


在设计行业快速变革的这几年,设计师不再只是简单的画图,而是重新思考自己的工作内容,设计价值如何体现? 本文结合在工作中对Dashboard设计的经验和思考,和大家一起探讨图表智能推荐。
01
—
寻找源头—图表推荐功能
关于图表智能推荐功能的意义一方面在于,工作中很多人不理解图表,有学习成本,且出现“用的不合适”,“用的不正确”的问题;另一方面对于常接触图表的人,譬如从事可视化方面的设计师、数据相关行业的人员,他们对于图表的用法比较了解,并且已经有一套对图表的选择逻辑。与其让用户去学习,不如让机器来。
目前,了解到具备智能推荐功能的产品有以下两款:
-
Excel 首先需要导入或者绘制一个表格,框选出需要变成图表的数据,点击智能推荐后便出现智能推荐结果,用户根据自己的需求进行选择。
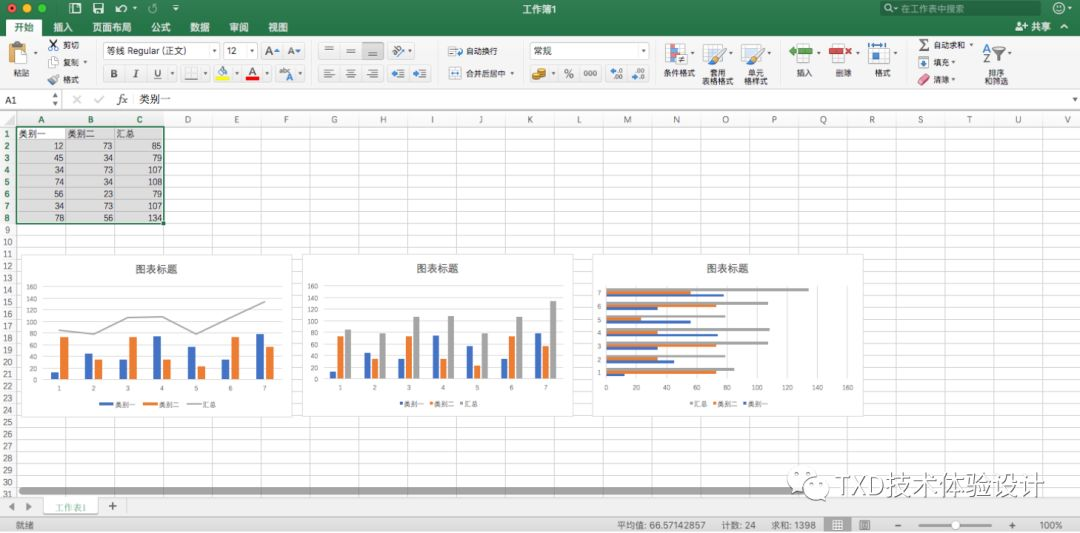
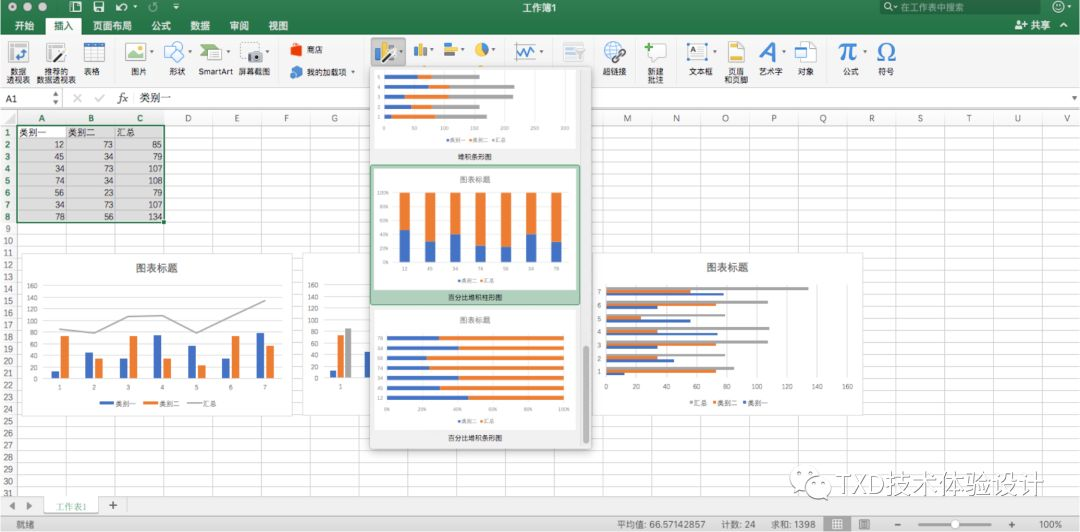
-
网易有数 从操作流程上来看,网易有数和Excel的流程几乎一致。
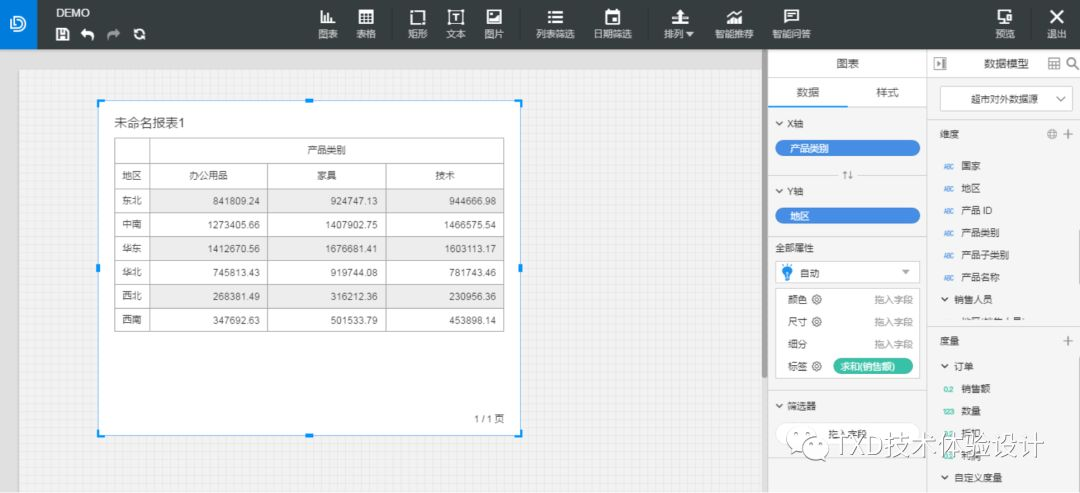
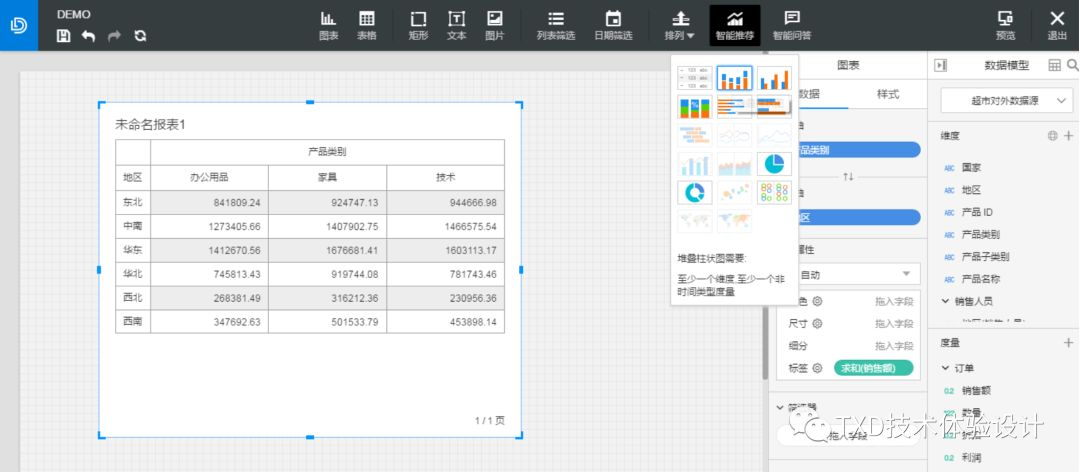
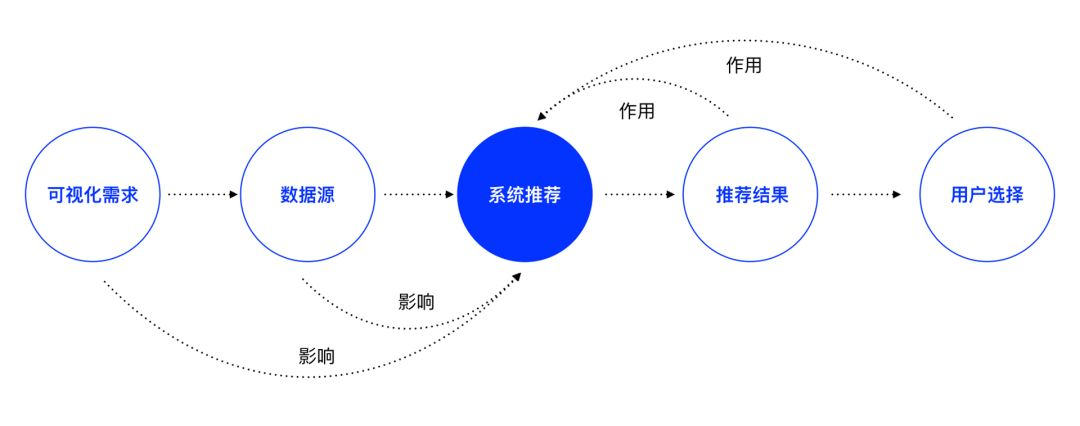
通过两个案例我们可以了解一个图表推荐的操作流程:首先用户拥有可视化需求,之后用户放入数据源,接下来系统或平台进行图表智能推荐,用户最终选择所需展示方式。从整个流程来看,可视化需求和数据源是图表推荐的必要条件,而完成整个图表选择流程还需要用户在推荐结果中选择自己所需。
