

 来源 | Women Who Code
译者 | 小大非
在运营和管理中,on-call 的团队通常负责确保服务和应用程序的可靠性和可用性。如果没有建立一个高效的 on-call 团队,将对业务造成明显的不良影响。一个不健康的 on-call 团队文化会在一个管理组织中产生压力和挫折感。
来源 | Women Who Code
译者 | 小大非
在运营和管理中,on-call 的团队通常负责确保服务和应用程序的可靠性和可用性。如果没有建立一个高效的 on-call 团队,将对业务造成明显的不良影响。一个不健康的 on-call 团队文化会在一个管理组织中产生压力和挫折感。
当我第一次加入 Button 的 on-call 团队时,我非常担心被排班。如果我在我值班时睡过去了怎么办? 那服务怎么办? 我应该盯着哪个仪表盘看呢? 从那以后,我几乎一年的时间都在轮班,值班了无数次。虽然我不能说我喜欢做 on-call 的工作,但我可以证明,作为 on-call 轮班的一员肯定是我在 Button 工作的一个亮点——在很大程度上是由于我们 on-call 团队的支持和文化。
什么是 on-call,其文化为什么重要?在运营和管理中,on-call 的团队通常负责确保服务和应用程序的可靠性和可用性。如果没有建立一个高效的 on-call 团队,将对业务造成明显的后果——直接收入损失和声誉损害。一个不健康的 on-call 团队文化会在一个管理组织中产生压力和挫折感。工程与软件的维护和构建同样重要。如果你一直需要为生产开发中断而担心,那么构建可扩展性的软件是很困难的!
如果处理不当,凌晨 2 点的宕机可能对公司造成损害,也可能让起床处理相关问题的个人感到厌烦和不爽。对于一种健康的 on-call 文化来说,关注这两点问题都很重要。在本文中,我将描述 Button 团队 on-call 管理的最佳实践。

Button 的 on-call 贴纸,由 Cori Huang 设计
在 Button,构建服务的产品工程师还负责保证所有关键服务的 24/7 正常运行时间。为了做到这一点,我们保持每周的 on-call 循环,从周五中午开始,我们会进行一个物理 WiFi 热点切换。同时确保总有两个人能随叫随到——一个是主负责人,一个是后备人员。如果主服务器在接收到由于停机而触发的初始页面请求没有响应或不可用时,该页面请求就会被转到备服务器。还会给工程 on-call 团队配一个业务团队对应人员,负责处理合作伙伴业务的升级和外部通信中断问题。
最后同样重要的是,处于随时待命状态是自愿的。并不是所有的产品工程师都需要参与 on-call,他们也可以随时加入或离开。因为 on-call 是一种独特的责任,而且往往需要作出特别的牺牲,作为回报,Button 每月会给 on-call 团队的每一个成员适当的奖金奖励。
促使on-call 团队成功的因素是什么?以下是我们团队 on-call 文化的一些核心理念:
-
做好入职流程
-
设定正确的目标
-
确定一个关键负责人
-
无保留的检视问题
-
我们的告警理念
-
鼓励自我照顾
从一开始就要为目标的达成做准备。我们不只是在 on-call 的轮换过程中增加人员,并期望他们能做好。我们的入职流程如下:
-
跟随一个当前 on-call 的工程师学习。
-
在一周的工作时间内成为主要负责人员,并在实际工作中逐步提升。
-
自己处理升级——我们会为新工程师模拟升级以便发现问题并解决问题。
-
加入 on-call 的排班序列中。
负责升级并不一定意味着你最终要解决每个问题并找到它们背后的根本原因,也不意味着你需要拥有这样做的专业知识。
下面引用我们升级手册中的一段话:
把它想象成一个医院:急诊室的医生在那里对病人进行前期处理和病情分类,然后把病人送到更专业的护理人员那里。
当我们真的需要处理现场问题时,我们并不需要解决所有问题——我们需要评估问题,确定对业务的影响是什么,通过我们的状态页面进行外部沟通,并尽可能地减少损失。通常情况下,需要执行后续任务以确保升级问题完全解决,而不会让它成为重复发生的事故。我们非常信任我们的工程师能够做出最好的判断,在升级过程中不断做出正确的判断需要经验和实践。
确定一个关键负责人有时高压升级可能是混乱的。可能有很多人参与其中,或者有很多系统在起作用,因此跟踪升级中的变化以及谁在做什么变得非常重要。我们遵循的理念是,在任何时候都由一个关键人物来负责升级响应。
我们的手册是这样描述的:
在升级过程中,该人对所有决策负责,包括生产变更,以及决定与其他方进行沟通的时间和内容。如果你不是关键人物,你就不应该做这些事情,除非关键人物明确要求并指示你去帮助他。
无保留的检视问题在升级过程中,关键人员可以更改 ; 只要它是明确的 (例如,“生产问题已经解决,Barry 将接过任务作为新的关键负责人。”)
我们努力从自己的错误中吸取教训,其中很大一部分是一种不要进行指责的事后自检文化。
不进行指责的事后分析让我们能够诚实而大胆地谈论我们本可以做得更好的事情,并反思我们所学到的东西。这些是工程师们提倡对现有流程进行关键基础设施改进或更改的地方。这为公司的其他成员提供了一个机会来权衡和讨论业务影响,并设定未来的期望。
问题检视也是深入研究问题根源的方式。我们坚信会有一个神秘的刺针——如果我们的生产系统以一种我们没有预料到的方式运行,我们想知道原因。
我们的告警理念
Prometheus 的 logo
我们使用普罗米修斯作为告警文化的一部分。告警规则会提交给 Github 和同行评审。Alertmanager 向 PagerDuty、email 和 Slack 发送告警提醒。我们有三种不同类型的告警:
-
非分页警报: 仅向电子邮件和 Slack 发送警报 。
-
日间分页提醒: 在白天向 PagerDuty 发送提醒,但在其他情况下只发送到电子邮件和 Slack。
-
寻呼警报: 随时向 PagerDuty、email 和 Slack 发出警报。
团队中的任何工程师都有权添加或删除警报,但所有警报都应该是可操作的,并且必须有一个问题报告。我们的报告应该是简短的,说明当警报被触发时可以采取的具体行动。每个报告条目都包含对业务影响、有用的 bash 命令和到适当指示板的链接的简要描述。我们的目标是让任何工程师,不管他们有多少上下文,都能够使用报告中的信息来快速定位问题。
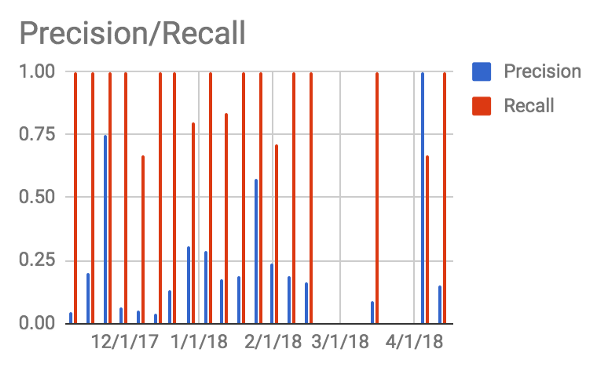
发送到 Button on-call 团队的页面请求的准确率和召回率
为了追踪我们的警报是否真正具有可操作性,我们借用了一些数据科学的概念,并测量了警报的准确率和召回率。在本例中,准确率指的是触发可操作性告警的百分比,召回率指的是警报通知我们的可操作性事件的百分比。当准确率较低时,我们会评估是否应该禁用或修改特定警报以在较低的阈值上触发。当召回率低的时候,我们试着看看是否有更好的信号来衡量我们应该应对的实际症状。
鼓励自我照顾无论是晚上被打电话,还是要重新安排晚餐时间,on-call 都可能破坏你的个人生活。然而,如果设置得当,on-call 不应该成为任何个人的不应有的负担。下面是 Button 的 on-call 团队确保我们的工程师不会精疲力竭的几种方法:
-
在一周结束的时候,我们会尽量安排另外的人进行轮换。如果有明确的问题,我们会关闭它们或将它们交给产品团队去处理。
-
我们维护一个 on-call 的历史记录,所以如果升级时某个问题重新出现,你可以看到以前的工程师是如何处理和解决它的。
-
在处理升级时,我们的 on-call 工程师使用 Slack 来一步步的沟通他们的决策和操作行为,以便其他人能够跟进。
-
我们的 on-call 日程很灵活。如果有人需要休息几个小时,我们会查看运营状态表,看看是否有人可以替代。如果某人是今晚的主要负责人,第二天我们鼓励换一个人做这件事,这样他们就可以得到他们应该得到的休息。
-
我们被鼓励并准备好在工作时间内外寻求帮助。没有什么比看到一个你根本不知道如何下手的任务更令人沮丧的了。我们知道,寻求帮助总是比按照错误的假设行事更好。我们将 on-call 的团队的联系信息存储在值班表中,以便在工作时间以外出现紧急情况时,我们能够联系到相关人员。
Button 现在的规模不适合期望每个工程师都知道每个服务是如何工作的。我们的 on-call 工程师不仅来自不同的工程学科,而且在 Button 的不同产品团队中工作。不是每个人都是 DevOps 专家,当然也不是每个人都熟悉我们系统中的每一个软件。然而,我们作为一个团队互相支持,帮助对方成长为我们的优势,克服挑战,学习新的技能。on-call 的经历教会了我如何设计和构建更好的软件,如何清晰地沟通,以及如何成为一个更有同理心的队友。
英文原文:
https://medium.com/@WomenWhoCode/fostering-a-strong-engineering-on-call-culture-9df5fd727736
