

本文根据黄炎在2018年8月3日在【2018 MySQL技术交流大会 · 上海站】现场演讲内容整理而成。
黄炎
爱可生研发总监,深入钻研分布式数据库相关技术,擅长业界相关MySQL中间件产品和开发,以及分布式中间件在企业内部的应用实践。
摘要:今天我带来的分享是系统观测工具,有所关联但不涉及MySQL自身的这样一个话题。
分享大纲:
1. MySQL 慢的诊断思路
2. 系统观测工具介绍
3. bcc (eBPF脚本集) 使用举例
4. eBPF 使用方法/限制
今天我带来的分享是系统观测工具,跟MySQL相关,但不是MySQL,选择这个话题最主要的原因是今天4场演讲,刚才是官方的专家来介绍MySQL的新特性,后面还有两位专家,一位是介绍MySQL在真实业务中的大规模应用,还有一位是介绍源码,留给我的空间并不是很多,所以选择了一个跟MySQL有所关联但不涉及MySQL自身的话题。
首先想请问一下大家,如果遇到MySQL慢的话大家的第一印象是什么,MySQL数据库如果性能不行的情况下,大家的处理手法是怎样?
我咨询了一些同行, 得到了以下反馈,第一反应是再试一次,第二个反应是优化一下SQL,第三个反应是我们调大buffer pool,然后开始换硬件了,换一下SSD,然后实在不行了我们找个搜索引擎问一下说“MySQL慢怎么办”。
如果大家用的是国内的搜索引擎的话,搜索引擎会推荐某某知道或者某某乎, 推荐一些MySQL调优经验, 调大参数A, 调低参数, 诸如此类,类似的网站能告诉你MySQL慢怎么办。

我们来分析一下这些现象背后隐藏的意义:

-
如果大家再试一次能够成功的话, 意味着你可能碰到了不可复现的外界因素的影响,导致MySQL会慢。
-
如果优化SQL能解决,就意味着SQL的执行复杂度远远大于它的需求复杂度。
-
如果调大buffer pool能解决,就意味着MySQL碰到了自身的某些限制。
-
如果换SSD能解决,那么意味着服务器资源受到了一定的限制。
-
如果需要搜索引擎,意味着调优这事已经变成了玄学。
所以今天我想向大家介绍的是四部分内容:
1.MySQL 慢的诊断思
2.系统观测工具介绍
3.bcc (eBPF脚本集) 使用举例
4.eBPF 使用方法/限制

第一部分,我们向大家介绍一下常规的MySQL诊断慢的思路,也是业界的常规思路。
第二部分,是今天介绍的主要命题 -- 系统观测工具的相关内容,我们会大概了解一下什么叫系统观测工具。
第三部分,给大家介绍一个脚本集,这个脚本集是开源的,开箱即用并且可以帮助大家快速诊断MySQL的一些问题,我们直接使用10个例子 快速地介绍一下这个脚本集能为我们做到什么。
最后,我们介绍一下eBPF的使用方法和脚本结构。任何一个好用的东西一定有它自己的限制,否则它就太完美了,所以我们也会介绍一下它的限制到底是怎样的。
1.MySQL 慢的诊断思路

我们先来看第一个阶段,MySQL慢的诊断思路,一般我们会从三个方向来做:
-
第一个方向是MySQL内部的观测
-
第二个方向是外部资源的观测
-
第三个方向是外部需求的改造
1.1 MySQL 内部观测

我们来看MySQL内部的观测,常用的观测手段是这样的,从上往下看,第一部分是Processlist,看一下哪个SQL压力不太正常,第二步是explain,解释一下它的执行计划,第三步我们要做Profilling,如果这个SQL能再执行一次的话, 就做一个Profilling,然后高级的DBA会直接动用performance_schema ,MySQL 5.7 以后直接动用sys_schema,sys_schema是一个视图,里面有便捷的各类信息,帮助大家来诊断性能。再高级一点,我们会动用innodb_metrics进行一个对引擎的诊断。
除了这些手段以外,大家还提出了一些乱七八糟的手段,我就不列在这了,这些是常规的一个MySQL的内部的状态观测的思路。除了这些以外,MySQL还陆陆续续提供了一些暴露自己状态的方案,但是这些方案并没有在实践中形成套路,原因是学习成本比较高。
1.2 外部资源观测

外部资源观测这部分,我引用了一篇文章,这篇文章的二维码我贴在上面了。这篇文章是国外的一个神写的,标题是:60秒的快速巡检,我们来看一下它在60秒之内对服务器到底做了一个什么样的巡检。一共十条命令,这是前五条,我们一条一条来看。

1.uptime,uptime告诉我们这个机器活了多久,以及它的平均的负载是多少。
2.dmesg -T | tail,告诉我们系统日志里边有没有什么报错。
3.vmstat 1,告诉我们虚拟内存的状态,页的换进换出有没有问题,swap有没有使用。
4. mpstat -P ALL, 告诉我们CPU压力在各个核上是不是均匀的。
5.pidstat 1,告诉我们各个进程的对资源的占用大概是什么样子。

我们来看一下后五条:
首先是iostat-xz 1,查看IO的问题,然后是free-m内存使用率,之后两个sar,按设备网卡设备的维度,看一下网络的消耗状态,以及总体看TCP的使用率和错误率是多少。最后一条命令top,看一下大概的进程和线程的问题。
这个就是对于外部资源的诊断,这十条命令揭示了应该去诊断哪些外部资源。
1.3 外部需求改造

第三个诊断思路是外部的需求改造,我在这里引用了一篇文档,这篇文档是MySQL的官方文档中的一章,这一章叫Examples of Common Queries,文档中介绍了常规的SQL怎么写, 给出了一些例子。文章的链接二维码在slide上。
我们来看一下它其中提到的一个例子。

它做的事情是从一个表里边去选取,这张表有三列,article、dealer、price,选取每个作者的最贵的商品列在结果集中,这是它的最原始的SQL,非常符合业务的写法,但是它是个关联子查询。

关联子查询成本是很贵的,所以上面的文档会教你快速地把它转成一个非关联子查询,大家可以看到中间的子查询和外边的查询之间是没有关联性的。

第三步,会教大家直接把子查询拿掉,然后转成这样一个SQL,这个就叫业务改造,前后三个SQL的成本都不一样,把关联子查询拆掉的成本,拆掉以后SQL会跑得非常好,但这个SQL已经不能良好表义了,只有在诊断到SQL成本比较高的情况下才建议大家使用这种方式。
为什么它能够把一个关联子查询拆掉呢?

