


在 UI2CODE 项目中,我们大量使用了深度学习方法来做一些物体检测。而深度学习模型的训练,避免不了存在需要大量的样本。在这篇文章中,我们将介绍我们如何利用工具,批量泛化出大量样本,为模型训练提供数据保障。
样本现状
我们的模型要解决的问题是在一个设计稿图片上识别出基础控件等信息,包括位置和类别。而它所需要的样本,主要存在两个问题:
-
数据量少:一个APP的页面是有限的,特别是针对单个APP做优化适配的时候,页面的数量是相对较少的,可能在几十到上百个。 而模型的对样本数量的需求是巨大的,特别像较为复杂的模型,对数据量的要求至少是万级别的,单靠真实样本,是远远达不到要求的。
-
标注成本高:物体检测的样本标注,不仅需要标注物体的类别,更需要标注出物体的具体位置,而一个样本上会存在多个物体标注。 因此,这类样本打标成本非常大。
样本获取途径
获取样本,主要有几种途径。
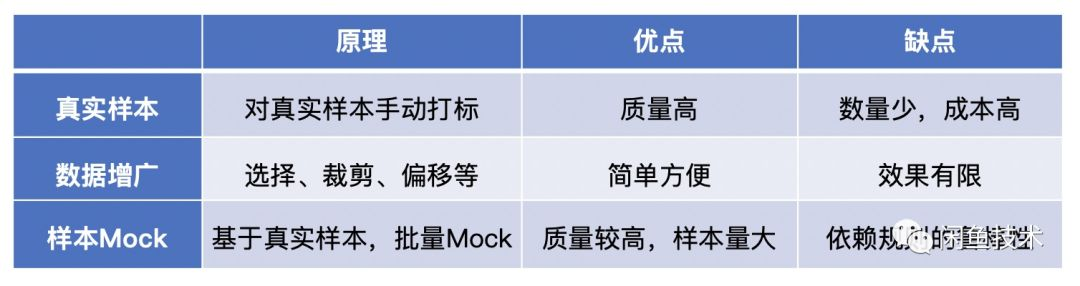
对于真实样本,这类质量是最高的,要想训练出效果很好的模型,这类样本基本是必不可少的,但是由于这类样本数量少,成本高,因此还需要其他方法来补充样本量。
对于数据增广,这种方法简单快速,但是效果也有限,特别是对于我们 UI2CODE 里识别控件这个任务来说,做旋转等操作基本是无效的。
因此,我们需要利用样本Mock,来扩充我们的数据量,尽量模拟出质量又多,量又大的样本。这里我们选择的是利用Weex页面来进行样本的Mock泛化。(当然还有一些其它方法,比如利用 Android 的特性,在运行时的APP页面,抓取页面数据,经过过滤和清洗,得到带标注的样本,这里不做展开)
WEEX页面样本泛化
在这里,我们介绍如何利用 Weex 页面,来批量泛化样本,并且得到样本标注的方法。
前端页面特点
之所以选择使用前端页面来生成样本,是因为前端页面更多的是做一些数据展示,并且其拥有完整的 DOM 树,只要我们拿着DOM树就可以解析出里面的各个元素。
对于节点内容,只要我们改变元素内容即可。这样我们就可以由一个前端页面很方便地泛化出不同文字、不同图片的多个样本。
当然,我们的闲鱼APP上有大量的Weex活动页,这也是我们选择做Weex页面泛化的原因之一。
思路
我们需要的基础控件的分类有“文本”、“图片”、“Shape”这三类,对于一个页面来说,我们的文本和图片内容基本都是可替换的,因此我们解析出所有节点以后,对里面的文本和图片进行替换,再进行渲染就可以得到新的样本。
利用Puppeteer实现
要想得到Weex页面,需要有一个渲染容器,并且我们可以很方便地修改其内容。这里,我们选择了Google的Puppeteer,它是Google推出的可以运行 Chrome Headless 环境以及对其进行操控的js接口套装。通过它,我们可以模拟一个Chrome运行环境,并且进行操控。 官方简介在这里.
