

序言
- 本文章主要以黑马程序员的「传智播客 Python 就业班 (ij6g)」、「 Python 从入门到精通教程 」和「 廖雪峰的 Python 教程 」为主线,输出学习笔记,目的是检验自己的学习效果和日常复习之需。
- 本文章也可作为入门 Python 的参考资料,除了视频的基础内容外,文章还会补充视频中讲解不详细或遗漏的必要知识点。
- 文章的内容和知识框架,与「廖雪峰的 Python 教程」和「传智播客的视频」大体保持一致:
- 分模块阐述:
Linux 基础、Python 基础、Python 面向对象、项目实战( 实战部分以爬虫、数据分析为主的项目实战 )。 - 每个模块又按知识点区分:
- Linux 基础部分参考:
传智播客 Python 从入门到精通教程; - Python 基础部分参考:
廖雪峰 Python 教程; - 项目实践,即数据分析部分参考书籍:
利用 Python 进行数据分析[ 5 ] " role="presentation" style="position: relative;">;
- Linux 基础部分参考:
- 分模块阐述:
-
最后,引用 Bruce Eckel 的原话作为开篇,期待您早日加入 Python 队伍中来。
Life is short, you need python.
更新进度
- 2018.09.03:完成初稿,且完成 Linux 基础部分的内容;
- 2018.09.18:更新 Python 基础部分内容 ( 语言基础、函数、高级特性 );
- 2018.09.21:更新 Python 基础部分内容 ( 函数式编程 );
参考书目
Python 基础Python 进阶Python 实践
教学资源
- 文章 | 廖雪峰. Python 3 教程. liaoxuefeng.com
- 视频 | 黑马程序员. Python 从入门到精通教程. 2017. bilibili.com
-
视频 | 传智播客. Python 就业班. 2017. BaiduCloud | Pwd: ij6g
本框架的学习笔记是基于此系列教学视频所得的。
Linux 基础
Linux 常用终端命令
仅列举一些项目中常用的命令。
-
LS 命令与通配符
*:代表任意个数个字符。?:代表任意一个字符。[]:表示可匹配字符组中任意一个。[abc]:匹配 a、b、c 中的任意一个字符。-
[a-f]:匹配从 a 到 f 范围内的任意一个字符。常使用
ls -al显示当前文件目录所有文件的详细信息。
-
CD 命令与切换目录
- 相对路径:最前面不是
/或~,表示相对当前目录所在的目录位置。 -
绝对路径:最前面是
/或~,表示从根目录 / Home 目录开始的具体目录位置。# 相对路径:返回上两级目录 cd ../../ # 绝对路径:相当于 cd /Users/your username/ cd ~
- 相对路径:最前面不是
-
Tree 命令:以树状结构显示文件目录结构,若
tree -d则显示目录,不显示文件。 -
查看文件内容
cat 文件名:查看文件内容、创建文件、文件合并、追加文件内容等功能。more 文件名:分屏显示文件内容。grep 搜索文本的文件名:搜索文件文件内容。- 例如搜索包含单词 “hello” 的文本,即
grep "hello" sample.txt。 - 选项参数:
-n显示匹配行号;-v显示不包含匹配文本的所有行;-i忽略大小写。
- 例如搜索包含单词 “hello” 的文本,即
-
Echo 命令与重定向
echo命令:在终端中显示参数指定的文字。- 重定向
>和>>:>表示输出,会覆盖文件原有内容。>>表示追加,会将内容追加到已有文件的末尾。
-
echo命令常结合重定向使用:# 将字符串 "Hello World" 追加到 echo "Hello World" >> sample.txt
-
管道符
|- Linux 允许将一个命令的输出通过管道作为另一个命令的输入。
-
ls 命令与 grep 命令的结合使用,如从 Home 目录下搜索包含 “python” 关键字的文件或者文件夹:
# 从 Home 目录下搜索包含 "python" 关键字的文件或者文件夹 ls -al ~ | grep python
-
Ifconfig 命令与 Ping 命令
ifconfig命令可查看/配置计算机当前的网卡配置。-
ping命令一般用于检测当前计算机到目标计算机之间的网络是否畅通。# 快速查看网卡对应的 IP 地址 ifconfig | grep inet
远程登录和复制文件
远程登录
- 远程登录即通过
SSH 客户端链接运行了SSH 服务器的远程机器上。 - SSH 是目前较可靠,专为
远程登录会话和其他网络服务提供安全性协议。- 有效防止远程管理过程中的信息泄露。
- 对所有传输的数据进行加密,也能防止 DNS 欺骗和 IP 欺骗。
- SSH 客户端是一种使用
Secure Shell协议连接到远程计算机的软件程序。 - SSH 客户端简单使用访问服务器:
ssh [-p port] user@remoteuser是远程机器上的用户名。remote是远程机器地址,可为 IP、域名或别名。port是 SSH 服务器监听的端口,若不指定端口默认为 22。
复制文件
-
SCP 即
Secure Copy,是一个在 Linux 下用来进行远程拷贝文件的命令。# 从本地复制文件到远程机器桌面上 scp -P sample.py user@remote:Desktop/sample.py # 从远程机器桌面上复制文件夹到本地上 scp -P port -r user@remote:Desktop/sample ~/Desktop/sample
SSH 高级用法
免密码登录
免密码登录:即客户端访问服务端时,需要密码验证身份登录。
- Step.01. 配置公钥:执行
ssh-keygen即生成 SSH 密钥。 -
Step.02. 上次共钥到服务器:执行
ssh-copy-id -p port user@remote,让远程服务器记住我们的公钥。1) 有关 SSH 配置信息都保存在
/Home/yousr username/.ssh目录下。
2) 免密登录使用的是非对称加密算法 ( RSA ),即使用公钥加密的数据,需要使用私钥解密;使用私钥加密的数据,需要使用公钥解密。若有兴趣了解RSA 算法的原理及计算,可参考引用文章 [1]、[2]。
