

node进程学习指北
1. 进程与线程
进程
- 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础,进程是线程的容器。
- 进程拥有独立的空间地址、数据栈,一个进程无法直接访问另外一个进程里定义的变量、数据结构,只有建立了 IPC 通信(Inter Process Communication),进程之间才可数据共享。node进程间通讯共有四种方法
线程
- 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.
- 线程本身不拥有独立的系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的一部分资源(地址空间、全局变量、子进程。。。),但是堆栈、局部变量等资源是独有的。
- 一个线程可以创建和撤销另一个线程;同一个进程中的多个线程之间可以并发执行
两者的区别
进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮。但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
-
简而言之,一个程序至少有一个进程,一个进程至少有一个线程。
-
线程的划分尺度小于进程,使得多线程程序的并发性高。
-
另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
-
线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在进程中,由进程控制执行。
-
从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
2. 单线程(node)与多线程(java、php)是如何处理并发的
问题:node 与 java 如何同时处理100个请求(假设该应用逻辑为:接受请求—访问数据库—返回数据)
多线程的处理办法(线程多开/线程池)
request ──> spawn thread
└──> wait for database request
└──> answer request
request ──> spawn thread
└──> wait for database request
└──> answer request
request ──> spawn thread
└──> wait for database request
└──> answer request
用不同的线程处理多个请求。
优点:真正的同时处理多个请求,感觉上应该比较快,实际并不一定
缺点:1.浪费资源:线程花费大部分时间使用0%CPU等待数据库返回数据。在这样做时,他们必须分配一个线程所需的内存,其中包含一个完全独立的程序堆栈。2.多线程的调用也会占用一定时间:他们必须启动一个线程虽然不像启动一个完整的进程那么昂贵但仍然不完全低廉。这样可能最终导致比单线程应用程序慢。
单线程的处理办法(事件循环、异步io)
request ──> make database request
——> request ──> make database request
——> request ──> make database request
/* 等待数据 */
database request complete ──> send response
---> database request complete ──> send response
---> database request complete ──> send response
单线程循环处理每个请求,将从数据库获取数据当成了异步io操作。
缺点是:这过程中不能有CPU密集处理,否则就会阻塞接受下一个请求。
优点是:系统资源占用比较少,我们不需要生成一个新的线程,所以我们不需要做很多很多的 malloc(动态内存分配),这会减慢我们的速度。
混合方法
综上,单纯的 多线程 与 单线程 都有各自的优缺点,配合不同的服务需求,一般会混合使用以上两种方法:多线程/多进程+事件循环。
例如,Nginx和Apache2将其网络处理代码实现为事件循环的线程池。每个线程运行一个事件循环,处理单线程请求,但请求在多个线程之间进行负载平衡。
一些单线程架构也使用混合方法。比如启动多个应用程序(例如,多核计算机上部署多个node.js进程),而不是从单个进程启动多个线程,然后使用负载均衡器在进程之间分配工作负载。(备注:Node的事件驱动已经解决了高并发量的问题,而多进程的主要是用来充分利用多核CPU。在很多现代操作系统中,一个进程的(虚)地址空间大小为约为4G,一般WINDOWS进程的用户空间为2G。所以多个进程就可以支配更多的系统资源。)