这背后的原理是关系代数,所有的SQL都可以被表达成等价的关系代数式,关系代数式之间有等价关系,这个等价关系通过变换可以把关联子查询拆掉。
上面的这篇文档是一个大学的教材,它从头教了关于代数和SQL之间的关系。然后一步步推导怎么去简化这句SQL。
第一 ,MySQL本身提供了很多命令来观察MySQL自身的各类状态,大家从上往下检一般能检到SQL的问题或者服务器的问题。
第二 ,从服务器的角度,我们从巡检的脚本角度入手,服务器的资源就这几种,观测手法也就那么几种,我们把服务器的资源全部都观察一圈就可以了。
第三 ,如果实在搞不定,需求方一定要按照数据库容易接受的方式去写SQL,这个成本会下降的非常快,这个是常规的MySQL慢的诊断思路。
2.系统观测工具介绍
我们先从诊断思路的讨论切换到系统的观测工具, 首先了解什么叫系统观测工具并且看一下它的举例,然后再回到诊断思路上,看看新的工具的引入能为我们的思路到底带来怎样的改变。

先来看一下什么叫系统观测工具?援引这篇文档,二微码如上,这是一个外国人写的文档,我把这个文档拆开,中间描述了三件事情:

第一 ,系统观测工具的数据源来自于哪里;
第二 ,数据采集过程,因为采集的是系统的运行状况,所以到底如何采集这是一个难点;
第三 ,应该怎么看数据,是用图来看,还是用表来看,它就叫数据处理前端;

第一步 ,我们来看一下数据源,Linux给我们提供的数据源是这几种,包括操作系统内核态提供的观测点和用户态提供的观测点,MySQL很早之前就提供了用户态的观测点。

第二步 ,怎么把数据抽出来,抽出来的时候,大家可以看到这些工具里边大家最熟悉的应该是perf和ftrace,然后sysdig也有人在用,其它的可能有所耳闻,这个是从操作系统里边抽取数据的方法。

第三步 ,数据处理前端,前端里边常用的也是perf和ftrace。如果大家对perf很熟悉的话会知道perf出来的数据是一个树形的数据,并可以跟这棵树进行交互,比如说: 查看某个函数运行了多久,哪一个函数的时间最长,这个是数据处理前端。

我们来对比一下常规的四类系统观测工具今天我要介绍的是第三类,eBPF,我们过往常用的是第四个,前面这两个是通用工具,我们来对比一下这四个到底有什么不同,看看Linux到底为啥提供这么多观测工具。

第一 ,来看一下ftrace,ftrace是一个sysfs中的一个桩,通过这个桩内核提供了一种观测的形式,这种观测的形式就是把想观测的函数的签名打到这个桩里,然后操作系统就会提供这个函数运行的状况。ftrace的结构如左图, 数据处理前端和采集端是ftrace, 数据源是下面这一堆。

第二 ,大家常用的perf,原理是操作系统提供了一个系统调用可以将数据写到一个缓存中, 然后客户端把这些数据端抽取出来然后呈现在显示器上。这个是perf的运行原理。
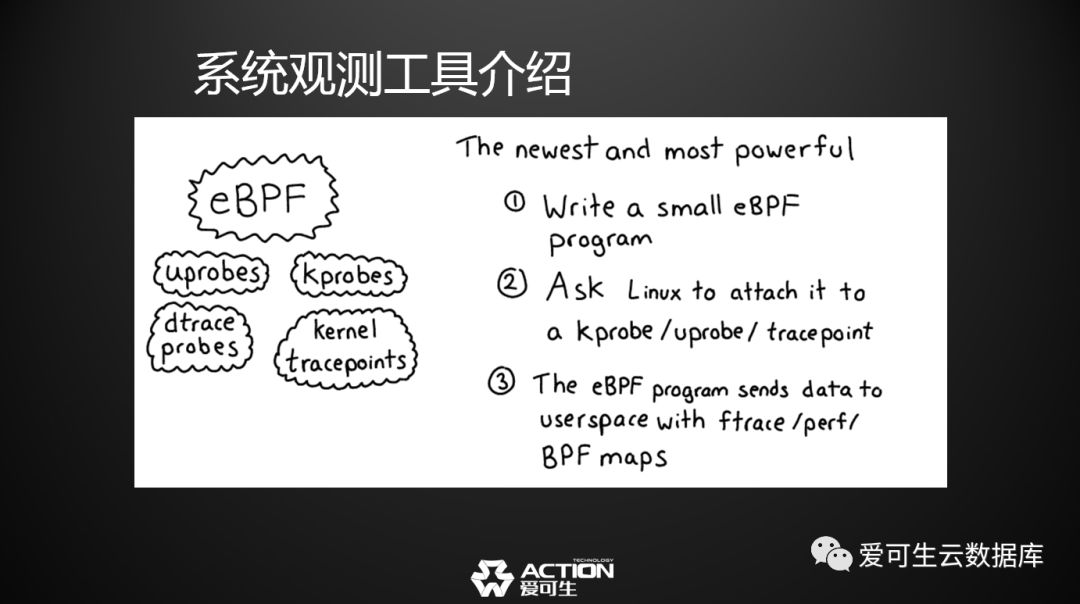
第三 ,eBPF是我们今天要重点介绍的,eBPF的方案,跟刚才两种方案不一样,刚才两种方案一种是操作系统提供的文件系统上的桩,一种是操作系统提供的系统调用,而eBPF是将一段代码直接插到操作系统内核某一个位置上的机制。
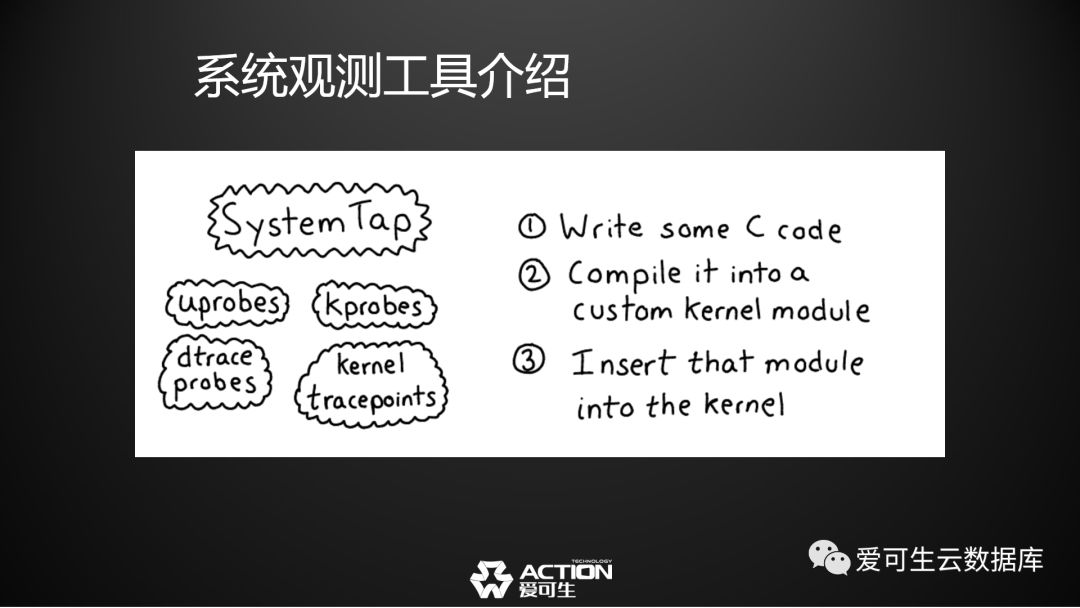
第四 ,Systemtap的原理是将一段C的代码编译成了一个内核的模块,然后将这个模块嵌到内核里边去,它不是由内核提供的一个机制,而是由内核的模块机制提供的一种功能。
这是四种观测工具的不同。
为什么要介绍这四种观测工具的不同,是因为大家在选取观测工具的时候就知道大概怎么选。
这四种观测工具里边对系统伤害最轻的是谁?
对系统伤害最轻的是系统调用,这是系统承诺出来的服务。然后是ftrace,这是系统在文件系统层面提供的一个口,告诉你可以通过这个口跟系统交互。
对系统侵入性最强的是谁?
对系统侵入性最强的应该是eBPF,因为它直接将一根代码嵌入到系统里边去做,最不稳定的应该是System Tap,因为它是系统的一个模块, 又提供了非常复杂的功能。
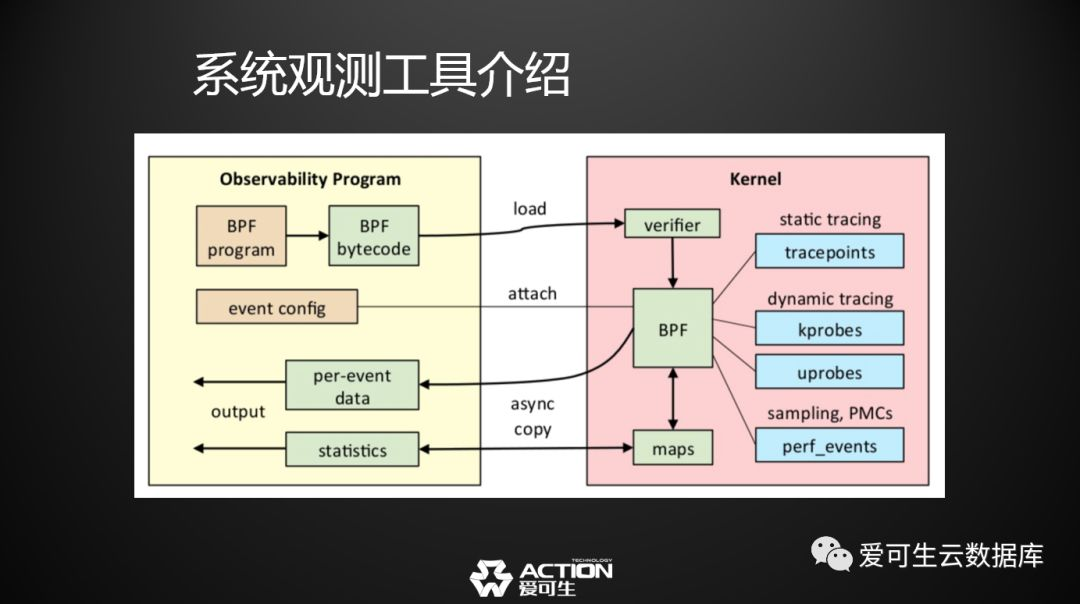
这张图是eBPF的架构图,eBPF先将一段程序编译成二进制代码,然后插到操作系统里边去,操作系统运行这段代码的时候,将采集到的数据吐到操作系统本身的一个空间里,然后再做统一返回,大概就是这样的一个结构。
eBPF这个结构,最核心的部分在于把代码插入到操作系统中运行,它需要做各种安全保护才能完成这一点,所以这也是这个机制复杂的地方。
3. bcc (eBPF脚本集) 使用举例
我们引用了一个开源的eBPF脚本集bcc, 快速看一下eBPF能做什么, 这些功能都是开箱即用。