图 4-1 免密码登录实现原理图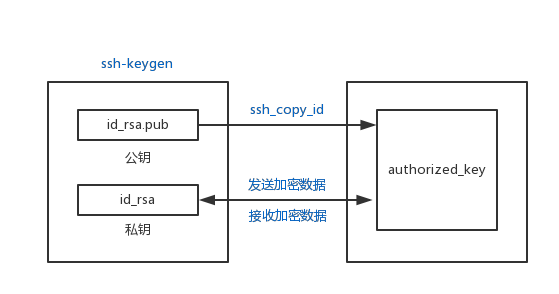
配置别名
配置别名:每次输入 ssh -p port user@remote 是非常繁琐重复的工作,配置别名的方式以替代上述这么一串命令代码。
-
在
/.ssh/config文件下追加以下内容 ( 需建立 Config 文件 ):Host mac HostName 192.168.10.1 User user Port 22
-
命令输入
ssh mac即可实现远程登录操作 ( SCP 同样原理 )。scp -P 22 -r ~/Desktop/Sample mac:Desktop/Sample
用户和权限
基本概念
- 在 Linux 中,可指定每一用户针对不同的文件或者目录的不同权限。
- 对文件 / 目录包含的权限有:
| 权限 | 英文 | 缩写 | 数字代号 |
|---|---|---|---|
| 读 | read | r | 4 |
| 写 | write | w | 2 |
| 执行 | excute | x | 1 |
组
- 为方便用户管理,提出组的概念。在实际开发中,可预先针对组设置好权限,然后将不同的用户添加到对应组中,从而不用依次为每个用户设置权限。
LL 命令
- LL 命令即 LS 命令的扩展用法
ls -al。 - LL 命令可查看文件夹下文件的详细信息,从左往右依次是:
- 权限:第一个字符是
d,表示目录;-表示文件; - 硬链接数:通俗理解即有多少种方式可访问到当前目录 / 文件;
- 拥有者:当前用户;
- 组:当前用户所属的组;
- 文件大小,修改时间,文件 / 目录名称.
- 权限:第一个字符是
| 目录 | 拥有者权限 | 组权限 | 其他用户权限 | 备注 |
|---|---|---|---|---|
| - | r w - | r w - | r - - | 文件权限示例 |
| d | r w x | r w x | r - x | 目录权限示例 |
Chmod 命令
-
Chmod 命令:可修改
用户/组对文件/目录的权限。# 一次性修改拥有者/组的权限 chmod +/-rwx 文件名/目录名
Sudo 命令
-
Sudo 命令:使用预设 ( root, 系统管理员 ) 的身份来执行命令。
Linux 系统中,通常使用标准用户登录及使用系统,通常
sudo命令临时获得权限用于系统的维护与和管理。
系统信息相关命令
- 查询时间和日期
date:查看系统时间。cal:查看当月日历,cal -y查看当年的日历。
- 磁盘和目录空间
- df:
df -h,Disk Free 显示磁盘剩余空间。 - du:
du -h,Disk Usage 显示目录下的文件大小。
- df:
-
进程信息
- ps:
ps aux,即 Process Status,查看进程的详细状况。 - top:动态显示运行中的进程并排序。
-
kill:
kill [-9] 进程代号,-9表示强行终止,终止指定代号的进程。使用
kill命令时,最好终止当前用户开启的进程,而不是终止root身份开启的进程。
- ps:
其他终端命令
查找文件
查找文件:find 命令功能非常强大,通常在特定目录下搜索符合条件的文件。
- 若省略路径,表示在当前文件夹下查找。
-
find命令可结合通配符一起使用。find [路径] -name "*.py"
软链接
软链接:建立文件的软链接,通俗理解即 PC/MacOS 上的 快捷方式。
- 源文件要使用绝对路径,即便于移动链接文件 (快捷方式) 仍能正常使用。
-
没有
-s选项是建立一个硬链接文件。ln -s 被链接的源文件 快捷方式的名称
-
在 Linux 中,文件名和文件的数据是分开储存的。
图 4-2 软、硬链接访问文件数据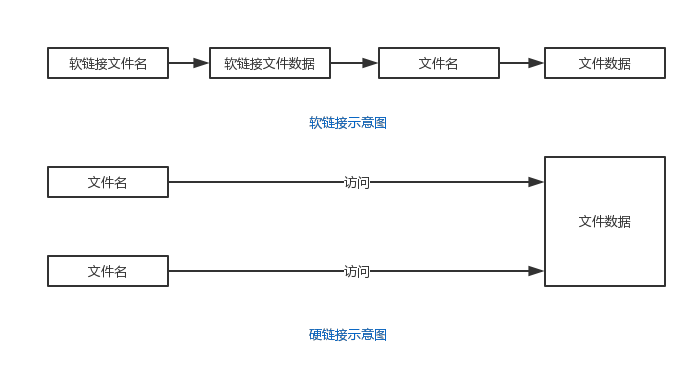
打包压缩
-
tar是 Linux 中最常用的备份工具 ( 打包并不压缩 ),其命令格式如下:# 选项 c:生成档案文件 (.tar) # 选项 x:解开档案文件 # 选项 v:列出归档/解档的详细过程,显示进程 # 选项 f:指定档案文件名称,选项 f 后应该紧跟 .tar 文件 # 打包文件:打包放于同一目录下 tar -cvf 打包文件.tar. 被打包文件路径 # 解包文件 tar - xvf 打包文件 [-C 目标路径]
-
tar与gzip命令结合可实现文件打包和压缩,即tar只负责打包文件,gzip负责压缩文件。# 压缩文件:压缩文件放于同一目录下 tar - zcvf 打包文件.tar.gz 被压缩文件路径 # 解压缩文件 tar -zxvf 打包文件.tar.gz # 解压缩文件到指定路径 tar -zxvf 打包文件.tar.gz [-C 目标路径]
Python 基础
引入
Python 优缺点
- Python 是面向对象 / 过程的语言 ( 对象和过程语言各有自己的优缺点 ):
- 面向对象:由
数据和功能组合而成的对象构建而成的程序。 - 面向过程:由
过程或仅仅是可重用代码构建起来的程序。
- 面向对象:由
Python 应用场景
- Web 端程序:
- mod_wsgi 模块:Apache 可运行用 Python 编写 Web 程序。
- 常见 Web 框架:Django、TurboGears、Web2py、Zope 等。
- 操作系统管理:服务器运维的自动化脚本。
- 科学计算:NumPy、SciPy、Matplotlib 等。
- 桌面端程序:PyQt、PySide、wxPython、PyGTK 等。
- 服务端程序:Twisted ( 支持异步网络编程和多数标准的网络协议,包括客户端和服务端 )。
Python 解释器
-
当我们编写 Python 代码时,我们得到的是一个包含 Python 代码的以
.py为扩展名的文本文件。要运行代码,就需要 Python 解释器去执行xxx.py文件。 -
CPython
- 当我们从 Python 官方网站下载 并安装好 Python 3.x 后,我们就直接获得了一个官方版本的解释器:
CPython( C 语言开发的 )。 - 在命令行下运行
python就是启动 CPython 解释器。
