文 / 张汝宸 张志博,扇贝算法团队

背景
扇贝,作为一个拥有超过八千万用户的移动英语学习平台,一直在探索如何利用数据来提供更精准的个性化教育。更快速、科学地评估用户词汇水平,不仅可以有效提高用户的学习效率,也可以帮助我们为每位用户制定更个性化的学习内容。
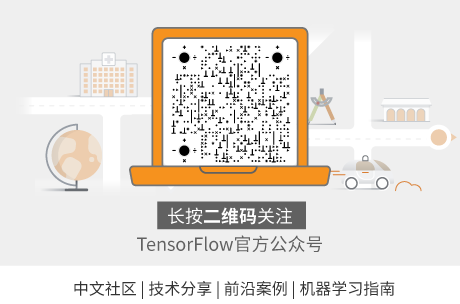
我们通过应用 TensorFlow,在深度知识追踪系统上可以实时地预测用户对词表上每个词回答正确的概率 (如图 1 所示)。本文将介绍扇贝是如何实现深度追踪模型并运用到英语学习者词汇水平评估中去。
图 1:实时预测答词正确率
模型介绍
基于先前大量线上词汇量测试记录,我们的总序列数量已经累积到千万级别,这为使用深度学习模型提供了坚实的基础。模型方面,我们选用了斯坦福大学 Piech Chris 等人在 NIPS 2015 发表的 Deep Knowledge Tracing (DKT) 模型 [1],该模型在 Khan Academy Data 上进行了验证,有着比传统 BKT 模型更好的效果。由表 1 可见,相比 Khan Academy Data,扇贝词汇量测试数据的题目数量和所涉及用户量都要更大,序列长度也更长,这些不同也是我们在模型调优过程中面临的最大挑战。
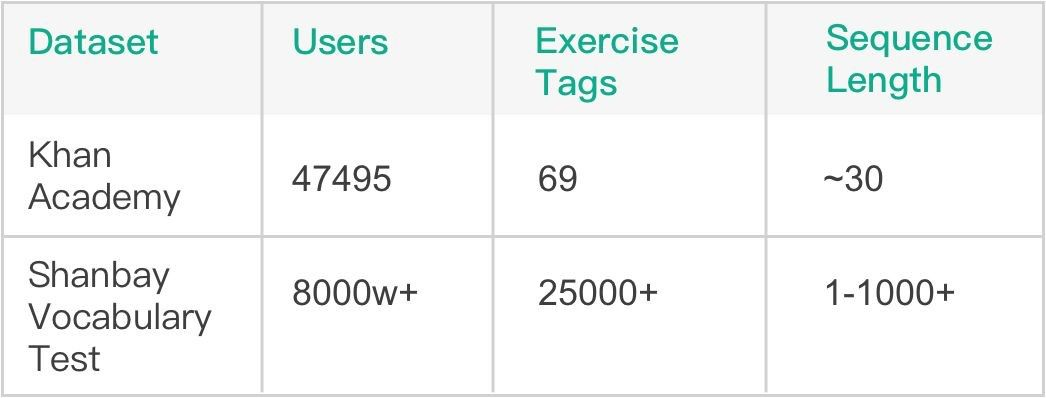
表 1:Khan Math 和 Shanbay Vocab 数据对比
Baseline 模型结构为单层 LSTM ,如图 2 所示,输入 xt 是用户当前 action(所答单词和正确与否)的 embedding,可以用 one-hot encodings 或者是 compressed representations。输出 yt 代表模型预测用户对词表中每个词回答正确的概率。
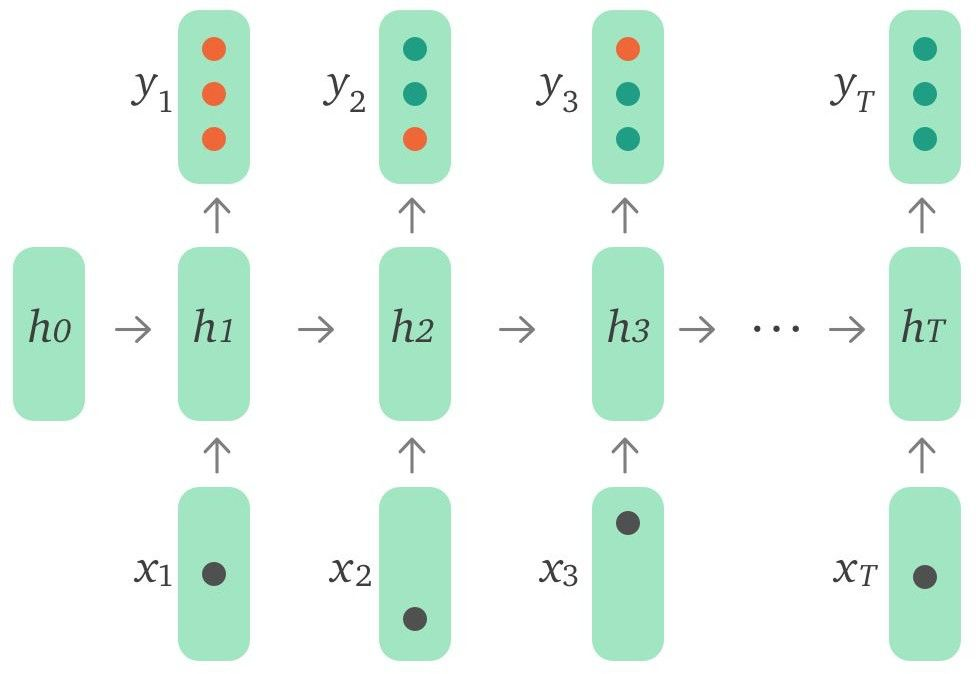
图 2:DKT 模型结构
模型改进
按照原论文思路实现的 baseline ,在 Khan Academy Data 上能较好地复现论文结果。针对实际应用场景,我们使用 TensorFlow 实现了相应模型,在如下几方面做出改进,尝试提升模型性能。
数据预处理
通过观察发现,原始数据存在如下几个问题:
-
少量异常用户数据占比过高
-
部分用户测试序列过短,提供的信息不足
-
存在少量极低频词
经过数据清洗后,模型准确率有 1.3% 左右的提升。
引入外部特征
DKT 原模型的输入只有当前题目和用户回答正确与否,事实上用户答题过程中相关的一些其他信息也是可以作为特征输入到模型中的。下面列出了其中一些有代表性的特征:
-
Time - 用户第一次遇到该单词时回答所花费的时间
-
Attempt count - 用户第几次遇到该单词
-
First action - 用户的第一个动作是直接回答还是求助系统给出提示信息
-
Word level - 先验单词等级
使用这些特征的方式有多种,可以通过自编码器编码后输入,也可以作为特征向量与 input embeddings 拼接后输入,还可以直接和 LSTM 输出的 hidden state 拼接后进行预测。这些特征的使用进一步将模型准确率提升了约 2.1%。我们还对不同特征能够带来的影响进行了对比实验,发现 Time 和 Attempt count 是最重要的两个特征维度,而其他特征带来的影响则很有限。
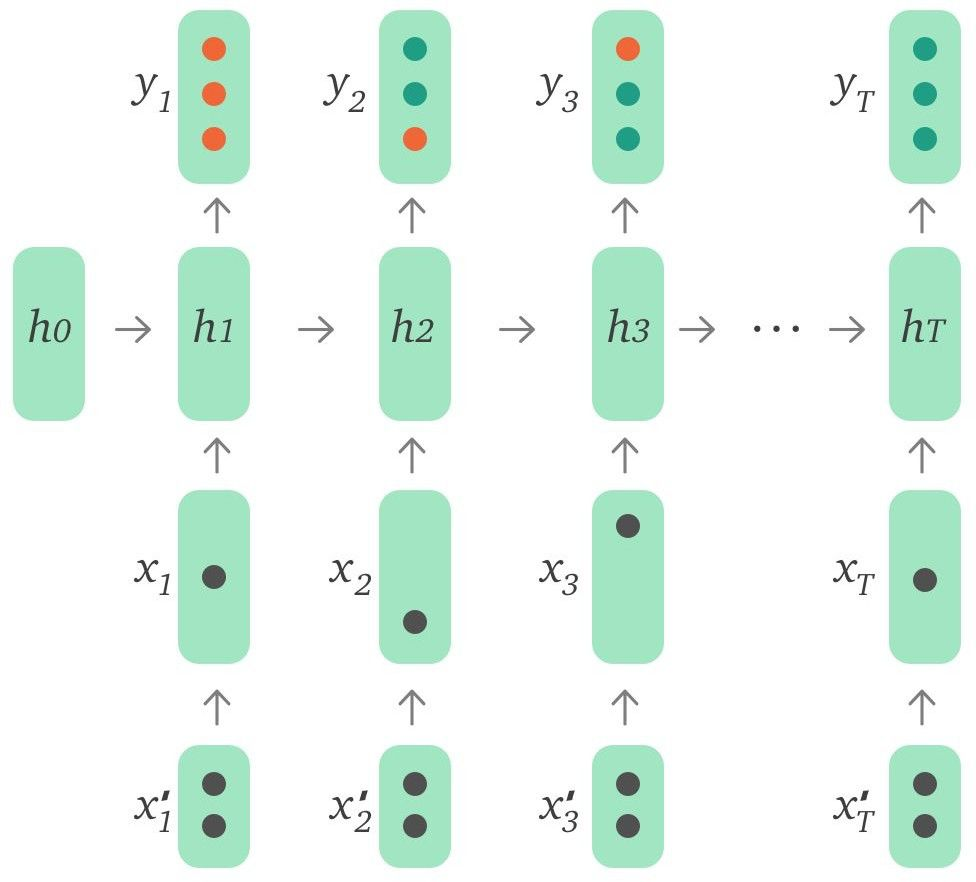
图 3:引入外部特征的 DKT 模型
长序列依赖
传统 LSTM 模型使用了门控函数,虽然有效缓解了梯度消失问题,但面对超长序列的时候仍然无法避免。此外,由于使用了 tanh 函数,在多层 LSTM 中,层与层之间的梯度消失问题依然存在。所以现阶段多层 LSTM 大多是采用 2~3 层,最多不超过 4 层。为了解决数据中存在的超长序列长期依赖问题,我们选用了 Shuai Li 等人在 CVPR 2018 发表的 Independently Recurrent Neural Network (IndRNN) 模型 [2]。 IndRNN 将层内神经元解耦,让它们相互独立,同时使用 ReLU 激活函数,有效解决了层内以及层间的梯度消失和爆炸问题,使得模型层数和能够学习到的序列长度大大增加。如图 4 所示,对于 Adding Problem (评价 RNN 模型的典型问题),当序列长度到达 1000 时, LSTM 已经无法降低均方误差,而 IndRNN 仍然可以快速地收敛到一个非常小的误差。
