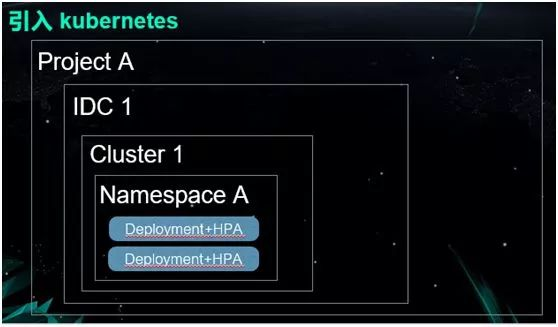
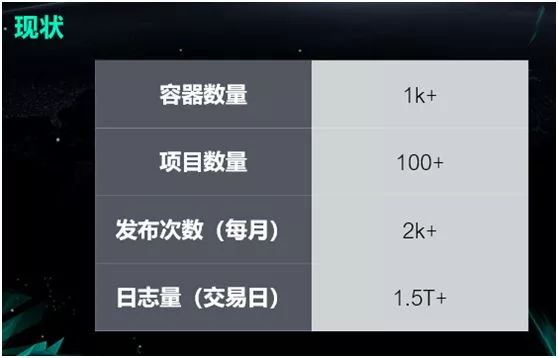
雪球目前拥有一千多个容器,项目数量大概有一百多个,规模并不是很大。但是得益于容器技术,雪球部署的效率非常高,雪球的开发人员只有几十个,但是每个月的发布次数高达两千多次。 雪球是一个投资者交流的社区,用户可以在上面买卖股票,代销基金等各种金融衍生业务,同时也可以通过雪盈证券来进行沪、深、港、美股的交易。
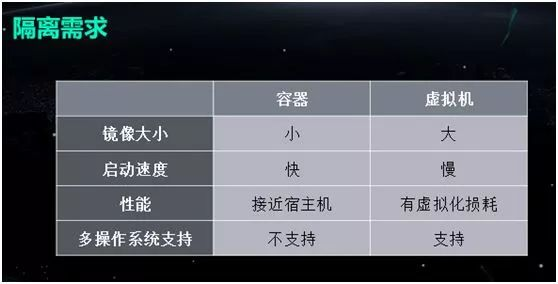
为什么要引入 Docker

-
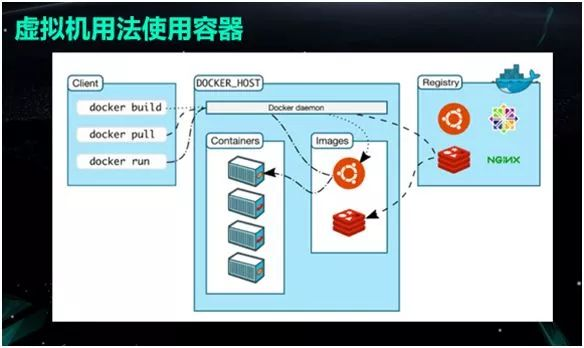
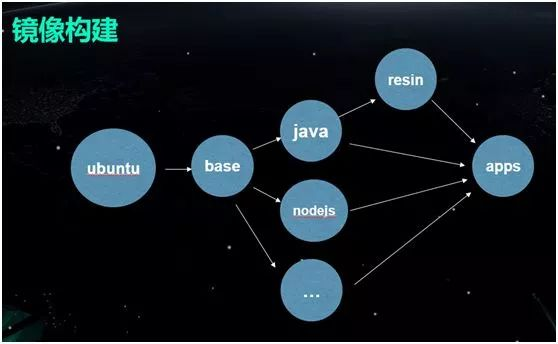
在一台 Host 主机上先运行 Docker Build。
-
然后运用 Docker Pull,从镜像仓库里把镜像拉下来。
-
最后使用 Docker Run,就有了一个运行的 Container。
-
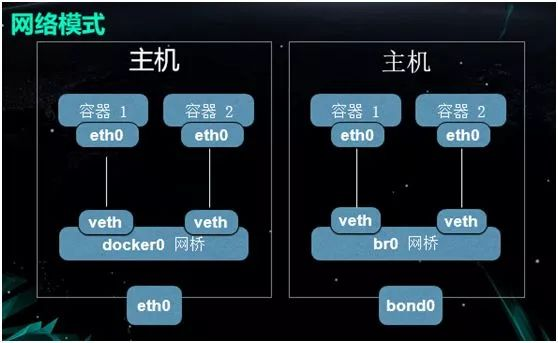
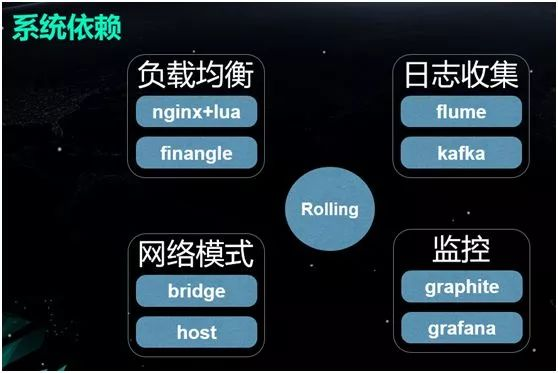
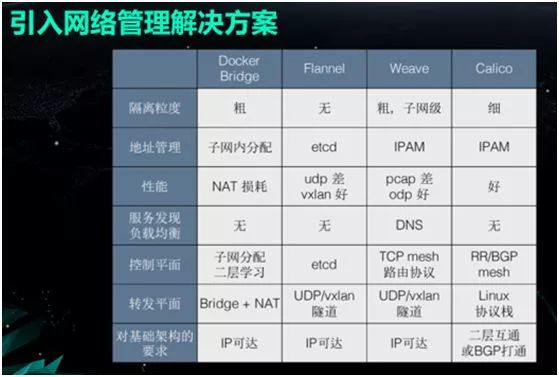
网络连通性,由于是单机软件,Docker 最初默认使用的是 Bridge 模式,不同宿主机之间的网络并不相通。因此,早期大家交流最多的就是如何解决网络连通性的问题。
-
多节点的服务部署与更新,在上马该容器方案之后,我们发现由于本身性能损耗比较小,其节点的数量会出现爆炸式增长。
因此,往往会出现一台物理机上能够运行几十个节点的状况。容器节点的绝对数量会比物理节点的数量大一个数量级,甚至更多。那么这么多节点的服务部署与更新,直接导致了工作量的倍数增加。
-
监控,同时,我们需要为这么多节点的运行状态采用合适的监控方案。

-
优点:由于在网络二层上实现了连接互通,而且仅用到了内核转发,因此整体性能非常好,与物理机真实网卡的效率差距不大。
