


背景
对于闲鱼这种处于高速增长期的部门来说,业务场景在快速膨胀,越来越多的业务数据对搜索能力有诉求。如果按照常规的方式为各个业务搭建独立搜索引擎服务,那么开发和维护的时间成本将是非常巨大的。
能否只用一套搜索引擎系统支撑不同业务场景产出的数据呢?不同场景的异构数据如何在一套引擎中兼容呢?闲鱼从实际的业务需求出发,搭建了一套通用搜索系统解决这个问题。
搜索原理简述
闲鱼使用的搜索引擎是阿里巴巴的HA3引擎,配合其上层的管控系统Tisplus2使用。可以拆分为以下几个子系统:
1. dump:接入搜索系统首先要做的就是把DB数据经过一些业务逻辑转换后(后面会详细描述的merge、join流程),按照引擎BuildService能够识别的文件格式写入到文件系统或者消息队列中供BS构建索引使用,这个过程分为全量与增量两种。
2. BuildService(简称BS):将dump产出的数据构建成索引文件。Searcher机器加载了BS产出的索引文件后才能提供倒排、正排、summary的查询服务。
3. 搜索业务网关:业务层封装统一服务接口,对业务接入方屏蔽搜索系统底层细节。
4. Search Planner(简称SP):组合搜索中台多种能力,调用算法服务对网关传入的查询串进行改写、类目预测、算分,实现多路召回、分层查询、翻页去重等功能,对QRS返回的结果进行包装返回。
5. 引擎在线服务:分为QRS与Searcher两种角色。SP的查询请求发送给QRS,QRS将请求转发到多台searcher机器上然后收集searcher返回的结果进行合并、算分、排序、返回。
整个搜索系统的简化版结构图如下
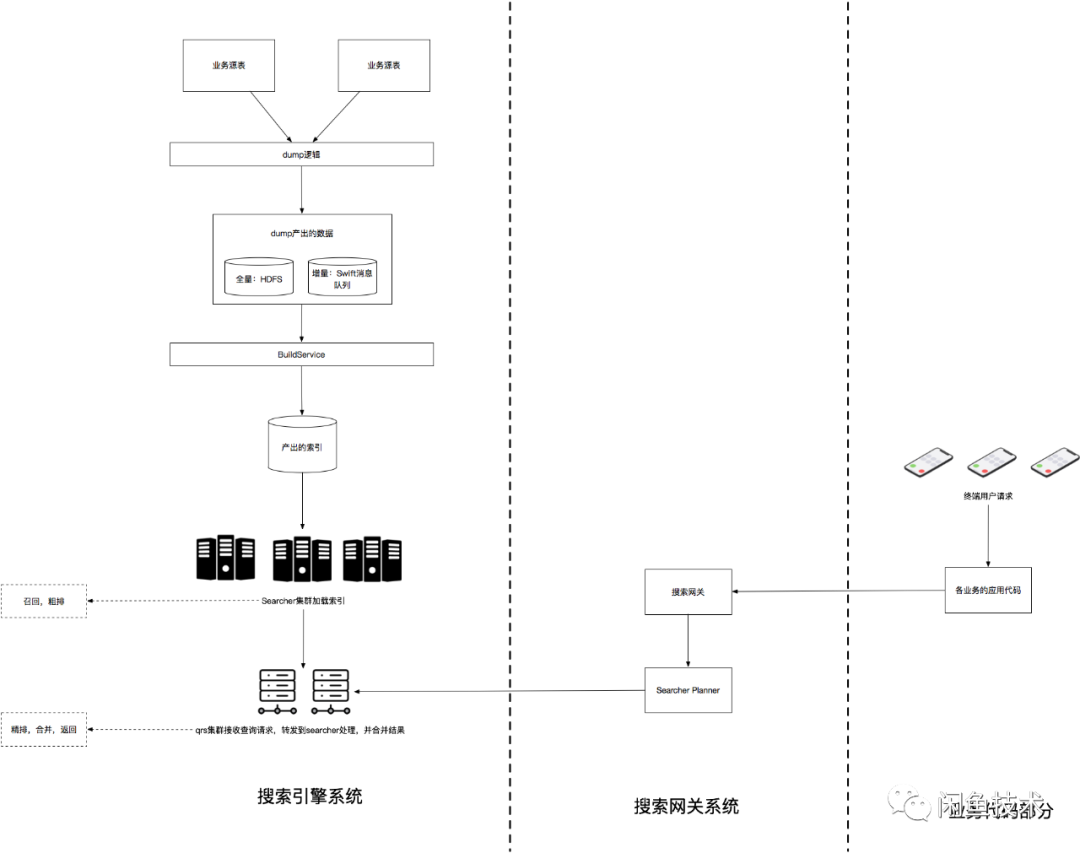
为每个业务场景从头搭建一套搜索系统是有一定复杂度的,而且需要花费较多时间。我们希望提供一套通用搜索系统,当新的业务数据接入搜索能力时,不需要业务开发同学精通搜索系统原理,只要在我们的系统中注册哪些数据需要被搜索,就可以完成搜索能力的自主接入,几乎无需开发,真正实现十分钟快速接入搜索。 多个业务的数据共存在一套搜索引擎服务中,各业务数据相互隔离互不影响。
这里涉及到两个问题:
1. 如何把异构数据从不同的业务db写入同一个引擎构建索引,且写入过程完全自动化、透明化,无需业务接入方参与开发;
2. 如何实现不同业务场景的开发同学在使用搜索召回的过程中不感知到其他业务数据的存在,就像在使用一套为他的业务单独搭建的引擎服务一样方便。
我们的解法
针对上面遇到的2个问题,我们的解决思路是提前构建一套通用搜索系统,把dump、bs、search、Search Planner、网关层的基本能力都提前实现,业务在调用服务时通过设定可选的入参来选择自己需要的能力(比如关键词改写、类目预测、pvlog打印、分层召回等)。通过一个中间层把dump流程自动化,并对dump、search过程进行字段翻译、结果包装。
