

了解了Kafka的窗户和内核之后,我们深入Broker中,看看Topic和Broker之间的关系,它们之间到底是用什么联系起来的。Broker对Message的持久化是如何处理的。
Partition
Kafka的Partition是分区的概念,在Kafka中,一个Topic可以有多个Partition,换句话说,就是一个Topic中的内容是被多个Partition分割的。对于Partition,我们需要注意以下几个要点:
- 一个Topic下的所有Partition是有顺序的,或者说在创建Topic和Partition时,Partition的顺序就已经是确定了的。
- 每条进入Partition中的Message都会获得一个自增的ID,这个ID称为Offset(消息的偏移量)。
- 通常在说Message的Offset时,只是针对该条Message所在的Partition而言。举个例子,Partition-0中Offset为3的Message和Partition-1中Offset为3的Message没有任何关系。
- 当说到Message的顺序时,通常有两种解读:
- 业务语义上的Message顺序,如下图所示,1至4条Message之间是有语义顺序的,可以理解为是消息生产者生产消息时的顺序。
- Partition中的Message顺序,如下图所示,Partition-1中的Message如果按照Offset的顺序,那么第一条和第二条Message其实是语义上的第一条和第三条Message。
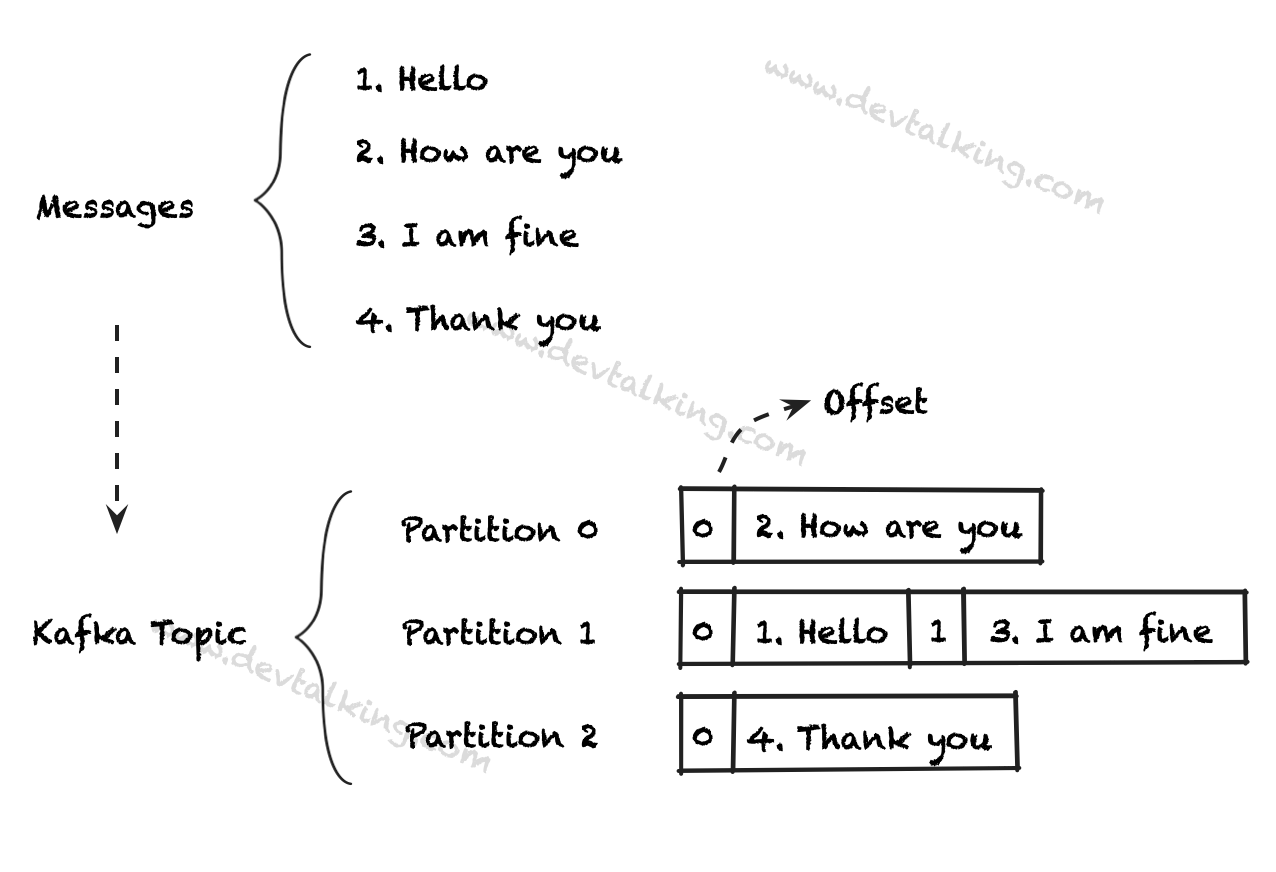
- 当Message进入Partition后,它的Offset和内容就无法再修改了。
- Message默认是随机存储在一个Topic下的不同的Partition中的,如上图。除非显示的指定Partition。