-
缺点:管理较为复杂,需要我们自己手动的去管理容器的 IP 和 MAC 地址。 由于整体处于网络大二层,一旦系统达到了一定规模,网络中的 ARP 包会产生网络广播风暴,甚至会偶发出现 PPS(Package Per Second)过高,网络间歇性不通等奇怪的现象。
由于处于底层网络连接,在实现网络隔离时也较为复杂。
-
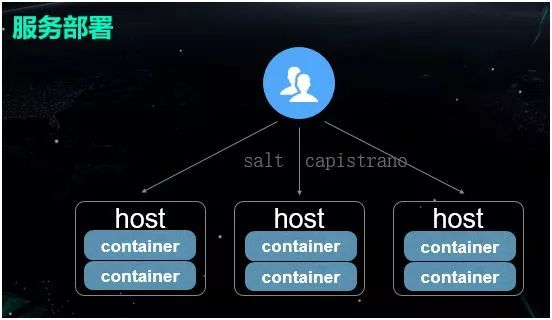
如果节点需要新增,我们就通过 Salt 来管理机器的配置。
-
如果节点需要更新,我们就通过 Capistrano 进行服务的分发,和多个节点的部署操作,变更容器中的业务程序。

-
与原来的基础设施相比,迁移的成本非常低。由于我们通过复用原来的基础设施,直接将各种服务部署在原先的物理机上进行,因此我们很容易地迁移到了容器之中。而对于开发人员来说,他们看不到容器这一层,也就如同在使用原来的物理机一样,毫无“违和感”。
-
与虚拟机相比,启动比较快,运行时没有虚拟化的损耗。
-
最重要的是一定程度上满足了我们对于隔离的需求。
-
迁移和扩容非常繁琐。例如:当某个服务需要扩容时,我们就需要有人登录到该物理机上,生成并启动一个空的容器,再把服务部署进去。此举较为低效。
-
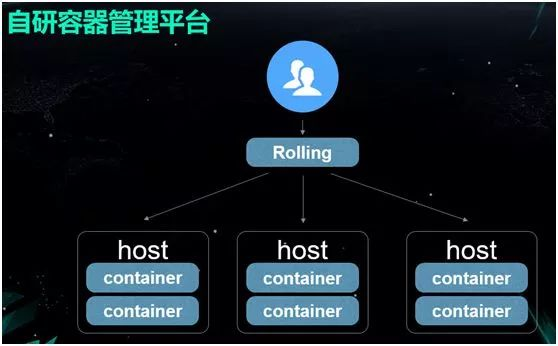
缺乏统一的平台进行各种历史版本的管理与维护。我们需要通过文档来记录整个机房的容器数量,和各个容器的 IP/MAC 地址,因此出错的可能性极高。
-
缺少流程和权限的控制。我们基本上采用的是原始的管控方式。
-
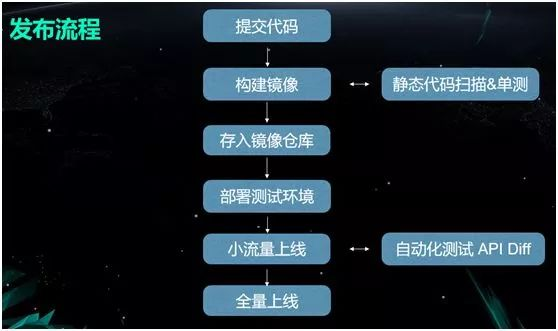
由开发人员将代码提交到代码仓库(如 Github)之中。
-
触发一个 Hook 去构建镜像,在构建的同时做一些 CI(持续集成),包括静态代码扫描和单测等。
-
将报告附加到镜像的信息里,并存入镜像仓库中。
-
部署测试环境。
-
小流量上线,上线之后,做一些自动化的 API Diff 测试,以判断是否可用。
-
继续全量上线。
-