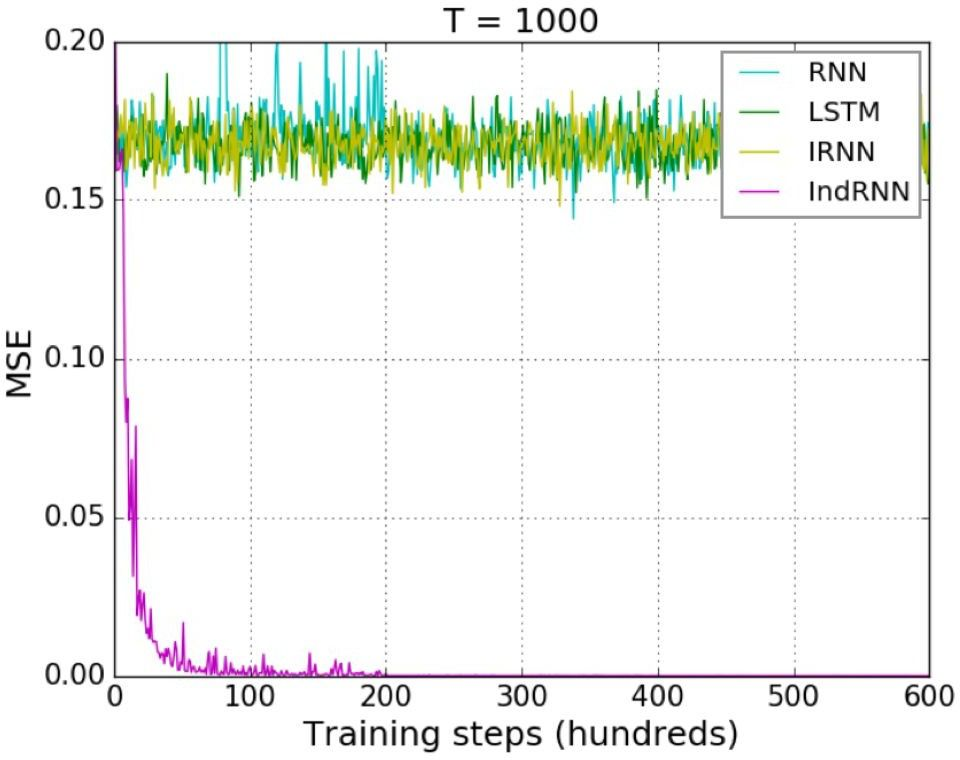
图 4:对 Adding Problem,各种 RNN 对长序列的收敛情况对比
IndRNN 的引入,有效地解决了数据中超长序列长期依赖问题,进一步将模型准确率提升了 1.2%。
超参数调优
在手动调参的模型已经得到了不错表现的基础上,我们希望通过自动调参来进一步优化模型。可调整的一些参数有:
-
RNN 结构类型 - LSTM,GRU,IndRNN
-
RNN 层数和连接方式
-
学习率和 Decay 步数
-
Input 和 RNN 维度
-
Dropout 大小
在自动调参算法中,Grid Search(网格搜索)、Random Search(随机搜索)和 Bayesian Optimization(贝叶斯优化)[3] 较为主流。网格搜索的问题在于容易遭遇维度灾难,而随机搜索则不能利用先验知识来更好地选择下一组超参数,只有贝叶斯优化是 “很可能” 比建模工程师调参能力更好的算法。因为它能利用先验知识高效地调节超参数。贝叶斯优化方法在目标函数未知且计算复杂度高的情况下很强大,该算法的基本思想是基于采样数据使用贝叶斯定理估计目标函数的后验分布,然后再根据分布选择下一个采样的超参数组合。
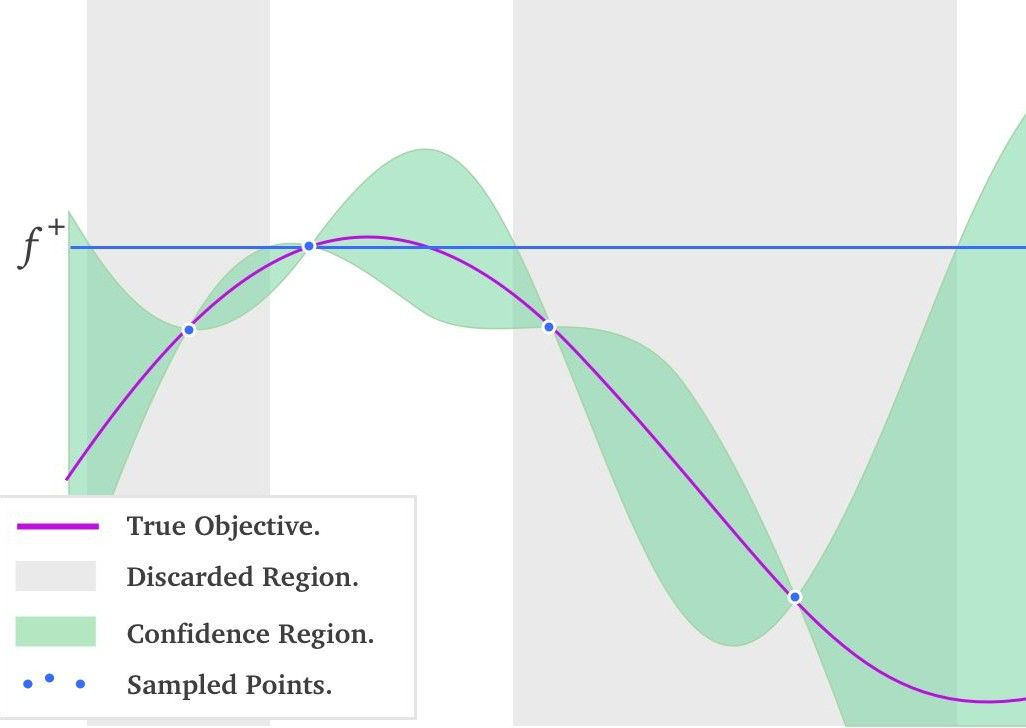
图 5:一维黑盒函数的贝叶斯优化过程
图 5 中红线代表真实的黑盒函数分布,绿色区域代表根据已采样点计算出的各位置处的置信区间。此刻要做的事情就是选择下一个采样点,选择均值大称为 exploitation,选择方差大称为 exploration。均值大的点会更有把握获得更优的解,而方差更大的点会更有机会得到全局最优。所以如何决定 exploitation 和 exploration 比例,是需要根据使用场景决定的。发挥这个功能的是一个叫做 acquisition function 的函数,它被用来权衡 exploitation 和 exploration 。常用的 acquisition function 有 Upper Condence Bound, Expected Improvement, Entropy Search 等。有了 acquisition function 后,就能以它取得最大值处的超参数,作为贝叶斯优化算法推荐的下一个超参数值。这个结果是根据超参数间的联合概率分布求出来,并且均衡了 exploritation 和 exploration 后得到的结果。
