



简介:字符集的由来是什么?各种字符编码又有什么关系?乱码是如何出现的?带着这些问题,我们一起倾听字符的故事。
前几天测试给提了个 bug ,“在长度限定的文本区域,输入表情时会展示乱码”。不由的产生了一些想法:这些表情是什么东西?为什么会出现乱码? JS 是使用哪种编码方式?便查阅了相关文献,最终找到了答案,今天就详细说一说编码的故事。

一、比特、字符、字节
在聊编码之前,有几个基础的概念需要先明确一下:
-
比特位:比特位即 Bit ,是计算机最小的存储单位。以 0 或 1 来表示比特位的值。也是网络信息传输的基本单位。
-
字节:8 个比特位表示一个字节。
-
字符:字符是可使用多种不同字符方案或代码页来表示的抽象实体。
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的序列。每一个二进制位(bit)有 0 和 1 两种状态,因此八个二进制位就可以组合出 256 种状态,这被称为一个字节( byte )。也就是说,一个字节一共可以用来表示 256 种不同的状态或者符号。如果我们制作一张对应表格,对于每一个 8 位二进制序列,都对应唯一的一个符号。每一个状态对应一个符号,就是 256 个符号,从 0000000 到 11111111 。
二、东方的故事
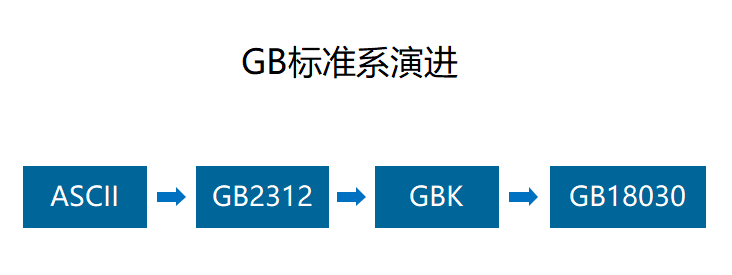
上个世纪 60 年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。 后来我们天朝也会用电脑了,但是汉字没办法表示,所以勤劳智慧的中国人民融合了 ASCII 中的数字、标点、字母,还把数字符号、罗马希腊字母与 7000 多个简体汉字整合进去,产生了 GB2312 , GB2312 是对 ASCII 的中文拓展。后来又发现中华文化实在是博大精深,汉字太多,原来的编码不太够用,因此再做拓展,此拓展方案叫做 GBK, GBK 中融合了 GB2312 的所有内容,同时新增 20000 个新的汉字(包括繁体字)和符号。再后来少数民族也用上了电脑,还得接着拓展。 GB18030 便由此诞生。从此中华民族灿烂的汉字文化,便在计算机中得以传承啦。
三、统一字符集
3.1 规则制定者
以上一个来自古老东方的故事,可是全世界很多国家都有自己的文字编码。每个国家的编码还都不一样。不由会让人产生一个想法“为何不建立一个全世界统一的字符集呢?”。

在20世纪80、90年代就有两个组织在做这个事情:
-
国际标准化组织( ISO ):
国际标准化组织是一个独立的非政府组织。它是世界上最大的自愿性国际标准开发商,通过在各国之间提供共同标准来促进世界贸易。ISO 试图制定一份“通用字符集”( UCS )
-
统一码联盟(Unicode Consortium):
其主要目的是维护和发布 Unicode 标准,该标准的开发旨在取代现有的字符编码方案,这些方案的大小和范围有限,并且与多语言环境不兼容。统一的在统一字符集的成功导致其广泛应用在国际化和本地化的软件。
两个机构的参与者意识到,世界上并不需要两个不兼容的字符集,因此双方开始合作。从 Unicode 2.0 开始,Unicode 采用了与 ISO 10646-1 相同的字库和字码;ISO 也承诺,ISO 10646 将不会替超出 U+10FFFF( Unicode 编码以 U+ 开头) 的 UCS-4 编码赋值,以使得两者保持一致。后来两个项目仍都独立存在,并独立地公布各自的标准。不过由于 Unicode- 这一名字比较好记,因而它使用更为广泛。
3.2 码点与区面
字符集从 0 开始为每个符号制定一个编码,叫码点。最新的 Unicode 版本一共有 109449 个符号。这些符号分区定义,每个区称作一个面,一共有 17(2^5)个面,每个面可以存放 65536(2^16) 个字符,也就是说一共可以存 2^21 个字符. 17 个面中有一个基本平面( BMP ),16个辅助平面( SMP )。
总而言之 Unicode 指得是字符的集合,而每个字符如何表示,那就需要编码方法,我们知道的编码方法有 UTF-32 、UTF-16 、UTF-8、UCS-2 等等,他们到底是什么?又有什么关系呢?
四、UTF-32 与 UCS-4