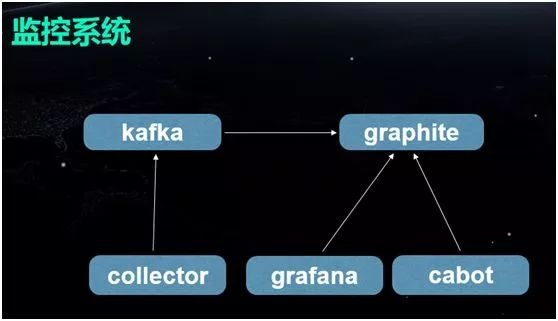
一类是 Nginx 这种不易侵入代码的,我们并没有设法去改变日志的流向,而是让它直接“打”到物理机的硬盘上,然后使用 Flume 进行收集,传输到 Kafka 中。
-
另一类是我们自己的业务。我们实现了一个 Log4 Appender,把日志直接写到 Kafka,再从 Kafka 转写到 ElasticSearch 里面。


-
流程与权限的控制。
-
代码版本与环境的固化,多个版本的发布,镜像的管理。
-
部署与扩容效率的大幅提升。
-
在流程控制逻辑,机器与网络管理,以及本身的耦合程度上都存在着缺陷。因此它并不算是一个非常好的架构,也没能真正实现“高内聚低耦合”。
-
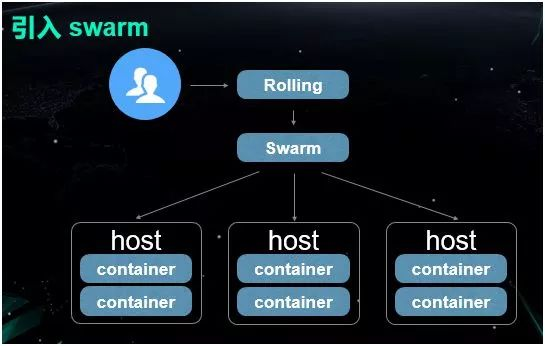
由于是自研的产品,其功能上并不完善,没能实现自愈,无法根据新增节点去自动选择物理机、并自动分配与管理 IP 地址。
-
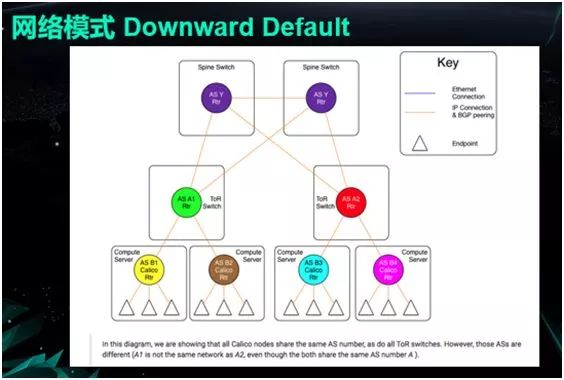
单个节点不必知道其他物理机的相关信息,它只需将数据包发往网关便可。因此单台物理机上的路由表也会大幅减少,其数量可保持在“单机上的容器数量 +一个常数(自行配置的路由)”的水平上。
-
每个上联交换机只需掌握自己机架上所有物理机的路由表信息。
-
核心交换机则需要持有所有的路由表。而这恰是其自身性能与功能的体现。
在此之后,我们也将 DevOps 的思想和模式逐步引入了当前的平台。具体包括如下三个方面:
-
通过更加自助化的流程,来解放运维。让开发人员自助式地创建、添加、监控他们自己的项目,我们只需了解各个项目在平台中所占用的资源情况便可,从而能够使得自己的精力更加专注于平台的开发与完善。
-
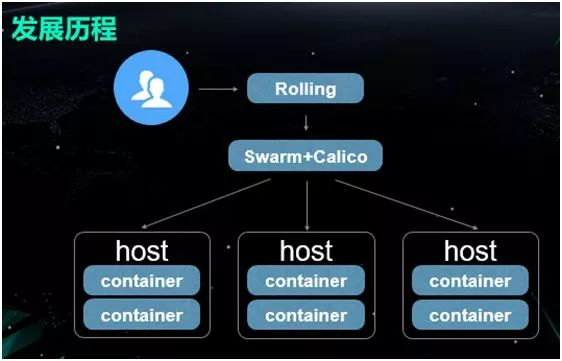
如今,由于 Kubernetes 基本上已成为了业界的标准,因此我们逐步替换了之前所用到的 Swarm,并通过 Kubernetes 来实现更好的调度方案。
-
支持多机房和多云环境,以达到更高的容灾等级,满足业务的发展需求,并完善集群的管理。