第一个例子,MySQL的请求延迟分析 ,一个MySQL承担了很多业务,上千个并发在那儿,哪一个SQL最慢,到底有哪些SQL在一秒以上,除了slow log以外,还可以用这种方法来看。

这个命令的结果分为三列,它的第一列是请求的延迟,指数级递增,单位是微秒,中间一列是它的命中数,如果有一个请求命中了64-127微秒这个区间,命中数会加一,最后一列是它的分布图,它在同一个报告里提供了数值的方式和图的方式,大家很容易看到结果。
对于这台服务器来说,我下了一个select的性能压力,它大部分的请求集中于64到127微秒之间。这个数据库的性能可能还不错。

我们再来看另外一种压力,我下了一个select+insert的混合压力在一个数据库里,它的图又变了,它呈现了一个非常好的双峰图,我将两个峰值用另外一种颜色标明,这两个峰值的意思是很有可能有混合压力在一个数据库里,或者是上面的这部分压力是命中了某些缓存,而下面的某些压力是由于没有命中缓存,导致这部分请求更慢一些, 形成另一个峰值,所以大家通过这种峰值分析可以看到数据库大概的一个运行状态。
如果能做得更好,大家可以抽检自己的数据库然后做环比图,比如说今天和昨天同样的时间,同样的业务压力下对数据库的延迟进行分析,如果数据库的延迟峰一直在往后延,就意味着数据库的状态在变得更糟糕一些。这是bcc第一个能做的事情,需要再次强调的是它开箱即用直接下载过来就可以使用。

第二个例子,MySQL的慢查询 ,MySQL本身提供很好的慢查询,我干嘛要用另外一个机制来获取MySQL的慢查询呢?
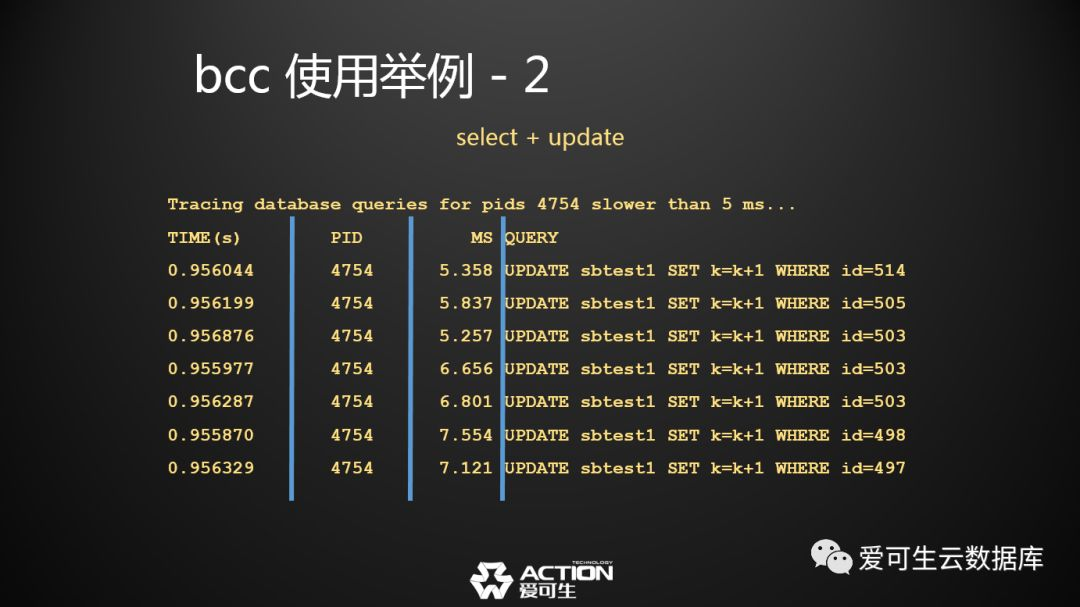
我们先看一下它的输出,其实跟MySQL本身的慢查询还要再简单一些。那么我们为什么要用另外一种方式来获取慢查询呢?