- 当我们从 Python 官方网站下载 并安装好 Python 3.x 后,我们就直接获得了一个官方版本的解释器:
-
iPython
- iPython 是基于 CPython 之上的一个交互式解释器,即 iPython 只是在交互方式上有所增强,但是执行 Python 代码的功能和 CPython 是完全一样的。
- 在命令行下运行
ipython即可启动 iPython 交互式解释器。 -
CPython 用
>>>作为提示符,而 IPython 用In [序号]:作为提示符。
图 5-1 Python 与 iPython 提示符表现形式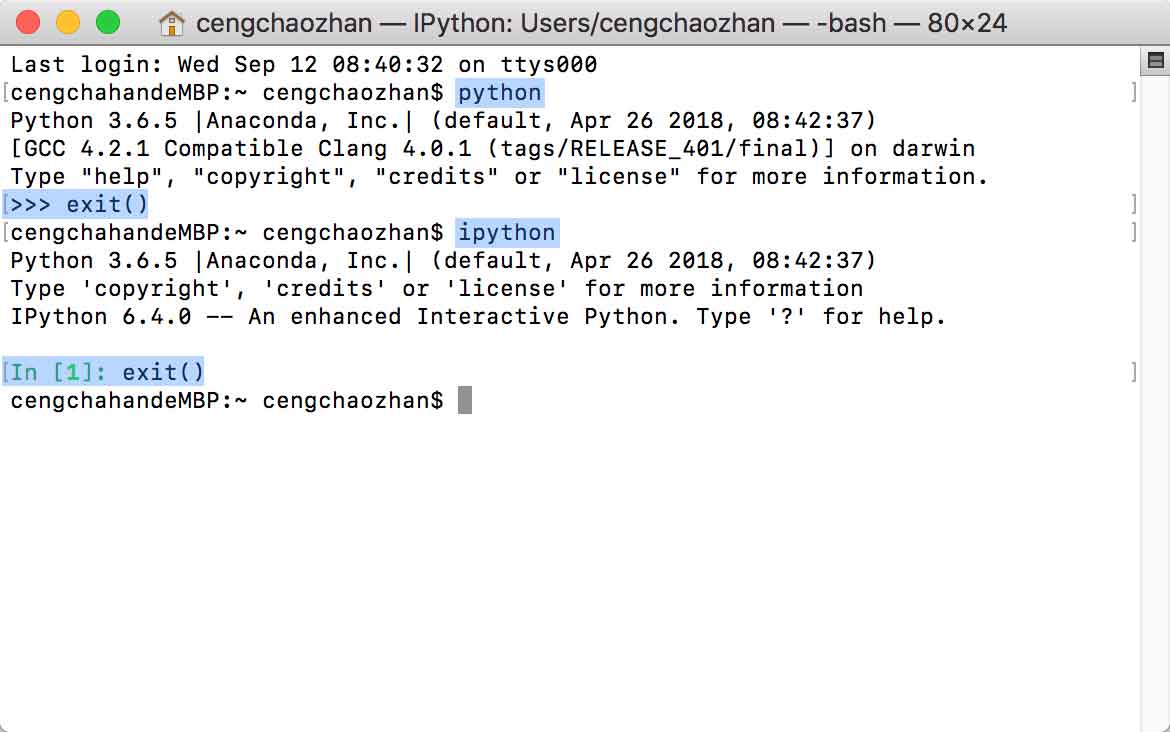
-
PyCharm
工欲善其事,必先利其器。为帮助开发者更便捷、更高效来开发 Python 程序,一款集成开发编辑器 ( IDE ) 显得格外重要。IDE 除了快捷键、插件外,重要的是它还支持
调试程序。当然,支持 Python 程序开发的 IDE 还有很多优秀的产品:如:Eclipse with PyDev
第一个程序
-
新建并运行 python 程序:
vi python_sample.py # === python_sample.py 内输入的内容 start === # === 声明部分 === # 取机器 Path 中指定的第一个 python 来执行脚本 #!/usr/bin/env python # python.py 文件中包含中文字符,Python2 在文件头加入以下语句 ( Python3 是默认支持的 ): # -*- coding=utf-8 -*- # === 代码部分 === print("Life is short, you need python.") # === python_sample.py 内输入的内容 end === python python_sample.py -
以一段简单代码演示:
#!/usr/bin/env python # -*- coding=utf-8 -*- a = 100 A = 200 if a >= 100: # 冒号 ":" 结尾,缩进的语句即为代码块 print(a) else: print(-A) # Python 是大小写敏感的
语言基础
注释
-
行注释、块注释:行注释的风格与 Linux 中 Shell 脚本的注释相同,即以
#开头的注释;块注释使用单、双引号实现。# 行注释 # line 1... # line 2... ''' 单引号块注释 line 1 line 2 ''' """ 双引号块注释 line 1 line 2 """
数据类型
整型:可处理任意大小的整数,当然包括负整数。例如 0,1,100,-8080 等。-
浮点型:即含有小数点的数,如 1.23,1.23e9 ( 1.23x10 9 " role="presentation" style="position: relative;">),1.23e-5 ( 1.23x10 − 5 " role="presentation" style="position: relative;">
)
1) 整数和浮点数在计算机内部存储的方式是不同的;
2) 整数运算永远是精确的,而浮点数运算则可能会有四舍五入的误差。 -
字符型:以单引号'或双引号"( 表示方式不同而已 ) 括起来的任意文本。例如'(1+2)\%3 == 0',或者"The 'a' is a lowercase letter of 'A'"。 布尔型:True / Flase 两种值。- 布尔运算:and、or、not,例如
(3 > 2) and (1 > 2),输出 Flase。
- 布尔运算:and、or、not,例如
空值:None,注意 None 不能理解为 0,因为 0 是有意义的,而 None 是一个特殊的空值。
Python 中的数据类型是没有大小限制的,若想定义无限大,可定义为无限大,即
inf。
常量变量
常量
- 常量:例如定义
PI = 3.14159,其实际也是变量,只是约定俗成罢了。
变量
- 形如
param = value的形式赋予变量值,但不用赋变量数据类型。 -
变量的输入与输出:
high = int( input(Please enter your high:) ) # input() 默认输出 String 类型 print("Your high is: %d" % high);
字符编码
- 一个字节,表示的最大的整数就是 255,即十进制为 255,二进制为
11111111。若想表示更大的整数则需要更多的字节。 -
ASCII:127 个字符编码,即大小写字母、数字和一些特殊字符。例如大些字母 A,对应的 ASCII 为 65。但处理中文显然一个字节是不够的 ( 至少两个字节 ),且还不能与 ASCII 编码冲突,所以中国制定了
GB2312编码。然而,世界有上百种语言,日本把日文编到
Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode 应运而生 [ 3 ] " role="presentation" style="position: relative;">
。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
-
Unicode:2 字节及以上。为节约空间,把 Unicode 编码转化为“可变长编码”的 UTF-8 编码。
-
UTF-8:根据数字大小编写 1 ~ 6 字节,英文字母 1 字节,汉字 3 字节 ( 生僻字符用到 4 ~ 6 字节 )。 -
ACSII、Unicode 与 UTF-8 的关系
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 0100 0001 | 00000000 01000001 | 01000001 |
| 中 | — | 01001110 00101101 | 11100100 10111000 1010 1101 |
-
启示:计算机系统通用的字符编码工作方式,如图 5-2 所示。
- 用记事本编辑的时,从文件读取的 UTF-8 字符被转换为 Unicode 字符到内存里,当保存的时再把 Unicode 转换为 UTF-8 保存到文件;
-
浏览网页时,服务器会把动态生成的 Unicode 内容转换为 UTF-8 再传输到浏览器。