02
—
推荐的上游—需求和数据特征
2.1 可视化需求
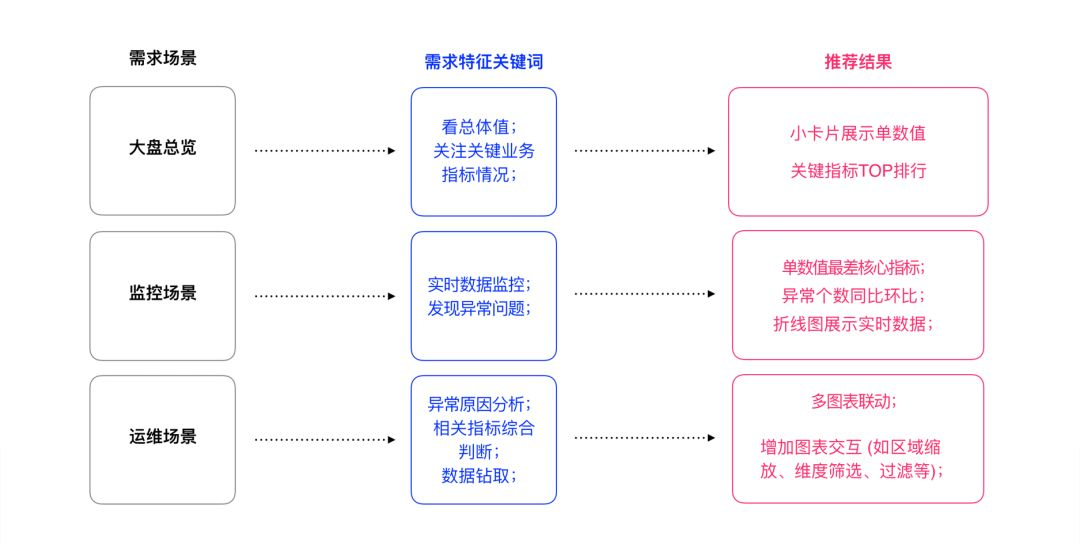
以后台产品为例,其需求场景一般为以下三类:大盘总览,监控,运维。其中,大盘总览是为了通过Dashboard看到总体资源分配情况,总体运行情况,进行关键业务指标呈现;监控是为了在数据多,且层次丰富的情况下,一眼看到异常;运维是为了异常产生原因分析,相关指标综合判断,钻取数据。
针对每种场景的需求,提炼需求特征关键词,针对这些关键词配合设计经验可以对应到各种图表展示组件:
2.2 数据特征
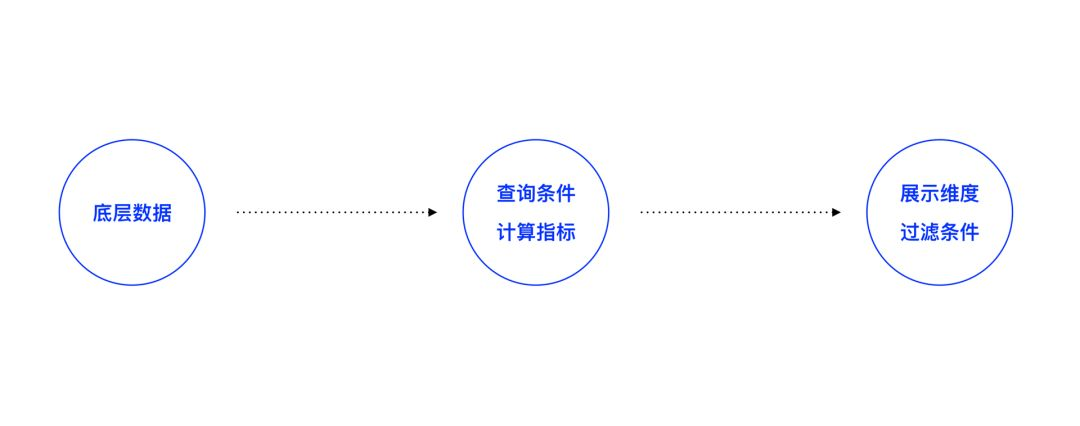