因为它能做到这些事情,而MySQL的慢查询可能很难做,与MySQL的慢日志相比, 它可以低成本地完成:
1. 获取少量慢查询
2. 获取某种模式的慢查询
3. 获取某个用户的慢查询
比如说获取少量的慢查询,为什么是少量呢?因为我们不确定现在的线上延迟是多少,慢查询只开一秒可能日志瞬间就被堆上去,性能就会下来,但是如果慢查询开个十秒左右,没有请求在这个区间命中,所以要一点一点的去调这个值,比如说线上1%的最慢的查询能够命中,但是在这个脚本里面,可以取一定区间的最大的几个查询把它拎出来。
通过脚本还可以命中某种模式的慢查询, 比如说我们只关心update的慢查询, 那么获取select的结果就没有太大的意义,或者是我一定要获取某一些特定表的相关的查询,我都可以通过脚本来做。
第三种情况我想获取某个用户的慢查询,这个一般对于多租户系统,因为多租户系统我只想针对某一个用户进行慢查询分析的时候,这种脚本就比较好用,这是我想说的第二个例子。
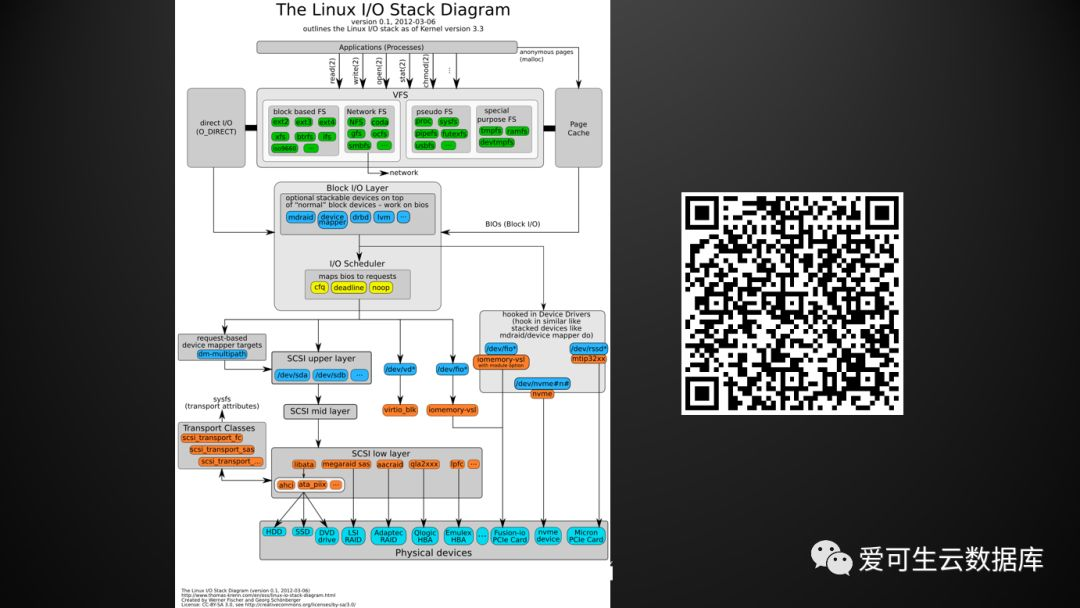
之后的几个例子都跟IO相关,所以我引用了另外一篇文档,这篇文档是Linux IO的堆栈图,右边是引用的二维码,这张堆栈图看起来很复杂,但这个其实是2012年画的第一版的IO堆栈图,现在IO堆栈图比这个要复杂很多,大家可以在这个网址上去体验一下。然后我们把其中的关键元素抽出来,我们看一下IO的堆栈大概是几个层次?

从MySQL开始,MySQL是运行在用户态中,它通过VFS层的接口,一个IO请求就下到内核态,然后从VFS转到真正的文件系统,之后IO请求会下到块设备层,在块设备层里边会经历IO的一个调度器,大家常见的MySQL的调优建议里面, 对于调度器的设置要么设成空要么设成deadline, 就是在这个位置起作用,最后通过SCSI接口, 将数据请求下到物理设备。

第三个例子,VFS延迟分析 ,我们对每一层都可以通过脚本对它进行IO分析,比如说我可以对VFS做延迟分析。

对VFS做延迟分析,这是对数据库进行了一个写压力,大家可以明显看到一个双峰图,这是写的两个峰,是数据库对于内核的写压力的反馈。
这个意味着什么呢?这个可能意味着因为这部分的写是命中了操作系统文件系统的缓存,而下面这部分写是真正的写穿到设备的,所以他们俩的延迟不一样,这是一个典型的双峰图,大家需要把两个峰拆开来去行这样的分析。
换一个说法,如果写压力都集中在这里,而没有第二个峰的情况下,需不需要去更换物理设备?有可能不需要,因为所有的东西都命中了操作系统的缓存。

