

本文最早于 2018 年 5 月 30 日发表(原文链接)。在前端和后端服务器的数据交互过程中,前端工程师希望使用GraphQL来灵活定制接口,实现快速迭代;而后端工程师希望使用Thrift来保证接口的稳定性和特异性。本文将讲述前端工程师和后端工程师如何在Airbnb进行合作,利用两者的优点,构建出满足所有人需求的数据交互框架。
作者:Adam Neary,Airbnb 工程师
译者:Kun Chen,Airbnb 中国工程经理
校对:Bobby Li,Airbnb 中国工程师
后端工程师: Hmm,所以你的意思是如果我们使用GraphQL,任何web和native工程师都可以在后端工程师完全不知晓的情况下,从后端服务中递归地查询任何字段?
前端工程师: 是的,是不是听起来非常酷啊!
【...沉默中...】
后端工程师: 保安,把这个人拖出去!
多年以来,一直有人尝试在 Airbnb 内部推广使用 GraphQL,但没有成功。主要原因是我们觉得 GraphQL 的整体思想不适合面向服务的架构(SOA)。在 Airbnb 的后端架构中,不同服务之间是使用 Thrift 定义的接口进行数据传输的,最终数据通过专门的展现服务层(presentation service)返回给客户端。而 GraphQL 的思想是让所有的数据构成一个图,客户端可以自顶向下任意访问图中的数据,这与展现服务层的设计是冲突的。
最近我们重新设计了一套方案,来实现支持 GraphQL 的 API 层。这个方案是将 GraphQL 作为展现服务层的扩展,而不是替代它。接下来我们将介绍 Airbnb 是如何建立这个架构的,以及为什么要这么做。如果你的使用场景和我们类似,或者需要做类似的取舍,这篇文章应该会对你有所帮助。
Thrift和展现服务层框架
我们强烈建议您在阅读下面的内容之前先阅读《Building Services at Airbnb》这篇文章的第一部分和第二部分。简单来说,以前 Airbnb 后端采用的是共享的单一资源模型(比如 Rails 里面全局的 @listing 房源数据模型),在这种架构下,某一个组对代码的改动很容易不小心破坏另外一个组的代码和业务。现在 Airbnb 正在摒弃这种架构,转而使用面向服务的架构(SOA),并在这个方向上取得了非常大的进展。
在面向服务的架构下,我们使用 Thrift 来定义不同服务之间通信 request 和 response 的格式。比如我们有各种各样的产品都会需要图片相关的功能,于是我们构建了一个内部的图片处理服务,该服务的接口定义如下:
# === Data Objects ===
typedef i64 PictureId
typedef string EntityId
typedef string JsonString # Give engineers a hint about how metadata will need ser/des
struct Picture {
1: optional PictureId id (non_null)
2: optional date_time createdAt (non_null)
3: optional date_time updatedAt (non_null)
4: optional EntityId entityId (non_null)
5: optional i32 sortOrder (non_null)
6: optional string imagePath (non_null)
7: optional JsonString metadata (non_null)
8: optional i32 metadataVersion (non_null)
}
struct NewPicture {
1: optional EntityId entityId (non_null)
2: optional string imagePath (non_null)
3: optional JsonString metadata (non_null)
}
# === Requests ===
struct PictureCollectionRequest {
1: optional EntityId entityId (non_null)
2: optional i32 limit
}
struct AppendPictureRequest {
1: optional EntityId entityId (non_null)
