

由来
最近有个需求需要统计一个方法的耗时,这个方法前后各打出一条日志,类似于 [INFO] 20180913 19:24:01.442 method start/end unique_id,unique_id 是我们框架为了区分每一个请求而生成的唯一ID。
由于在高并发场景下, start 和 end 的日志并不一定是挨着的,很可能方法执行期间,又有其他的日志输出了出来,于是产生了这样的日志:
[INFO] 20180913 19:24:01.442 method start aaa
[INFO] 20180913 19:24:01.452 method start bbb
[INFO] 20180913 19:24:01.456 do something ccc
[INFO] 20180913 19:24:01.562 method end aaa
...由于日志在服务器上,不想再把日志 down 下来,又因为日志比较规范,于是决定自己写个 shell 脚本来处理这些数据。花了一下午时间,换了 4 个 shell 脚本,才优雅地处理了这些数据,其中走进了思维误区,踩了一个扩展问题的大坑。
转载随意,请注明来源地址:zhenbianshu.github.io ,文章持续修订。
初入坑
思路
处理这个问题的第一步,肯定是拿到要处理的这些数据,首先用 grep 命令加输出重定向可以轻松地拿到这些数据,一共 76W。
由于需要考虑不同请求日志的穿插问题,又加上用久了 PHP 的数组和 Java 的 map 而形成的惯性思维,又加上我最近学习的 bash 的关联数据用法,我决定把 start 日志和 end 日志,拆分为两个文件,然后将这些数据生成两个大的关联数组,以 unique_id 为键,以当时的时间戳为值,分别存储请求的开始时间(arr_start)和结束时间(arr_end)。最后再遍历结束时间数组(arr_end),并查找开始时间数组内的值,进行减法运算,将差值输出到另一个文件里。
这样,写出的脚本就是这样:
脚本
#!/bin/bash
# 获取准确时间的函数
function get_acc_time() {
arr=($1)
date_str=${arr[1]}" "${arr[2]}
# date -d "date_str" "+%format" 可以指定输入日期,以替代默认的当前时间
# cut 根据 '.' 切分,并取第二个字段
echo `date -d "$date_str" "+%s"`"."`echo ${arr[2]} | cut -d '.' -f2`
}
# 使用 -A 声明关联数组
declare -A arr_start
declare -A arr_end
# 构造开始时间数组
while read -r start_line
do
arr_start[${arr[5]}]=`get_acc_time $start_line`
done < $start_file
# 构造结束时间数组
while read -r end_line
do
arr_end[${arr[5]}]=`get_acc_time $end_line`
done < $end_file
# 遍历结束时间数组
for request in ${!arr_end[*]}
do
end_time=${arr_end[$request]}
start_time=${arr_start[$request]}
if [ -z "$start_time" ]; then
continue;
fi
# 直接使用 bc 不会显示小数点前的 0
echo `print "%.3f" echo "scale=3;$end_time-$start_time"| bc` >> $out_file
done越陷越深
这个脚本有个缺陷就是它执行得非常慢(后面小节有对它速度的分析),而且中途没有输出,我根本不知道它什么进度,运行了半个小时还没有输出,急于解决问题,我就换了一个方法。
排序并行法
这时我想让它忙尽快有结果输出出来,让我随时能看到进度,而且只有部分结果出来时我也能进行分析。那么有没有办法让我在遍历结束日志
的时候能很轻松地找到开始日志
里面对应的那条请求日志呢?