3. node的 "单线程"
node的单线程是指:js执行是单线程(不考虑node10 新加的worker功能)。Node.js启动后会创建V8实例,V8实例是多线程的,V8中的线程有:
- 主线程:获取代码、编译执行
- 编译线程:主线程执行的时候,可以优化代码
- Profiler线程:记录哪些方法耗时,为优化提供支持
- 其他线程:用于垃圾回收清除工作,因为是多个线程,所以可以并行清除
# demo5-1: 测试cluster多进程的 共享tcp与负载均衡
siege -c 20 -r 1 http://127.0.0.1:8000
# demo5-1: 去掉多进程之后
siege -c 20 -r 1 http://127.0.0.1:8000
4. node.js 创建子进程实现方式 child_process
子进程的作用:
- 进程中可以执行系统shell命令,让我们可以使用操作系统一些功能
- 如果有很耗时的任务,可以通过子进程来避免阻塞事件循环
创建子进程方法:
方法一、child_process.spawn(command [, args] [, options])
(1)用于执行非node应用,但不能直接执行shell
(2)子进程结果并不是执行完成后,一次性的输出的,而是以流的形式输出。对于大批量的数据输出,通过流的形式可以减少内存的使用。
const { spawn } = require('child_process');
const find = spawn('find', ['.', '-type', 'f']); // 列出所有的文件 shell find . -type f
const npnInstallReact = spawn('npm',['install','react', '-g'])
方法二、child_process.exec(command [, options] [, callback])
(1) 衍生一个 shell 然后在该 shell 中执行 command,command 一般是 shell 内置的 命令,如 ls,cat 等,也可以是shell脚本组成的文件,如 start.sh 等。需要注意的是exec执行的等级很高,执行后会出现安全性的问题。可以直接执行:rm -rf
(2) 子进程的结果保存在缓冲区,等完成后一次性传给父进程。这里的buffer是有最大缓存区的,如果超出会直接被kill掉,maxBuffer属性默认: 200*1024。所以一般不用来处理大数据量的操作。
(3)可以使用 callback;
let cp=require('child_process');
cp.exec('npm install react -g',function(err,stdout){
console.log(stdout);
});
cp.exec('echo hello world',function(err,stdout){
console.log(stdout);
});
方法三、child_process.execFile(program [, args] [, options] [, callback])
(1) file 是要运行的可执行文件的名称或路径,如 node.exe,不能是 start.js 这种脚本文件,默认情况下不会衍生 shell 比 child_process.exec() 稍微更高效。碰到危险的shell操作会发出警告。比exec要安全。
(2) 其他与exec类似
let cp=require('child_process');
cp.execFile('npm',['install','react', '-g'],function(err,stdout){
console.log(stdout);
});
方法四、child_process.fork(modulePath [, args] [, options])
(1) 用于执行node应用,会产生一个新的V8实例
(2) 返回的子进程将内置一个额外的ipc通信通道,允许消息在父进程和子进程之间来回传递。可以很方便的使用EventEmitter API进行通讯:
const fork = require('child_process').fork;
const compute = fork('./fork_compute.js');
上面四个方法的关系:
这些方法都是对spawn方法的复用,然后spawn方法底层调用了libuv进行进程的管理,具体可以看下图。
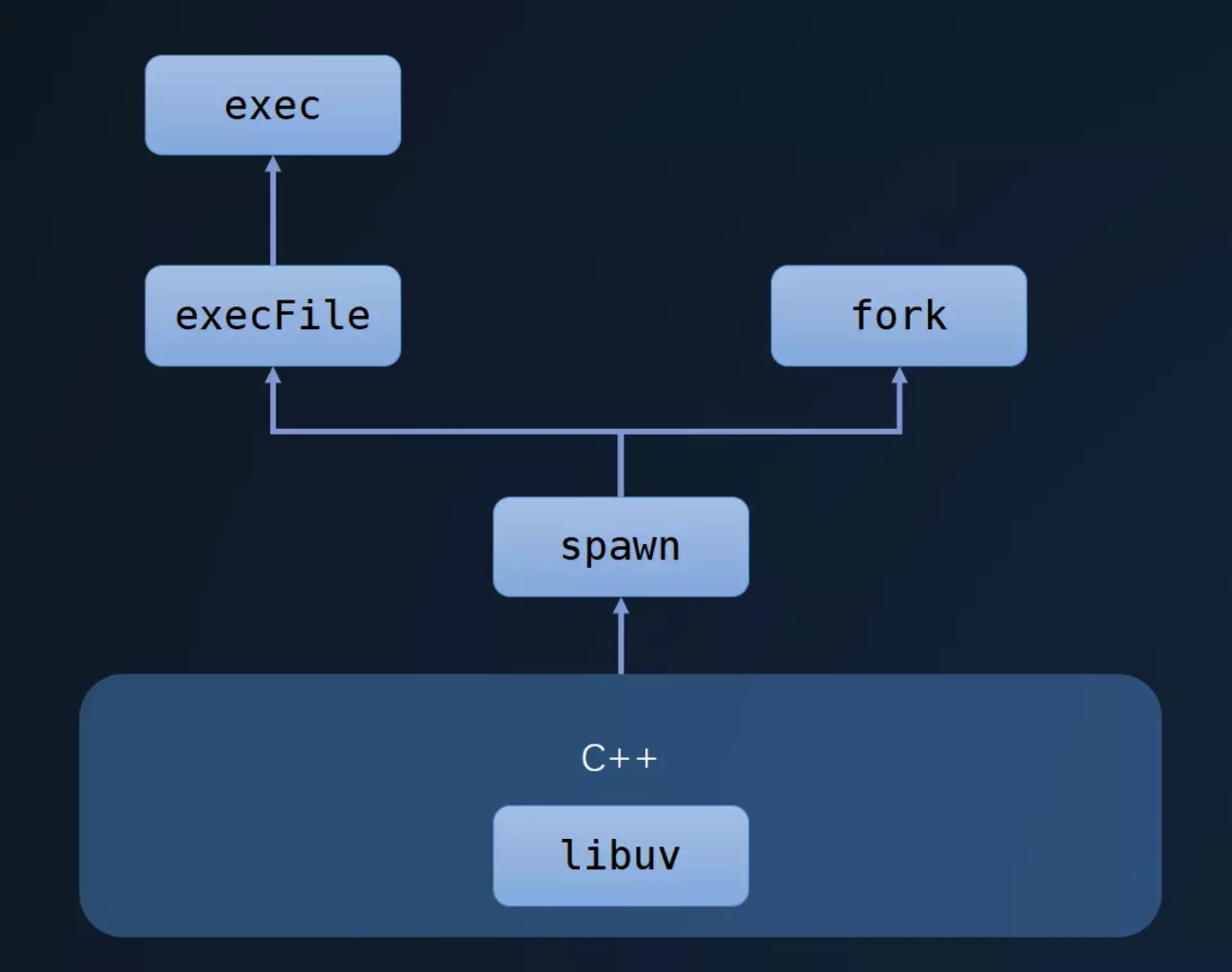 image-20190628041601722
image-20190628041601722
5. master-worker :常用的并发模型
简单图:
[图片上传失败...(image-2721e3-1561721997717)]
假定worker进程如下:
const http = require('http')
http.createServer((req, res) => {
res.end('Hello World\n');
}).listen( 3000 )
方案一、master代理模式
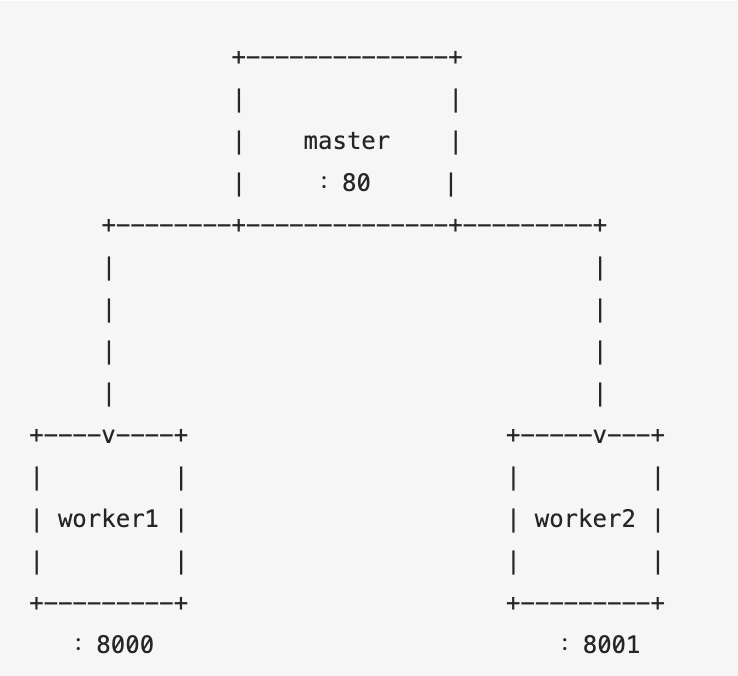 image-20190628050103016
image-20190628050103016
这种方案会碰到一个问题:master与worker的通讯问题。
第一种方案是:直接请求转发。但是这么做又会带来另一个问题,代理模式中十分消耗文件描述符(linux系统默认的最大文件描述符限制是1024),文件描述符在windows系统中称为句柄(handle),习惯性的我们也可以称linux中的文件描述符为句柄。当用户进行访问,首先连接到master进程,会消耗一个句柄,然后master进程再代理到worker进程又会消耗掉一个句柄,所以这种做法十分浪费系统资源。
句柄是一种特殊的智能指针 。当一个应用程序要引用其他系统(如数据库、操作系统)所管理的内存块或对象时,就要使用句柄。
为了解决这个问题,Node的进程间通信可以发送句柄,节省系统资源。
@ demo5-1 siege -c 10 -r 1 http://127.0.0.1:3000
// master.js
const fork = require('child_process').fork
const net = require('net')
console.log('master create, pid is ', process.pid)
// 创建TCP服务器
var server = net.createServer()
// 由TCP 服务监听端口
server.listen(3000, function() {
console.log('master listening on: ', 3000)
for (var i = 0; i < 2; i++) {
// 创建工作进程
var child = fork('./worker5-1.js')
// 监听端口后将服务器句柄发送给工作进程
child.send('server', server)
console.log('worker create, pid is ', child.pid)
}
// 关闭主线程服务器的端口监听,交给子进程去监听
server.close()
})
// child.js
const http = require('http')
const httpServer = http.createServer((req, res) => {
// 利用setTimeout模拟处理请求时的操作耗时
setTimeout(() => {
res.writeHead(200, { 'Content-Type': 'text/plain' })
res.end('Request handled by worker-' + process.pid)
}, 10)
})
process.on('message', function (msg, handler) {
msg
// 获取到句柄后,进行请求的监听
handler.on('connection', function(socket) {
// 将socket提交给HTTP服务器处理
httpServer.emit('connection', socket)
})
})
可以看到,多个进程对同一个服务响应的连接事件监听,谁先抢占,就由谁进行响应。这里就会出现一个Linux网络编程中很常见的事件,当多个进程同时监听网络的连接事件,当这个有新的连接到达时,这些进程被同时唤醒,这被称为“惊群”。这样导致的情况就是,一旦事件到达,每个进程同时去响应这一个事件,而最终只有一个进程能处理事件成功,其他的进程在处理该事件失败后重新休眠,造成了系统资源的浪费。其实主要是负载不均衡。
第二种方案:niginx 做反向代理 来 完成master的转发调度工作(原理:锁的使用)
http {
