

奇技指南
我们发现公司的服务器cpu, memory等资源利用并不充分;如果能够充分利用这些机器上的空闲资源同时又能保证业务服务的正常运行,将会节省不少的机器资源;所以我们研究了Mesos来构建多任务调度系统。接下来就为大家介绍下我们的Mesos系统。
本文转载自HULK一线技术杂谈。
背景
公司内部的云平台为各个业务线提供了大量的实体机和虚拟机来运行业务的服务,经过统计发现,这些分配给业务的机器cpu, memory等资源利用并不充分;
如果能够充分利用这些机器上的空闲资源同时又能保证业务服务的正常运行,将会节省不少的机器资源;
选型
一提到多任务运行和调度,大部分人可能首先都会想到Kubernetes(k8s) + Docker, 跑起来如清风拂面, 顺畅无比。然而我们的业务机器大部分为centos 6.2, linux kernel 2.6的环境,而docker的运行需要Linux kernel的版本是 3.10+
(可参考: https://docs.docker.com/engine/faq/#how-do-i-connect-docker-containers)
因为想利用业务正在使用的机器,又不能影响现有已在跑的服务, 所以不能升级内核, 不能重启机器,显然k8s这条路走不通;
还好,这个世界总是提供给我们多样的选择,除了Kubernetes(k8s) + Docker, 我们还有mesos;
Mesos简介
先放上官方网站, 上面有很详细的说明;
http://mesos.apache.org/
简单来说,Mesos就是用于整个计算中心的操作系统,它统一管理计算中心所有机器的cpu, memory, disk, network等计算资源,按任务所需分配资源,调度任务,支持故障转移等等;
Mesos特性
Mesos最大特点是两级资源调度, 如下图:
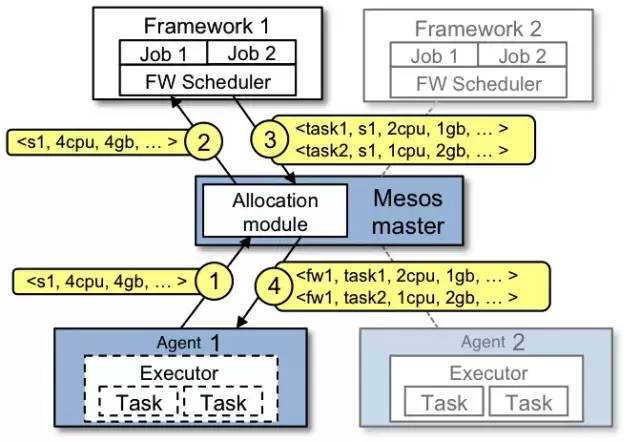
上面架构图的简要说明如下:
-
各个Agent上报自已的计算资源给Master;
-
Master给各个二级调度框架Framework发送resource offer;
-
Framework将其上等待调度的task与收到的resource offer作匹配,反馈给Master;
-
Master将相应Framework反馈的task和resource offer发送到对应的Agent;
-
Agent使用Executor来运行task, 并限定资源使用;
在Mesos上可以运行Spark, Storm, Hadoop, Marathon等多种Framework;
Mesos系统架构
官方文档:
http://mesos.apache.org/documentation/latest/architecture/;
针对任务隔离这块, Mesos除了支持docker容器技术,还提供了它自己的Mesos Containerizer, 这正是我们所需要的.其实Mesos Containerizer目前也是利用Linux Cgroup作资源限制, 用Linux namespace作资源隔离。
Mesos Containerizer:
http://mesos.apache.org/documentation/latest/mesos-containerizer/
面临挑战
我们的多任务调度系统需要解决的几个问题
-
Mesos agent在业务机器上需要非侵入式地部署,不能污染所部署的机器的环境;
-
实时监控和调整Mesos Agent所能使用的计算资源;
-
Task的快速部署和资源隔离;
-
集群整体运行情况的监控;
多任务调度系统总体架构
架构设计图
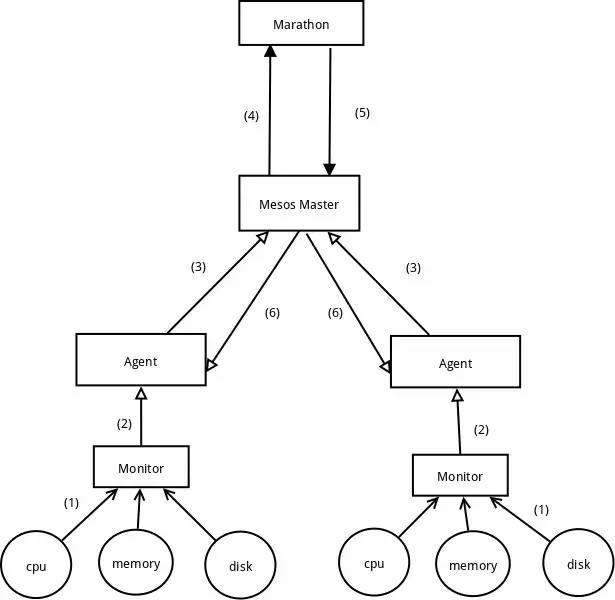
-
各组件简介:1.1 主体还是Mesos master + Mesos agent;1.2 二级调度框架使用的是Marathon;1.3 在部署了Mesos agent的机器上同时部署monitor用于实时监控和调整Agent的可用计算资源;
