

连接池是一个用来维护可复用连接的数据结构,正确地使用连接池可以达到减少网络往返损耗,降低系统资源占用,提升响应性能的目的。连接池主要的思想是把新建的连接暂存到池子中,当请求结束后不关闭连接,而是放回到连接池中,需要的时候从连接池中取出连接使用。最近因为工作研究了一些开源的连接池的实现,下面会逐一介绍,如有错误,欢迎指出。
用不同的姿势实现连接池
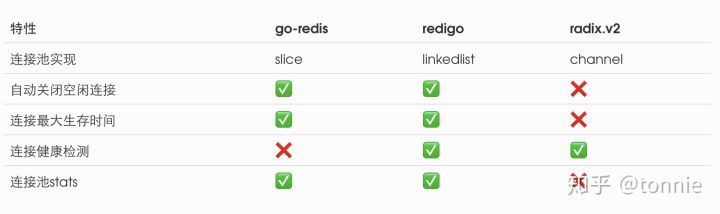
go-redis,redigo和radix.v2都是用Go实现的Redis客户端,它们都在代码中实现了健壮的连接池,而它们实现的方式又各不一样,接下来就跟随着源码一起窥探它们的连接池实现的区别。
下面这个表格展示了它们的特点:
go-redis
ConnPool是go-redis中连接池的实现,其数据结构如下:
type ConnPool struct {
opt *Options
dialErrorsNum uint32 // atomic
lastDialErrorMu sync.RWMutex
lastDialError error
queue chan struct{}
connsMu sync.Mutex
conns []*Conn
idleConns []*Conn
poolSize int
idleConnsLen int
stats Stats
_closed uint32 // atomic
}主要字段说明:
- opt:连接池的参数选项。
- dialErrorsNum:连接失败的错误数。
- lastDialError:最近一次的连接错误。
- queue:轮转队列,是一个channel结构。
- conns:连接队列,维护了未被删除所有连接。
- idleConns:空闲连接队列,维护了所有的空闲连接。
- poolSize:连接池大小。
- idleConnsLen:空闲连接数。
- stats:连接池的使用数据。
- _closed:连接池是否关闭。
连接池的选项如下:
type Options struct {
Dialer func() (net.Conn, error)
OnClose func(*Conn) error
PoolSize int
MinIdleConns int
MaxConnAge time.Duration
PoolTimeout time.Duration
IdleTimeout time.Duration
IdleCheckFrequency time.Duration
}字段说明:
- Dialer:新建连接的工厂函数。
- OnClose:关闭连接的回调函数。
- PoolSize:连接池大小。
- MinIdleConns:最小空闲连接数。
- PoolTimeout:连接池获取的超时时间。
- IdleTimeout:空闲连接的超时时间。
- IdleCheckFrequency:超时空闲连接清理的间隔时间。
新建连接池的过程如下:
func NewConnPool(opt *Options) *ConnPool {
p := &ConnPool{
opt: opt,
queue: make(chan struct{}, opt.PoolSize),
conns: make([]*Conn, 0, opt.PoolSize),
idleConns: make([]*Conn, 0, opt.PoolSize),
}
for i := 0; i < opt.MinIdleConns; i++ {
p.checkMinIdleConns()
}
if opt.IdleTimeout > 0 && opt.IdleCheckFrequency > 0 {
go p.reaper(opt.IdleCheckFrequency)
}
return p
}首先会初始化一个ConnPool实例,赋予PoolSize大小的连接队列和轮转队列,接着会根据MinIdleConns参数维持一个最小连接数,以保证连接池中有这么多数量的连接处于活跃状态。IdleTimeout和IdleCheckFrequency参数用来在每过一段时间内会对连接池中不活跃的连接做清理操作。
从连接池中获取一个连接的过程如下:
1.检查连接池是否被关闭,如果被关闭直接返回ErrClosed错误。否则尝试在轮转队列中占据一个位置,如果抢占的等待时间超过连接池的超时时间,会返回ErrPoolTimeout错误。
if p.closed() {
return nil, ErrClosed
}
err := p.waitTurn()
if err != nil {
return nil, err
}这里面的等待过程如下:
func (p *ConnPool) waitTurn() error {
select {
case p.queue <- struct{}{}:
return nil
default:
timer := timers.Get().(*time.Timer)
timer.Reset(p.opt.PoolTimeout)
select {
case p.queue <- struct{}{}:
if !timer.Stop() {
<-timer.C
}
timers.Put(timer)
return nil
case <-timer.C:
timers.Put(timer)
return ErrPoolTimeout
}
}
}轮转队列的主要作用是协调连接池的生产-消费过程,每往轮转队列中添加一个元素时,可用的连接资源的数量就减少一。若无法立即写入,该过程将尝试等待PoolTimeout大小的时间后,返回相应结果。
2.尝试从连接池的空闲连接队列中获取一个已有连接,如果该连接已过期,则关闭并丢弃该连接,继续重复相同尝试操作,直至获取到一个连接或连接队列为空为止。