upstream localhost { // 代理的端口
server 127.0.0.1:8000;
server 127.0.0.1:8001;
keepalive 64;
}
server {
listen 8888;
server_name shenfq.com;
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_set_header Connection "";
proxy_pass http://localhost; # 这里要和最上面upstream后的应用名一致,可以自定义
}
}
}
<! -- demo5-2 -- >
// 此处demo的实现存在问题,有待解决。nginx代理之后,两个子进程会同时响应一个请求。
// master.js
const fork = require('child_process').fork
const ports = [8000,8001]
for (var i = 0; i < 2; i++) {
var child = fork('./worker5-2.js')
child.send(ports[i])
console.log('worker create, pid is ', child.pid)
}
// child.js
var http = require('http')
process.on('message', port => {
http.createServer(function(req, res) {
res.writeHead(200, { 'Content-Type': 'text/plain' })
res.end('Hello World '+port+'\n')
console.log('处理进程为:', process.pid)
}).listen(port, '127.0.0.1', function() {
console.log('子进程启动成功,端口号为:', port)
})
})
分析:如果我们自己用Node原生来实现一个多进程模型,存在这样或者那样的问题,虽然最终我们借助了nginx达到了这个目的,但是使用nginx的话,我们需要另外维护一套nginx的配置,而且如果有一个Node服务挂了,nginx并不知道,还是会将请求转发到那个端口。
6. node.js 多进程实现方式:cluster.fork
特点:
- 可以共享tcp连接 (其实利用的是类似上面方案一种的方法)
- 自带负载均衡
<!-- demo5-1: 测试cluster多进程的 共享tcp与负载均衡 siege -c 10 -r 2 http://127.0.0.1:8000 -->
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) { // 判断是否为主进程
console.log(`主进程 ${process.pid} 正在运行`);
// 衍生工作进程。
for (let i = 0; i < numCPUs; i++) {
cluster.fork(); // 再次执行当前文件
}
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
});
} else { // 子进程进行服务器创建
// 工作进程可以共享任何 TCP 连接。
// 在本例子中,共享的是一个 HTTP 服务器。
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world'+process.pid+'\n');
}).listen(8000);
console.log(`工作进程 ${process.pid} 已启动`);
}
cluster源码:基于child_process.fork 进行的封装
const { fork } = require('child_process');
cluster.fork = function(env) {
cluster.setupMaster();
const id = ++ids;
const workerProcess = createWorkerProcess(id, env);
const worker = new Worker({
id: id,
process: workerProcess
});
// 监听子进程的消息
worker.process.on('internalMessage', internal(worker, onmessage));
// ...