第四个例子,Ext4 文件IO延迟分析 ,我们之前看到的图是以磁盘设备为维度的。
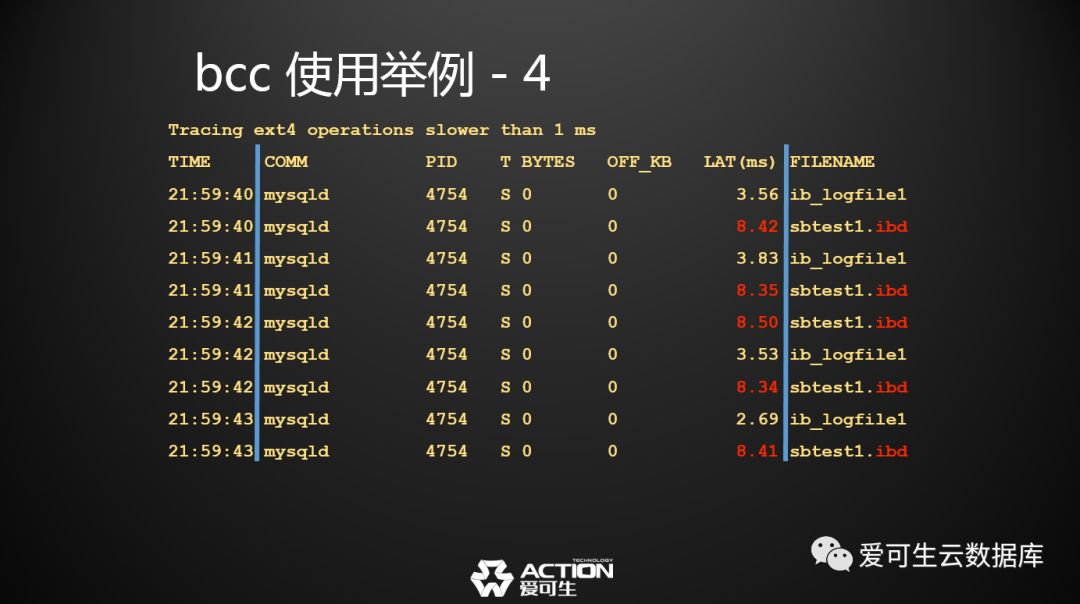
那么我能不能按照文件维度去看到底是哪个文件的IO慢,这个脚本可以直接做到。 我下了一个最简单的写压力到数据库上。
红色标明的地方比非红色的地方的数值都要高,而它的共性在于都是数据文件 ,而非红色的部分都是各类的日志文件,这就是大家常说的日志文件是顺序写的,数据文件是随机写的,顺序写比随机写快, 就在这个延迟上体现了,所以通过这种观测方式大家可以观测到各个文件的写压力的平均延迟大概在什么水平上。
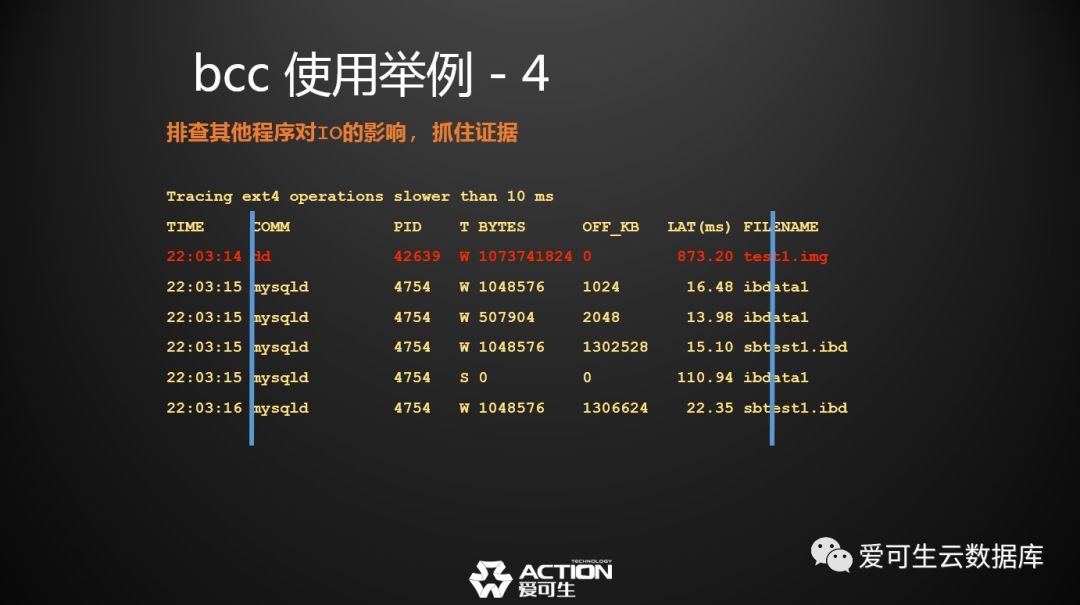
我用这个工具主要是用来抓住一些证据, 比如其他进程影响了数据库的IO。在这个地方故意用了DD,不是打车的滴滴,是写IO的DD,DD的IO压力就会被工具抓出来, 这就是铁的证据。这是我想介绍的第四个例子,它可以做基于文件的IO分析。

第五个例子,块设备的延迟分析 ,为什么要补充一个块设备的延迟分析呢?因为从刚才的这些延迟分析上,延迟都是带有操作系统缓存的影响的,而通过这个脚本可以看出真实下到设备上的延迟是多少。

这是一个下到设备上的压力的情况, 大部分的延迟在32微秒到64微秒之间,我也不知道这个设备是好还是不好,做IO压力的时候很难通过绝对值去判断这个事是好还是不好,大家需要通过环比得出正确的结论。

这张双峰图, 是我的同事做出来的,他问我说这是个典型的双峰图,是不是IO出了问题设备出了问题,一组IO比另一组IO的延迟明显要高。
那这个图到底有没有问题呢?这个图没有什么太大的问题,因为它的count很小。它真实的select下在到设备上的读只有五个请求,这五个请求里边明显有三个比其它的两个延迟要高一些,这个事儿不值得分析。大部分的请求全部都被InnoDB的buffer和操作系统的Cache全部都hold住了,所以这个事情是不值得分析的,大家通过这个图也可以完成刚才“需不需要更换设备, 更换设备以后MySQL会不会变得更快”的问题,在如图的情况下应该不会。

第六个例子,MySQL线程对文件的IO压力汇总 ,我们看了刚才基于设备的、基于全局文件的IO压力分析,我想知道MySQL到底哪一根线程对IO造成了压力,是InnoDB负责刷数据的哪根线程,还是正在导数据的线程。
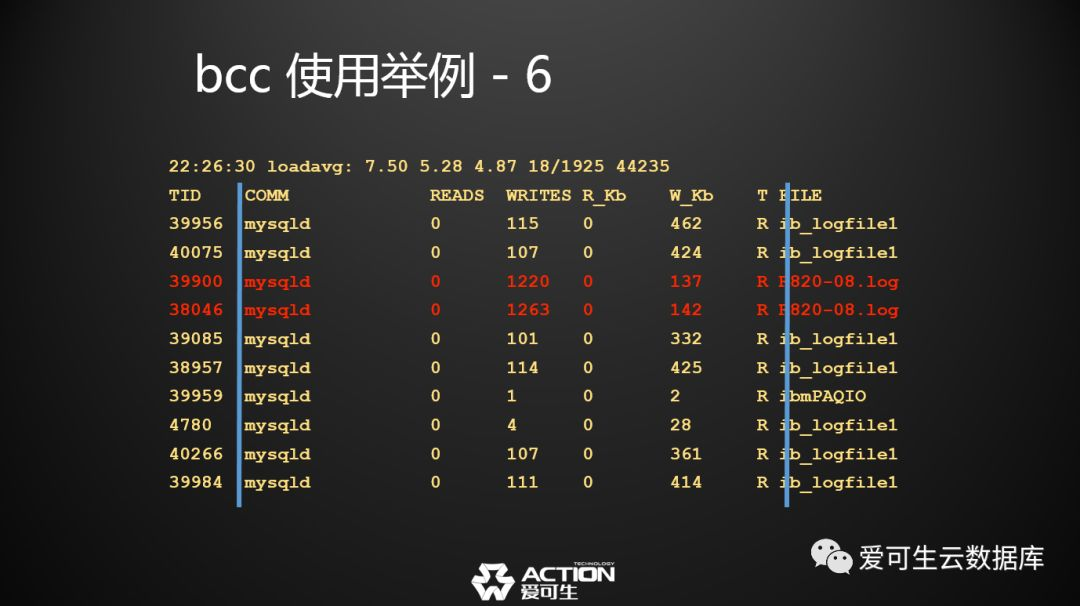
这个脚本可以帮大家做到这个事情,看看这个脚本的输出结果是这样的,它最左边一列是TID,是线程号,最右边一列是文件,中间部分是它写的大小。在这样的一个数据库上,大家可以明显看到这个数据库出了什么问题。
即使没有my.cnf的内容也能知道这个数据库出了什么问题,它的问题可能在于开启了general log。这个是基于线程的,所以大家只要找到这两根线程, 就能知道这两根线程是哪个业务下来的,这两根线程的SQL可能异常多, 所以general log一直在刷日志,刷成了现在这样子。这个是基于线程,并且基于文件的对IO的分析。

