

夏乙 岳排槐 发自 亚龙湾
量子位 出品 | 公众号 QbitAI
索尼大法好。
索尼自己说。
刚刚,索尼在arXiv上发文宣布:他们用224秒在ImageNet上完成了ResNet-50训练,没有明显的准确率损失。
而且训练误差曲线与参考曲线非常相似。最大的mini-batch size可以增大到119K而没有明显的准确率损失,不过进一步增大到136K时准确率会降低约0.5%。
这是索尼给出的对比。
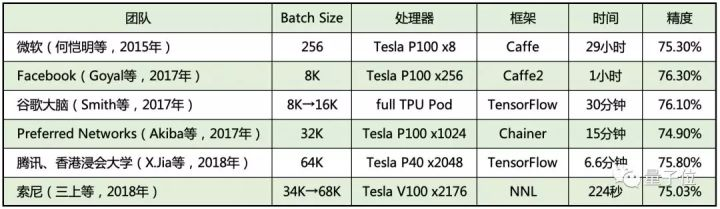
从这个表格可以看出,斜刺里杀出的索尼,堪称完胜。比腾讯今年6月创造的成绩还要好。比前几年的成绩,更是多个数量级的进步。
关于上表中腾讯的成绩,有些同学可能会有疑问:不是4分钟吗?
情况是这样的,腾讯今年6月的“4分钟训练ImageNet”,指的是AlexNet网络;而上面列出的,是训练ResNet-50网络需要的时间和达到的准确率。
插播一个花絮,上表中腾讯公司的Xianyan Jia,现在已经供职于阿里巴巴了……
当然,索尼也是下了血本。为了达到这个成绩,动用了更多的GPU。不过索尼自己也说,他们的方法也能更有效的利用大规模GPU。
在训练速度和GPU规模效率上,索尼把自己的方法与单节点(4个GPU)进行了对比。下面这个表格显示了当mini-batch size设置为32时,不同GPU数量的效率。
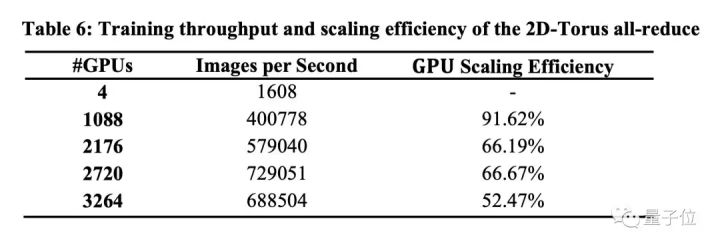
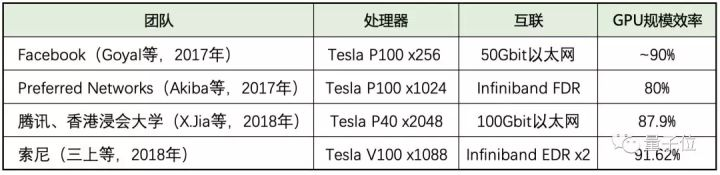
如上表所示,当索尼使用1088个GPU时,规模效率超过90%。腾讯之前的工作中,使用1024个Tesla P40,GPU的规模效率为87.9%。
索尼表示,他们的互联方案能基于更快(Tesla V100)和更多的GPU,实现更高的GPU规模效率。
两件装备
更快的训练速度,更高的GPU规模化效率来自两件加速装备:
一是针对大批次(batch)训练不稳定问题的批次大小控制,二是2D-Torus all-reduce,降低了梯度同步的通信开销。
它们所解决的,正是困扰大规模分布式深度学习训练的两个问题。
所谓批次大小控制,是指在训练过程中逐渐提升批次的整体大小。每当训练的损失图变“平”,就提大批次,这样有助于避开局部最小值。
在这个224秒训练完ImageNet的方案中,批次大小超过32k时,索尼五人组用这种方法来防止准确率的下降。
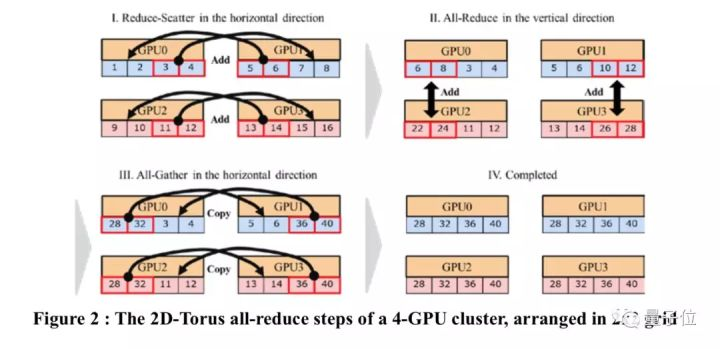
而2D-Torus All-reduce,是一种“高效的”通信拓扑结构。不像之前的Ring All-redice等算法,就算有上千个GPU,2D-Torus all-reduce也能完全利用它们的带宽。
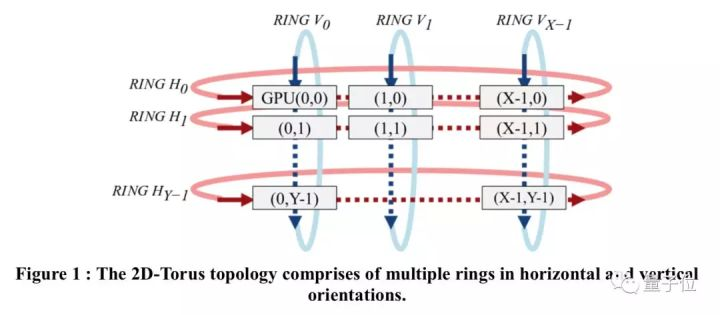
2D-Torus拓扑结构如上图所示。这种结构下,簇里的GPU排列在2D网格中,all-reduce由3步组成:1) 水平进行的reduce-scatter、2) 垂直进行的all-reduce、水平进行的all-gather。
上面提到的两件加速装备,都是用索尼自家神经网络库Neural Network Libraries(NNL)实现的,这个库还有个可能稍微更为人所熟知一点的名字:nnabla。
在nnabla这个名字里,nn代表神经网络(neural network)的缩写,而nabla代表梯度的数学符号∇。
2017年6月,索尼在GitHub上开源了这个库,repo名叫nnabla。它在GitHub上一直在活跃更新,现在有2000多星,226次fork。
nnabla基本用C++11写成,让用户能直观地用少量代码定义计算图,带有CUDA扩展,能添加新函数,支持动态计算图,可以在Linux和Window上运行。
地址在这里:https://github.com/sony/nnabla
最后,附上这篇224秒训练ImageNet/ResNet-50:

ImageNet/ResNet-50 Training in 224 Seconds
https://arxiv.org/abs/1811.05233arxiv.org— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!
相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI· 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