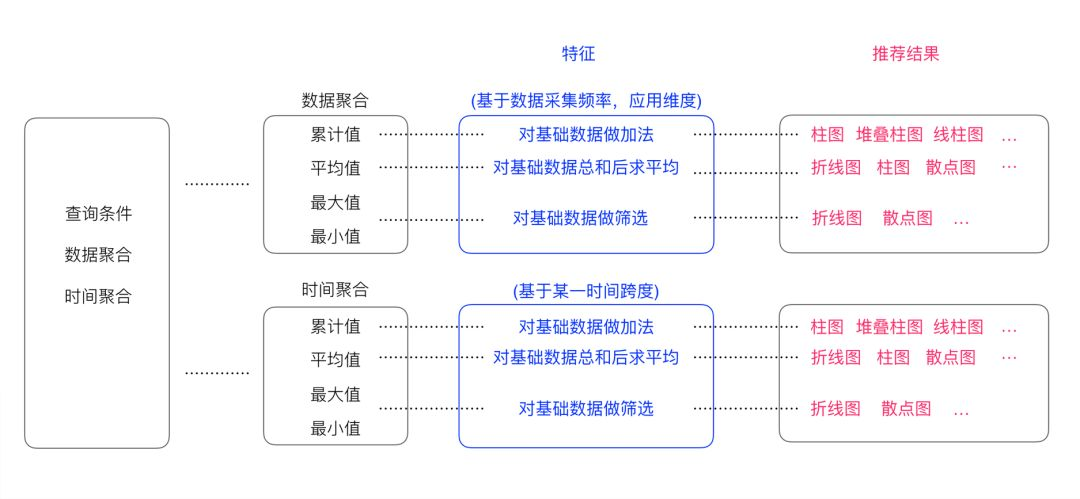
以监控场景数据为例,数据一般从最底层数据源,通过一些查询条件、筛选条件、过滤条件、展示维度呈现出用户需要的数据,整个流程如下图所示:
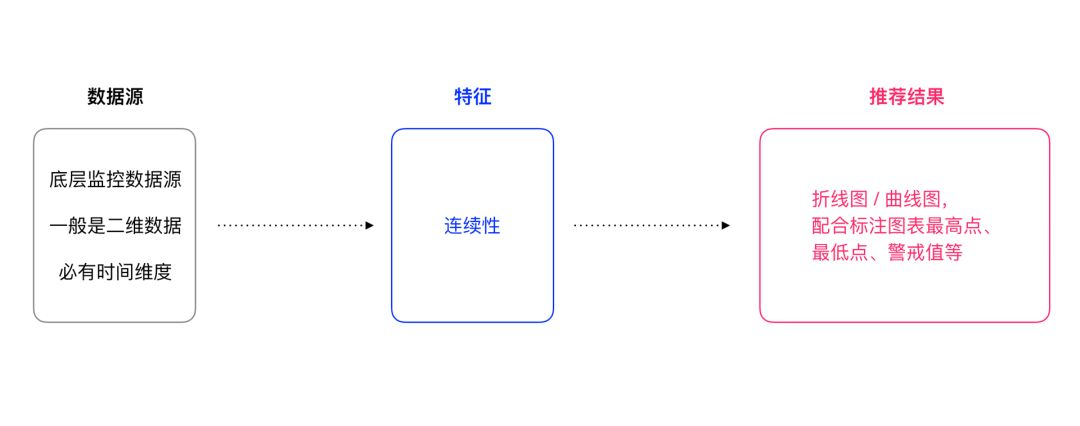
这里所指的底层数据一般具有较简单的数据构成:时间维度和该时间点下的某个指标的值,所以这种数据具有较明确的时间连续性特征,根据整个特征结合对图表的设计理解推荐使用曲线图,折线图等。
对于查询指标,设计师则需要和其它岗位的同学配合去理解,这里我以简单的聚合方式为例说明推荐的过程。例如当我们做加法求几个数据间的累计值时,可能使用堆叠柱图展示对比和组成关系 ;用线柱图展示他们的对比关系及波动等。
03
—
推荐的下游—图表特征