};
// 配置master进程
cluster.setupMaster = function(options) {
cluster.settings = {
args: process.argv.slice(2),
exec: process.argv[1],
execArgv: process.execArgv,
silent: false,
...cluster.settings,
...options
};
};
// 创建子进程
function createWorkerProcess(id, env) {
return fork(cluster.settings.exec, cluster.settings.args, {
// some options
});
}
其他部分的源码分析: 参考文章
上面只是简单的demo实现,实际生产中一个健壮的多进程模型需要考虑多个因素:
- 负载均衡,高并发是将请求平均分配给多个子进程。
- 子进程监听同一端口,减少句柄的浪费。
- 进程安全重启(平滑重启、限量重启)
- 工作进程存活状态管理
- 进程性能优化
- 多进程模式下定时任务处理等
- 。。。。。
7. PM2 中 的 cluster 、Egg 中的多进程模式
PM2的cluster模式:也是基于child_process.fork进行的封装,跟 cluster API类似
直接通过 pm2 start ./index.js -i number, 直接启动多个node进程,结合cluster的优势。直接实现了一个比较完善的master-worker多进程模型。能满足我们的大部分需求。
另外还有Egg 中的多进程增强模型(Egg-Cluster模块)
上面两个多进程模式中都存在一个守护进程
定义: 守护进程运行在后台不受终端的影响,什么意思呢?Node.js 开发的同学们可能熟悉,当我们打开终端执行 node app.js 开启一个服务进程之后,这个终端就会一直被占用,如果关掉终端,服务就会断掉,即前台运行模式。如果采用守护进程进程方式,这个终端我执行 node app.js 开启一个服务进程之后,我还可以在这个终端上做些别的事情,且不会相互影响。
守护进程创建步骤
创建步骤
-
创建子进程
-
在子进程中创建新会话(调用系统函数 setsid)
-
改变子进程工作目录(如:“/” 或 “/usr/ 等)
-
父进程终止
// index.js 目前有点问题。
const spawn = require('child_process').spawn;