搜索引擎基本服务的搭建过程与常规方式无大的差异,这里不详细描述。接下来我详细介绍一下此方案实施过程中拆分出的4个技术要点:①通用搜索预留表;②元数据注册中心; ③两层dump;④在线查询服务。
通用搜索预留表
常规情况下,我们会把dump产出的大宽表字段命名为itemId、title、price、userId等具有明确语义的字段名。但是如果要实现多场景共用一套引擎就不能这么做了,因为并不是所有场景数据都有itemId、title、price字段,也可能某个场景中需要接入color字段但是我们的引擎中没有定义这个字段,导致无法支持这个业务场景。 既然问题的关键是字段定义有语义,那么我们解决这个问题的思路就是让已引擎中的所有字段都完全无语义,只有类型信息。我们按照下图的方式预定义2个维度,每个维度下各2张Mysql表和2张ODPS表(这种定义已经可以覆盖绝大多数场景了),称为通用搜索预留表
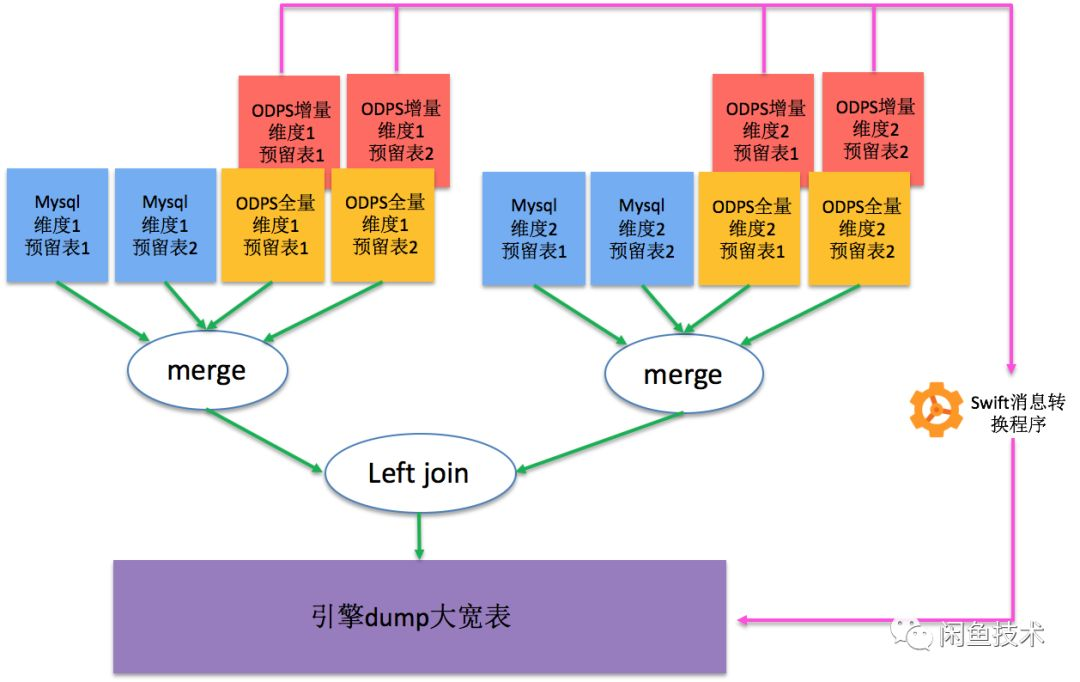
为每张预留表预留各种类型的字段,按照所处维度、表在维度内位置、字段类型进行字段命名:
1. 将第一个维度中第一张预留表表的字段命名为dimapk、dimaaintr1、dima atextmultilevelr1、dimadimbjoinkey等;
2. 将第一个维度中第二张预留表表命名为dimabinnermergekey、dimab intr1、dimabintr2、dimablongr1等;
3. 将第二个维度中第一张预留表表字段命名为dimbpk、dimbaintr1等;
4. 将第二个维度中第二张预留表表命名为dimbbinnermergekey、dimbb intr1、dimbblong_r1等;
然后将预留表按照上图的结构,与引擎原生的dump系统进行对接,并配置索引构建信息。当这套引擎服务搭建完成后,如果直接往通用搜索预留表中接入几条数据,就已经可以从引擎在线查询接口中查到数据了。不过这套搜索系统对业务开发同学来说是不可用的,因为业务源表结果与我们的预留表结构完全不同,业务同学很难把数据从源表按照我们预定义的格式全部迁移到通用搜索预留表,且查询时用“dimaatext multilevelr1='iPhone6S'”这种无语义的方式做查询也是业务同学无法接受的。接下来我们就来解决这些问题。
元数据注册中心
我们设计了一个元数据注册中心,当一个新业务需要接入搜索能力时,只需要在注册中心填写业务相关注册信息(包括业务场景标签,需要接入搜索能力的数据库、表名、字段等基本信息),系统会分配一个业务唯一识别码,这个识别码会作为dump、bs、查询流程中实现多业务隔离的最重要标识。