- 存储在Partition中的Message是有时效性的,默认是保存一周,可以通过配置更改(后续章节会介绍)。
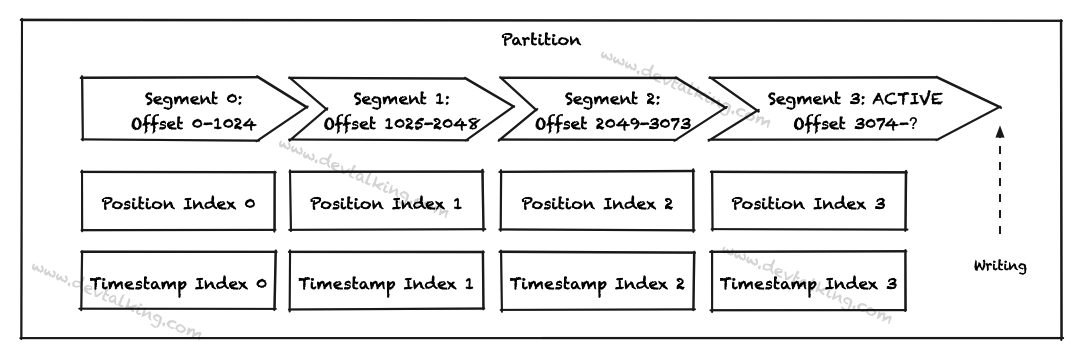
在Kafka中,一个Partition对应物理机器上的一个文件夹,文件夹命名会以Topic名称加序号表示。换句话说,Partition在Broker中以文件夹的形式存在。每个Partition文件夹中会有多个大小相等的日志段文件(Segment File),消息生产者生产的消息发送到Broker后就会以追加到日志文件末尾的方式持久化到Partition中。
Replication
我们再来看一个和Partition相关的概念,Replication。从字面意思就可以看出,这是Partition副本的意思。Replication Factor决定了将Partition复制几份,也就是将数据复制几份。Partition的副本也是会随机被分配到任意Broker中。下图展示了它们之间的关系:
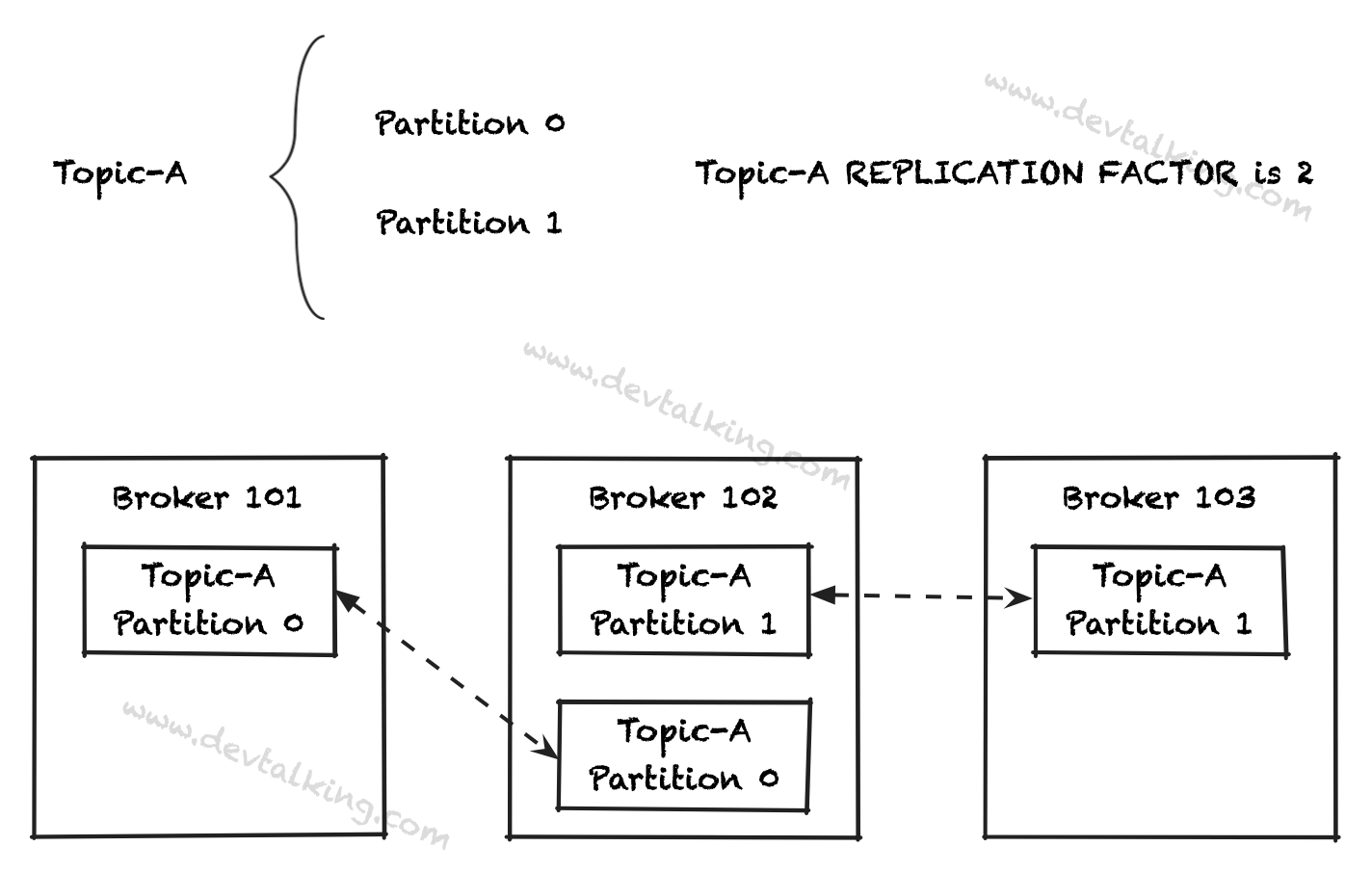
从上图中可以看出,如果Broker 102挂掉了,是不会影响我们的Kafka集群的运转的,因为我们的数据并没有丢失,Broker 101和Broker 103中任何持久化着Topic-A的数据。这就是Replication的作用,它可以有效保证数据在Kafka系统中的完整性和有效性。
Leader for Partition
当Partition有多个副本时,又会引出一个概念,那就是Partition的Leader Broker。关于Partition的Leader有以下几个要点:
- 在任何时候,只有一个Broker会成为某个Partition的Leader。