上文中对图表和需求以及数据的对应关系进行了举例,那么这些对应关系是如何产生的 ?设计师所拥有的图表设计经验是否能够进行抽离和概括?
首先,我们需要了解图表本身具有的视觉认知特性,可视化图表由四个基本元素构成,即点、线、面、体。这四个基本元素在可视化中结合一种或多种视觉表现方式呈现图表认知特征,即位置、大小、形状、方向、色相、饱和度、明度等。一个图表综合呈现的特征和人类的感知可以用经典的格式塔原理来帮助理解,格式塔原理包括:接近性原理,相似性原理,连续性原理,封闭性原理,对称性原理等等。
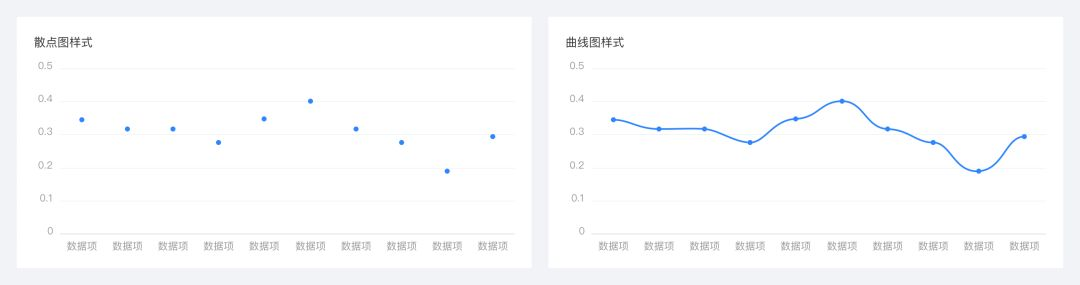
这里使用同一组数据的散点图,曲线图为例说明。