

其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造,自2019年1月出版以来已重印3次。
PDF全文链接:视觉问答:VQA经典模型Up-Down以及VQA 2017challenge 冠军方案解读
本文作者 Johnny
引言
视觉问答(Visual Question Answering,VQA)是一个需要理解文本和视觉的新领域。通常需要结合文本和图像技术来做,由于深度学习技术显著地改善了自然语言处理和计算机视觉结果,我们可以合理地预期VQA将在未来几年变得越来越准确,未来基于VQA的应用也会越来越多的出现在现实生活中。
VQA是什么?
vqa是一个结合自然语言和计算机视觉的高级任务,需要计算机有一定的推理能力,相比传统计算机视觉任务有更高的要求。建立一个能够回答关于图像的自然语言问题的系统一直被认为是一个很有前景的方向。根据下面图像,想象一个机器人,它可以回答这些问题:
l 图像中有什么?
l 有人类吗?
l 什么运动正在进行?
l 谁在踢球?
l 图像中有多少球员?
l 参赛者有哪些人?
l 在下雨吗?

那么,图像中有多少足球运动员?这是VQA中的counting问题,我们可以数一数,可以看到有十一名球员。因为我们能够分类出运动员和裁判,所以不会将裁判员也计数。
尽管作为人类,我们通常可以轻松地执行此任务,但研发具有这些功能的系统似乎更接近于科幻小说,而非当然人工智能(AI)所能实现的。然而,随着深度学习(DL)的出现,我们目睹了视觉问答(VQA)方面的巨大研究进展,使得能够回答这些问题的系统正在出现,并带来很有希望的成果。
up-down 论文解读
接下来介绍的这篇论文,是VQA领域比较重要的工作,其重要性不亚于faster rcnn在目标检测领域的地位。
题目叫做<Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering>, 作者来自澳洲国立大学,阿德莱德大学,微软研究院,京东AI研究院和麦考瑞大学,该方法简称up-down

简介
VQA中最核心的问题是如何提取文字和图像的特征,并进行特征融合。由于卷积神经网络在图像分类中取得了巨大进展,之前的方法大多用基于分类的网络提取图像的全局特征,对于问题通过embeding 方法+ lstm或者gru去提取特征,然后融合,这种方法只考虑了图像的整体特征,但是缺乏对局部特征的建模,因此对于某些问题回答的不是很好。
本文提出一种自上而下与自下而上相结合的注意力模型方法,应用于视觉场景理解和视觉问答系统的相关问题。其中基于自下而上的关注模型(使用Faster R-CNN)用于提取图像中的兴趣区域,获取对象特征;而基于自上而下的注意力模型用于学习特征所对应的权重(使用LSTM),以此实现对视觉图像的深入理解。
为什么使用Faster R-CNN 而不使用CNN?

从图中可以看出使用CNN需要使用比R-CNN更多的特征,而且很多额特征往往是无用的。R-CNN的目标检测方法,首先针对图像获取兴趣区域,然后对每个兴趣区域应用目标检测器,这样就可以准确的获得图像类别;而CNN方法需要输入整幅图像,而且用于大样本分类的网络往往很复杂,计算量更大。另外,Faster R-CNN对之前几代R-CNN方法进行改进,实现了只输入一次就可以识别所有对象的能力,极大的提高的处理效率。