第七个例子,短生命周期的临时文件检测 ,这个大家不一定常见,MySQL会在某些情况下动用临时表, 如果SQL没写好就会创建临时表,这些临时表的生命周期很短,但是量很大,所以一定要写文件而不能内存里。
在这种情况下会对操作系统造成一些压力,而这个压力又不太好诊断,是因为临时文件的生存周期短,所以这个脚本可以帮大家提供这样的一个方案,这个方案的结果大概是这样子。

我做了一个临时表,这个临时表活了5.3秒左右,于是它展现在了脚本的结果里。如果大家扫描自己的线上MySQL发现这里有大量的东西说明在大量的使用临时表,如果IO压力在此时比较大, 就可能受了临时表的影响。

第八个例子,短连接分析 ,好一点的应用都会用连接池,但是我们很多的时候没有那么好的运气,老碰到那么好的应用,所以经常业务会扔过来大量的短连接。

这个例子中, sysbench上了一个大并发,但是只活了300多毫秒,这些连接都只活了300多毫秒,反复运行这个sysbench就可以将数据库打死,建立一千个连接,300毫秒以后也会销毁,再建立一千个连接,你的业务就会忽上忽下,通过这个脚本就可以抓到这个压力从哪个服务器来的,哪个端口来的,然后把它搞定就可以了,这是数据库的短连接分析。

第九个例子,长连接分析 ,除了短连接分析,还有长连接分析,哪一个业务端老在搞我的数据,老在往里写,总在往里读,搞的网络特别慢。

这个就可以帮大家提供这样的一个视角,这个就是长连接分析。它有读有写,都在这里,这是第九个脚本。

第十个例子,CPU offcpu 消耗分析 。看看最后一个脚本,这个我需要介绍一下背景,什么叫offcpu,什么叫消耗分析,以及最终形成的图大概是什么样子。
为什么我们要对CPU的offcpu进行分析呢?
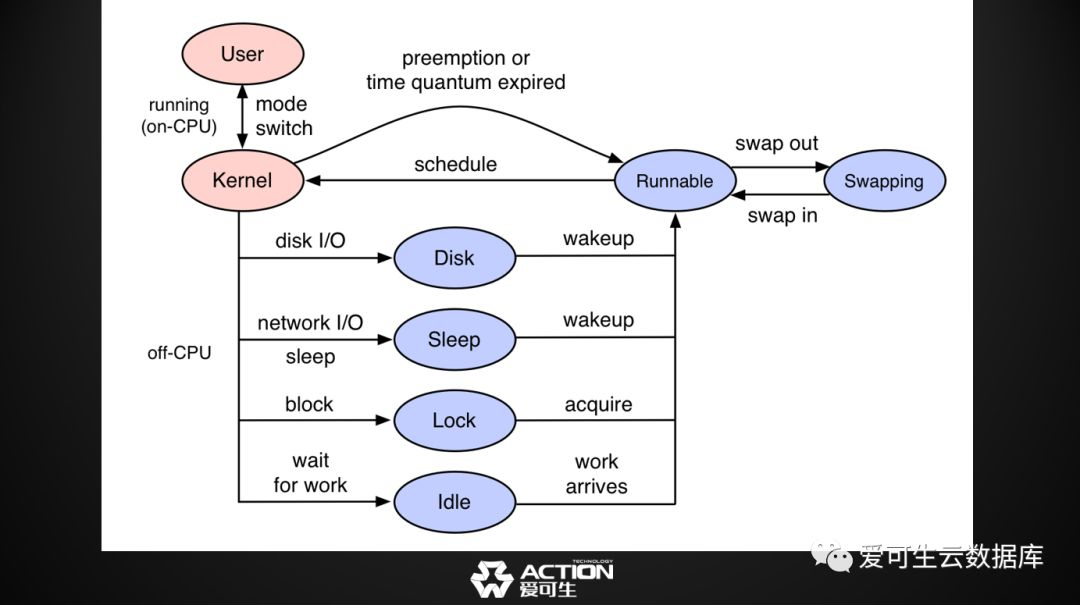
因为正常的情况下CPU的工作过程是这样子的,MySQL运行在操作系统的用户态。序运行过程中会切入到内核态, 比如说程序进行了系统调用,比较好的情况是程序可以一直占着cpu,所以它一直都会在运行中,如果不太好的情况,比如说遇到了磁盘的IO,网络的IO,主动的睡眠,一些锁的阻塞,它就会陷入不占用CPU的情况,把CPU放弃了,然后让给了其它线程。
但是这个时候是不是意味着数据库工作良好?如果大家对MySQL只做onCPU的分析,这个阶段onCPU是0,不占CPU,但是因为IO是阻塞的,我想知道到底是因为什么阻塞在这,这个就叫offcpu的分析,就是MySQL从内核态开始把CPU让出来,开始下台的时候,我想知道它为什么下台,以及下台持续了多久,然后来进行这样的分析。