图 5-2 计算机系统通用的字符编码工作方式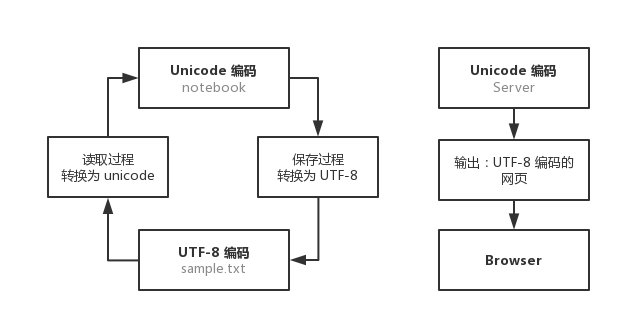
字符串/列表/元组/字典
字符串 Str
-
Python 3 中,字符串是以 Unicode 编码的。
- Python 的字符串类型为 String,内存中以 Unicode 表示。若在网络中传输,则可以把 string 类型的数据变成以字节为单位的
bytes。 -
encode()与decode():- 英文字符可用 ASCII 编码 Bytes,即
"ABC".encode("ascii")。 -
中文字符可用 UTF-8 编码,即
"中国".encode("utf-8")。含有中文的 str 无法用 ASCII 编码,因中文编码的范围超过了 ASCII 编码的范围。强制编码会抛出异常:
'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)。
- 英文字符可用 ASCII 编码 Bytes,即
- Python 的字符串类型为 String,内存中以 Unicode 表示。若在网络中传输,则可以把 string 类型的数据变成以字节为单位的
-
常用数据类型转换,见表 5-2 所示。
| 函数格式 | 使用示例 | 描述 |
|---|---|---|
| int(x [,base]) | int(“8”) | 可转换的包括 String 类型和其他数字类型,但高精度转换会丢失精度 |
| float(x) | float(1) 或 float(“1”) | 可转换 String 和其他数字类型,不足的位数用 0 补齐,例如 1 会变成 1.0 |
| comple(real,imag) | complex(“1”) 或 complex(1,2) | 第一个参数可以是 String 或者数字,第二个参数只能为数字类型,第二个参数没有时默认为 0 |
| str(x) | str(1) | 将数字转化为 String |
| repr(x) | repr(Object) | 返回一个对象的 String 格式 |
| eval(str) | eval(“12+23”) | 执行一个字符串表达式,返回计算的结果,如例子中返回 35 |
| tuple(seq) | tuple((1,2,3,4)) | 参数可以是元组、列表或字典。若为字典时,返回字典的 key 组成的集合 |
| list(s) | list((1,2,3,4)) | 将序列转变成一个列表,参数可为元组、字典、列表。若为字典时,返回字典的 key 组成的集合 |
| set(s) | set([‘b’, ‘r’, ‘u’, ‘o’, ‘n’])或者set(“asdfg”) | 将一个可迭代对象转变为可变集合且去重复,返回结果可以用来计算差集 x - y、并集 x l y、交集 x & y |
| frozenset(s) | frozenset([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) | 将一个可迭代对象转变成不可变集合,参数为元组、字典、列表等 |
| chr(x) | chr(0x30) | chr() 用一个范围在 range (0~255) 内的整数作参数,返回一个对应的字符。返回值是当前整数对应的 ASCII 字符。 |
| ord(x) | ord(‘a’) | 返回对应的 ASCII 数值,或者 Unicode 数值 |
| hex(x) | hex(12) | 把整数 x 转换为 16 进制字符串 |
| oct(x) | oct(12) | 把整数 x 转换为 8 进制字符串 |
-
字符串输入和输出:
name = input("Enter your name:") age = int( input("Enter your age:") ) print("name: %s, age: %d" % (name, age))
-
组成字符串的方式:
str1 = "Hello" str2 = "World" # str3 组装成 "HelloWorld" str3 = str1 + str2 # 组装成 "===HelloWorld===",此方式常用拼凑字符串 "===%s===" % (str1 + str2)
-
字符串下标与取值:
array = "ABCDE" print( array[0] ) # 输出 A print( array[4] ) # 输出 E print( array[-1] ) # 输出 E # 切片 print( array[0:3] ) # 输出 ABC print( array[0:-1] ) # 输出 ABCD print( array[0:] ) # 输出 ABCDE # 即以 2 为步进距离,从下标 0 开始取值至末尾,输出 ACE print( array[0::2] ) # 即以 -1 为步进距离,从末尾开始取值至开端,逆序输出 print( array[-1::-1] )
-
字符串常见操作
-
find(s)与index(s):从目标字符串中寻找子串,找到会返回子串的起始下标;若找不到则返回-1。index() 找到目标的情况和 find() 相同,找不到目标则会抛出异常。当然还有 rfind(s) 和 rindex(),即从右端开始寻找子字符串。
-
count(str, start, end):例如count(str, start = 0, end = len(myStr)),即在目标字符串myStr原始字符串,求得str在 start 和 end 之间出现的次数。 replace(原始字符串, 目标字符串)或replace(原始字符串, 目标字符串,替代次数):myStr.replace("world", "python")。split(str):根据str把原字符串切开。-
splitlines(str):将字符串中的每一行切割开来。re.split(正则表达式, 目标字符串),根据正则表达式切割字符。
-