元数据注册表结构:
元数据注册中心以WEB界面形式提供新业务注册的能力,用户在填写业务的库名,会通过中间件自动拉取到包含的所有表名。用户从中选择自己需要接入的表名,界面上列出此表下的全部字段,以及系统预设的全部通用搜索预留表字段。用户在源表字段与预留表字段之间用鼠标建立连线,完成后点击提交,系统将对用户建立的映射关系进行各项合法性检查,检查通过后按照上面的元数据注册表结构写入DB。 这份注册数据以后将在dump、查询等多个环节用到。
两层dump
每一张业务源表的语义一般比较单一,多张表组合在一起才能够形成一个业务场景的全貌。比如:
1. 商品基本信息表中会存储商品id、标题、描述、图片、卖家id等信息;
2. 商品扩展信息表中会以商品id为主键,存储商品扩展信息,如sku信息、扩展标签信息等;
3. 卖家基本信息表中会以用户id为主键,存储用户的昵称、头像等基本信息;
4. 卖家信用信息表中会以用户id为主键,存储用户的芝麻信用等级。
在一次典型的搜索请求场景中,用户以“iPhone6S”进行搜索,在搜索结果中用户除了希望看到商品基本信息如标题、描述、图片等,还希望看到存储在扩展表中的sku、扩展标签等扩展信息,以及卖家的昵称、头像、信用等级等用户维度信息。如何实现在一次召回过程把分散存储在多张表中的与同一个商品相关的信息都返回呢? 这就需要在dump过程中把多表数据按照一定的方式组织起来,拼装成最终希望的宽表格式,再写入持久化存储供引擎构建索引。
我们在dump过程中,把与此业务场景相关的多张表按照主键做merge和join。同一维度内的多张表按照主键拼成大宽表的过程成为merge,比如1和2之间就是按照商品id做merge,结果记为M1;3和4之间就是按照用户id做merge,结果记为M2。 结果M1中有一列数据是卖家的用户id,而M2的主键就是用户id,将M1和M2根据用户id做join,就得到了最终的大宽表,宽表中的任何一条数据都包含了1234中的完整场景信息。
在通用搜索预留表构建过程中,我们已经按照dimapk+imabinnermergekey和dimb pk+dimbbinnermergekey的方式做维度内merge,按照dimapk+dimbpk的方式做维度间join的方式完成了预留表与BuilderService的对接。 只要业务同学把源表数据正确迁移到预留表中,就可以实现上面描述的复杂dump流程。数据迁移既要保证源表的全部数据被迁移,也要保证线上实时增量数据被迁移,而且迁移过程中需要根据元数据注册中心的字段映射信息进行转换,这个流程还是比较复杂的,如何自动化实现这部分工作呢?