2: optional NewPicture picture (non_null)
}
# === Responses ===
struct PictureCollectionResponse {
1: optional list<Picture> pictures (non_null)
2: optional EntityId entityId (non_null)
3: optional i32 count (non_null)
4: optional i32 limit
}
struct AppendPictureResponse {
1: optional Picture picture (non_null)
}
# === Service ===
service PictureService {
picture_data.PictureCollectionResponse index(1: picture_data.PictureCollectionRequest request)
throws (1: picture_data.IdlReadException ex)
resource (accept_replay = "true", idempotent = "true")
picture_data.AppendPictureResponse create(1: picture_data.AppendPictureRequest request)
throws (
1: picture_data.IdlConsistentWriteException ex1,
2: picture_data.IdlInconsistentWriteException ex2,
3: picture_data.IdlReadException ex3
)
resource (accept_replay = "false", idempotent = "false")}
}
而对于 API 层,由于 Airbnb 经常进行大量的产品迭代及 A/B 实验,我们需要不断地改变 API 返回的数据。为了减少对底层服务的更改,我们构建了一个叫做展现服务的中间层。该展现层和具体的前端业务逻辑相关,它负责从不同的后端服务获取数据,进行一些业务逻辑处理,然后将数据组合后返回给前端使用。
service LuxuryHomePresentationService {
# Retrieves data from listing, images, and other downstream services
LuxuryHomeResponse getLuxuryListingsById(1: LuxuryListingsByIdRequest request)
# Retrieves data from reviews service
LuxuryHomeReviewsResponse getReviewsByListingId(1: ReviewsByListingIdRequest request)
# Retrieves data from pricing service
LuxuryHomeQuoteResponse getLuxuryListingQuote(1: LuxuryListingQuoteRequest request)
# Retrieves data from experiences service
LuxuryHomeServicesResponse getServicesByListingId(1: LuxuryServicesRequest request)
}
展现服务层组合成的数据会直接映射成 RESTful API 接口供前端访问(比如上面的例子中 getReviewsByListingId 可以直接通过 /api/luxury/reviews/123 接口访问)。由于 Thrift 在语义上就支持版本控制,我们 API 的版本控制可以直接和 Thrift 挂钩。
关于 GraphQL 思想
在 Airbnb 现有的展现服务层架构下,不直接用 GraphQL 的理由是显而易见的。举一个很常见的例子:如果使用 GraphQL,后端工程师在房源详情中加了一个叫做 bathroom_label 的字段(用来格式化显示卫生间的数量,比如“2个卫生间”,计算这个字段需要访问我们的翻译服务);几个月之后,客户端工程师把这个字段加入到了搜索结果中(比如想在搜索结果页面也显示卫生间数量)。于是大家突然发现搜索的性能降低了 100ms,原因是这触发了 n+1 查询问题(对于每一个搜索结果都需要请求一次翻译服务)。这个问题可能需要后端工程师来修复,即使他们并没有改任何代码。长此以往,后端工程师和客户端工程师就会为了责任划分、性能管控、数据准确性、接口格式等问题进行激烈争论。