capitalize()与title():前者是把字符串中的第一个字符转为大写字母,后者是把字符串中每个单词的首字母转为大写。 startsWith(str)与endsWith(str):前者是判断目标字符是否以字符串 str 开头,后者则是判断目标字符是否以字符串 str 结尾。lower()与upper():前者是将目标字符串全转为小写字母,后者是将字符串全转为大写字母。rstrip()、lstrip()与strip():去除字符串左边、右边或者两端的空白字符。partition(str):以 str 为中心,将目标字符串划分成左、中 ( str 本身 )、右三部分的字符串。isalpha()、isdigit()与isalnum():分别用于判断是否为字符,是否为数字和是否全为数字。-
join():例如str.join(array),即使用 str 将列表 array 的内容拼接起来。array = ['A', 'B', 'C'] str1 = '&' str2 = str1.join(array) # str2 被组装成 A&B&C,即将 str1 组装到字符数组中
-
列表 List
- 定义一个列表:
list = ['A', 'B', 'C', 'D']或者student = ['lucy', 25, 'female']。 - 列表的增删改查 :
- 增加:
1) 在列表尾部追加元素:list.append('D')
2) 自定义插入位置:list.insert(位置,添加的内容)
3) 往一列表中添加另一个列表:student + list或者student.extend(list) - 删除:
1) 出栈:list.pop()/ 入栈:list.append()
2) 根据下标来删除:del list[0],清空列表del list[0::1] - 查询:
1)('B' in list)结果为 Ture
2)('D' not in list)结果为 Ture
- 增加:
元组 Tuple
-
有序列表元组 ( Tuple ),与 List 不同,Tuple 一旦初始化就不能修改。
定义一些常量参数时可用 Tuple。
-
定义:
tuples = ('A', 'B', 'C')。 - 歧义:
tuple = (1)相当于tuple = 1;tuple(-1, )才是元组列表。 -
事实: Tuple 中存储的是
引用。tuple = ('a', 'b', ['A', 'B']) tuple[2][0] = 'X' tuple[2][1] = 'Y' # 事实上,'A' 和 'B' 被改变为 'X' 和 'Y' # 即 Tuple 定义是不变的,即 Tuple 存储的 List 为引用
-
再议不可变对象:replace() 并没有改变字符串的内容,我们理解
str是变量,abc是字符串对象。replace() 相当于创建了新的字符串对象Abc。str = 'abc' print( str.replace('a', 'A') ) # 输出 Abc print(tmp) # 输出 abc
字典 Dict
- 字典 ( Dict ),其他语言中又称 Map,使用键值 ( key-value ) 存储。
- 定义:
dict = {'name': 'Lucy', 'age':25, 'gender': 'female}。 - 字典的增删改查:
- 增加:
dict['high'] = 175,若对应键值存在即修改的效果。 - 删除:
dict.pop('high')/del dict['high'] - 查询:
dict.get('name'),若找不到对应键值则抛出异常。
- 增加:
集合 Set
- Set 与 Dict 类似,是一组 key 的集合,但不存储 value。
-
Set 可看成数学意义上的无序和无重复元素的集合。
print( set([1, 1, 2, 3, 4, 4, 5]) ) # 输出 [1, 2, 3, 4, 5]
条件判断
if <condition1>:
<action1>
elif <condition2>:
<action2>
else:
if <condition3>: # if 嵌套
<action3>
循环结构
-
For循环与While循环# For 循环 names = ['LiMing', 'ZhangWei'] for name in names print(name) # While 循环 sum = 0 i = 0 while( i<100 ): sum += 1 i += 1 -
Break与Continue- Break:终止 ( 跳出 ) 循环。
- Continue:中断本次循环。
函数
定义函数
-
定义函数使用
def语句,依次写函数名、括号、( 还可以包括参数)、冒号。然后是函数体( 需缩进编写 )。def FuncName(param): <action> return [返回参数]
-
空函数:模块化设计,即先架构后编码。
def FuncName(param): pass # 占位符:暂不书写代码逻辑
-
返回多个值:
def move(x, y): x = x + 1 y = y + 1 return x, y x, y = move(100, 100) # 其实返回的是一个 Tuple,即 (x, y)
函数参数
-
默认参数 ( 缺省参数 ):最大好处是降低调用函数难度,类似注册时,多数用户只关心核心的信息,即其余信息设置为默认值。
注意:定义默认参数时,必须指向不变对象。如 n = 2,不能 n = m ( m 为变量 )
def power(x, n = 2): s = 1 while(n > 0): n = n - 1 s = s * x return s print( power(5) ) # 输出 25 print( power(5, 3) ) # 计算 5 的 3 次方,输出 125
-
可变参数:顾名思义,可变参数就是传入的参数个数是可变的。
# def calculator(numbers),即理解 numbers 为一个 tuple def calculator(*numbers): sum = 0 for n in numbers: sum = sum + n ** 2 return sum # 等价于 calculator( (1, 3, 5, 7) ) print( calculator(1, 3, 5, 7) ) # 输出 84
-
关键字参数:
可变参数允许你传入 0 个或任意个参数,这些参数在函数调用时自动组装为一个元组( Tuple )。