我们的实现方式是基于阿里巴巴内部的中间件平台“精卫”做二次开发,编写自主消费tar包上传到精卫平台运行,根据各业务的注册信息完成适用于各业务的迁移任务,这部分工作由我们在开发通用搜索系统时完成,对各业务接入同学完全透明。精卫平台支持全量迁移任务和增量迁移任务,简单的理解全量迁移任务就是循环对源表执行“select * from tablexxx where id>m and id
在线查询服务
既然dump产出数据的字段是无语义的,那么相应的BuildService构建处端索引数据各字段也是无语义的。
这里看起来通过无语义的定义方式支持了将多场景异构数据写入同一个引擎服务,但是对业务开发同学来说太不友好了。他们在业务开发中调用搜索服务时,期望的方式是自然的业务语义调用,如下面的代码片段:
param.setTitle("iPhone6S");
param.setSellerId(1234567L);
result = searchService.doSearch(param);
但是现在字段没了语义,他们开发的复杂度大大提升,甚至时间一长会陷入难以维护的境地,因为业务代码写完1个月后没人会再记得代码中的“param.setDimaALongR1(1234567L)”是什么意思,这是按照用户id还是商品id查询?虽然底层我们是将多个业务的数据放在一个引擎服务中,但是我们希望提供给业务开发同学(也就是我们这套系统的用户)的在线查询服务与独立搭建一套引擎的体验是一样的。 所以,这里就需要有一个翻译层,通用搜索系统接收到的查询请求是“title=iPhone6S”,我们需要根据元数据注册中心的映射关系自动翻译成“dimaatextmultilevelr1=iPhone6S”后再向引擎发起搜索请求,并把引擎返回的数据DO中无语义字段翻译成源表的有语义字段。
 可以看到,通过我们提供的搜索网关二方包,业务同学可以按照有语义的方式设置查询条件“param.setTitle("iPhone6S")”,同时自动化把引擎返回的无语义字段进行包装成为有语义的字段。业务同学完全觉察不到中间的转换过程,对他来说就像在使用一个为他单独搭建的搜索引擎服务一样。每个业务接入方的源表字段定义都不同,只写一套搜索网关代码肯定无法实现上面的能力。
可以看到,通过我们提供的搜索网关二方包,业务同学可以按照有语义的方式设置查询条件“param.setTitle("iPhone6S")”,同时自动化把引擎返回的无语义字段进行包装成为有语义的字段。业务同学完全觉察不到中间的转换过程,对他来说就像在使用一个为他单独搭建的搜索引擎服务一样。每个业务接入方的源表字段定义都不同,只写一套搜索网关代码肯定无法实现上面的能力。