for {
p.connsMu.Lock()
cn := p.popIdle()
p.connsMu.Unlock()
if cn == nil {
break
}
if p.isStaleConn(cn) {
_ = p.CloseConn(cn)
continue
}
return cn, nil
}3.如果上一步无法获取到已有连接,则新建一个连接,如果没有返回错误则直接返回,如果新建连接时返回错误,则释放掉轮转队列中的位置,返回连接错误。
newcn, err := p._NewConn(true)
if err != nil {
p.freeTurn()
return nil, err
}
return newcn, nil其中新建连接的过程如下:
cn, err := p.newConn(pooled)
if err != nil {
return nil, err
}
p.connsMu.Lock()
p.conns = append(p.conns, cn)
if pooled {
if p.poolSize < p.opt.PoolSize {
p.poolSize++
} else {
cn.pooled = false
}
}
p.connsMu.Unlock()
return cn, nil新建的连接会插入到连接池的conns队列中,当发现连接池的大小超出了设定的连接大小时,这时候会触发超卖,新建的连接的pooled属性被设置为false,也就是说这个连接不会再落地,未来将会被删除。
从连接池中取出的连接一般来说都是要放回到连接池中的,放回的过程如下:
func (p *ConnPool) Put(cn *Conn) {
if !cn.pooled {
p.Remove(cn)
return
}
p.connsMu.Lock()
p.idleConns = append(p.idleConns, cn)
p.idleConnsLen++
p.connsMu.Unlock()
p.freeTurn()
}简单地说就是直接放空闲连接队列中插入这个连接,并把轮转队列的资源释放掉。若连接被标记为不要被池化,则会从连接池中删除这个连接。
删除的过程如下,删除会从连接池的conns队列中移除这个连接:
func (p *ConnPool) removeConn(cn *Conn) {
p.connsMu.Lock()
for i, c := range p.conns {
if c == cn {
p.conns = append(p.conns[:i], p.conns[i+1:]...)
if cn.pooled {
p.poolSize--
p.checkMinIdleConns()
}
break
}
}
p.connsMu.Unlock()
}最后再来看下连接池是怎么自动收割长时间不使用的空闲连接的,后台的goroutine会定时执行任务,不断地从空闲连接队列中取出过时连接,做删除和关闭连接操作,并释放轮转资源:
var n int
for {
p.getTurn()
p.connsMu.Lock()
cn := p.reapStaleConn()
p.connsMu.Unlock()
if cn != nil {
p.removeConn(cn)
}
p.freeTurn()
if cn != nil {
p.closeConn(cn)
n++
} else {
break
}
}
return n, nilredigo
Pool是redigo中连接池的实现,其数据结构如下:
type Pool struct {
Dial func() (Conn, error)
TestOnBorrow func(c Conn, t time.Time) error
MaxIdle int
MaxActive int
IdleTimeout time.Duration
Wait bool
MaxConnLifetime time.Duration
chInitialized uint32
mu sync.Mutex
closed bool
active int
ch chan struct{}
idle idleList
}主要字段说明:
- Dial:新建连接的工厂函数。
- TestOnBorrow:连接的健康检测函数。
- MaxIdle:最大空闲连接数。
- MaxActive:最大活跃连接数。
- IdleTimeout:空闲连接的超时时间
- Wait:如果连接池达到了最大的活跃连接数,Wait用以指示是否需要继续等待。
- active:活跃连接数量。
- closed:连接池是否关闭。
- idle:维护空闲连接的集合,
idleList的实现与链表类似,不多介绍。
可以看出连接池的参数选项和数据都集中在了连接池的结构体中,区别于go-redis中连接池和连接选项分开的情况。
redigo推荐用类似以下的方式来新建一个连接池,而不是使用一个它自带的工厂方法:
func newPool(addr string) *redis.Pool {
return &redis.Pool{
MaxIdle: 3,
IdleTimeout: 240 * time.Second,
Dial: func () (redis.Conn, error) { return redis.Dial("tcp", addr)},
}
}从连接池中获取一个连接的过程如下:
1.检测是否设置了Wait和MaxActive选项,若是,则对连接池的ch属性进行懒加载,ch是一个设置了MaxActive大小的channel,用以维护活跃连接资源,如果ch已经被初始化了则会马上返回。
接下来再尝试从ch中获取一个资源,这里会进行一个阻塞获取操作,等待直至有可用资源。
// Handle limit for p.Wait == true.