关键字参数允许你传入 0 个或任意个参数,这些关键字参数在函数内部自动组装成为一个词典( Dict )。def person(name, age, **kw): print(' name:', name, ' age:', age, ' others:', kw) person('Lucy', 35, city = 'Guangzhou', gender = 'M') # 输出 name: Lucy age: 35 others: {'city': 'Guangzhou', 'gender': 'M'} # 当然,我们可先组装词典 dict,然后把该 dict 转换为关键字参数传进去 extra = {'city': 'Guangzhou', 'gender': 'M'} # 将字典中的元素,拆分成独立的 Key-Value 键值,引用时前缀也要加 "**" person('Jack Ma', 50, **extra) # 输出 name: Jack Ma age: 50 others: {'city': 'Guangzhou', 'gender': 'M'}
-
参数组合:Python 中定义函数,可多种参数组合使用,但必须满足一下参数定义顺序:
必选参数、默认参数、可变参数、命名关键字和关键字参数。def func(a, b, c = 0, *args, **kw): print(' a=', a, ' b=', b, ' c=', c, ' args=', args, ' kw=', kw) # 输出 a=1 b=2 c=3 args=('a', 'b') kw={'x'=99} func(1, 2, 3, 'a', 'b', 'x'=99) -
结合
tuple和dict:即通过类似func(*args, **kw)形式调用函数。参数虽可自由组合使用,但不要组合太复杂,以造成可理解性较差的结果。args = (1, 2, 3) kw = {'x' = 5, 'y' = 6} func(*args, **kw)
递归函数
-
函数内部可以调用其他函数。若一个函数内部调用了其自身,即该函数为
递归函数。def fact(n): if n == 1: return 1 return n * fact(n - 1)
- 递归的过深调用会导致栈溢出。可通过
尾递归优化。 -
尾递归优化:解决递归调用栈溢出的方法,即函数返回时调用本身,并且 return 语句不能包含表达式。
- 区别上述的 fact(n) 函数,由于
return n * fact(n - 1)引入了乘法表达式,即非尾递归。 - 而
return fact_iter(num - 1, num * product)仅仅返回函数本身。 -
这样,编译器 / 解释器就可对尾递归做优化,即使递归本身调用 n 次,都只占用一个栈帧,不会出现栈溢出的情况。
def fact(): return fact_iter(n, 1) def fact_iter(num, product): if num == 1: return product return fact_iter(num -1, num * product)
- 区别上述的 fact(n) 函数,由于
高级特性
切片
-
切片操作符:在 List 中指定
索引范围的操作。
索引范围具体为:起始位置:结束位置:步进,注意步进数 ( 默认为 1,不能为 0 )。list = [11, 22, 33, 44, 55] # 输出 [11, 22, 33],即从小标为 0 开始,步进为 1,取前 3 个元素 print( list[0:3:1] ) -
倒数切片:
list = ['A', 'B', 'C', 'D', 'E'] # 输出 ['A', 'B', 'C', 'D'],即从下标为 0 开始,切片至倒数第一个元素 (不含其本身) print( list[0:-1] )
-
字符串切片:
str = 'ABCDE' # 输出 ACE,即对字符串中所有字符作用,每隔两位取值 print( str[::2] )
- 注意:
Tuple也是一种List,唯一不同的是 Tuple 不可变,因此 Tuple 不可用切片操作。
迭代
-
迭代:给定一个 List 或 Tuple,通过 For 循环遍历这个 List 或 Tuple。
list = ['A', 'B', 'C', 'D', 'E'] for str in list: print(str) # 输出 ABCDE
-
enumerate函数可以把一个 list 变成索引-元素树,这样就可以在 For 循环中同时迭代索引和元素本身。list = ['A', 'B', 'C', 'D', 'E'] for i, value in enumerate(list) print(i, value)
列表生成式
-
列表生成式:List Comprehensions,用于创建 List 的生成式。
list1 = [] list1 = [x**2 for num in range(1, 10)] # 输出 1x1,2x2,3x3, ..., 9x9 print(list1) ''' 等价于: for num in range(1, 10): list1.append(num ** 2) ''' # for 循环与 if 判断配合,例如取得 10 以内的偶数,求其平方数 list2 = [ num**2 for num in range(1, 10) if num%2 == 0 ] # 输出 2x2, 4x4, 6x6, 8x8 print(list2) # 两层 for 循环 list3 = [ m+str(n) for m in 'ABC' for n in range(1,4) ] # 输出 ['A1', 'A2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3'] print(list3) list4 = [ m*n for m in 'ABC' for n in range(1,4) ] # 输出 ['A', 'AA', 'AAA', 'B', 'BB', 'BBB', 'C', 'CC', 'CCC'] print(list4) # 列出当前目录下所有文件和目录名 import os # 导入 os 模块 list = [d for d in os.listdir('.')]