自下而上的关注模型
文中提及使用Faster R-CNN实现自下向上的关注模型,从图中可以看出相比之前不同之处在于,通过设定的阈值允许兴趣框的重叠,这样可以更有效的理解图像内容。文中对每一个感兴趣区域不仅使用对象检测器还使用属性分类器,这样可以获得对对象的(属性,对象)的二元描述。这样的描述更加贴合实际应用。
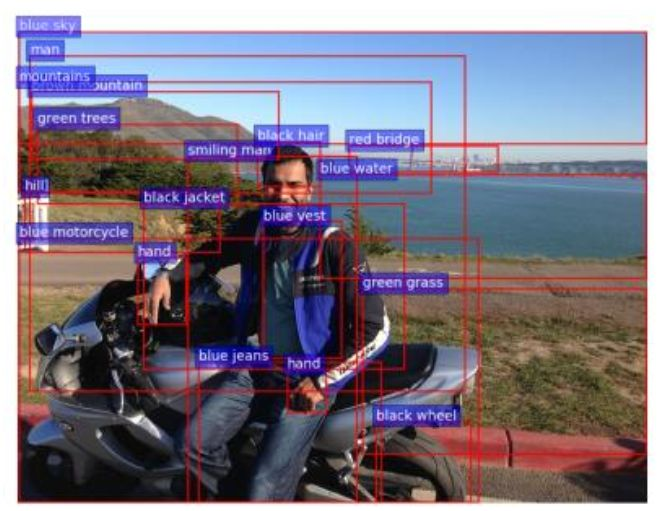
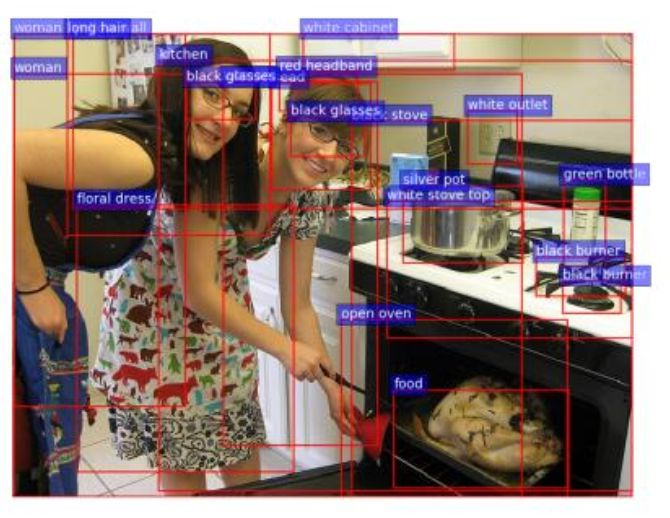
自上而下的关注模型
文中提到使用;两层LSTM模型,一层用于实现自上而下的注意力,一层实现语言模型。
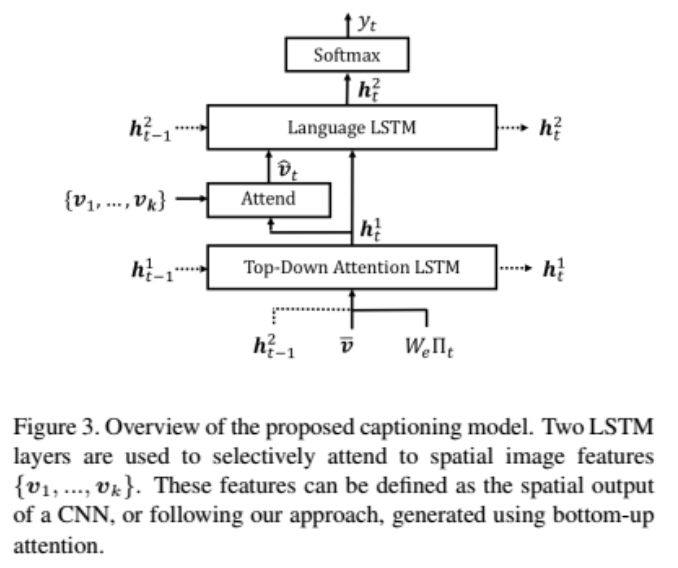
文章中提到的公式如下:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/22/16c18484520b7440~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/22/16c184844f6df7e9~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/22/16c18484530ff845~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/22/16c184845178b4c6~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
实验结果
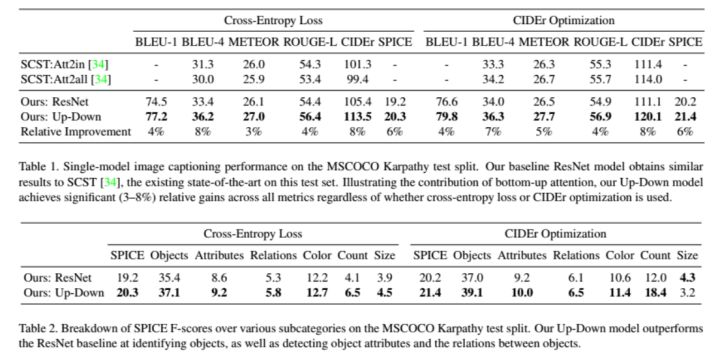
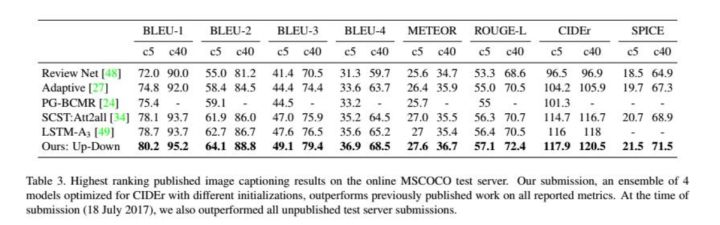

从实验结果可以看出,文中所提方法的确获得良好结果。并且通过可视化结果看出,基于faster rcnn的特征可以有效的理解问题的描述,并定位出关于问题的目标。
2017 VQA Challenge 冠军方案解读
2017 VQA冠军同样是这篇文章的作者,用了up down的方法,但是增加了一些tricks。接下来我们看看用了什么trick能给up down带来进一步提升。
VQA2.0数据集
大家比较常用的数据集就是 VQA 这个数据集,来自 Gatech 和微软;他们在去年发布了第一个版本。由于这个数据集很新,所以还存在一些问题:你可以用简单的通过死记硬背来回答对很多问题,获得 ok 的效果。比如说 yes/no 问题,如果永远回答 yes,你就能答对大部分。所以这个数据集的答案有一定先验,不是很平衡。
今年,他们在去年的基础上,采集了新的数据,发布了 VQA-v2 的版本,这个版本比之前的版本又大了一倍。一共有 650000 的问题答案对,涉及 120000 幅不同的图片。