-
系统运行流程,按上图中标号顺序
2.1 Monitor实时监控组件收集所在机器上的可用资源;
2.2 Monitor根据所在机器上的可用资源动态调整agent的保留资源;
2.3 Agent动态实时的将自已的保留资源上报到Mesos master;
2.4 Mesos Master在resource offer发到Marathon;
2.5 Marathon根据收到的resource offer和需要运行的task作资源分配, 将分配结果反馈给Mesos Master;
2.6Mesos Master将task分配到具体的Agent上执行;
Mesos agent在业务机器上非侵入式部署
我们采用的是Mesos 1.4.1版本,用C++11编写,Mesos项目本身非常庞大,依赖库必然也很多,解决这些运行依赖问题首当其冲;
部署原则就是不改变,不污染所部署的机器环境,针对libstdc++和其他一些so, 我们不会将其安装到例如/usr/local/lib这样的系统目录, 而是在打包时采用动态更改可执行程序的rpath的方法,使其运行时从我们的安装目录加载相应的so库, 具体作法就是
-
我们将mesos运行所需要的所有lib文件都集中放在libs目录下;
-
编译出来的mesos可执行文件,使用patchelf来更新rpath路径,指向我们自已的libs目录即可;
-
patchelf这个工具可以在不影响可执行文件运行的前提下,修改其elf文件结构中的某些属性值, 具体可参考:https://nixos.org/patchelf.html
这样部署完,Mesos agent只是一个单独的目录,卸载只需要停掉进程,删除目录就好;
说一下编译过程,虽然官网上已经介绍得比较详细,但在编译过程中还是会遇到一些问题:
-
官网编译步骤: 请参考
http://mesos.apache.org/documentation/latest/building/;
-
gcc官方要求是 4.8.1+, 我用了 gcc 5.4, 自己在 centos 6.2,linux 2.6.32上重新编译的;
-
编译默认是编译java语言的binding的, 但在 编译 "Build and attach javadoc"时缺 protobuffer的jar包,没编译过, 解决方案:修改 src/java/mesos.pom.in,先找到 ``, 在它下面的 <configuration>下添加 <skip>true</skip>,这样不会编译这个 javdoc, 但不影响 java binding的使用
2
实时监控和调整Agent所能使用的计算资源
自行开发了Monitor程序,和Agent一同部署在业务机器上,周期性的监测机器上可用资源和Agent本身所用资源;
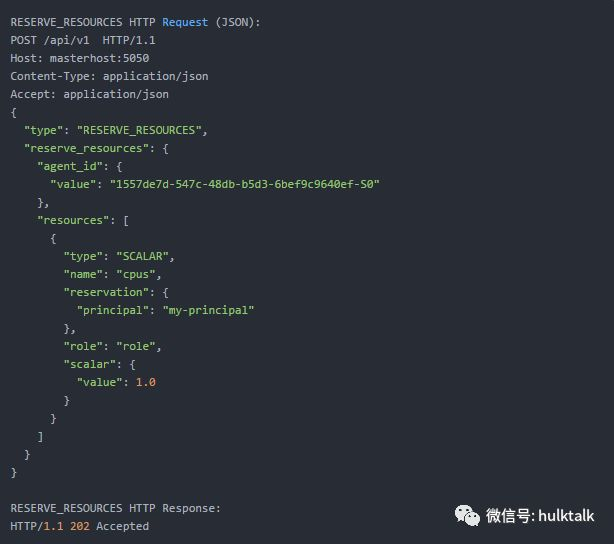
Mesos为我们提供了动态资源保留这个超实用的功能,可以限制Agent当前针对某个Role可以使用的计算资源:
Monitor的监控评估结果就是当前Agent可以使用的计算资源;
本想着到这里这个问题就结束了,测试时发现Agent并不能在线实时调整这个动态资源保留,需要在配置文件时更新好当前能够使用的动态资源,然后重启Agent;
重启Agent是我们不能忍受的,因此我们修改了源码,通过http接口在线调整动态资源保留, 这部分其实不难,mesos http接口定义十分清晰,依葫芦画瓢就好了。
3
Task的快速部署和资源隔离
task的部署目前我们采用Marathon,上手简单,功能够用; 如果需要更灵活的调整策略,可能就需要自己开采框架或基于某一框架二次开发了;