生成器
- 引入:
列表生成式,可直接创建一个列表。但受到内存限制,列表容量肯定是有限的。例如:我们需要一个包含 100 万个元素的列表 ( 列表中的元素按照某种算法推算出来 ),直接创建是不太现实的,那么我们是否可通过某种过程,实现动态推算并输出元素? - Generator:
生成器,即不用一步到位创建 list 对象,而是通过循环过程中不断推算出后续的元素。在 Python中,把这种一边循环一边计算的机制称作Generator。 -
创建 Generator:把列表生成式的
[]改成()即可。# 受到内存限制,运行过程中可能会崩掉 list = [ x for x in range(1, int(10e10)) ] # 简单生成器: generator = ( x for x in range(1, int(10e10)) ) for n in generator: print(n) """ " 简单示例: " 带 yield 的 Generator 函数 " 1) 在每次循环时都执行,遇到 yield 语句返回 " 2) 再次执行时,从上次返回的 yield 语句处继续执行 """ def odd(): print('First Return: ') yield [1, 2, 3] print('Second Return:') yield (1, 2, 3) print('Third Return:') yield {'key': 'value'} for n in odd(): print(n) # Fibonacci 数列: def fibonacci(times): n, a, b = 0, 0, 1 while n < times: yield b (a, b) = (b, a+b) n = n + 1 return 'done' for n in fibonacci(10): print(n)
迭代器
- 可用于 for 循环的数据类型:
- 集合数据类型:list、tuple、dict (字典)、set、str (字符串)
- Generator 生成器和带
yield的 Generator 函数
-
可用于 for 循环的对象统称为可迭代对象
Iterable。# 使用 isinstance() 判断一个对象是否为 Iterable 对象 form collections import Iterable isinstance([], Iterable) # True isinstance((x for x in range(1, 10)), Iterable) # True isinstance(100, Iterable) # False -
生成器是
Iterator对象;List、Dict、Str 虽然是 Iterable 对象,但却不是Iterator。
我们可以通过iter()函数,把 List、Dict、Str 等 Iterable 转换达成Iterator。Python 的迭代器 ( Iterator ) 对象表示的是一个数据流,即 Iterator 对象可被
next()函数调用并不断返回下一个数据,直至没有数据时抛出StopIteration异常。isinstance(iter([]), Iterator) # True isinstance(iter('abc'), Iterator) # True
函数式编程
- 函数:
模块化编程,即把大段功能代码拆分、封装成模块,通过层层调用,把复杂任务解构成简单任务。- 这种分解称之为
面向过程的程序设计。 - 函数是面向过程程序设计的
基本单元。
- 函数式编程:
- 就是一种抽象程序很高的
编程范式; - 纯粹的函数式编程语言编写的函数没有变量;
- 函数式编程的特点:允许函数作为
参数,作为另一函数的输入。
- 就是一种抽象程序很高的
高阶函数
-
变量可指向函数:
# 直接调用函数 x = abs(-10) # 变量可指向函数 f = abs x = f(-10) # x 的结果都为 10
-
函数名也是变量:函数名其实就是指向函数的变量。
注意:
1) 而在实际编码当中,绝对不能这样写,只是为了说明函数名也是变量。
2) 若需恢复 abs 函数,请重启 Python 交互环境。abs = 10 abs(-1) # 抛出异常 # 即 abs 已指向一个整数 10,而不是指向求绝对值的函数。 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'int' object is not callble
-
传入函数:一个函数接收另一个函数作为参数,称为
高阶函数。def add(x, y, f): return f(x) + f(y) # 调用 add(-5, 6 abs) 时,计算的过程为: # x = -5 # y = -6 # f = abs # f(x) + f(y)
MapReduce
- Python 内建了 map() 和 reduce() 函数。
-
Map / Reduce 的概念 :
- MapReduce 是一种编程模型,是
处理和生成大型数据集的相关实现。 -
用户指定一映射函数
map()处理键/值对,以生成一组中间键/值对;同时也指定reduce()函数用以合并含相同中间键所关联的所有中间值。为了更加透彻理解 MapReduce,可研读 Google 关于 MapReduce 的论文:
MapReduce: Simplified Data Processing on Large Clusters[ 4 ] " role="presentation" style="position: relative;">。
- MapReduce 是一种编程模型,是
Map 函数
-
map() 函数:其接收
两个参数,第一个是函数,第二个是Iterable。即 map 将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。# 例 1:有一个函数 f(x) = x*x,将其作用于一个 list = [1, 2, 3, 4, 5] def f(x): return x ** 2 # 1) map() 函数 r = map(f, [1, 2, 3, 4, 5]) print(list(r)) # 输出 [1, 4, 9, 16, 25] # 2) 不需要 map() 函数的等价写法 list = [] for n in [1, 2, 3, 4, 5] list.append( f(n) ) print(list) # 输出 [1, 4, 9, 16, 25] # 例 2:map 作为高阶函数,事实上它把运算规则抽象了,如把 list 中数字转字符串 list( map(str, [1, 2, 3, 4, 5]) ) # 输出 ['1', '2', '3', '4', '5']
Reduce 函数
-
reduce() 函数:其接收
两个参数,第一个是函数,第二个是Iterable。即 reduce 把结果继续和序列的下一个元素做累积计算。reduce(f, [x1, x2, x3, x4]) 等价于 f( f( f(x1, x2), x3 ), x4 )
from functools import reduce def add(x, y): return x + y print( reduce(add, [1, 2, 3, 4, 5]) ) -
当然,上述的实例只是为了描述原理而设定,下面将结合 map() 与 reduce() 举例:
from functools import reduce # 定义一计算公式 def fn(x, y): return x * 10 + y # 定义一字符转数字的函数 def char2num(s): digits = {'0': 10, '1': 20, '2': 30, '3': 40} return digits[s] # map/reduce 实现处理与计算的功能 print( reduce(fn, map(char2num, '0123')) )