这个新的数据库主要解决了答案不平衡的问题。对于同一个问题,他们保证,有两张不同的图片,使得他们对这个问题的答案是不同的。

在新的 VQA-v2 中,对于 yes/no 问题,yes 和 no 的回答是五五开。
VQA 基本建模方法
首先把 VQA 问题看作分类问题。由于 VQA 数据集中的问题大多跟图片内容有关,所以其实可能的正确答案的个数非常有限,大概在几百到几千个。
一般来说,会根据训练数据集中答案出现的次数,设定一个阈值,只保留出现过一定次数的答案,作为答案的候选选项。然后把这些候选答案当作不同的标签,这样的话 VQA 就可以当作一个分类问题。
其次是使用 Joint embedding 方法。就是对于一张图片,一个问题,我们分别对图片和问题用神经网络进行 embed,把他们投影到一个共同的“语义”空间中,然后对图片和问题特征进行一些操作(比如连接,逐元素相乘啊等等),最后输入进一个分类网络;
根据训练集的数据 end-to-end 训练整个网络。
以下为本文的整体框架:
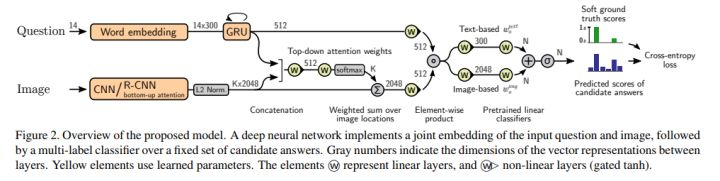
简而言之,这是一个 joint RNN/CNN embedding 模型,加上一个简单的问题对图片的注意力机制。
本文使用的一些 trick 汇总:
· 把 VQA 看成多类别分类(mutli-label clasification)问题,而不是多选一;
· 使用 soft score 作为 label;
· 使用 gated tanh 作为非线性层的 activation;
· 使用了 bottom-up 的图片特征;
· 用预训练的特征对最后的分类网络进行初始化;
· 训练时使用大 mini-batch,并在 sample 训练数据时使用均衡的 sample 方法。
多类别分类
在 VQA-v2 数据集中,由于数据采集自不同的 turker,所以同一张图片同一个问题可能会有多个答案。在数据集中,每个答案都有 0 到 1 的 accuracy。
基于这样的事实,本文并没有像其他论文一样做多选一的分类问题,而是转换成了 multi-label 分类问题。原本的 softmax 层被改为了 sigmoid 层。因此,最后的网络输出给了每个答案一个 0-1 的分数。
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/22/16c184845152a7d7~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
这个公式和普通的二值分类的 binary cross entropy 非常像。事实上,如果 ground truth accuracy 是 0 或者 1 的话,这个公式就等价于 binary cross entropy。
虽然在预处理时,我们根据答案的出现次数滤掉了一些不常见的答案,但是我们仍然会使用这一部分数据,只是认为这个问题所有候选答案的 accuracy 都是 0。
看成多类别分类效果更好的原因有二:首先,sigmoid output 能够对有多个答案的数据进行训练;其次,soft target score 提供了更丰富的训练信号。