- 只有作为Leader的Broker才会为Partition接收和处理数据。其他持有Partition副本的Broker只是从Leader Broker同步数据。
- 每个Partition只有一个Leader Broker,但可以有多个随从Broker,或者说是ISR(in-sync replica)。
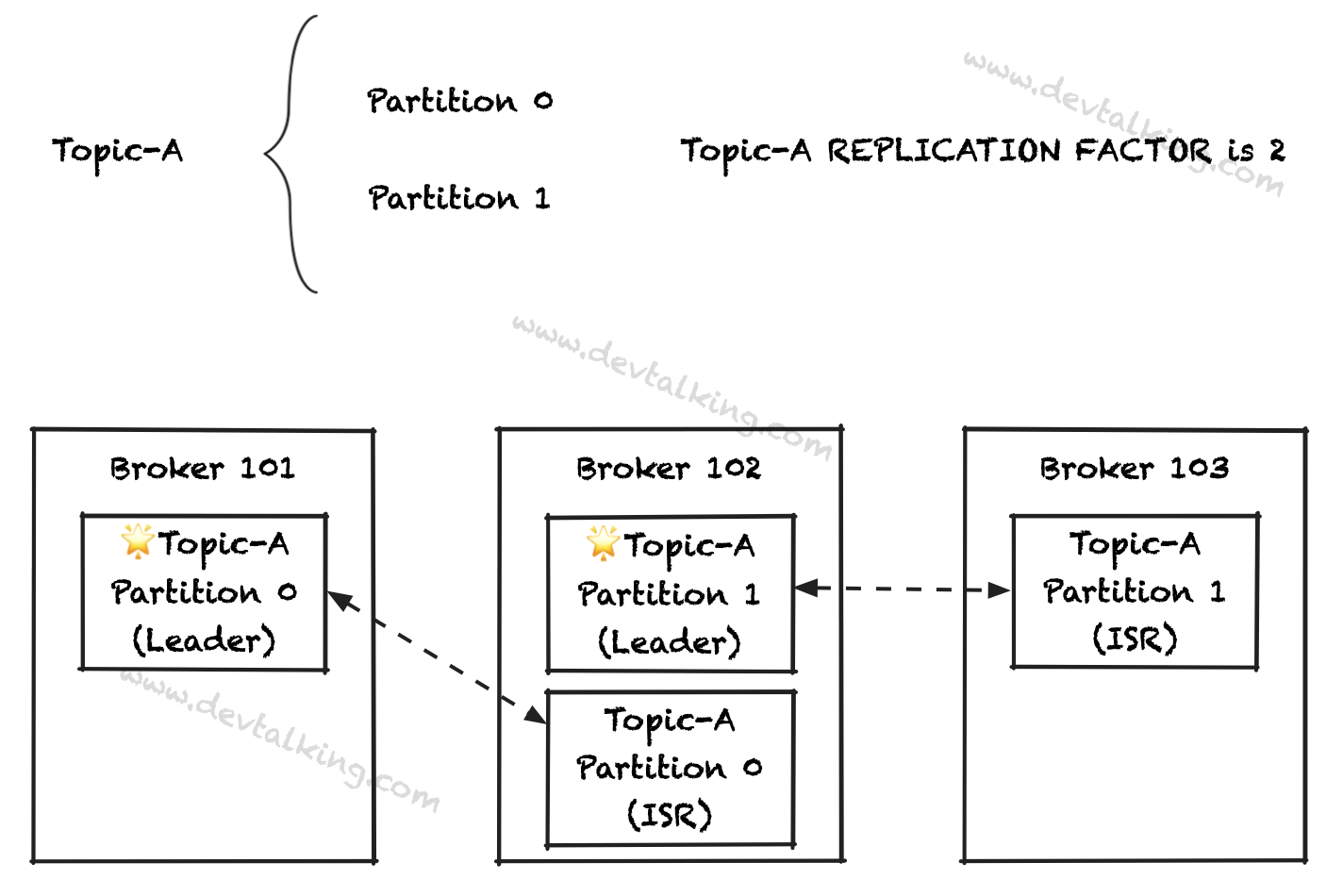
上图所示,Broker 101是Topic-A Partition 0的Leader Broker。Broker 102是Topic-A Partition 1的Leader Broker。如果Broker 101挂掉了,那么Broker 102会自动被选举为新的Topic-A Partition 0的Leader Broker。当Broker 101恢复后,会重新将Leader交还给Broker 101。选举Leader Broker的工作由Zookeeper帮Kafka完成,这里暂做了解。
Partition Count and Replication Factor Convention
在通常情况下,设置Topic的Partition数量和Replication数量有一些惯例可以参照。
首先这两个参数是非常非常重要的,直接关系到Kafka集群的性能、高可用问题。在创建Topic之前,一定要先思考如何设置Partition数量和Replication数量。并且尽量不要在之后调整Partition数量和Replication数量。
前文中讲过,如果在Kafka运行时调整Topic的Partition数量,会直接影响Message根据Key的顺序问题。如果调整Replication数量,会给集群带来较大的性能压力,因为涉及到Zookeeper要重新选举Leader一系列操作。