因为日志是按时间排序的,如果保持其时间序的话,我每次查找开始日志都得在一定的时间范围内找,而且遍历到下一条结束日志后,开始日志的查找起点也不好确定。 如果用上面的日志示例,我查找 unique_id 为 aaa 的请求时,我必须查找 19:24:01.442-19:24:01.562 这一时间范围内的所有日志,而且查找 unique_id 为 bbb 的请求时,无法确定时间起点,如果从开头遍历的话,消耗会非常大。
这个方法肯定是不可行的,但我可以把这些请求以 unique_id 排序,排序后它们会像两条并行的线,就像:
开始日志 aaa bbb ccc ddd eee fff
结束日志 aaa bbb ccc ddd eee fff我只需要记录每一个 unique_id 在结束日志里的的行数,查找开始时间时,直接取开始日志里的对应行就可以了。
使用 sort -k 5 start.log >> start_sorted.log 将日志排下序,再写脚本处理。
#!/bin/bash
function get_acc_time() {
date_str=$1" "$2
acc_time=`date -d "$date_str" "+%s"`"."`echo $2 | cut -d '.' -f2`
echo $acc_time
}
total=`cat $end_file | wc -l`
i=0
while read -r start_line
do
i=`expr $i + 1`
arr_start=($start_line)
# 如果取不到的话去下一行取
for j in `seq $i $total`
do
end_line=`awk "NR==$j" $end_file` // 用 awk 直接取到第 N 行的数据
arr_end=($end_line)
# 判断两条日志的 unique_id 一样
if [ "${arr_start[5]}" = "${arr_end[5]}" ];then
break
fi
i=`expr $i + 1`
done
start_time=`get_acc_time ${arr_start[1]} ${arr_start[2]}`
end_time=`get_acc_time ${arr_end[1]} ${arr_end[2]}`
echo `print "%.3f" echo "scale=3;$end_time-$start_time"| bc` >> $out_file
done < $start_file非常遗憾的是,这个脚本执行得非常慢,以每秒 1 个结果的速度输出,不过我还没有技穷,于是想新的办法来解决。
全量加载法
这次我以为是 awk 执行得很慢,于是我想使用新的策略来替代 awk,这时我想到将日志全量加载到内存中处理。 于是我又写出了新的脚本:
#!/bin/bash
function get_time() {
date_str=$1" "`echo $2 | cut -d '.' -f1`
acc_time=`date -d "$date_str" "+%s"`"."`echo $2 | cut -d '.' -f2`
echo $acc_time
}
SAVEIFS=$IFS # 保存系统原来的分隔符(空格)
IFS=$'\n' # 将分隔符设置为换行,这样才能将文件按行分隔为数组
start_lines=(`cat $start_file`)
end_lines=(`cat $end_file`)
total=`cat $end_file | wc -l`
i=0
IFS=$SAVEIFS # 将分隔符还设置回空格,后续使用它将每行日志切分为数组
for start_line in ${start_lines[*]}
do
arr_start=($start_line)
for j in `seq $i $total`
do
end_line=${end_lines[$j]}
arr_end=($end_line)
if [ -z "$end_line" -o "${arr_start[5]}" = "${arr_end[5]}" ];then
break
fi
i=`expr $i + 1`
done
i=`expr $i + 1`
start_time=`get_time ${arr_start[1]} ${arr_start[2]}`
end_time=`get_time ${arr_end[1]} ${arr_end[2]}`
echo `print "%.3f" echo "scale=3;$end_time-$start_time"| bc` >> $out_file
done脚本运行起来后,由于需要一次加载整个日志文件,再生成大数组,系统顿时严重卡顿(幸好早把日志传到了测试机上),一阵卡顿过后,我看着依然每秒 1 个的输出沉默了。
新的思路
这时终于想到问一下边上的同事,跟同事讲了一下需求,又说了我怎么做的之后,同事的第一反应是 你为啥非要把日志拆开?
,顿时豁然开朗了,原来我一开始就错了。
如果不把日志分开,而是存在同一个文件的话,根据 unique_id 排序的话,两个请求的日志一定是在一起的。再用 paste 命令稍做处理,将相邻的两条日志合并成一行,再使用循环读就行了,命令很简单: cat start.log end.log | sort -k 5 | paste - - cost.log,文件生成后,再写脚本来处理。
#!/bin/bash
function get_time() {
date_str=$1" "`echo $2 | cut -d '.' -f1`
acc_time=`date -d "$date_str" "+%s"`"."`echo $2 | cut -d '.' -f2`
echo $acc_time
}
while read -r start_line
do
arr_s=($start_line)
start_time=`get_time ${arr_s[1]} ${arr_s[2]}`
end_time=`get_time ${arr_s[5]} ${arr_s[6]}`
# 每行前面输出一个 unique_id
echo -e ${arr_s[5]}" \c" >> $out_file
echo `print "%.3f" echo "scale=3;$end_time-$start_time"| bc` >> $out_file
done < $start_file再次运行,发现速度虽然还不尽如人意,但每秒至少能有几十个输出了。使用 split 将文件拆分为多个,开启多个进程同时处理,半个多小时,终于将结果统计出来了。
脚本运行速度分析
问题虽然解决了,但脚本运行慢的原因却不可放过,于是今天用 strace 命令分析了一下。 由于 strace 的 -c 选项只统计系统调用的时间,而系统调用实际上是非常快的,我更需要的时查看的是各个系统调用之间的时间,于是我使用 -r 选项输出了两个步骤之间的相对时间,统计了各步骤间相对时间耗时。
read 慢


从统计数据可以看到它的很大一部分时间都消耗在 read 步骤上,那么, read 为什么会这么慢呢?