我们的方案是,当用户在元数据注册中心曾经接入一个新业务后,后台自动化生成生成为业务定制的二方包代码,其中包含了查询入参、返回DO、查询服务接口。还是以poi数据接入为例,poi业务域的开发同学在元数据注册中心说明了他需要按照poiname做文本模糊匹配,需要根据poicode做包含查询、不包含的精确查询。根据此登记信息,我们为用户自动生成poi业务场景专用的查询服务入参,每个入参都是一定的规则拼接而成,网关在线服务拿到此参数后可以根据命名规则翻译成具体的查询串。参数命名规则如下图
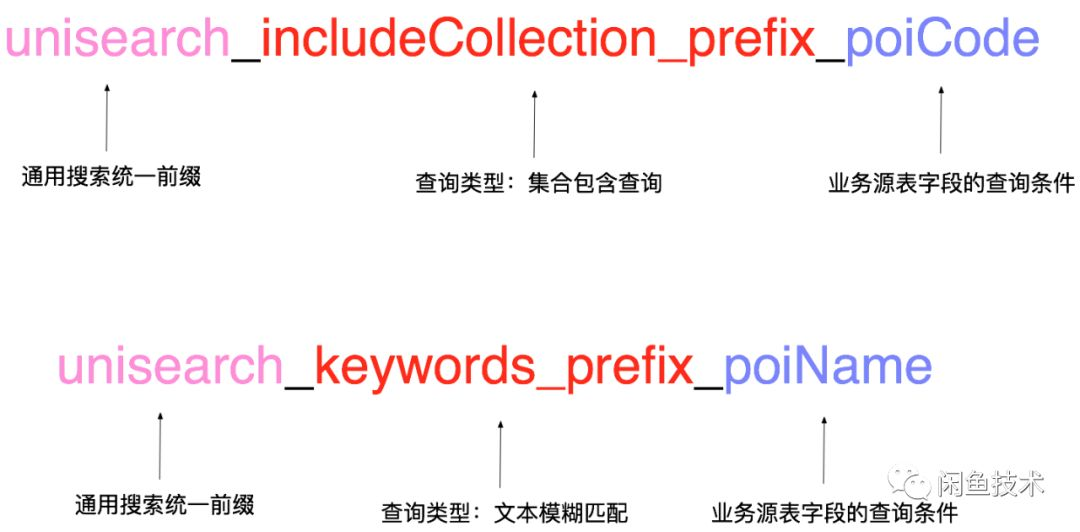
入参Demo代码如下:
public class UnisearchBiz1001SearchParam extends IdleUnisearchBaseSearchParams {
private Set<Long> unisearch_includeCollection_prefix_poiCode;
private Set<Long> unisearch_excludeCollection_prefix_poiCode;
private String unisearch_keywords_poiName;
}
用户通过在线查询服务把此查询条件传入时,查询服务检测到入参是IdleUnisearchBaseSearchParams的之类,会根据命名规则使用反射机制判定unisearchincludeCollectionprefixpoiCode是需要对业务源表的poiCode字段做include(包含)查询,然后从元数据注册中心的映射关系数据取出poiCode对应的预留表字段名为dimaalongr1,构造Search Planner查询串,执行后续查询动作。 当引擎返回查询结果后,网关查询服务再次根据元数据注册信息,利用反射对引擎结果DO进行翻译转换,包装成下面所示的poi业务专用DO后返回给业务开发同学。
public class UnisearchBiz1001SearchResultDo extends IdleUnisearchBaseSearchResultDo {
private Long poiId;
private Long poiCode;
private String poiName;
}
通用搜索预留表一共有8张,全部字段加起来是比较多的。如果把字段全部召回,实际上大部分字段都是业务没有进行注册的空字段,返回数据会比实际需要的数据大小膨胀几十倍,网络传输开销、大量空字段反序列化开销、DO字段转换开销会导致在线查询服务的RT很高。 解决此问题比较简单,我们把整个在线召回流程定义为两个阶段,第一个阶段只根据用户的查询条件在引擎中召回符合要求的数据主键rawpk;第二阶段根据此rawpk列表去获取对应数据的summary(即所有字段的信息)时,利用引擎支持的dl语法,要求二阶段仅返回用户注册过的预留字段即可。 当然,这些工作也由我们在通用搜索系统的网关代码中提前实现了,对各业务接入同学透明。