所以在较小的Kafka集群中(小于6个Broker),一般每个Topic的Partition数量为Broker数量的两倍。在较大的Kafka集群中(大于12个Broker),一般每个Topic的Partition数量等于Broker的数量。介于这两者之间的可以根据具体业务和IaaS的情况,设置两倍于Broker或等于Broker数量。
Replication数量最少为2,通常为3,最大也就设置到4。前文中说过,Replication的数量关系到我们可以容忍有几个Broker挂掉(N -1个)。而且如果acks=all,Replication太多会影响效率,并且会增加磁盘空间。所以综上,一般将Replication Factor设置为3,比较合理。
Segment File
我们已经知道了Topic是由Partition构成的。再来说说构成Partition的Segment文件。
进入kafka_2.12-2.0.0/data/kafka这个目录后(这里的目录暂做了解,后续在Kafka搭建小节里会讲到),可以看到一些以Topic name-index这种格式命名的文件夹,这些就是Partition:
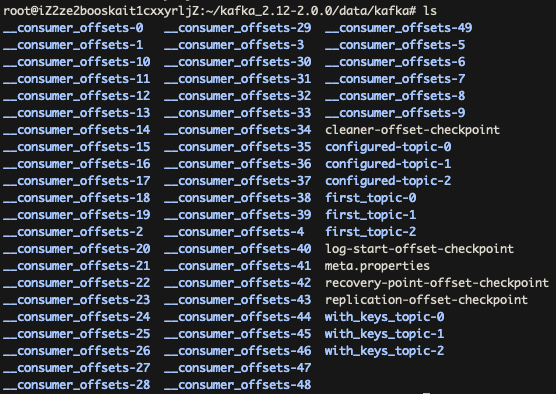
进入first_topic-0这个Partition后,可以看到有一些文件,*.log就是Partition的Segment文件:

Partition的Segment文件涉及到两个参数:
log.segment.bytes:设置每个Segment文件的大小,默认是1GB。log.segment.ms:设置每个Segment文件允许写入的时间,默认是一周。
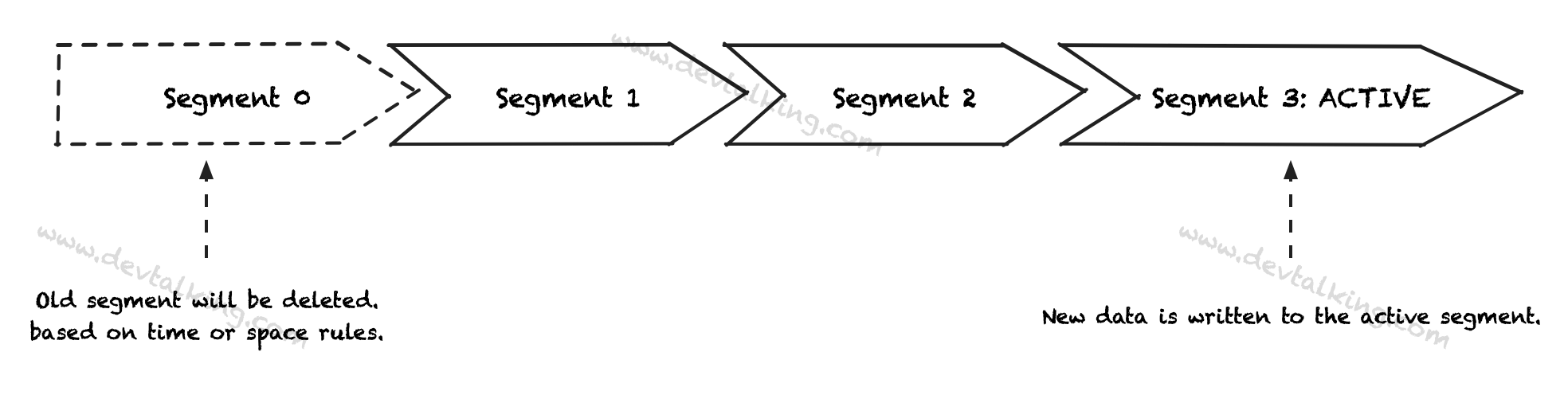
