

由于微信公众号不能插入外链,请点击 阅读原文 查看原文。
原文地址:https://blog.gurock.com/service-mesh-performance-testing/ 作者:Bob Reselman 译者:杨传胜

现代 IT 企业的数字基础设施极其复杂,通过手动配置防火墙来保护一台连接到路由器的服务器的日子已经一去不复返了。
今天我们生活在虚拟化和弹性计算的世界中,计算资源基础设施需要具有自动扩展和收缩的能力来满足当下的各种需求,因为 IP 地址来得快去得也快,安全策略每分钟都可能发生变化,任何一个服务都可能要随时随地运行。这时候就需要新的自动化技术来支撑超越人类管理能力的企业,而在数字化领域, 服务网格(Service Mesh)正是我们所需要的这种技术。
服务网格正在扩展分布式系统在服务发现、操作和维护方面的能力,它不仅影响了服务如何部署到公司的数字环境中,而且该技术还将在系统可靠性和性能方面发挥更大作用。因此,我建议那些关注性能和可靠性测试的童鞋掌握服务网络的工作原理,特别是关于路由和重试这一部分。
随着服务网格逐渐成为标准控制平面,性能测试工程师在创建适用于服务网格体系架构的测试计划时提前熟悉该技术将会变得很有必要。
1. 服务网格的用例

服务网格解决了现代分布式计算中的两个基本问题:如何在系统中查找服务的位置,以及定义了当服务出现故障时该如何应对。
在服务网格出现之前,每个服务都需要知道它所依赖的服务的位置才能正常工作。例如,如下图所示,为了使服务 A 能够将请求任务传递给服务 C,它需要知道服务 C 的确切位置。服务 C 的位置可以定义为 IP 地址或 DNS 域名。一旦服务 C 的位置发生了变化,如果情况不是太糟,改一下服务 A 的配置就可以继续工作了,更糟糕的情况下整个服务
A 可能都需要重写。
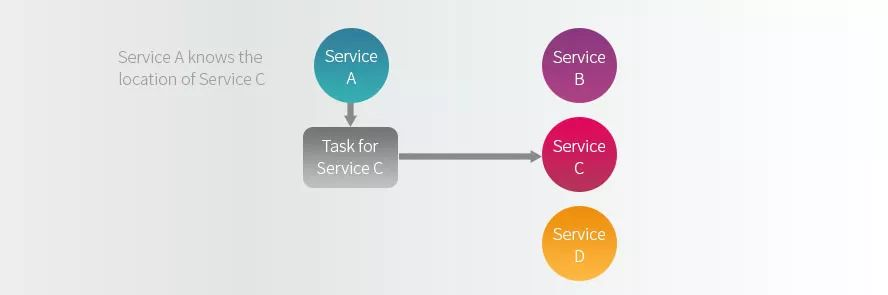
服务之间的紧耦合将会导致系统很脆弱,并且难以扩展,因此很多公司开始使用诸如 ZooKeeper,Consul 和 Etcd 等服务发现工具,这样服务就不再需要知道它所依赖的服务的位置也可以正常工作了。如下图所示:
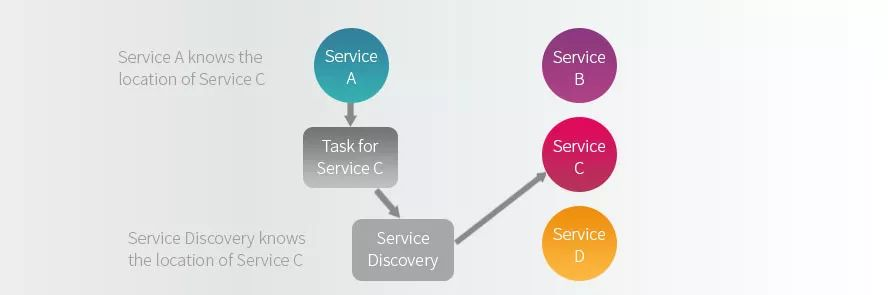
然而还有一个问题需要解决:当服务 A 调用其中一个依赖服务失败时,服务 A 会执行什么操作,它应该报错还是重试?如果重试,那么应该重试多少次才算失败?这时候服务网格就派上用场了。
服务网格聚合了服务发现和故障策略等其他功能,也就是说服务网格不仅允许各个服务之间相互交互,还会根据配置的策略执行重试、重定向或终止等操作。如下图所示:
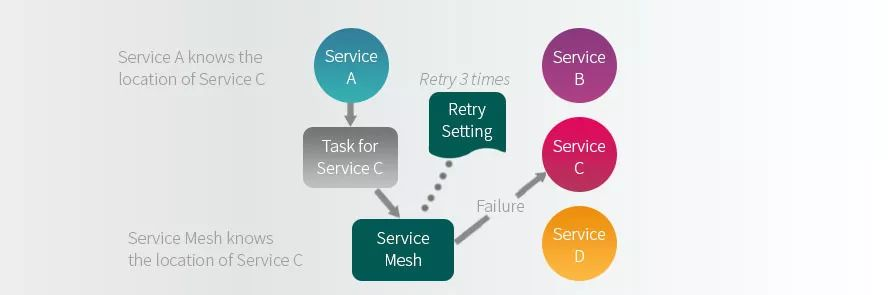
服务网格是一个控制平面,可以在各个服务之间路由流量,并为每个服务提供故障安全机制。此外,服务网格还将网格内流量的所有活动都记录下来,从而提供对系统整体性能的可观察性。这种记录方式增加了分布式链路追踪的可能性,这样不需要关心每个服务的位置就可以对这些服务进行观测和故障排除。
目前比较流行的服务网格技术是 Linkerd、Envoy 和 Istio。
从性能测试的角度来理解服务网格的原因在于该技术对系统性能有着直接影响。因此,测试工程师至少应该掌握服务网格技术的原理和实践方法。同时,测试工程师可以通过将服务网格中生成的数据集成到测试计划和报告中获得很多好处。
2. 在性能测试计划中使用服务网格

性能测试工程师该如何利用服务网络提供的这些功能?这取决于性能测试的范围和测试工程师对服务网格的兴趣。如果工程师只关心 Web 客户端和 Web 服务端之间的响应时间,那么只需要理解服务网格的原理和使用方式就够了。但如果测试过程中需要关注服务端任何一个应用程序的性能,那么事情就会变得有趣了。
第一个也是最有说服力的好处是服务网格支持分布式链路追踪。这意味着服务网格可以观察到分布式架构中所有服务在调用期间的执行时间,因此测试工程师可以更准确地识别系统的性能瓶颈。一旦确定了瓶颈所在,就可以根据追踪数据找到与之相关的具体配置,以便发现性能问题的本质原因。
服务网格除了为测试服务提供相关信息之外,它本身也会成为测试的关注点。记住:服务网格的配置将会对系统性能产生直接影响,这种影响为性能测试增加了一个新的维度。在测试过程中除了需要关注应用程序本身的逻辑,还需要关注服务网格本身,比如在测试自动重试时,如何配置好请求截止时间和熔断将会起到很重要的作用。
-
自动重试 : 自动重试是服务网格中的一项配置,可以使消费服务在返回特定类型的错误代码时重新尝试调用依赖服务。例如,如果服务 A 调用服务 B,而服务 B 返回了
502错误(网关出错),则服务 A 将会根据配置自动尝试重新调用服务 B 若干次。由于502错误可能是暂时的环境抖动,会很快恢复,所以重试是一个很合理的行为。 -
请求截止时间 : 请求截止时间与超时类似,允许在特定的时间段内对特定的服务执行调用请求。如果到了截止时间,无论如何配置重试策略,调用请求都会失败,从而防止被调用服务的负载过高。
-
熔断 : 当系统中的某个单点(例如某个服务)发生故障并导致其他其他单点也接连发生故障时,可以通过熔断来防止系统出现级联故障。熔断器是一个围绕在服务周围的组件,如果服务处于故障状态,熔断器就会”跳闸“,这时对失败服务的调用请求会立即被作为错误拒绝,而不必承担流量转发和服务调用的开销。如果是在服务网格中,熔断器还会记录对故障服务的尝试调用过程,同时通过对网格内的服务配置监控和告警策略来应对熔断器的打开和关闭。
随着服务网格渐渐成为企业系统架构的一部分,性能测试工程师会逐渐将服务网格本身的测试作为整体性能测试计划的一部分。
3. 总结

使用传统的方式进行性能测试的日子即将结束,现代化的应用程序过于复杂,中间有太多的依赖服务,不能仅依靠测试客户端和服务端之间的请求和响应时间来判断其性能。作为一个合格的企业架构师,无论基础设施的规模有多大,变化速度有多快,都不会为了实现动态配置和管理的需求而牺牲观察和管理系统的能力。
随着 DevOps 的精神不断渗透到 IT 文化中,服务网络正在成为使用现代分布式架构的企业的关键组成部分。如果能深入理解服务网格技术的价值和使用方式,测试工程师就能为性能测试添加新的维度。如果能够精通该技术,那么服务网格将会为你带来最大的优化效益。
本文作者是 Bob Reselman,著名的软件开发者,系统架构师,行业分析师和技术作家。Bob 撰写了许多关于计算机编程方面的书籍和数十篇关于软件开发技术以及软件开发文化的文章。Bob 是 Cap Gemini 的首席顾问,也是计算机制造商 Gateway 的平台架构师。除了软件开发和测试之外,Bob 还在编写一本关于自动化对人类就业影响的书。他住在洛杉矶,可以直接通过他的 LinkedIn 链接 和他联系。