从上面的例子,可想而知 GraphQL 的倡导者在 Airbnb 受到的阻力有多大:如果将所有数据组织为一张图,且允许客户端工程师随意访问任何数据,那么现有的展示服务层架构会一直面临同样的问题,而且需要永无止境的修复。
我们一直以为的是 GraphQL 只能用来替换现有架构,而不能与现有框架共存。如果使用GraphQL来代替现有的架构,后端工程师会发现即使他们不提交任何代码,他们负责的服务仍然会突然出现性能问题。而且服务等级协议、接口协议以及服务可观测性都将不复存在,维护服务的性能也更加困难,这都是我们无法接受的。
在API层中使用GraphQL
不过,大概6个月前,我们又重新开启了关于 GraphQL 的讨论。这次讨论的起点是 Apollo,因为它带来的好处实在太吸引人了:
- 强类型的 API schema
- 可以灵活选择需要获取的字段,不管是在宏观上(比如如果不需要就不用去请求一个很耗时的操作),还是微观上(比如不用去请求那些不会被使用到的字段)
- 客户端开发的跨平台性(Web, iOS和Android),不用依赖后端工程师对API数据进行迭代
- Apollo生态系统给客户端开发带来的各种好处,比如缓存,本地数据状态和网络数据状态的一致性管理,字段级别的统计和分析等等
基于以往的经验,我们提出了下面这个架构:
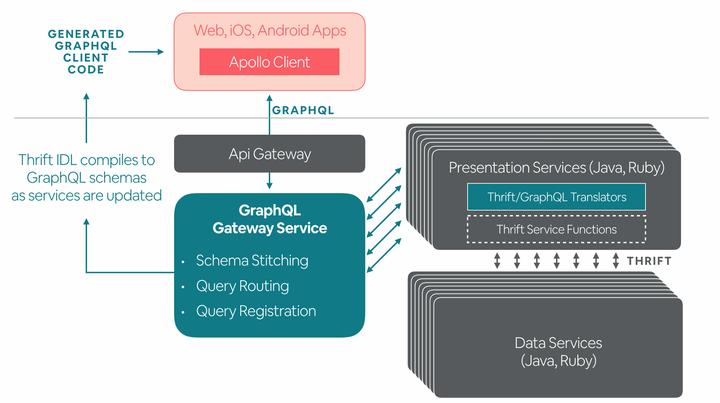
Thrift/GraphQL 转换器:一个简单的例子
考虑到 Airbnb 面向服务的架构,我们没有去构建一个单一的 GraphQL 服务器来解析和执行 GraphQL 查询。我们采取的方案是在各个展现服务层中内嵌一个转换器,该转换器能够自动将 Thrift 定义的 structs 和 service 函数转换成 GraphQL 的 schema 定义,并将它们串起来。
例如对于上面的 LuxuryHomePresentationService 这个例子,通过转化器我们能够自动得到以下的 GraphQL schema:
type LuxuryHome {
luxuryListingsById(listingId: ID!): LuxuryHomePdp
reviewsByListingId(listingId: ID!): LuxuryHomeReviews
luxuryListingQuote(listingId: ID!): LuxuryHomeQuotes
servicesByListingId(listingId: ID!): LuxuryHomeServices
}
于是我们能够运行下面的 GraphQL 查询:
query LuxuryHomeQuery {
luxuryHome {
listings: luxuryListingsById(listingId: 123) {
id
bathrooms
bedrooms
heroMedia {
landscapePicture {
imageUrl
}
}
}
reviews: reviewsByListingId(listingId: 123) {
// ...
}
quote: luxuryListingQuote(listingId: 123) {
// ...
}
}
}
值得注意的是,基于性能考虑我们禁止了递归查询和链式查询。举一个例子,我们不希望客户端先通过房源 ID 拉取到房源数据,再通过房源数据里的评论 ID 数组去拉取所有评论数据。相反,房源的所有评论数据应该调用 reviewsByListingId 通过房源 ID 来获取,这样使得所有数据可以并行查询。
你觉得这里面最让人兴奋的一点是什么?当然是所有的 GraphQL 查询逻辑和 schema 定义全部都是通过展现服务层定义的 Thrfit 自动构建出来的!作为一个后端工程师,如果想让自己负责的展现服务层支持 GraphQL,只需把转换器模块包含进来即可!
Thrift/GraphQL 转换器:Unions和Interfaces
在 Airbnb,大约一半的 API 接口是直接返回数据模型的,就如之前房源数据的例子。客户端拿到这些数据后,按照本地已经定义好的逻辑进行 UI 渲染。
同时我们也有一半接口是由服务端决定客户端的 UI 渲染逻辑。服务器会下发不同的 sections,客户端根据 section 的类型进行不同的 UI 渲染。
