


在这个Keras教程中,您将发现开始使用深度学习和Python是多么容易。您将使用Keras深度学习库来在自定义图像数据集上训练您的第一个神经网络,并且您也将实现第一个卷积神经网络(CNN)。
这个指南的灵感来自PyImageSearch读者Igor,他几周前给我发了电子邮件这样问到:
嘿,Adrian,谢谢PyImageSearch上的精彩博客。我发现几乎每个Keras或图像分类“入门指南”都使用内置在Keras的MNIST或CIFAR-10数据集。我只需调用这些函数中的一个,数据就自动加载。
但是我该如何在Keras上使用自己的图像数据集呢?我必须采取什么步骤?
Igor是对的——您遇到的大多数Keras教程都试图使用图像分类数据集(如MNIST(手写识别)或CIFAR-10(基本对象识别)来教您库的基本知识。
这些图像数据集是计算机视觉和深度学习文献中的标准基准,当然,它们绝对会让你开始使用Keras……
...但它们不一定实用,因为它们没有教你如何处理磁盘上的一组图像。相反,您只是调用助手函数来加载预编译数据集。
我将给大家带来一个全新的与众不同的Keras教程。
我将教你如何利用这些预先编译的数据集,而不是教你如何使用定制的数据集来训练你的第一个神经网络和卷积神经网络,说实话,你的目标是将深度学习应用到你自己的数据集,而不是内置的Keras,我说的对吗?
学习如何开始Keras,深度学习,和Python,继续阅读!
引言
今天的Keras教程是针对实践人员设计的——这是实践人员应用深度学习的方法。
这意味着我们用实践学习,并亲手编写一些Keras代码,然后在我们的自定义数据集上训练我们的网络。
本教程并不意味着深入学习围绕深度学习的理论。
如果您想深入地研究深度学习,包括动手实现和理论讨论,我建议您看看我的书《使用Python进行计算机视觉的深度学习》。
概述:包括什么内容呢
用Keras训练第一个简单的神经网络不需要很多代码,但是我们将慢慢开始,逐步进行,确保您理解如何在自己的自定义数据集上训练网络。
我们今天要讨论的步骤包括:
- 在系统上安装Keras和其他依赖项
- 从磁盘加载数据
- 创建训练和测试分支
- 定义您的Keras模型体系结构
- 编译你的Keras模型
- 训练你的训练数据模型
- 在测试数据上评估模型
- 用训练的Keras模型进行预测
我还增加了一个训练你的第一个卷积神经网络的部分。
这看起来像是很多步骤,但我向你保证,一旦我们开始进入示例,您将看到示例是线性的,具有直观的意义,并且将帮助您理解用Keras训练神经网络的基本原理。
我们的示例数据集

图1:在这个KARAS教程中,我们不会使用CiFoE10或MNIST用于我们的数据集。相反,我将向您展示如何组织自己的图像数据集,并使用Keras的深度学习训练神经网络
大多数你遇到的解决图像分类问题的Keras教程都会使用MNIST或CIFAR-10——我不打算这样做。
首先,MNIST和CIFAR-10已经不是什么新鲜的例子了。
这些教程实际上不涉及如何使用自己的自定义图像数据集。相反,他们简单地调用内置的Keras实用程序,奇迹般地返回MNIST和CIFAR-10数据集作为Numpy数组。事实上,你的训练和测试分裂已经为你预分了!
其次,如果你想使用你自己的自定义数据集但又真的不知道该从哪里入手,你或许已经抓狂并有如下疑问:
- 帮助函数从何处加载数据?
- 磁盘上的数据集应该是什么格式?
- 如何将数据集加载到内存中?
- 我需要执行哪些预处理步骤?
老实说,你在学习Keras和深入学习的目标不是与这些预焙的数据集一起工作。
相反,您希望使用自己的自定义数据集。
你所遇到的介绍性教程只会带你走这么远。
这就是为什么在这个Keras教程中,我们将使用一个名为 “Animals Dataset” 的自定义数据集,我为我的书《使用Python进行计算机视觉的深度学习》创建了这个数据集:

图2:在这个Keras教程中,我们将从我的深度学习书中直接使用一个示例动物数据集。数据集由狗、猫和熊猫组成
该数据集的目的是正确地分类图像包含:
- cats
- dogs
- panda
只包含3000个图像,动物数据集意味着是一个介绍性数据集,我们可以快速训练一个深入的学习模型使用我们的CPU或GPU(并仍然获得合理的准确性)。
此外,使用此自定义数据集使您能够理解:
- 如何在磁盘上分配数据集
- 如何从磁盘加载图像和类标签
- 如何将数据划分为训练和测试分支
- 如何在训练数据上训练第一个Keras神经网络
- 如何评价测试数据的模型
- 如何将你的训练模型重用于全新的数据,并在训练和测试之外进行分割
通过遵循此Keras教程中的步骤,您将能够用任何数据集来代替我的动物数据集,前提是您可以使用下面详细描述的项目/目录结构。
需要数据吗?如果你需要从网上苦苦搜寻图像来创建一个数据集,可以看看the easy way with Bing Image Search它,或者slightly more involved way with Google Images.。
项目结构
有许多与此项目关联的文件。从“下载”部分抓取zip,然后使用 tree 命令显示终端中的项目结构(我已经为 tree 提供了两条命令行参数标志,以使输出美观和整洁):
$ tree --dirsfirst --filelimit 10
.