上面两个参数说明了,Partition的Segment文件可以有多个,当一个Segment的大小达到log.segment.bytes参数设置的大小后,关闭(不允许写入)这个Segment文件,并自动开启下一个Segment文件。如果一个Segment文件在log.segment.ms参数设置的时间内没有写满,那么也将自动关闭,并开启新的Segment文件。所以始终只会有一个处于活跃状态的Segment文件可以被写入。
log.segment.bytes设置的越小,Partition的Segment文件数就越多,对关闭的*.log文件压缩操作就越频繁。log.segment.ms的值也同样影响文件压缩的频率。所以这两个参数要根据业务实际情况,对吞吐量的需求去合理设置。
在上图中,还看到*.index和*.timeindex两个文件,这两个都是帮助Kafka查找Message的索引文件:
*.index:这个文件记录了Message Offset,可以让Kafka通过Message Offset快速定位到Message。*.timeindex:这个文件记录了Message的时间戳,可以让Kafka通过绝对时间定位到Message。
这三个文件的名称是一样的,整个名称的长度为20位数字,第一个Segment文件从0开始,后续每个Segment文件的名称为上一个*.log文件中最后一条Message Offset,其他位数用0填充,比如:
0000000000000000000.index
0000000000000000000.log
0000000000000037489.index
0000000000000037489.log
0000000000005467283.index
0000000000005467283.log
用一张图来概括Partition和Segment文件的关系:
Delete Cleanup Policy