仔细检视代码发现我使用很多 ` 创建子进程,于是使用 stace 的 -f 选项跟踪子进程,看到输出如下: 
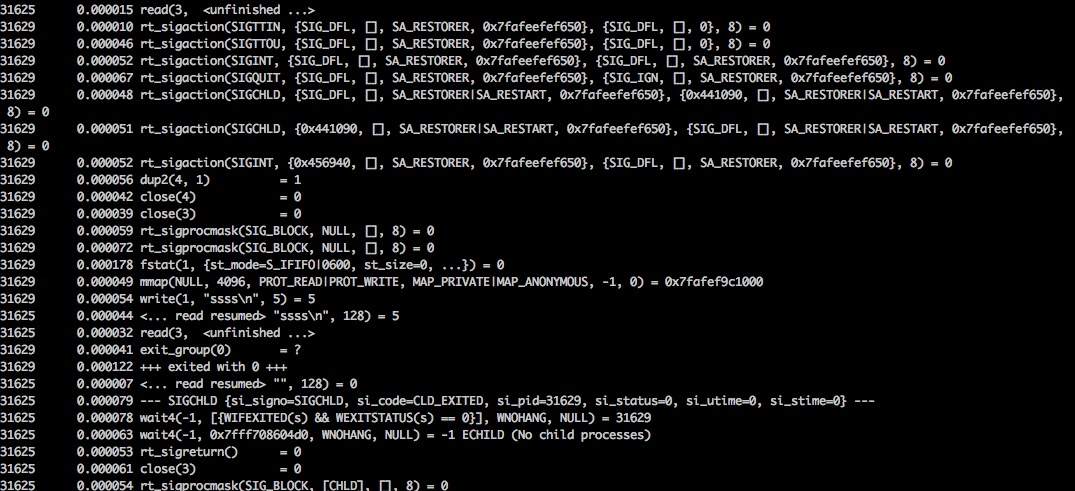
可以看出进程创建一个子进程并执行命令,到最后回收子进程的消耗是很大的,需要对子进程进行信号处理,文件描述符等操作。最终工作的代码只有一个 write 且耗时很短。
由于脚本是完全同步运行的,所以子进程耗时很长,主进程的 read 也只能等待,导致整个脚本的耗时增加。
为了验证我的猜测,我把脚本简写后,使用 time 命令统计了耗时分布。
#!/bin/bash
while read -r start_line
do
str=`echo "hello"`
done < $start_file
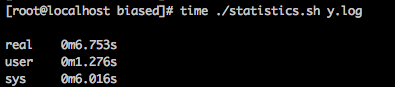
可以看得出来,绝大部分时间都是系统时间。
循环慢
另外一个问题是,最终解决问题的脚本和全量加载法的脚本在主要步骤上并没有太大差异,但效率为什么会差这么多呢?
我忽然注意到脚本里的一个循环 for j in `seq $i $total`, 这个语句也创建了子进程,那它跟主进程之间的交互就是问题了所在了, 在脚本运行初期,$i 非常小,而 $total 是结束日志的总行数:76W,如果 seq 命令是产生一个这么大的数组。。。
我使用 strace 跟踪了这个脚本,发现有大量的此类系统调用: 
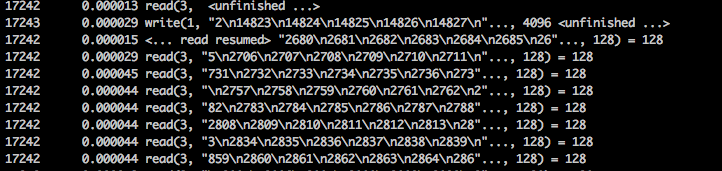
总算破案了。
小结
在这个问题的解决上,我的做法有很多不对的地方。
首先,解决问题过程中,脚本不正常地效率低,我没有仔细分析,而是在不停地避开问题,寻找新的解决方案,但新方案的实施也总有困难,结果总在不停地试错路上。
然后是解决问题有些一根筋了,看似找到了一个又一个方案,其实这些方案都是旧方案的补丁,而没有真正地解决问题。从A问题引入了B问题,然后为了解决B问题又引入了C问题,直到撞到南墙。
在第一家公司,初入编程领域时,我当时的 leader 老是跟我们强调一定要避免 X-Y
问题。针对 X 问题提出了一个方案,在方案实施过程中,遇到了问题 Y,于是不停地查找 Y 问题的解决办法,而忽略了原来的问题 X。有时候,方案可能是完全错误的,解决 Y 问题可能完全没有意义,换一种方案,原来的问题就全解决了。
在跟别人交流问题时,我一直把初始需求说清楚,避免此类问题,没想到这次不知不觉就沉入其中了,下次一定注意。
关于本文有什么问题可以在下面留言交流,如果您觉得本文对您有帮助,可以点击下面的 推荐 支持一下我,博客一直在更新,欢迎 关注。