├── animals
│ ├── cats [1000 entries exceeds filelimit, not opening dir]
│ ├── dogs [1000 entries exceeds filelimit, not opening dir]
│ └── panda [1000 entries exceeds filelimit, not opening dir]
├── images
│ ├── cat.jpg
│ ├── dog.jpg
│ └── panda.jpg
├── output
│ ├── simple_nn.model
│ ├── simple_nn_lb.pickle
│ ├── simple_nn_plot.png
│ ├── smallvggnet.model
│ ├── smallvggnet_lb.pickle
│ └── smallvggnet_plot.png
├── pyimagesearch
│ ├── __init__.py
│ └── smallvggnet.py
├── predict.py
├── train_simple_nn.py
└── train_vgg.py
7 directories, 14 files
如前所述,今天我们将使用的是动物数据集。注意如何在项目树中分配 animals。在 animals 内部,有三个类目录:cat/、dogs/、panda/。这些目录中的每一个都是对应于相应类的1000个图像。
如果你使用你自己的数据集,就用同样的方式分配它!理想情况下,每类你至少需要收集1000个图像。这并不总是可能的,但你至少应该有类别平衡。一个类文件夹中的图像偏多可能会导致模型偏差。
接下来是 image/ 目录。这个目录包含三个用于测试目的的图像,我们将用它们演示如何从磁盘加载经过训练的模型,然后对不属于原始数据集的输入图像进行分类。
output/ 文件夹包含三种类型的文件,这些文件是通过训练生成的:
- .model :训练后生成一个序列化的Keras模型文件,可以用于将来的推理脚本。
- .packle :序列化的标签二值化文件。这个文件包含一个包含类名的对象。它伴随着一个模型文件。
- .png :我总是把我的训练/验证绘图图像放在输出文件夹中,因为它是训练过程的输出。
Pyimagesearch 目录是一个模块。与我收到的许多问题相反,Pyimagesearch 不是一个可安装的 pip 程序包。相反,它驻留在项目文件夹中,包含在其中的类可以导入到您的脚本中。它在Keras教程的“下载”部分提供。
今天我们将回顾四个 .py 文件:
- 在博客文章的前半部分,我们将训练一个简单的模型。训练脚本是train_simple_nn.py。
- 我们将使用 train_vgg.py 脚本来培训SmallVGGNET.
- smallvggnet.py 文件包含我们的SmallVGGNET类和一个卷积神经网络。
- 序列化模型有什么好处,除非我们可以部署它?在 predict.py 中,我为您提供了一个示例代码,用于加载一个序列化的“模型+标签”文件并对图像进行推理。预测脚本是有用的,我们已经成功地训练了一个模型,具有合理的准确性。运行此脚本以测试不包含在数据集内的图像总是有用的。
1. 在系统上安装Keras

图3:我们将使用Kras和TysFLOW后端来介绍KRAS的深度学习博客文章
对于今天的教程,您需要安装Keras、TensorFlow和OpenCV。
如果你的系统还没有这个软件,就先不要莽撞行事!我已经编写了一些易于遵循的安装指南。我也在定期更新它们。以下是你需要的:
- OpenCV安装指南——这个启动板链接到帮助您在Ubuntu、MacOS或Raspberry Pi上安装OpenCV的教程。
- 安装Keras与TensorFlow -你将与Keras和TensorFlow运行不到两分钟,感谢 pip 。你可以在Raspberry Pi上安装这些软件包,但是,我建议不要用你的Pi来训练。预先训练和适当大小的模型(比如我们今天介绍的两个模型)可以很容易地在Pi上运行,但是请确保首先训练它们!