它最后的输出结果是这样的一个图,这个图叫火焰图并且这是一个冷火焰图,它的是offcpu的,大家常见的火焰图是火焰图, 是红色的, 指的是oncpu的分析。我们特意把它做成了冷色的,这是offcpu的火焰图,很显然没有任何一个人能读得懂上面写的到底是什么。所以我来介绍一下什么叫火焰图,火焰图是这样一个过程。
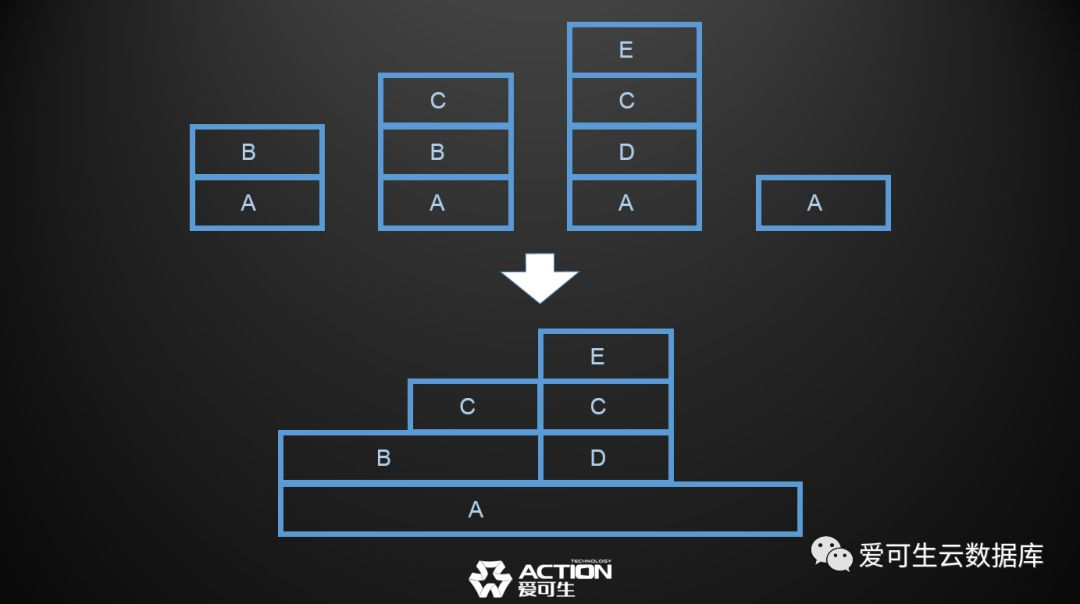
比如说对数据库进行采样,进行采样的过程中,采了四个样,这四个样这个地方代表数据库的运行堆栈,然后它的运行堆栈是这样子,这样四个运行堆栈,然后在火焰图上他们就会被合并成这样子,他们四个都涉及到第一个调用是A,所以它会把A合并在一起,第二个调用有两个是B,把B合并在一起,最后大家看到的就是这样一个图,这个图变大以后,就会长成像一个火焰的样子,所以它就是Flame Graph。
这个是火焰图是怎么形成的,它是通过采样,然后把采样合并成一张图,然后大家在这个图上能获得什么信息,获得的信息是程序的入口可能是A,因为所有的采样都过了A,其中B独立运行占了四分之一的时间,B之上C占了四分之一的时间,大家就能从这个图上快速的读出这个事情。
所以如果对这个程序要进行调优的话,大家会调到哪里,从哪里下手调优最直接方便?B独立运行了四分之一,C独立运行了四分之一,E独立运行四分之一,我们唯一知道的是调优D是没有用的,因为D所有的时间都被E占用了,所以调优D不管怎么调它自己的时间是没有占用的,这个就是火焰图的基本原理。

我们来看一个例子,这个例子是我从刚才的那个图上截出来的,这是offCPU分析中的一部分,它占了刚才那张图差不多25%的左右的大小,这个堆站从下往上读,最下面这个大家能读懂吧,innobase:index_read, 表示引擎在读索引树。然后往上读,不知道什么意思,mvcc不知道什么意思,无所谓,再往上读,Btr_...to_nth_level, 表示在读索引数的第n层,再往上读,我buffer上面开了一个页,它开始读页了,然后这个地方涉及到了fil_io, 为了读取这个页我开始读文件了,然后上面do_syscall_...进行了系统调用,然后到了VFS开始真实的进行这个系统调用。
如果这个堆栈出现在整个MySQL堆栈的25%,意味着什么呢?意味着MySQL花了25%的时间来读页,来从文件系统里边把这个页读出来,这个页是干什么用的?这个页是在索引中的,就即使不懂代码,读这些英文,大概也能分析出如果把磁盘换掉,或者是把buffer pool扩大,扩得非常大,然后开始加内存,最好的条件下能让这个数据库变快25%,可能能够把这个堆栈整个消掉,这个就是火焰图带给大家的IO分析的方法。
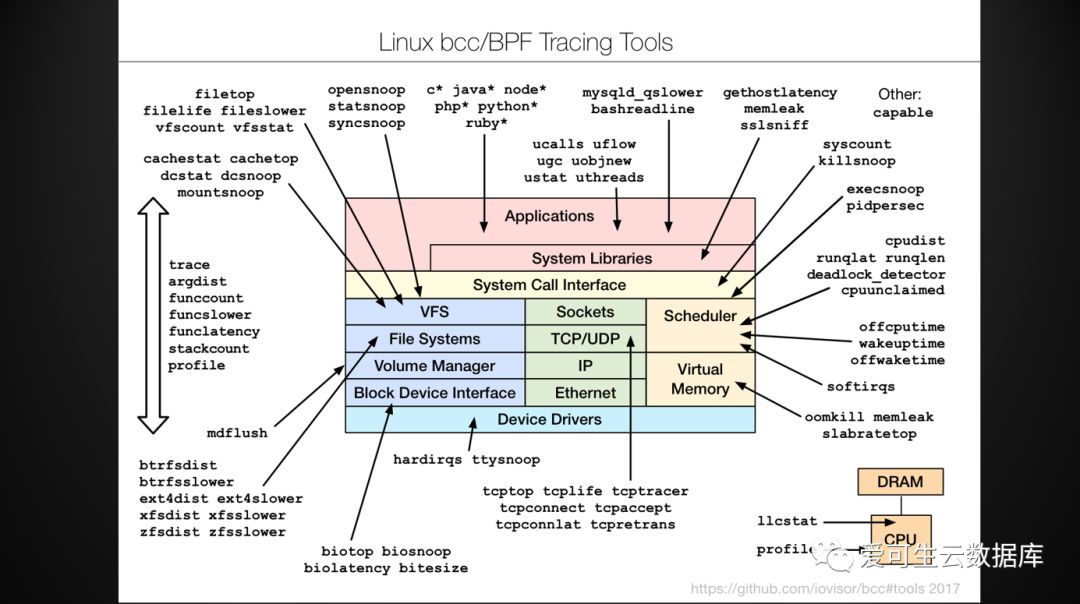
刚才我们介绍了十个bcc相关的例子,这些例子都是现成的脚本,bcc这个工具能向大家提供的是一整套,可以观测这个操作系统的各个方面,比如说如果有东西被OOM kill掉了,然后内存有泄露的也可以看,然后这边有N多的其他的部分,这个基本上是我们这几年发现的一个宝库,大家直接调用这些脚本就可以完成很多的别人完成不了的分析,它的技术用的是eBPF,就是我们刚才介绍的系统观测工具。大家直接在github上直接搜就行了。
4.eBPF 使用方法/限制
如果这里边脚本满足不了要求, 那我们可以自己写。这里我们介绍一下脚本的写法以及eBPF的限制。