增量问题的特殊解法
到现在为止一切看起来都很完美,貌似我们已经用这套系统完美解决了数据导入、转换、bs、查询等一系列工作的自动化包装,业务同学需要做的仅仅是来我们的业务注册中心界面上登记一下而已。
不过实际上在表面之下还隐藏着一个较严峻的问题,就是大增量的问题。由于与BuildeService直接对接的是结构已经固定的通用搜索预留表,也就意味着原生的dump层数据源结构是不可能变化的,唯一能变化的是从业务源表经过精卫系统写入通用搜索预留表的数据。 当上游有一个新业务接入进来时,如果它的源表数据量达到了十亿级别,按照目前精卫能够达到的迁移速度,也就意味着通用搜索预留表的更新TPS能够达到5万的级别,而这每秒5万条数据更新的压力就会直接打在实时BS系统上,即引擎需要每秒更新5万条doc数据才能保证搜索结果与源表数据的一致性。而搜索引擎的实时BS能力依赖于实时内存的容量,这么大的增量TPS会在短时间内打满实时内存,导致源表后续的更新数据无法实时被BS构建成索引,那么搜索系统就无法搜索到最新的业务数据(包括新增、更新、删除的数据),称为增量延迟问题。
多个业务共享这套引擎服务,线上已经在提供搜索服务的业务无法接受增量延迟;而对本次新接入的业务来说,在第一次接入时把数据往通用预留表同步的这段时间内,数据搜索不到是完全可以接受的。
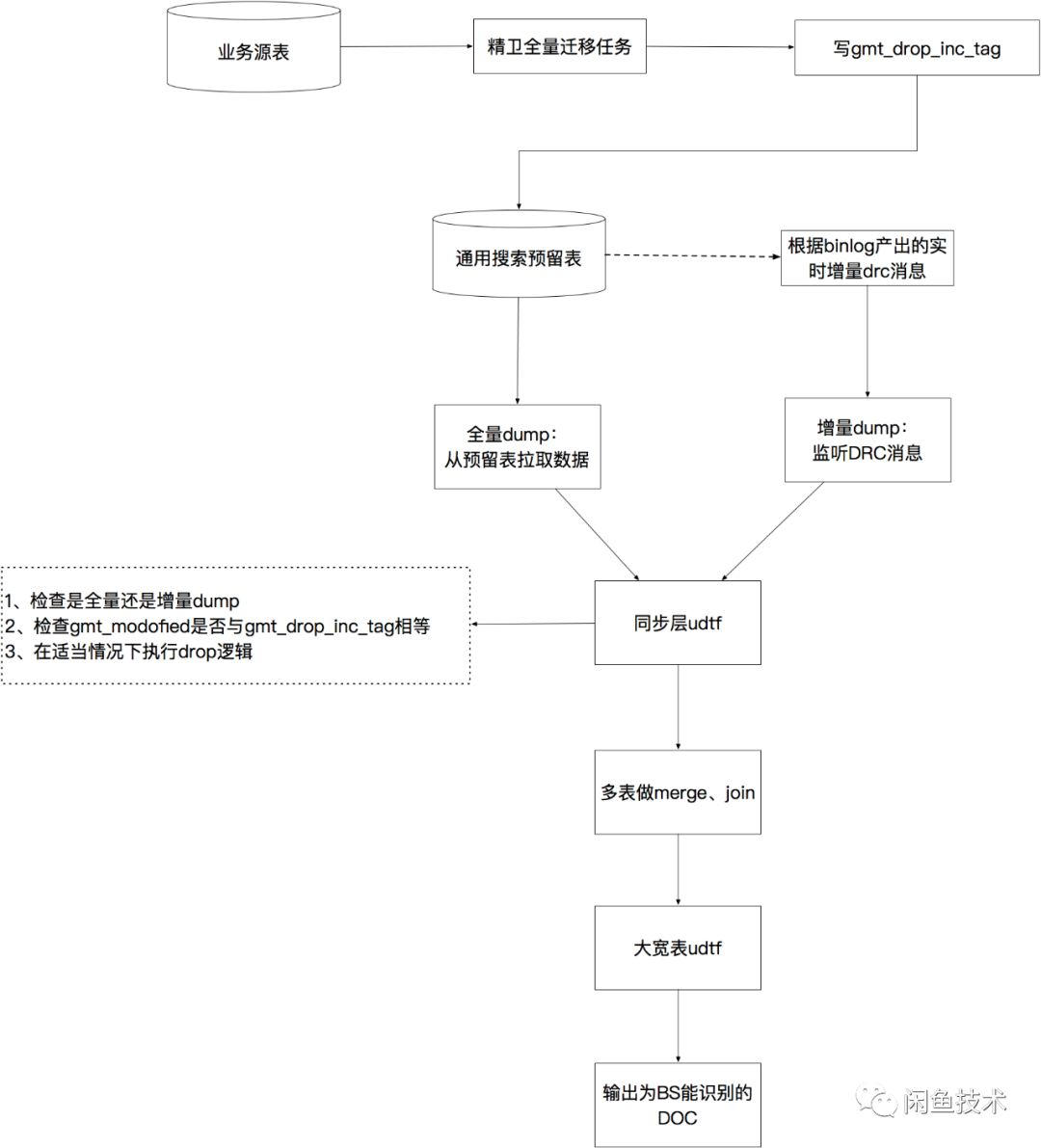
因此,我们想出一个办法实现了线上存量业务的增量数据正常实时进引擎,而新业务的全量迁移数据引发的增量不实时进引擎。具体实现分为以下几个步骤:
1. 通用搜索预留表按照db表的创建规范,都会有一个gmtmodofied字段,类型为datetime。当预留表中的数据发生任何变化(增、删、改)时,gmtmodofied字段都会更新为本次操作的时间戳。 这个逻辑在精卫迁移任务的DAO层实现。
2. 为通用搜索预留表的每一张表额外增加一个datetime类型字段,命名为gmtdropinctag。精卫全量任务为新业务导数据时,我们在精卫任务启动参数中带上“dropinctag=true”的标识,相应地我们在精卫自主消费代码中识别到这个标识后,会在完成数据转换生成的DAO层入参DO中把gmtdropinctag字段赋值为gmtmodofied一样的值,然后写入DB。 而非新业务全量和增量精卫任务的启动参数中无“dropinctag=true”的标识,则其他业务的增量精卫任务写入DB的记录中只会更新gmtmodofied而不会更新gmtdropinctag字段。