if p.Wait && p.MaxActive > 0 {
p.lazyInit()
if ctx == nil {
<-p.ch
} else {
select {
case <-p.ch:
case <-ctx.Done():
return nil, ctx.Err()
}
}
}2.接下来会进行几个动作,首先会遍历空闲连接的链表,逐个检测连接是否过时,如果连接已超过设定的过时时间,则从链表中摘走该连接,并关闭底层连接,把活跃连接数减少一;接着尝试从链表头部中获取一个可用连接,调用测活函数和检查生命周期,如果通过判断则返回该连接,如果不通过则丢弃掉该连接,并把活跃连接数减少一,如果连接池被关闭的话,函数会在这时候返回错误。
p.mu.Lock()
// Prune stale connections at the back of the idle list.
if p.IdleTimeout > 0 {
n := p.idle.count
for i := 0; i < n && p.idle.back != nil && p.idle.back.t.Add(p.IdleTimeout).Before(nowFunc()); i++ {
pc := p.idle.back
p.idle.popBack()
p.mu.Unlock()
pc.c.Close()
p.mu.Lock()
p.active--
}
}
// Get idle connection from the front of idle list.
for p.idle.front != nil {
pc := p.idle.front
p.idle.popFront()
p.mu.Unlock()
if (p.TestOnBorrow == nil || p.TestOnBorrow(pc.c, pc.t) == nil) &&
(p.MaxConnLifetime == 0 || nowFunc().Sub(pc.created) < p.MaxConnLifetime) {
return pc, nil
}
pc.c.Close()
p.mu.Lock()
p.active--
}
// Check for pool closed before dialing a new connection.
if p.closed {
p.mu.Unlock()
return nil, errors.New("redigo: get on closed pool")
}
// Handle limit for p.Wait == false.
if !p.Wait && p.MaxActive > 0 && p.active >= p.MaxActive {
p.mu.Unlock()
return nil, ErrPoolExhausted
}
p.active++
p.mu.Unlock()3.如果无法在上一步获取连接,连接池则会新建一个连接返回,如果连接返回失败,则释放掉ch中的资源,可以看出这里的ch的作用跟go-redis连接池实现中的轮转队列的作用是类似的。
c, err := p.Dial()
if err != nil {
c = nil
p.mu.Lock()
p.active--
if p.ch != nil && !p.closed {
p.ch <- struct{}{}
}
p.mu.Unlock()
}
return &poolConn{c: c, created: nowFunc()}, err在redigo的连接池的Get方法中无论成功或失败,是只返回一个连接结构体作为返回结果的,而在go-redis中的Get方法则返回两个结果,一个代表连接,另一个是错误,这里也可以看出它们在接口设计上的区别。
func (p *ConnPool) Get() (*Conn, error) // go-redis
func (p *Pool) Get() Conn // redigo把连接放回到连接池的过程如下:
p.mu.Lock()
if !p.closed && !forceClose {
pc.t = nowFunc()
p.idle.pushFront(pc)
if p.idle.count > p.MaxIdle {
pc = p.idle.back
p.idle.popBack()
} else {
pc = nil
}
}
if pc != nil {
p.mu.Unlock()
pc.c.Close()
p.mu.Lock()
p.active--
}
if p.ch != nil && !p.closed {
p.ch <- struct{}{}
}
p.mu.Unlock()
return nil当连接池没被关闭时,放回连接池的连接会被重新插入到链表头中,如果链表长度超过最大空闲数量了,则会从链表尾部摘除一个连接。否则连接会被关闭并释放相应资源。
注意这里的put方法是不对外暴露的,而是通过对外暴露的Close方法的内部进行调用,使用者无须关心把连接放回池中的逻辑,而只需要像使用普通网络连接一样使用就好了:
func serveHome(w http.ResponseWriter, r *http.Request) {
conn := pool.Get()
defer conn.Close()
//...