大 minibatch 和均衡 sample
本文他们尝试了多种 minbatch size 的可能,他们发现,256, 384,512 作为 batch size 效果都不错,比更多数据或者更少的数据要更好。
均衡 sample 的设计来源于 vqa v2 本身的特性。由于每个问题,都可以找到不同的答案,所以这里作者强制在同一个 batch 中,每个问题都要出现两次,并且问题的答案需要是不同的。
其他的比如使用Bottom up特征其实和论文里写的是一样的啦。
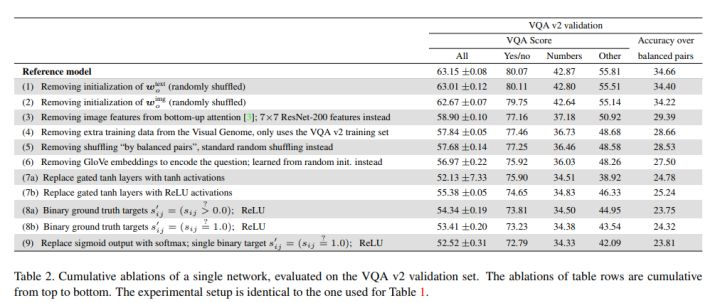
这几改进对结果的影响可以在此表中展现,可以看到每移除一项变化对结果的影响。
Ensemble
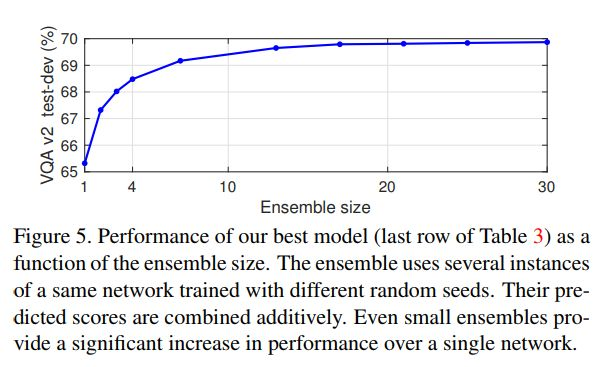
Ensemble 对于结果的提升也是非常大的,下图表现了 Ensemble 的个数对结果的影响。
他们一共融合了30个模型,比原始结果提高了5个百分点。。
VQA潜在的应用
VQA有许多潜在的应用。最直接的应用可能是帮助盲人和视障人士。VQA系统可以提供有关Web或任何社交媒体上的图像的信息。另一个明显的应用是将VQA集成到图像检索系统中。这可能会对社交媒体或电子商务产生巨大影响。VQA也可以用于教育或娱乐目的。
总结:
VQA是一个需要理解文本和视觉的新领域。由于深度学习技术显著地改善了NLP和CV结果,我们可以合理地预期VQA将在未来几年变得越来越准确。
与AI中的许多其他任务一样,构建的数据集和定义的度量标准以某种方式塑造了迄今为止所做的研究工作。评估VQA系统的最佳方式仍然是一个悬而未决的问题,很有可能新的数据集和度量标准将有助于加深和改进质量概念。
参考文献:
[1] Anderson P, He X, Buehler C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6077-6086.
[2] Teney D, Anderson P, He X, et al. Tips and tricks for visual question answering: Learnings from the 2017 challenge[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4223-4232.
[3] Antol S, Agrawal A, Lu J, et al. Vqa: Visual question answering[C]//Proceedings of the IEEE international conference on computer vision. 2015: 2425-2433.
[4] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[5] Girshick R. Fast r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