在散点图中,我们看到的是这组数据的分布情况,因为以接近性原理来看,当数据以点的形式独立存在时,人会主动将他们组织在一起,相互靠近的物体我们会看成为一组。在曲线图中,这些点被连起来成为一条线,我们看到的则是整个数据的走势,因为线具有连续的视觉认知,数据不再是离散的碎片。
基于这样种种的特征,每个图表都有自己的属性特征标签。设计师因为能够熟练的运用图表的这些认知特性,同时对业务需求和数据有充分的理解,从而匹配两方面的特征即可得出推荐结果。
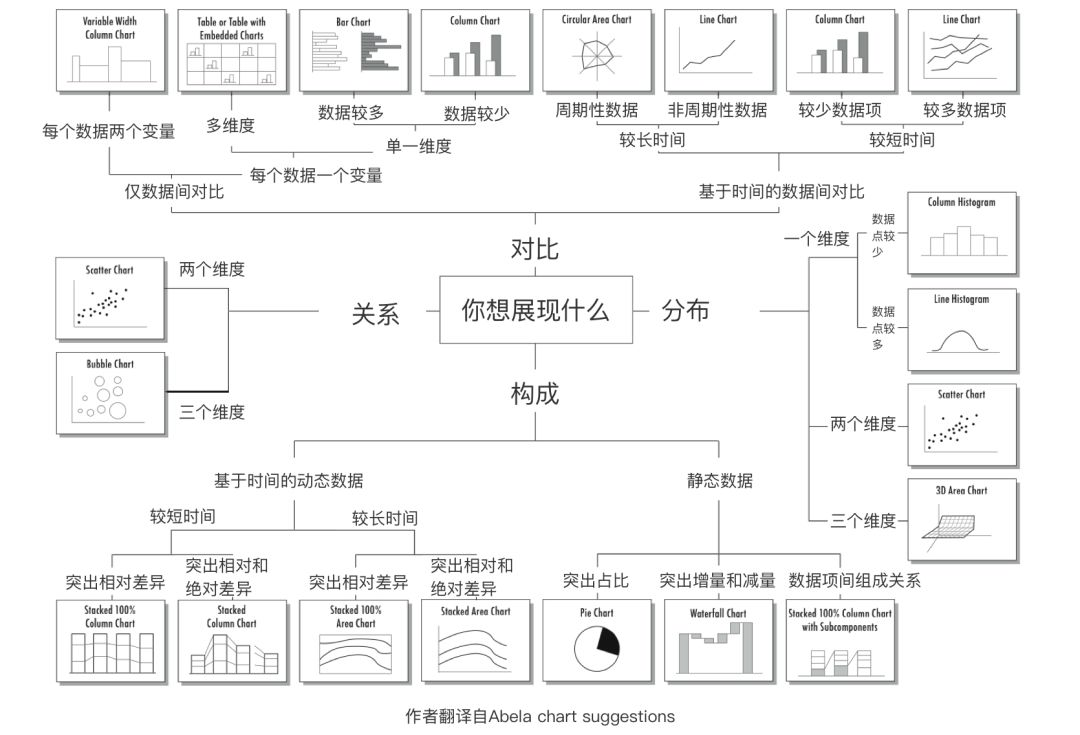
数据可视化经过这几年的发展,已经有大量的设计师从事该行业,可喜的是现在我们能够站在巨人的肩膀上。Abela已经对图表的各种特征进行了大致的概括总结:
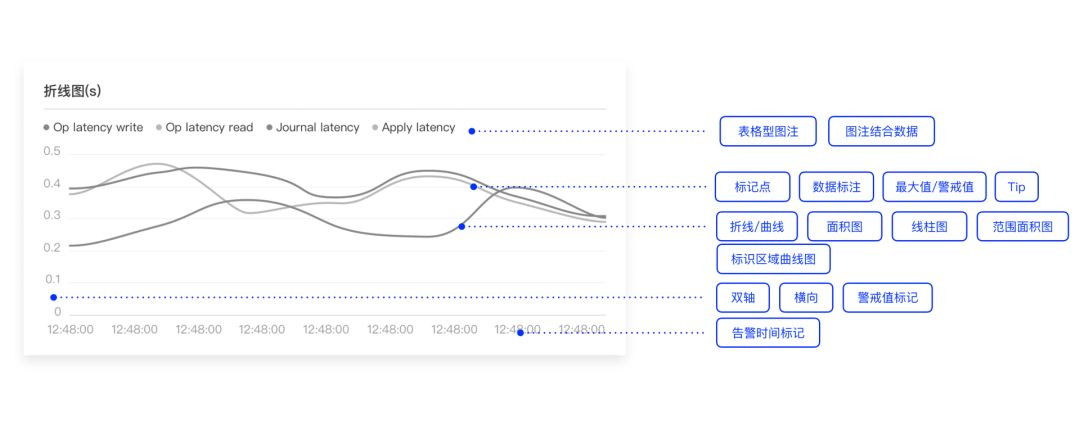