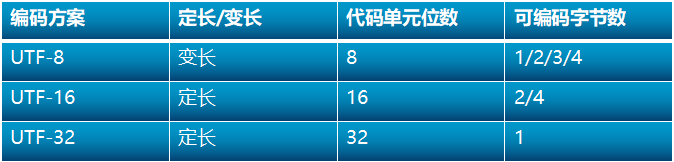
在 Unicode 与 UCS 合并之前已经产生了 UCS-4 编码方式。 UCS-4 还是使用 32 位( 4 字节)来表示每个 Unicode 编码,整个代码值表示所述代码空间范围介于 0 和 十六进制 7FFFFFFF 之间。但实际使用范围不超过 0x10FFFF ,为了兼容 Unicode 标准产生了 UTF-32 .他的码值与 UCS-4 一致,不过编码空间被限定在 0~0x10FFFF 之间,因此可以说 UTF-32 是 UCS-4 的子集。
由上文可以看出 UCS-4 存有明显的问题:由于 UTF-32 使用 4个字节来描绘每个字符,对于同样的英文文本来说,它是 ASCII 码使用空间的四倍。因此在HTML5网页标准中就明确规定,不得使用 UTF-32 进行编码。
五、UTF-16 与 UCS-2
5.1 UTF-16
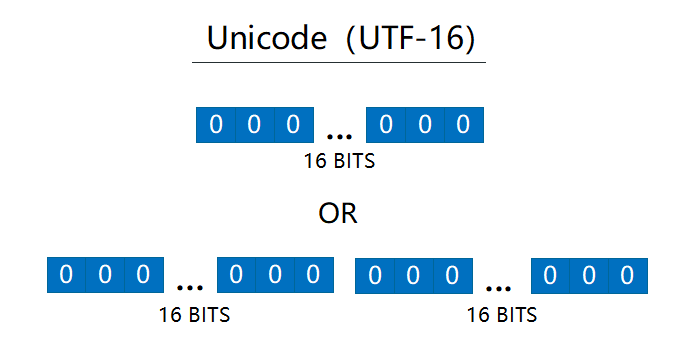
UTF-16 的编码方式介于 UTF-32 和 UTF-8 之间,同时结合了定长和变长两种编码的特点。上文中提到过 Unicode 编码点有 17 个平面,一个基本平面,16 个辅助平面,UTF-16 的编码规则很简单:基本平面的字符占用两个字节,辅助平面的字符占用四个字节。就是说 UTF-16 编码要么是两个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF).
5.2 辅助平面字符表示
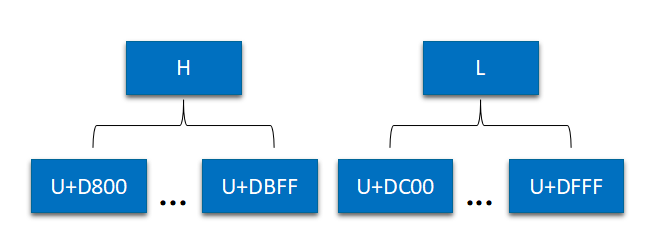
那么问题来了,如果遇到两个字节如何确定这两个字节就是一个字符,还是这两个字节拼上后面的两个字节形成一个字符呢? 其实是这样的,在基本平面内,从 U+D800 到 U+DFFF 是一个空段,不对应任何码点,这个空段用来映射辅助平面的字符。如何映射呢?首先辅助平面的字符一共是 16*2^16 个,也就是 2^20 个。一共 20 位,前 10 位跟后 10 位分开。前 10 位称为高位(H),后 10 位称为低位(L)。即一个辅助平面的字符,被拆成两个基本平面的字符表示。
5.3 Unicode 转 UTF-16
如何将 Unicode 码点转成 UTF-16 呢?
基本平面字符:直接将码点转为 16 进制
U+597D=>0x597D
辅助平面字符:
H = Math.floor((c-0x10000) / 0x400)+0xD800
L = (c - 0x10000) % 0x400 + 0xDC00
5.4 UCS-2
UCS-2 又是什么,跟 UTF-16 又有什么关系呢?
JavaScript 采用了 Unicode 字符集。但是只支持一种编码方式。JS 最先采用的编码既不是 UTF-16 也不是 UTF-32 或 UTF-8 ,而是 UCS-2 。UTF-16明确宣布是 UCS-2 的超集。UTF-16 中基本平面字符延用 UCS-2 编码。辅助平面字符定义了 4 个字节的表示方法。UCS-2 被整合进了 UTF-16 。并且由于 JavaScript 诞生的时候还没有 UTF-16 编码( UCS-2 于 1990 年公布。而 UTF-16 于 1996 年公布),因此 JS 最先采用了已经被淘汰的 UCS-2。
那么问题就显而易见了。JS 只能处理 UCS-2 编码,造成所有字符在这门语言中都是两个字节,如果是四个字节的字符。会被当做两个双字节的字符处理。
六、UTF-8
如果理解了我在前文中说的 UTF-32 和 UTF-16 两种编码方式,不难发现一个问题。对于英语国家来说一个字符完全可以单字节编码。使用以上的两种编码方式是对带宽的极大浪费。UTF-8 便由此而生!
UTF-8 的编码规则:
-
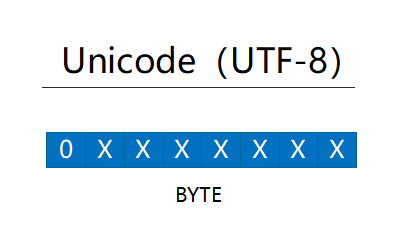
对于 ASCII 码中的符号,使用单字节编码,其编码值与 ASCII 值相同。其中 ASCII 值的范围为 0~0x7F ,所有编码的二进制值中第一位为 0(这个正好可以用来区分单字节编码和多字节编码)。
-
其它字符用多个字节来编码(假设用 N 个字节),多字节编码需满足:第一个字节的前 N 位都为 1,第 N+1 位为 0,后面 N-1 个字节的前两位都为 10,这 N 个字节中其余位全部用来存储 Unicode 中的码位值。
| 字节数 | Unicode | UTF-8编码 |
|---|---|---|
| 1 | 000000-00007F | 0xxxxxxx |
| 2 | 000080-0007FF | 110xxxxx 10xxxxxx |
| 3 | 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 010000-10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
七、最初的疑惑