3. 在引擎原生dump层,我们在每一张通用搜索预留表与后续merge节点之间增加一层udtf逻辑代码。这里的udtf代码是dump层对外开放的一个口子,允许引擎接入方在dump流程上对数据做一些特殊处理,每一条上游的数据都会经过udtf的逻辑处理后再输出到下游进行merge、join、输出给BS系统。 我们在这里实现的逻辑是,如果识别到当前是全量dump流程,则把当前流入数据的gmtdropinctag置为空,然后向下游输出;若识别到当前是增量dump流程,则检查当前流入的数据其gmtmodofied字段与gmtdropinctag字段是否相同,若两字段相同则对此数据执行drop逻辑,若两字段不同则把当前流入数据的gmtdropinc_tag置为空后向下游输出。 所有被执行了drop逻辑的数据都会被dump系统丢弃,不会输出到最终产出的数据文件中。
如此一来,老业务的增量数据都任然正常经过dump流程后通过BS(BuildServcie)系统实时反映到搜索在线服务中。而本次新接入业务的全量迁移数据都只是从业务源表迁移到了搜索预留表中,BS系统完全感知不到这批数据的存在。 待新业务的数据已经全部从源表迁移到预留表之后,我们对引擎服务触发一次大全量流程,即先以全量dump的方式把通用搜索预留表的数据全部重新走一次dump逻辑,产出完整的HDFS数据,然后离线BS系统批量对此HDFS数据构建索引,然后加载到searcher机器提供在线服务。随后,对新业务开启精卫增量迁移任务,保证业务源表的变更实时反映到引擎中。
效果
闲鱼这套通用搜索系统目前已经在线上为3个业务提供服务,每个新业务都能在10~30分钟内完成接入。而在有此系统之前,一个业务方如果想接入搜索能力,需要向团队中精通搜索底层原理的搜索业务owner提开发需求,等待一周左右开发排期,待搜索owner完成一套引擎服务搭建后,业务同学后才能进入业务开发阶段。 我们用此系统消除了搜索owner的单点阻塞问题,实现了用自动化技术解放生产力。
展望
闲鱼还将继续在自动化提效方面进行更多探索,把开发同学从繁重的重复性工作中解放出来,将时间投入到更具有创造性意义的工作中。闲鱼今年有更多有深度有挑战的项目在进行中,期待您的加入,与我们共同创造奇迹。
闲鱼团队是Flutter+Dart FaaS前后端一体化新技术的行业领军者,就是现在! 客户端/服务端java/架构/前端/质量工程师 通通期待你的加入,base杭州阿里巴巴西溪园区,一起做有创想空间的社区产品、做深度顶级的开源项目,一起拓展技术边界成就极致!
*投喂简历给小闲鱼→guicai.gxy@alibaba-inc.com


更多系列文章、开源项目、关键洞察、深度解读
请认准 闲鱼技术