Filter
- Python 内建了
filter()函数,用于过滤序列。 -
filter() 函数:接收
两个参数,一个是函数,另一个是序列。即 filter 把传入的函数作用于每个元素,然后根据返回值是True/False决定是否保留/丢弃该元素。filter() 函数返回的是一个 Iterator,即一个惰性序列,故需要强迫 filter() 完成计算结果,如 list() 函数获得所有结果。
# 在一个 list 中,删掉偶数,只保留奇数 def isOdd(n): return n % 2 == 1 # 输出 [1, 3, 5] list( filter(isOdd, [1, 2, 3, 4, 5]) ) # 把一个序列中的空字符剔除 def rejectBlankStr(s): return s and s.strip() # 输出 ABC list( filter(rejectBlankStr, ['A', 'B', '', None, 'C']) )
Sorted
-
排序算法:排序的核心是
比较两元素的大小。若是数字则直接比较;但比较的若是字符串或两个字典,则比较过程需通过函数抽象实现。# 输出 [-6, 2, 12, 24, 36] print( sorted( [36, 24, -6, 12, 2] ) )
-
sorted()也是一高阶函数,可接收一个 key 函数来自定义排序:# 输出 [2, -6, 12, 24, 36] print( sorted([36, 24, -6, 12, 2], key = abs) ) # 忽略大小写,实现字符串排序 # 实现字符串的比较是根据 ASCII 实现比较的 print( sorted(['Bob', 'Lucy', 'Zoo', 'Danny'], key = str.lower) ) # 进行反向排序,可传入第三个参数实现 print( sorted(['Bob', 'Lucy', 'Zoo', 'Danny'], key = str.lower, reverse = True) )
返回函数
函数作为返回值
-
函数作为返回值:高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
# 通常情况实现一个可变参数的求和 def calcSum(*args): ax = 0 for n in args: ax = ax + n return ax # 若不想立刻求和,可不返回求和结果,而是求和函数 def lazySum(*args): def sum(): ax = 0 for n in args: ax = ax + n return ax return sum # 调用 lazySum() 时,返回函数而不是结果 f = lazySum(1, 3, 5, 7, 9) # 调用 f,才真正计算求和的结果 f() # 当每次调用 lazySum() 时,都会返回一个新的函数,既使传入参数相同 f1 = lazySum(1, 3, 5, 7, 9) f2 = lazySum(1, 3, 5, 7, 9) print( f1 == f2 ) # 输出 False
闭包
- 注意到上述例子返回的函数在其定义内部引用了局部变量
args,故当一个函数返回一个函数后,其内部的局部变量还被新函数引用。 -
注意返回的函数并没有立刻执行,而是调用了
f()才执行。def count(): fs = [] for i in range(1, 4): def f(): return i ** 2 fs.append(f) return fs f1, f2, f3 = count() # 输出 9::9::9 print( str(f1()) + '::' + str(f2()) + '::' + str(f3()) ) """ " 实际结果为:f1() --> 9,f2() --> 9, f3() --> 9 " 全部结果都为 9,原因在于返回的函数引用了变量 i,但它并非立刻执行 " 需等到 3 个函数都返回时,它们所引用的变量 i 已经变成了 3,故最终结果是 9 """ # 若需引用循环的变量 def count(): def f(j): def g(): return j * j return g fs = [] for i in range(1, 4): fs.append( f(i) ) # f(i) 立刻执行,i 的当前值被传入 f() return fs f1, f2, f3 = count() # 输出 1::4::9 print( str(f1()) + '::' + str(f2()) + '::' + str(f3()) )返回闭包时牢记一点:返回函数不要引用任何循环变量,或后续会发生变化的变量。
匿名函数
- 当函数作为
传入参数时,我们不需要显式地定义函数,直接传入匿名函数更便捷。 -
关键字
lambda表示匿名函数,冒号前面表示传入参数,后面为返回值 ( 一般为表达式运算后的结果 ),如lambda x, y : x+y# 以 map() 函数为例 # 输出 [1, 4, 9, 16, 25] print( list(map(lambda x : x ** 2, [1, 2, 3, 4, 5])) ) # 匿名函数实际为: def f(x): return x ** 2 -
匿名函数有一好处,即不必担心
函数名冲突。此外,匿名函数也是一个函数对象,可把匿名函数赋值给一个变量,再利用变量来调用。f = lambda x : x ** 2 print( f(5) ) # 输出 25
-
匿名函数作为返回值返回:
def build(x, y): return lambda: x * x + y * y
装饰器
偏函数
-
例:int() 函数可把字符串转为整数,当且仅当传入字符串时,int() 函数默认按照
10 进制转换。print( int('12345') ) # 输出 12345 # int() 函数提供额外 base 参数,默认值为 10 # 若传入 base 参数即可做 N 进制转换 ( N 进制转到 10 进制 ) print( int('10', base = 8) ) # 输出 8 print( int('A', base = 16) ) # 输出 10 # 若我们要转换大量二进制字符串,则可通过定义函数 def int2(x, base = 2): return int(x, base) # 这样转换二进制就非常便捷了 print( int2('10000000') ) # 输出 128 print( int2('10101010') ) # 输出 170 -
其实
functools.partial就是帮助我们创建一个偏函数,即其作用就是把一个函数的某些参数固定住 ( 设置默认值 ),返回一个新函数。import functools int2 = fuctools.partial(int, base = 2)
-
创建偏函数时,实际可接收
函数对象、*args和**kw这三个参数。int2 = fuctools.partial(int, base = 2)/ # 相当于: args = '10001000' kw = {'base': 2} int(*args, **kw)
参考资料
[1] Eddie Woo. The RSA Encryption Algorithm. 2017. bilibili.com
[2] John cui. 轻松学习RSA加密算法原理. 2018. jianshu.com
[3]
廖雪峰. Python 教程. 2018, liaoxuefeng.com
[4] Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters [J]. Communications of the ACM, 2008, 51(1): 107-113.
[5]
Wes McKinney. 利用 Python 进行数据分析 [M]. 机械工业出版社, 2013