}radix.v2
Pool是radix.v2中的连接池的实现,其数据结构如下:
type Pool struct {
pool chan *redis.Client
reservePool chan *redis.Client
df DialFunc
po opts
limited chan bool
initDoneCh chan bool // used for tests
stopCh chan bool
Network, Addr string
}主要字段说明:
- pool:维护连接的channel。
- reservePool:连接保留池,若pool的连接满了,额外的连接会放到这里面来,其中的连接会定期尝试回到pool中。
- df:连接的工厂函数。
- po:连接选项。
- limited:连接限制池。
radix.v2的连接池实现对比其他两个来说要比较简洁一些,其新建一个连接池的过程如下:
1.初始化构造参数,新建一个Pool实例:
var defaultPoolOpts []Opt
// if pool size is 0 don't do any pinging, cause there'd be no point
if size > 0 {
defaultPoolOpts = append(defaultPoolOpts, PingInterval(10*time.Second/time.Duration(size)))
}
var po opts
for _, opt := range append(defaultPoolOpts, os...) {
opt(&po)
}
p := Pool{
Network: network,
Addr: addr,
po: po,
pool: make(chan *redis.Client, size),
reservePool: make(chan *redis.Client, po.overflowSize),
limited: make(chan bool, po.createLimitBuffer),
df: df,
initDoneCh: make(chan bool),
stopCh: make(chan bool),
}这里面会构造一些默认参数,例如设置了连接定期发送ping命令的配置,以及对Pool实例中的数据结构进行初始化。
2.启动后台任务,分别定时进行连接健康检测,以及定时从保留连接池中清理连接:
if po.pingInterval > 0 {
doEvery(po.pingInterval, func() {
// instead of using Cmd/Get, which might make a new connection,
// we only check from the pool
select {
case conn := <-p.pool:
// we don't care if PING errors since Put will handle that
conn.Cmd("PING")
p.Put(conn)
default:
}
})
}
if po.overflowSize > 0 {
doEvery(po.overflowDrainInterval, func() {
// remove one from the reservePool, if there is any, and try putting it
// into the main pool
select {
case conn := <-p.reservePool:
select {
case p.pool <- conn:
default:
// if the main pool is full then just close it
conn.Close()
}
default:
}
})
}3.新建一个连接并检测server是否存活,如果存在错误直接返回,否则继续新建size-1数量的连接,存放在连接池供使用:
mkConn := func() error {
client, err := df(network, addr)
if err == nil {
p.pool <- client
}
return err
}
if size > 0 {
// make one connection to make sure the redis instance is actually there
if err := mkConn(); err != nil {
return &p, err
}
}
// make the rest of the connections in the background, if any fail it's fine
go func() {
for i := 0; i < size-1; i++ {
mkConn()
}
close(p.initDoneCh)
}()
return &p, nil从连接池中获取一个连接的过程如下:
select {
case conn := <-p.pool:
return conn, nil
case conn := <-p.reservePool:
return conn, nil
case <-p.stopCh:
return nil, errors.New("pool emptied")
default:
var timeoutCh <-chan time.Time
if p.po.getTimeout > 0 {
timer := time.NewTimer(p.po.getTimeout)
defer timer.Stop()
timeoutCh = timer.C
}
select {
case conn := <-p.pool:
return conn, nil
case conn := <-p.reservePool:
return conn, nil
case <-timeoutCh:
return nil, ErrGetTimeout
case <-p.limited:
return p.df(p.Network, p.Addr)
}
}连接池首先尝试从pool中获取一个连接,其次会尝试从reservePool中获取一个连接,如果都无法获取到连接,则会等待一段时间获取连接,直至超时或返回。
把连接放回到连接池的过程如下:
select {
case <-p.stopCh:
conn.Close()
return
default:
}
select {
case p.pool <- conn:
default:
if p.po.overflowSize == 0 {
conn.Close()
return
}
// we need a separate select here since it's indeterminate which case go
// will select and we want to always prefer the main pool over the reserve
select {
case p.reservePool <- conn:
default:
conn.Close()
}
}同样地,连接会首先尝试放回到pool中,如果失败则会尝试放到reservePool中,当还是出现失败则直接丢弃并关闭连接。
总结
用不同方式实现的连接池都有各自的特点,比如用channel实现的话代码会更加简单和清晰,用slice或linkedlist实现的话则整体性能会更高一些,但良好的连接池共同的特点是:提供对用户友好的接口,安全可靠,以及能保证在并发环境下的正确性。