我们拿刚才MySQL延迟分析举例,一个MySQL上面有一千个query,这些query大概都落在哪个延迟时间里面那张图,为了完成这个需求, 我需要写两段程序,其中第一段程序是运行在内核里边的程序。
这段程序的逻辑是这样的,先在query开始的时候截获一下,让它记录一个时间戳,然后请求结束的时候再截获一下记录一个时间戳,然后把两个时间戳相减获得一个延迟,然后把这个延迟扔到结果集里边去,程序就完成了,正常思路吧。我用结束时间减开始时间,减一下得到一个延迟,然后把延迟扔到一个统计容器里面,这个事就结束了。这是我要写的第一个程序,是嵌到内核里的程序,但是需要一个外壳的程序负责嵌入。

这个外壳程序的逻辑也非常简单,把刚才那段内核的程序嵌到MySQL的观测点上,嵌到内核里面去,然后把结果集拿出来,打印出来就结束了,这是如何写一个eBPF的脚本,大家唯一需要做的事情就是这两个程序,然后运行一下。

这个程序有多长呢?这个程序就这么长,45行,但是我中间忽略了一些部分,这些部分是负责差错处理,它的核心就是这45行,然后大家只需要把现在的脚本拿下来抄一抄,改一改就可以完成很多的功能了。
我们来聊聊限制,这么好的方法为什么很多人不知道呢?

操作系统内核的限制,这个功能是Linux 4.4引进来的,但是在Linux 4.4上存在统计的bug,如果大家用那张分布图的话,会看到这个图上数不太对,我们推荐的是Linux 4.9+,部分好用的功能是在4.13+上才开放,这个是eBPF最大的限制。怎么办呢?只能祝大家长寿吧!活到Linux 4.x内核能在生产环境上使用的那一天。
它的第二个最大的限制是MySQL的编译参数,MySQL虽然在很早很早的时候,已经提供了dtrace的观测点,这些观测点是公用的,但是它在默认的编译出来的官方发布的包里边是不带观测点编译的,所以在直接官方发布的二进制的包里边是用不了这个功能的,大家需要自己编译一下。编译的时候需要带这个参数,这个可能也是属于一个比较大的限制。
所以如果大家受到限制,我们推荐换一个工具,systemtap 。

Linux 2.6就已经有了,但是我刚才说过,它的机制是写一个内核模块,这种机制其实不是特别稳定,它为了解决不是特别稳定的问题增加了若干限制,比如说能在内核中使用的内存大小有限制,采集频率也有限制,对整个内核的性能的影响的百分比也有限制,在这些限制参数都开起来的情况下,它还是比较安全的。
但是很多观测功能比如说offCPU的火焰图,就必须要把这些限制关掉,一旦关掉内核就不是很稳定,所以这个工具,我没有敢把它的缺点写在上面因为确实是个好的工具,我们也很难说它的这个缺点是个致命的缺陷,但是不太推荐在生产环境上使用,但是在测试环境上确实是非常好玩的一个工具,如果大家用不了eBPF的话可以用systemtap来做一些诊断。这是跟限制相关的部分。

然后有systemtap,有eBPF,大家就想知道有没有其它的选择的部分,这个图也是我偷来的,都是羊驼,就有这么多工具,大家可以去选择它。
至于怎么选择的话,大家直接谷歌一下有专门的文章教大家怎么来选择这些观测工具,但是总的来说没有一个科学的思路,就是尝试,不停的尝试。

推荐一本书,所有的这次演讲里知识的来源都来源于这本书,我们刚才说的bcc的脚本集的作者,这是他写的书,他还做了很多神一样的事情,强烈推荐给大家,这本书很早中文版就出版了,但是好像很多人读过的人不是很多。
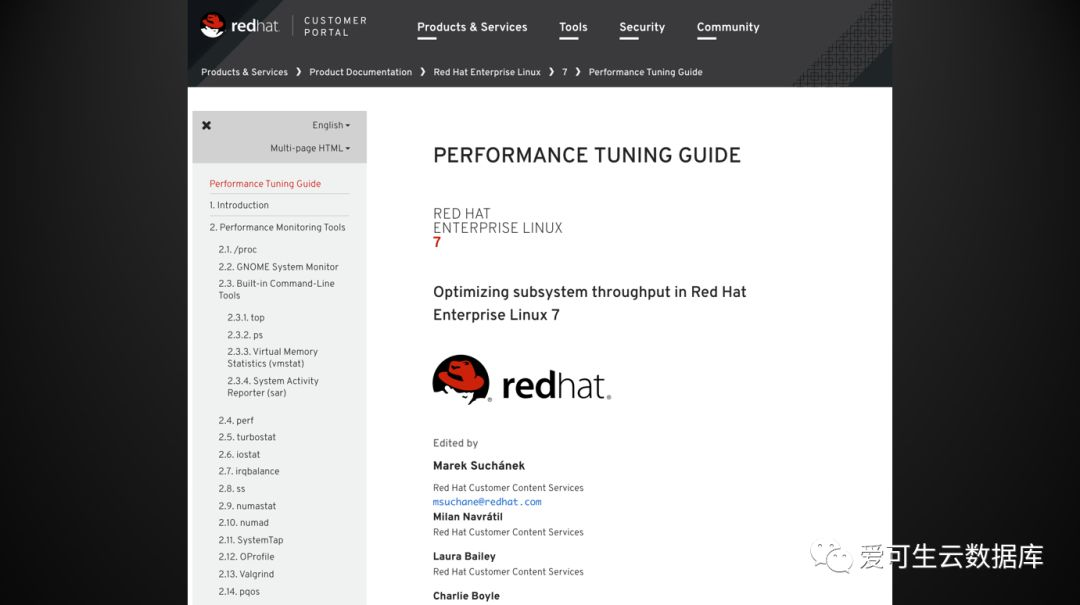
除了中文版的书之外,再推荐一个文档,这篇文档是红帽的官方文档,不需要红帽企业的会员,免费可以读,叫:Performance Tuning Guide,它在第二节介绍了操作系统各种可以用的观测工具,覆盖了我们的第一部分所说的所有的外部观测工具,以及我们在中间所说的系统观测工具,都在这上面。但是我不太喜欢这个文档的原因是因为它很少有原理分析,而都是在说这边有一个参数可以调,那边有一个参数可以调,如果大家想获取这部分的知识的话,这篇文档的质量也是异常的高,红帽我一直觉得是一个卖文档顺便卖操作系统的公司。
我今天的所有的内容都已经呈现完了,谢谢!
PPT下载链接:
github.com/actiontech/slides