使用了贝叶斯优化调参后,模型的准确率进一步提升了 1.7%。
模型部署
我们使用 TensorFlow Serving 作为模型部署上线的方案。在上线前我们有利用一些模型压缩技术来减少模型大小,并根据 TensorFlow Serving Batching Guide [4] 来找到最优的 batching config 参数。
模型压缩
模型压缩有很多种方式,参数共享和剪枝、参数量化、低秩分解等。从简单易行的角度考虑,我们借鉴了 LSTMP [5] 中 projection layer 的思想,对最终输出层的 embedding matrix 进行了分解,增加了一个 projection layer。这么做的原因在于模型最终输出词表维度很大,因此模型大部分参数都集中在输出层。分解后模型大小减少到原来的一半,而模型准确率却没有损失。
此外,DKT 模型的 hidden state 对于每个用户而言是不同的,所以基于长期学习需求,我们需要为每位用户保存这个向量来作为 user embedding。但如果这个向量维度较大的话,面对大量潜在用户,存储压力是非常大的,所以我们尝试着去降低这个向量维度。起初的方案是使用 LSTMP,但实验发现,直接降低这个维度对模型准确率损害是很低的。将维度降低到 baseline 模型的五分之一,对准确率几乎没有负面影响,这个结果也超出了我们的预期。
TensorFlow Serving Batching 调优
根据官方 performance tuning guide,对于线上预测系统,我们将 num_batch_threads 设为 CPU 的核心数量,max_batch_size 设为一个很大的值,同时 batch_timeout_micros 设为 0 . 随后在 1~10millisecond 范围内调整 batch_timeout_micros,找到最优配置。经过测试发现,在同样的计算资源下,使用调优过后的 Batching config,并发量是不使用时候的 2~2.5 倍。
总结和展望