Kafka的Message既然是存在磁盘上的,那么必然会有数据回收或者数据清理的机制,这里涉及到一个参数log.cleanup.policy如果将值设置为delete,那么Partition中的Message会基于规则在一段时间后被删除。这里的规则有两个,一个是基于时间的,一个是基于Partition大小的。
log.retention.hours
log.retention.hours参数的值默认是168小时,既1周时间,也就是Partition中的未处于活跃状态的Segment文件只保留一周,一周后会被自动删除。
这个参数如果设置的比较大,那么意味着Topic的历史数据会保留较长时间,Consumer丢失数据的容错率会高一些。同时会占用更多磁盘空间。如果设置的比较小,意味着Topic的历史数据保留的时间较短,Consumer丢失数据的潜在风险较大,但是占用的磁盘空间较小。所以该值需要根据实际情况设置。
log.retention.bytes
log.retention.bytes参数的值默认是-1,也就是指Partition的大小是无穷大的,既不考虑Partition的大小。如果将其设置为524288000,那么就表示当Partition大小超过500MB时,会删除未处于活跃状态的Segment文件。
通常情况下,使用默认配置就好,既不考虑Partition大小,历史数据保留一周。但也可以根据业务自行设置,灵活组合。但有一点需要注意的是,这两个规则只要达到一个,就会启动清理数据的任务。
Compaction Cleanup Policy
另外一个策略是压缩策略,__consumer_offset这个Topic默认采用的就是这种策略,我们先看一张图:
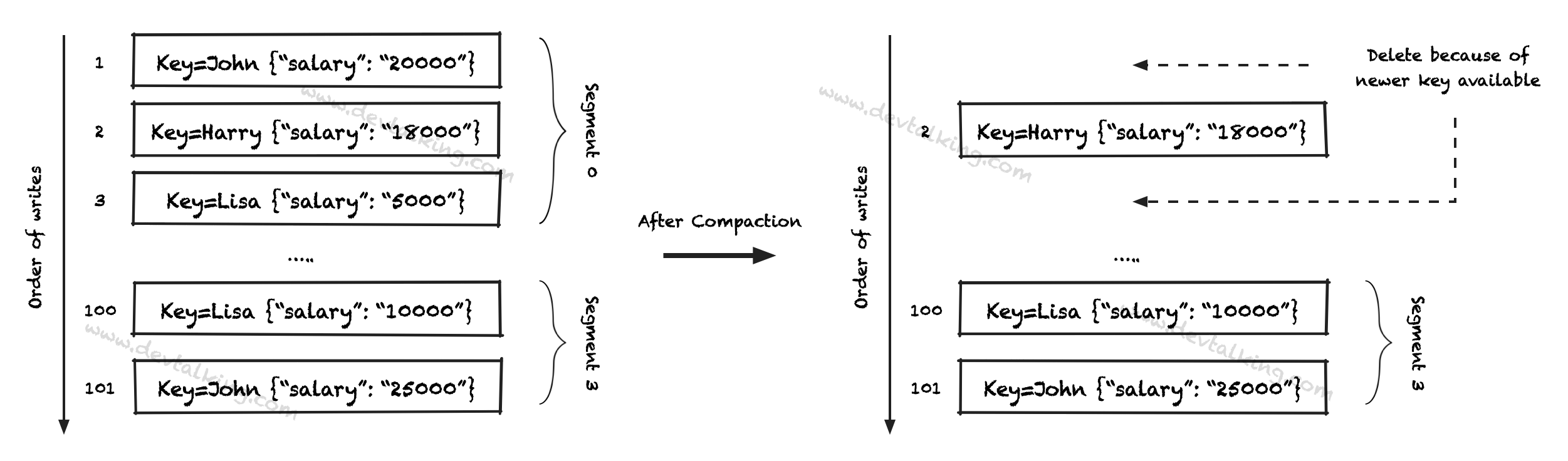