- 安装imutil、scikit-learning和matplotlib——确保也安装这些包(理想情况下是在虚拟环境中)。安装 pip 很容易:
$ workon <your_env_name> # optional
$ pip install --upgrade imutils
$ pip install --upgrade scikit-learn
$ pip install --upgrade matplotlib
2. 从磁盘加载数据
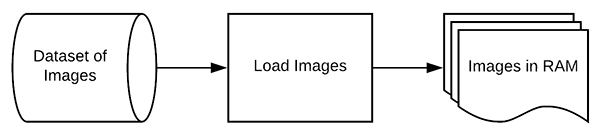
图4:我们的Keras教程的步骤第2步是将图像从磁盘加载到内存中
现在,我们系统上已经安装好了Keras,我们可以开始使用Keras来实现我们的第一个简单的神经网络训练脚本。我们稍后将实现一个完整的卷积神经网络,但让我们轻松地开始实现吧。
打开 train_simple_nn.py 并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.models import Sequential
from keras.layers.core import Dense
from keras.optimizers import SGD
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
import os
第2-19行导入我们需要的包。正如你所看到的,这个脚本有很多工具在利用。让我们回顾一下重要的事情:
- matplotlib :这是Python的绘图程序包。也就是说,它确实有它的细微差别,如果你遇到问题,请参阅这篇博客文章。在第3行,我们指示 matplotlib 使用"agg"后端使我们能够将绘图保存到磁盘——这是您的第一个细微差别!
- sk learn:scikit-learning库将帮助我们将标签二值化,将用于训练/测试的数据分割,并在我们的终端中生成训练报告。
- keras:您正在阅读本教程以了解Keras——它是我们进入TensorFlow和其他深度学习后端的高级前端。
- imutils:我的一套函数扩展包。我们将使用路径模块来生成用于训练的图像文件路径列表。
- Numpy:用Python进行数值处理。这是另一种包装方式。如果你已经安装了Python和skiti-learn的OpenCV,那么你就有了Numpy,因为它是一个依赖项。
- cv2:也就是OpenCV。一般老说是用2,但是你也很有可能使用OpenCV 3或更高。
- 剩余的导入被内置到Python的安装中!
额,这的确很多,但是当我们浏览这些脚本时,对每个导入用于什么有一个概念将有助于您理解。
让我们用argparse模块解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset of images")
ap.add_argument("-m", "--model", required=True,
help="path to output trained model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", required=True,
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
当执行脚本时,我们的脚本将动态处理通过命令行提供的附加信息。附加信息以命令行参数的形式出现。将 argparse 模块内置到Python中,并将处理解析您在命令字符串中提供的信息。如需进一步解释,请参阅此博客文章。
我们有四个命令行参数解析:
- dataset:磁盘上的图像数据集的路径。
- model :我们的模型将被序列化并输出到磁盘。此参数包含输出模型文件的路径。
- label-bin:Dataset 标签被序列化到磁盘,以便于在其他脚本中进行回溯。这是输出标签二值化器文件的路径。
- plot:输出训练绘图图像文件的路径。我们将检查这个图以检查数据是否过/欠拟合。
使用数据集信息,让我们加载我们的图像和类标签:
# initialize the data and labels
print("[INFO] loading images...")
data = []
labels = []
# grab the image paths and randomly shuffle them
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# loop over the input images
for imagePath in imagePaths:
# load the image, resize the image to be 32x32 pixels (ignoring
# aspect ratio), flatten the image into 32x32x3=3072 pixel image
# into a list, and store the image in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (32, 32)).flatten()
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
这里我们:
- 初始化我们的 data 和 label 的列表(第35行和第36行)。这些将随后成为Numpy数组。
- 抓取 imagepaths 并随机洗牌(第31-41行)。在排序和 shuffle 之前, paths.list_image 函数将方便地查找到--dataset目录中所有输入图像的所有路径。设置 seed ,以便随机重新排序是可重复的。
- 开始在数据集(第44行)中循环所有 imagepaths 。
对于每个图像路径,我们着手:
- 将 image 加载到内存中(第48行)。
- 将 image 调整为 32×32 像素(忽略纵横比),并使图像flatten (第49行)。适当地resize 我们的图像是至关重要的,因为这个神经网络需要这些尺寸。每个神经网络都需要不同的维度,所以请注意这一点。平坦化数据允许我们轻易地将原始像素强度传递到输入层神经元。您稍后会看到,对于VGGNET,从卷积开始,我们将卷传递给网络。请记住,这个例子只是一个简单的非卷积网络——我们将在博客后面看到一个更高级的例子。