然而这些还不够,我们还能够基于这种方法继续挖掘图表的更多延伸属性,以线图为例:当数据项较多时,可推荐使用表格型标注方式;当业务场景需要显示当前数值时,我们推荐图注结合数字的方式展示...
04
—
匹配及量化
总的来说,推荐的过程其实是“上游” 和“下游”进行特征匹配的过程。但是,从可行性角度来思考,我们还需要将这种匹配程度进行量化。
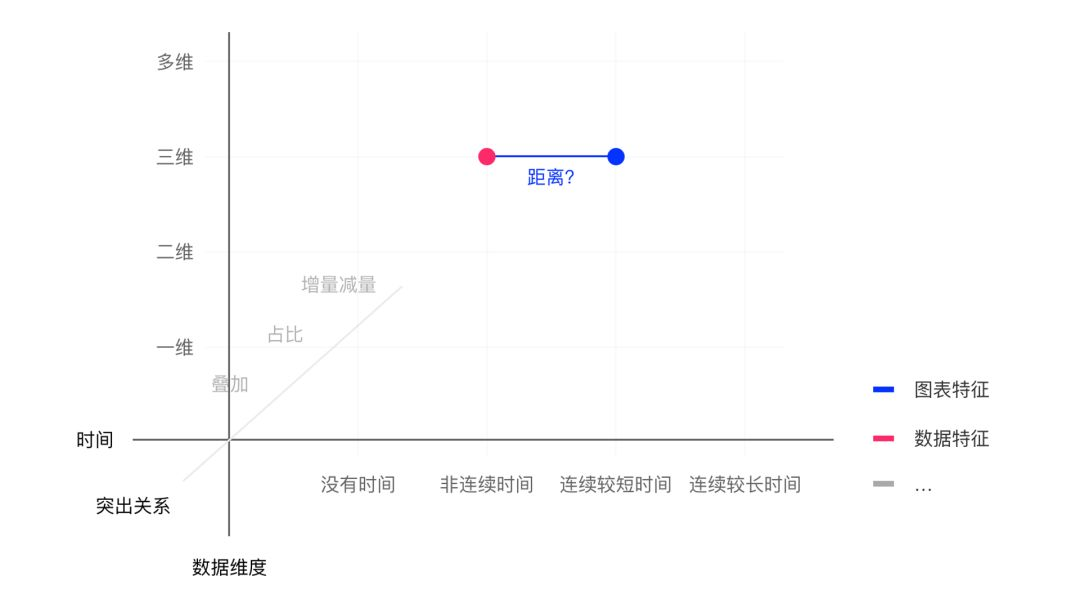
可以猜想: 当我们将图表的特征,需求的特征,数据的特征标签化,绘制成多个维度。通过对某一图表的特征属性定位,可以锁定到图表中的一个点;同理,将数据特征锁定为一个点;需求锁定成为一个点。当这些点在这个虚拟的数据空间中距离越近时,他们的匹配程度就越高。

关注查看更多原创内容