说到此处,便可以对最初的疑惑做出解释:
-
这些表情是什么东西?
emoji 是通过 UCS-2(UTF-16)编码的字符,由于码点在辅助平面因此需要四个字节表示,即两个字符,这也说明为什么 emoji 表情的 length 值为 2 。
-
为什么会出现乱码?
emoji 表情符号,在 JS 中需要用两个字符表示。当在文本框限定长度时,假设长度限定为 15 ,在第 15 个字符输入一个表情(占两个字符),此时该表情会被输入区域自动截取一半,此时便无法正确显示啦。
-
JS 是使用哪种编码方式?
JS 早期使用 UCS-2 编码,后来使用 UTF-16。UTF-16 是 UCS-2 的超集。
-
如何校验辅助平面的字符呢?(如 emoji 表情)
依据其特点,正则校验方式如下:
var patt=/[\ud800-\udbff][\udc00-\udfff]/g;
-
问题解决方案
首先不再使用原生 textarea 或者 input 组件的 maxlength 属性进行长度校验,改为通过 JS 校验。当输入内容超过指定长度时,校验限定长度的位置跟下一个位置,是否刚好可以拼成一个 emoji 表情(校验正则如上),如果为表情,截取至表情之前即可。
八、总结:
-
Unicode 是字符集,不是编码方式。UTF-8、UTF-16、UTF-32、UCS-2、UCS-4 为编码方式。
-
字节编码的“派别”归类
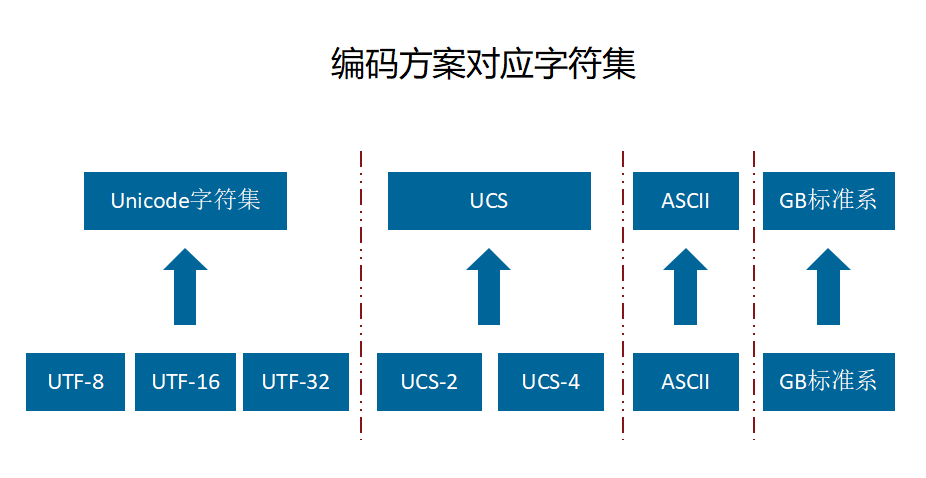
-
UTF-8、UTF-16、UTF-32编码比较

九、拓展阅读:
[1]维基百科-unicode:https://en.wikipedia.org/wiki/Unicode
[2]维基百科-国际标准化组织:https://en.wikipedia.org/wiki/InternationalOrganizationfor_Standardization(iso)
[3]维基百科-统一码联盟:https://en.wikipedia.org/wiki/Unicode_Consortium
[4]维基百科-通用字符集(UCS):https://en.wikipedia.org/wiki/UniversalCodedCharacter_Set
[5]维基百科-UCS-4:https://hu.wikipedia.org/wiki/UTF-32/UCS-4
[6]维基百科-UTF-32:https://en.wikipedia.org/wiki/UTF-32
[7]维基百科-UTF-16:https://en.wikipedia.org/wiki/UTF-16
[8]维基百科-UTF-8:https://en.wikipedia.org/wiki/UTF-8
[9]Unicode与JavaScript详解:http://www.ruanyifeng.com/blog/2014/12/unicode.html
[10]移动前端手机输入法自带emoji表情字符处理:https://blog.csdn.net/binjly/article/details/47321043
[11]emoji存库以及乱码问题解决:https://blog.csdn.net/Mr_LXming/article/details/77967964