上图表示的应该比较清楚了,压缩模式就是把相同Key的旧数据删了,每个Key只留下最近的数据。这种模式相对DELETE策略,至少每个Key都会有数据,但是历史数据会丢失。
当log.cleanup.policy=compact时,有以下相关的一些参数需要我们注意:
segment.ms:该参数会使用默认的值,默认为7天。该参数表示等待关闭活跃状态Segment文件的时间。segment.bytes:每个Segment文件的大小,默认为1G。min.compaction.lag.ms:当Message可以被压缩的时候,要等待的时长,也就是延迟压缩的时间,默认是0。delete.retention.ms:当Message被标记为需要压缩到删除它之间的时间,默认为24小时。min.cleanable.dirty.ratio:压缩率,默认为0.5。
Cleanup Frequency
不论是删除策略还是压缩策略,都是针对Partition的Segment文件进行的,根本还是磁盘IO操作,所以这种清理工作不应该过于频繁,否则会对整个Broker造成性能方面的影响。对Segment文件的大小也要把控在合理的范围内。太小,太多的Segment文件肯定会使清理工作更加频繁。
另外还可以对log.cleaner.backoff.ms参数进行设置来控制清理频率,这个参数控制检测是否需要清理的时间,默认是15秒检查一次。将其设大一点,也可以降低清理频率。
总结
这一章节通过对Partition、Replication、Segment File的介绍可以了解Broker中对Message持久化的方式。通过对Partition Leader、Relipcation Factor、Message的处理策略的介绍了解了Kafka保证可用性和稳定性的基本策略。这些概念是之后我们进行实践时的基础。希望能给小伙伴们带来帮助。