- 将调整大小的图像追加到 data(第50行)。
- 从路径中提取图像的类 labels(第54行)并将其添加到 labels列表(第55行)。labels 列表包含对应于数据列表中的每个图像的类。
现在,我们可以将数组操作应用到数据和标签:
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
在第58行,我们从范围[0, 255 ]到[0, 1 ]缩放像素强度(一个共同的预处理步骤)。
我们还将 labels 列表转换为Numpy数组(第59行)。
3. 构建你的训练和测试分支
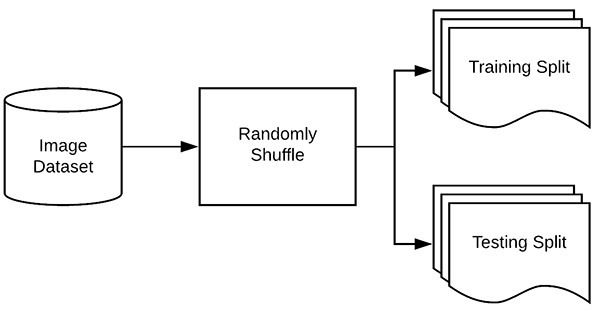
图5:在装配一个深度学习或机器学习模型之前,你必须把你的数据分割成训练和测试集。在这篇博客文章中使用Scikit-learn来分割我们的数据
现在我们已经从磁盘加载了图像数据,接下来我们需要构建我们的训练和测试分割:
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.25, random_state=42)
典型的是,要为训练分配一部分数据,而要测试的数据比例要小一些。Scikit-learn提供了一个方便的train_test_split 函数,它将为我们分割数据。
trainX和testX都是图像数据本身,而trainY和testY则构成了标签。
我们的类标签目前被表示为字符串,然而,Keras将假设这两个:
- 标签被编码为整数。
- 此外,在这些标签上执行一个热编码,使每个标签表示为向量而不是整数。
为了实现这一编码,我们可以使用 LabelBinarizer 类:
# convert the labels from integers to vectors (for 2-class, binary
# classification you should use Keras' to_categorical function
# instead as the scikit-learn's LabelBinarizer will not return a
# vector)
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
在第70行,我们初始化 LabelBinarizer 对象。
调用 fit_transform 发现 trainY 中所有唯一的类标签,然后将它们转换成一个热编码标签。
对 testY中 .transform 的调用只需执行一个热编码步骤——可能的类标签的唯一集合已经通过调用 fit_transform 来确定。
下面是一个例子:
[1, 0, 0] # corresponds to cats
[0, 1, 0] # corresponds to dogs
[0, 0, 1] # corresponds to panda
请注意,只有一个数组元素是“热”,这就是为什么我们称之为“one hot ”编码。
4.定义您的Keras模型体系结构
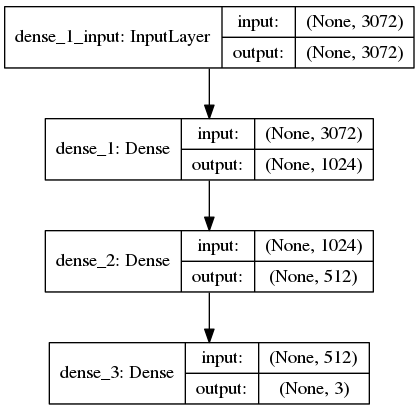
下一步是使用Keras定义我们的神经网络体系结构。在这里,我们将使用具有一个输入层、两个隐藏层和一个输出层的网络:
# define the 3072-1024-512-3 architecture using Keras
model = Sequential()
model.add(Dense(1024, input_shape=(3072,), activation="sigmoid"))
model.add(Dense(512, activation="sigmoid"))
model.add(Dense(len(lb.classes_), activation="softmax"))
由于我们的模型非常简单,所以我们继续在这个脚本中定义它(通常我喜欢在模型体系结构的单独文件中创建单独的类)。
输入层和第一隐藏层在第76行上定义。将有 3072 的 input_shape,因为在平移输入图像中有32×32×3=3072个像素。第一个隐藏层将有1024个节点。
第二隐藏层将有512个节点(第77行)。
最后,在最终输出层(第78行)中的节点数量将是可能的类标签的数量——在这种情况下,输出层将具有三个节点,每个节点用于我们的类标签(“cats”、“dogs”和“panda”)。
5.编译你的KRAS模型
图7:我们的KARAS教程的第5步要求我们用优化器和丢失函数编译模型
一旦我们定义了我们的神经网络体系结构,下一步就是“编译”它:
# initialize our initial learning rate and # of epochs to train for
INIT_LR = 0.01
EPOCHS = 75
# compile the model using SGD as our optimizer and categorical
# cross-entropy loss (you'll want to use binary_crossentropy
# for 2-class classification)
print("[INFO] training network...")
opt = SGD(lr=INIT_LR)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
首先,我们初始化我们的学习率和历元总数来训练(第81行和第82行)。
然后以“categorical_crossentropy”为损失函数,采用随机梯度下降法(SGD)优化器对模型进行了compile 。
分类交叉熵被用作几乎所有被训练来执行分类的网络的损失。唯一的例外是2类分类,其中只有两个可能的类标签。在这种情况下,你会想要交换“categorical_crossentropy”,用于“binary_crossentropy”。
未完待续!