首先启动一个不带界面的浏览器:
const browser = await puppeteer.launch({
headless: true
});
启动一个页面,然后打开一个网站:
const page = await browser.newPage();
await page.goto(nowUrls, {waitUntil: ['load','domcontentloaded','networkidle0']});
模拟IPhone6环境:
await page.emulate({
'name': 'iPhone 6',
'userAgent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
'viewport': {
'width': 750,
'height': 1334,
'deviceScaleFactor': 1,
'isMobile': true,
'hasTouch': true,
'isLandscape': false
}
});
搜索所需控件:
let
d_root = document.querySelectorAll('.weex-root'
);
let
nodes_root = [];
collectChildren(d_root, nodes_root);
/**
* 遍历节点,搜集所有需要的控件
*/
function
collectChildren(d, _nodes) {
for(var
i = 0,l = d.length;i < l;i++){
let hasPushed = false
;
//nodeType === 1 时 push
if (d[i].nodeType !== 1
&& d[i].nodeType !== 3) {
continue;
}
if(d[i].style){
let backgrounColorValue = d[i].style['background-color'];
if(backgrounColorValue && backgrounColorValue !==
'rgb(255, 255, 255)' && backgrounColorValue !==
'rgb(0, 0, 0)' && backgrounColorValue !==
'transparent'){
_nodes.push(d[i]);
hasPushed =
true;
}
}
if(d[i].hasChildNodes()){
collectChildren(d[i].childNodes, _nodes);
}
else{
let _node = d[i];
let _className = _node.className;
if(!_className && _node.nodeName ===
'#text'){
_className = _node.parentNode.className;
}
if(_className && !hasPushed){
if(_className.indexOf('weex-text'
) > -1 || _className.indexOf(
'weex-image') > -1
){
_nodes.push(d[i]);
}
}
}
}
return _nodes;
}
获取控件信息:
/**
* 获取 基础视图元素的属性
*/
function getRealyStyle(node,attrKey){
let wvStyle = window.getComputedStyle(node);
if(node[attrKey] && node[attrKey] !== ''){
return node[attrKey];
}else{
return wvStyle[attrKey]
}
}
/**
* 获取 基础视图元素的位置
*/
function getViewPosition(node){
const {top, left, bottom, right} = node.getBoundingClientRect();
return {
"y": top,
"x": left,
"height": bottom-top,
"width": right-left
}
}
获取页面图片:
await page.screenshot({
path: pngName,
fullPage : true
});
清理数据:
部分页面会存在弹窗的情况(mask图层),而我们的标注规则是希望只标注上面的图层,因此还需要根据mask图层的位置和大小,过滤掉底下图层里的控件。
通过上述方法,我们就能得到各个文本、图片、Shape以及他们的位置和属性等。基于位置和控件类别信息,我们就能够得到带有位置和类别标注的样本。
泛化文本和图片
通过上面的方法,只要提供一个Weex页面的url,就可以获取到一个带有标注的真实样本,后面我们只要修改里面文本和图片节点的内容,就可以批量泛化出多个样本。这些样本基于真实的页面布局,质量相对较高,并且可以随意控制泛化比例,比如设置 1:10,就可以有100分样本生成出10000份,大大提高了样本量。
总结
通过Weex泛化样本的方法,我们由100多个Weex活动页,泛化出10000+个样本,并且无需手动打标,节省了大量的打标成本。且由于样本质量相对较高,模型的准确率得到了很大的提升。当然,我们也探索了很多其它方法,包括抓取Android运行时的页面数据来生成自动打标的数据,以及利用已训练模型自动预打标来节省手动打标的人力成本等,未来我们还会继续探索更多的样本生成及自动打标方法,为模型训练提供更多有用数据。
闲鱼团队是Flutter+Dart FaaS前后端一体化新技术的行业领军者,就是现在!客户端/服务端java/架构/前端/质量工程师通通期待你的加入,base杭州阿里巴巴西溪园区,一起做有创想空间的社区产品、做深度顶级的开源项目,一起拓展技术边界成就极致!
*投喂简历给小闲鱼→guicai.gxy@alibaba-inc.com


更多系列文章、开源项目、关键洞察、深度解读
请认准 闲鱼技术