本文以词汇水平评估场景为例,介绍了 TensorFlow 在 Computer-Aided Language Learning(计算机辅助语言学习)中的应用。通过对一系列论文结果的复现、改进以及调优,成功将 DKT 模型上线,为数千万用户提供了更科学的词汇测试方案。
后续我们会继续探究如何将 DKT 模型更深入地应用到扇贝单词的单词学习场景中去。同时还会将单词题拓展到更泛性的练习题上去,在更广的领域,更多的视角上进行知识追踪,从而更高效地帮助用户进行英语学习。用 AI 给教育赋能,是扇贝不变的追求。
参考文献
[1] Piech, C. et al. Deep knowledge tracing. in Advances in Neural Information Processing Systems 505–513 (2015).
[2] Li, S., Li, W., Cook, C., Zhu, C. & Gao, Y. Independently Recurrent Neural Network(IndRNN): Building A Longer and Deeper RNN. (2018).
[3] Shahriari, B., Swersky, K., Wang, Z., Adams, R. P. & Freitas, N. de. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proceedings of the IEEE 104, 148–175(2016).
[4] TensorFlow Serving Batching Guide. (2018). Available at:
https://github.com/tensorflow/serving/tree/master/tensorflow_serving/batching.
[5] Sak, H., Senior, A. & Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. in Fifteenth annual conference of the international speech communication association (2014).