task其实是有重要,紧急之分,占用资源也不尽相同。对于重要紧急任务,为了保障任务的更好运行,我们会利用Mesos attribute,在调度任务时让特定任务只跑在具有特定attributes的agent上, 这就需要为每个mesos agent设置相应的attributes;
遇到了同样的问题,mesos不能在线动态调整attributes :-(, 其实也比较简单,稍微梳理下mesos源码结构,改起来不难;
还有一个问题,attributes是动态调整的,agent如果重启了怎么办?我们为此部署了etcd集群来管理,每台agent都是etcd上的一个node, 通过etcd提供的http接口更新其attribrtes, agent会周期性的从etcd上同步;同时各agent 上的attributes信息也很容易从etcd上获得;
直接操作etcd, 删除某台agent上的attribute, 那依赖于这种attribute部署的任务会自动别调度走,不再在这台agent上运行;
task隔离问题,针对cpu和memory,mesos都是通过cgroup来完成,对于cpu的限制, 我们使用cfs方式,前提是需要判断当前kernel是否支持.对于disk的限制,目前mesos使用的是du命令周期性检测的方式;
对于cpu的限制,mesos有两种方式:
-
cpu shared方式:这种方式对 cpu 没有严格限制,机器上的任何task都可以访问机器上所有cpu资源,比如你限定的cpu使用资源是2, 这种方式可能使用到4,6或更高;
-
cpu CFS方式: 相当于配置了独占 cpu, 比如cpu配置为1,那么这个任务的 cpu 使用率就不会超过 100%, 相当于设定了一个hard limit;
在我们的大部分环境中,受限于kernel版本,mount namespace不支持,因此我们采用rootfs + chroot的方式来作简单的资源隔离;
我们定制了若干版本的rootfs, 任务打包就是将任务本身的依赖和相应rootfs结合的过程, 打包好可以放到s3等存储上,供marathon部署任务时调用。
这里我们结合marathon的一个任务部署的json配置来讲一下, 先看一个这个配置, 我将说明直接写在里面
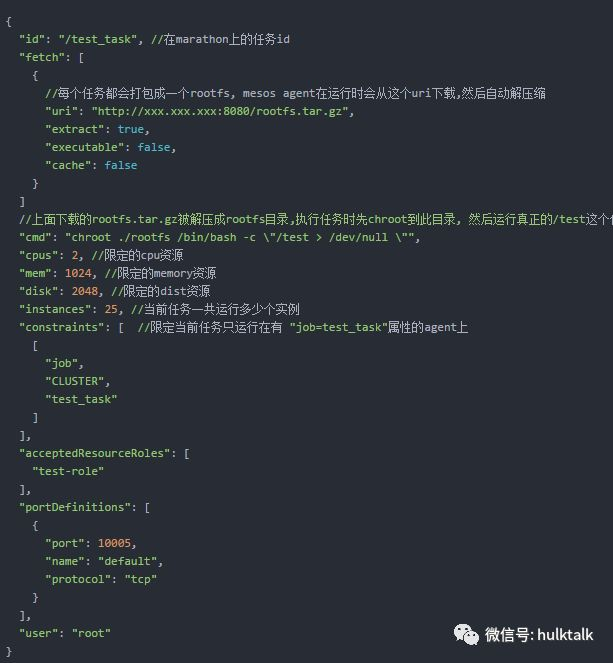
关于chroot, 大家可以参考下面的网址内容,简单讲就是构造了一个沙箱,和已有的文件系统隔离;
https://www.ibm.com/developerworks/cn/linux/l-cn-chroot/
4
集群整体运行情况的监控
机器本身的基础监控一般公司还有自己的统一监控, 这部分不用投入精力;
我们主要关注task的调度运行情况,目前的方案是mesos-exporter和mesos-agent(或mesos-master)一起部署,上报监控信息到prometheus,使用grafana来展示:
mesos本身为我们提供了很丰富的http api来获取当前集群的属性,状态,Framework情况,task的运行状态等等,结合这些我们自己来作监控其实也不是难事,可以参考这里:
http://mesos.apache.org/documentation/latest/operator-http-api
仍然存在的问题
打包task没有实现自动化, 我们虽然定制了若干种不同的rootfs, 比如c++11环境的, python环境的, java环境的等等, 但是想要运行的task依赖千差万别, 现在都是结合rootfs和业务的程序,手动合成专用的rootfs, 基本上每个task都要走这个手动流程,烦锁,耗时,容易出错;
目前只引用了marathon一种调度框架,适用于长期运行的task, 对于需要定时运行的task目前无法支持;
结束
到此我们利用Mesos构建的多任务调度系统就简单介绍完成,其中还有很多不完善的地方,有兴趣的同学可以一起讨论,互相学习~~~
界世的你当不
只作你的肩膀
无


360官方技术公众号
技术干货|一手资讯|精彩活动
空·