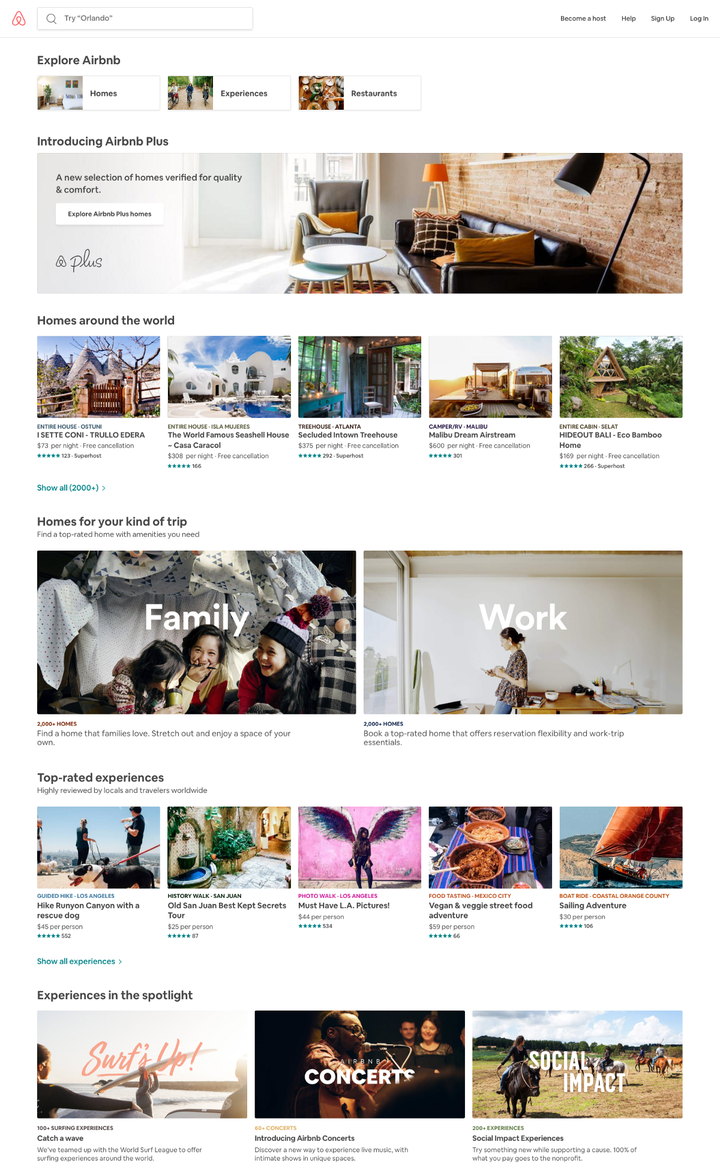
搜索页面就是一个很好的例子。客户端在搜索时不是请求一种固定的数据模型,而是提交搜索类型及搜索条件;服务器则是根据客户端请求,将一系列数据组合成动态页面返回。这使得客户端UI渲染更加“无脑”,不用再根据原始数据决定展示逻辑,只需要将服务器返回的不同 section 渲染出来即可。
在上面的搜索首页截图中,整个页面从上到下包含了好几个 section,第一个 section 包含了几个可以点击的业务分类(房源、体验、餐馆),下面的 section 是我们新上线的爱彼迎 Plus相关的信息,接下来的 section 是一个房源卡片的列表,里面包含来自全球的精选房源。当搜索洛杉矶的房源的时候,整个页面的 sections 可能会完全不一样,比如可能会先显示一个推荐餐厅的 section,接下来的 section 是这个城市你之前浏览过的的房源卡片列表,等等。简而言之,整个搜索页面的 UI 完全是由 API 来驱动的。
幸运的是,GraphQL 的 interfaces 和 unions 可以完美支持这种场景。我们只需要定义 sections 所有可能的类型,以及每种类型所包含的字段即可。由于 Thrift 也支持 unions,我们在 Thrift 里面定义的 unions 结构可以直接通过转换器自动转换成 GraphQL Schema。例如对于上面的搜索页面,我们可以定义如下的 Thrift Struct:
struct RefinementItem {
1: optional i32 count
2: optional ExploreImage image
3: optional ExploreSearchParams searchParams
4: optional string title # e.g. Homes, Experiences, Restaurants
5: optional string subtitle
}
struct RefinementSection {
1: optional string title # e.g. Explore Airbnb
2: optional string subtitle
3: list<RefinementItem> refinements
}
struct HomeCarouselItem {
1: optional Listing listing
4: optional PricingQuote pricingQuote
5: optional Verified verified
6: optional bool verifiedCard
}
struct HomeCarouselSection {
1: optional string title # e.g. Homes around the world
2: optional string subtitle
3: list<HomeCarouselItem> listings
4: optional SeeAllInfo seeAllInfo
}
# and so on…
union ExploreSectionContent {
1: RefinementSection refinements
2: HomeCarouselSection homes
21: RecommendationSection recommendationItems
27: InformationalSection informationalItems
28: StorySection stories
29: HomeTourSection homeTours
32: LuxuryListingCarouselSection luxuryListings
33: ExperienceCarouselSection experiences
}
struct ExploreSection {
1: optional string backendSearchId
2: optional string searchSessionid
3: optional string sectionId
4: optional string sectionTypeUid
5: optional ExploreSectionContent content
}
在客户端,我们可以请求这样的GraphQL查询:
{
searchService {
search(filters) {
sections {
sectionId
sectionTypeUid
content {
...on RefinementSection {
title
refinements {
image
searchParams
title
}
}
...on HomeCarouselSection {
title
listings {
id
name
bedroom_label
bathroom_label
localized_city
picture_url
}
seeAllInfo {
link_copy
link_href
}
}
... on InformationalSection {
title
subtitle
messages {
cta_type
cta_button_text
}
}
... on LuxuryListingCarouselSection {
title
subtitle
listings {
id
name
hero_media
bedrooms
bathrooms
location {
lat
lng
localized_location
points_of_interest
}
base_nightly_rate {
amount_formatted
currency
}
}
}
}
}
}
}
}
当然,我们不会在实际代码里这么写 GraphQL 请求。我们会将 LuxuryListingCarouselSection 的定义与 React 组件共享,并通过 CI 自动生成 GraphQL 请求。
当采用服务端驱动的 UI 渲染方式时,API 的版本控制是一个很大的问题。可以看到,使用 GraphQL 可以完美解决这个问题。这里面最棒的地方是由客户端的 GraphQL query 来主动指定请求哪些 section 类型(自然是当前客户端版本能够渲染的 section),以及对于每个 section 类型当前客户端需要的字段。对于像搜索页面这么复杂和频繁迭代的场景,如果我们使用 REST API,可以想象当升级 version(比如新增了一个 section 类型)时前端和后端工程师是多么痛苦。使用 GraphQL 后,各个版本的客户端都只会请求那些它们能支持的类型和字段,这样就大幅提高了前端工程师和后端工程师的工作效率。
API 网关服务和 Query 注册
在我们的架构中,每个展现服务层都嵌入了 GraphQL,各个展现服务层的 GraphQL 是相互独立的(包括 schema 和查询执行逻辑)。但是我们并不希望客户端知道有 n 个不同的 endpoints 存在,我们决定使用一个轻量级的 API 网关服务将所有的展现服务层提供的接口合并起来。这个网关服务包含以下功能:
- 聚合GraphQL Schema:将所有展现服务层的 GraphQL Schema 聚合在一起形成一个单一的 Schema,利用 Apollo 服务器的 Remote Schemas 特性很容易实现。网关在初始化的时候获取和解析所有展现服务层的 GraphQL Schema,并将他们合并在一起,同时通过轮询来监听 Schema 的变化。
- 提供简单的路由功能,将 GraphQL query 转发到相应的展现服务层去执行。
- 我们希望这个网关之后能和 Apollo 引擎对接,提供分析、缓存等功能。
最后,我们构建了自己的 Query 注册机制。我们的 CI 系统会扫描所有的 query,并将它们注册到后台,以便能够在生产环境中使用这些 query。这样做有两个好处:一是提高安全性,只有被注册过 query 才能在生产环境中执行。二是客户端不用每次都发送冗长的完整的 GraphQL query,只需使用 query 注册时生成的 UUID 即可。
展望未来
本文描述的只是我们 GraphQL 相关工作的开端。这周我们刚在生产环境下针对一些访问量较低的接口启用了 GraphQL,但是我们马上会在访问量最高的 API 接口之一开始 GraphQL 相关的实验。如果一切顺利,我们期望能在年底把所有核心业务流程都迁移到 GraphQL。
我们也花了很多时间思考如何更好地使用 Apollo 客户端以及 Apollo 引擎,利用它们让代码更加简洁、性能更好。比如怎么在客户端做数据的持久化,要不要让 Apollo 引擎支持缓存,等等。再加上我们在 service worker 上投入的大量工作,我们期望能将核心页面的加载速度加快 10 倍。