function startDaemon() {
// 1. 使用 spawn 创建子进程
const daemon = spawn('node', ['daemon.js'], {
// 2. detached 为 true 可以使子进程在父进程退出后继续运行(系统层会调用 setsid 方法)
detached : true,
// 3 .指定当前子进程工作目录若不做设置默认继承当前工作目录
// cwd: '/usr',
stdio: 'ignore',
});
console.log('守护进程开启 父进程 pid: %s, 守护进程 pid: %s', process.pid, daemon.pid);
// 4. 退出父进程
daemon.unref();
}
startDaemon()
// daemon.js 文件里处理逻辑开启一个定时器每 10 秒执行一次,使得这个资源不会退出,同时写入日志到子进程当前工作目录下
const fs = require('fs');
const { Console } = require('console');
// custom simple logger
const logger = new Console(fs.createWriteStream('./stdout.log'), fs.createWriteStream('./stderr.log'));
setInterval(function() {
logger.log('daemon pid: ', process.pid, ', ppid: ', process.ppid);
}, 1000 * 10);
守护进程最重要的是稳定,如果守护进程挂掉,那么其管理的子进程都将变为孤儿进程,同时被init进程接管,这是我们不愿意看到的。于此同时,守护进程对于子进程的管理也是有非常多的发挥余地的,例如PM2中,将一个进程同时启动4次,达到CPU多核使用的目的(很有可能你的进程在同一核中运行),进程挂掉后自动重启等等,这些操作都是通过守护进程的方式来实现的。
测试工具推荐---siege
在mac上安装ab会遇到不少问题,为了方便可以使用siege。功能基本类似。
使用方法:
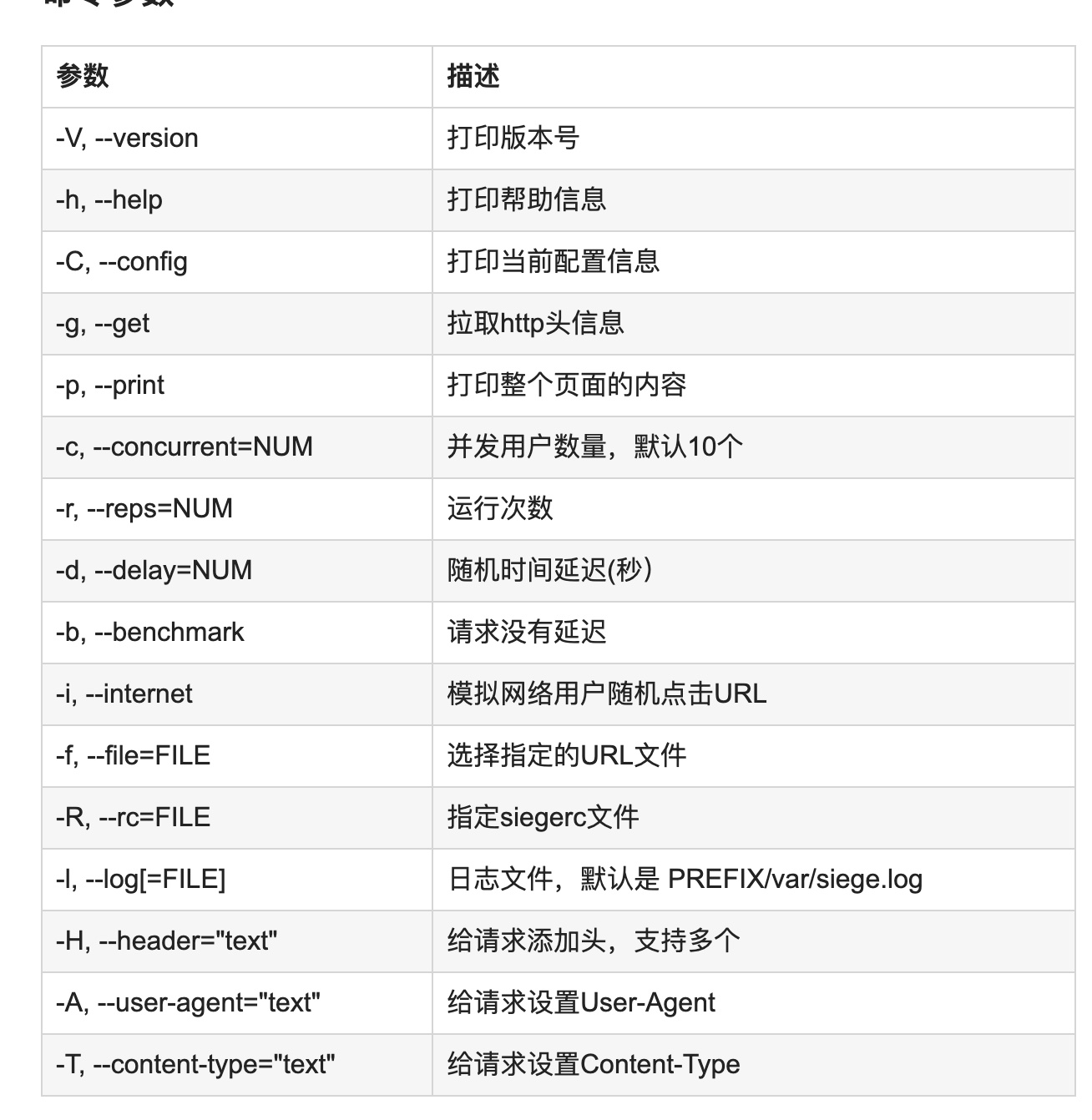 image-20190628083511315
image-20190628083511315 结果分析: [图片上传失败...(image-da6b32-1561721997717)]
参考文章:
