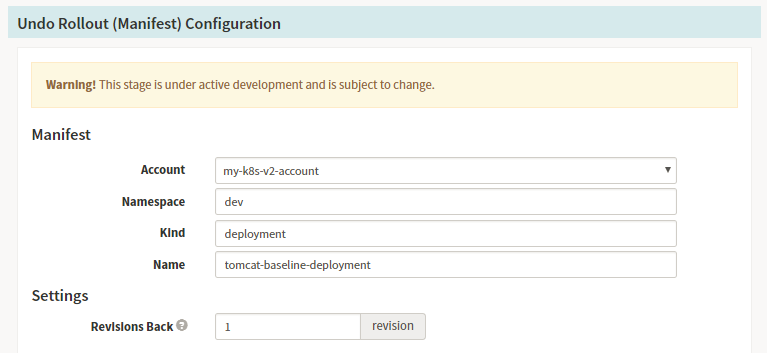
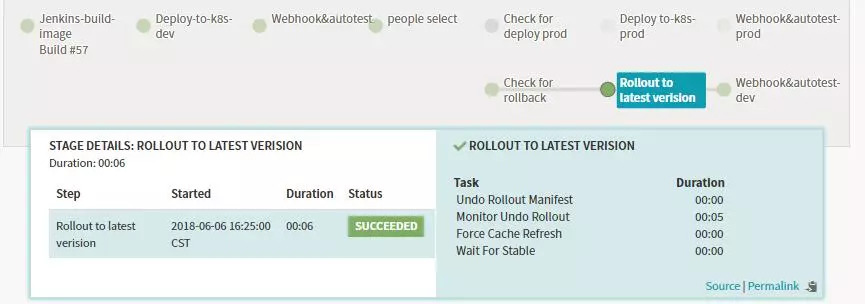
-
验证数据
-
清理数据
-
比对指标
-
分数计算
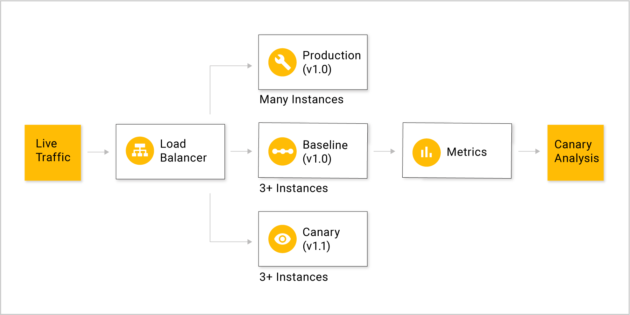
-
我们需要对应用开启Canary的配置。
-
创建出Baseline与Canary的deployment由同一个Service指向这两个deployment。
-
我们这里采用读取Prometheus的指标,需要在hal中增加Prometheus配置。Metric可以直接匹配Prometheus的指标。
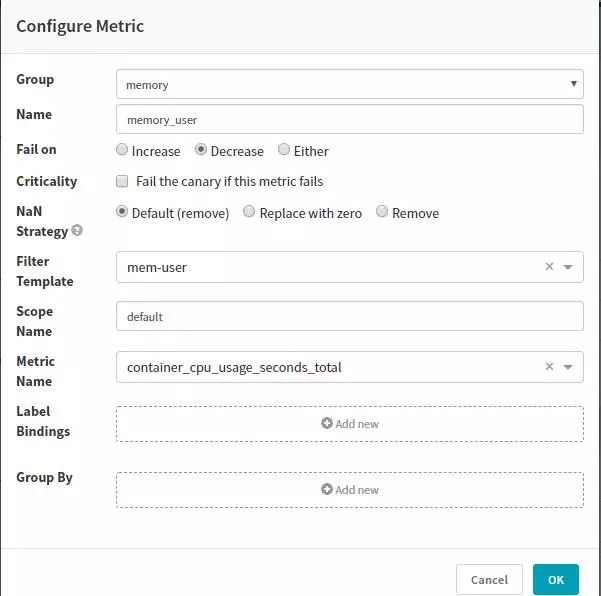
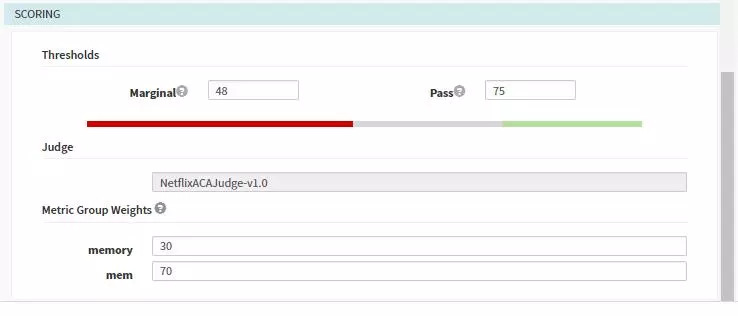
需要配置收集指标以及指标的权重:
-
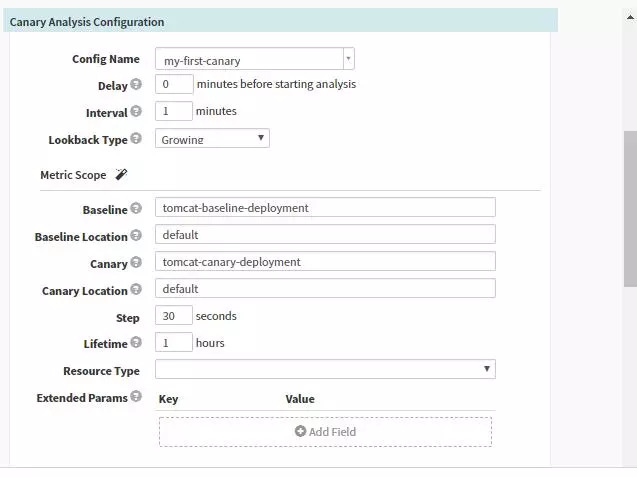
在Pipeline中指定收集分析的频率以及需要指定的源,同时可以配置scoring从而覆盖模板中的配置。
-
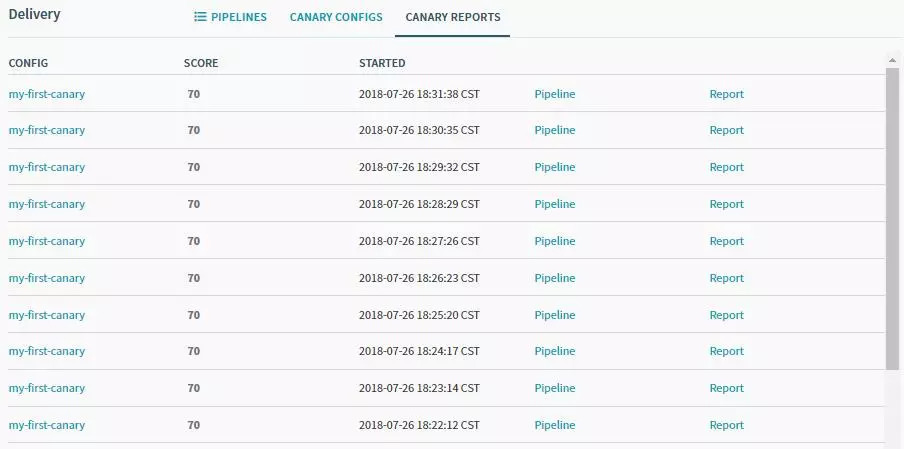
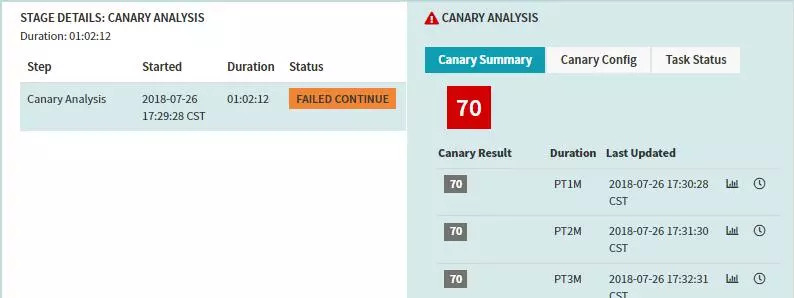
每次分析的执行记录:
-
结果展示如下,由于我们设置的目标是75,所以pipeline的结果判定为失败。
我们是腾讯云的客户,采用腾讯云容器服务主要看重以下几个方面:
-
Kubernetes在自搭建的集群中,要实现Overlay网络,在腾讯云的环境里,它本身就是软件定义网络VPC,所以它在网络上的实现可以做到在容器环境里和原生的VM网络一样的快,没有任何的性能牺牲。
-
应用型负载均衡器和Kubernetes里的Ingress相关联,对于需要外部访问的服务能够快速的创建。
-
腾讯云的云储存可以被Kubernetes管理,便于持久化的操作。
-
腾讯云的部署以及告警也对外提供了服务与接口,可以更好的查看与监控相关的Node与Pod的情况。
-
腾讯云日志服务很好的与容器进行融合,能够方便的收集与检索日志。
Q&A
Q:为什么没有和CI结合在一起?使用这个比较重的Spannaker有什么优势? A:可以和CI进行结合,比如Webhook的方式,或者采用Jenkins调度的方式。优势在于可以和很多云平台进行结合,而且他的Pipeline比较的完美,参数化程度很高。 Q:目前IaaS只支持OpenStack和国外的公有云厂商,国内的云服务商如果要支持的话,底层需要怎么做呢(管理云主机而不是容器)?自己实现的话容易吗?怎么入手? A:目前我们主要使用Spinnaker用来管理容器这部分的内容,对于国内的云厂商Spinnaker支持都不是非常的好,像LB,安全策略这些都不可在Spinnaker上面控制。若是需要研究可以查看Cloud driver这个组件的功能。 Q:Spinnaker能不能在Pipeline里通过http API获取一个deployment yaml进行deploy,这个yaml可能是动态生成的? A:部署服务有两种方式:1. 在Spinnaker的UI中直接填入Manifest Source,其实就是对应的deployment YAML,只不过这里可以写入Pipeline的参数;2. 可以从GitHub中拉取对应的文件,来部署。 Q:Spannaker的安全性方面怎么控制? A:Spinnaker中Fiat是鉴权的组件,配置权限管理,Auth、SAML、LDAP、GitHub teams、Azure Groups、 Google Groups,我们就采用LDAP,登陆后会在上面显示对应的登陆人员。 Q: deploy和test以及rollback可以跟helm chart集成吗? A:我觉得是可以,很笨的方法最终都是可以借助于Jenkins来实现,但是Spinnaker的回滚与部署技术很强大,在页面上点击就可以进行快速的版本回滚与部署。 Q: Spannaker之前的截图看到也有对部分用户开发的功能,用Spannaker之后还需要Istio吗? A:这两个有不同的功能,【对部分用户开发的功能】这个是依靠创建不同的service以及Ingress来实现的,他的路由能力肯定没有Istio强悍,而且也不具备熔断等等的技术,我们线下这么创建主要为了方便开发人员进行快速的部署与调试。
