

今天给大家推荐一个数据分析与挖掘的实战项目案例“基于京东手机销售数据用回归决策树预测价格”。该项目先基于京东手机销售数据做出一系列分析后,利用回归决策树仅根据手机外部特征进行价格预测。
本项目来自于实验楼《楼+ 数据分析与挖掘实战》第五期学员:Ted_Wei。
数据获取
由于手机的价格以及评论数是需要经过 javascript 渲染的动态信息,单纯用 requests 模块是爬取不到的。我的解决方案是首先使用 selenium 的 webbrowser 模块使用本地 Chrome 浏览器爬取每一款手机在京东的内部id,价格,以及评论数。然后再根据爬取到的id找到每款手机的销售页面,爬取每款手机的关键参数。
爬虫代码parsing_code.py可通过此页面: www.kaggle.com/ted0001/dm0… 获取。
数据清洗
获取到的数据包含1199行,21列,每一行代表一款正在销售的手机,每一列包含关于手机的一项参数(比如价格,内存大小,像素,等等)。 获取到的数据大多为自然语言,非数值信息,对于分析十分不友好。所以数据分析的重点在于,找到实际上的缺失信息(如‘无’,‘参考官方数据’等都可认为是缺失数据NaN),以使用re模块解析自然语言,提取其中有用的数值信息。
数据清洗的步骤其实相当繁琐,如果把代码贴出也会占用过多篇幅,因此数据清洗的代码data_clean.py可通过此页面: www.kaggle.com/ted0001/dm0… 获取。
数据分析
下面直接进入正题,主要完成估计各品牌手机销量并进行比较分析、对决定手机价格因素的探索、尝试用机器学习方法预测手机价格。
首先调用所需的模块
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_absolute_error as mae读取已经清洗好的数据,数据也可在 www.kaggle.com/ted0001/dm0… 获取。
data=pd.read_csv('../input/data-acquisitioncleaning/cleaned_data.csv')
data=data.set_index(['Unnamed: 0']) #DataFrame在存储为csv file以后原来的index会变为一个列,因此要重新设置index
data.shape输出结果:
(1199,21)估计各品牌手机销量并进行比较分析
拿到清洗好的数据后的第一个想法,便是对各个品牌的手机的销量进行一个比较。由于京东只显示了每部手机的评论数量而不是具体销量,我们只好默认评论数量comments和销量成正比,从而估计各个手机品牌的销量占比
pie_plt=data.groupby(['brand']).sum()['comments'].sort_values(ascending=False)#统计每个品牌评论总数,以此作为我们对销量的估计
pie_plt输出结果:
brand
HUAWEI 11320592.0
Apple 9797100.0
XIAOMI 7995236.0
NOKIA 1324000.0
Philips 1227100.0
OPPO 1205300.0
vivo 1101330.0
K-Touch 793300.0
MEIZU 574900.0
SAMSUNG 539800.0
smartisan 364000.0
lenovo 275500.0
realme 157000.0
Meitu 109200.0
nubia 86000.0
chilli 58000.0
360 31000.0
ZTE 17000.0
Coolpad 12000.0
BlackBerry 10000.0
WE 90.0
Name: comments, dtype: float64我们可以对以上数据用扇形图更好地展现出来
#绘制各个手机品牌估计销量的占比扇形图
fig,axes=plt.subplots(figsize=(12,12))
comment_sum=pie_plt.values.sum()
percen=[np.round(each/comment_sum*100,2) for each in pie_plt.values]
axes.pie(pie_plt.values,labels=pie_plt.index,labeldistance=1.2,autopct = '%3.1f%%')
axes.legend([pie_plt.index[i]+': '+str(percen[i])+"%" for i in range(len(percen))],loc='upper right',bbox_to_anchor=(1, 0, 1, 1))
axes.set_title('Estimated Handphone Market Share in China')
plt.show()输出结果:
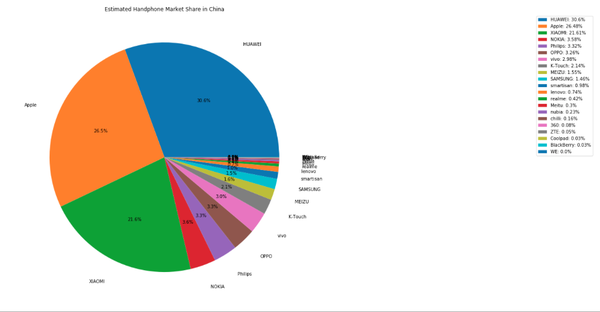
从以上扇形图我们可以估计,在中国市场销量前三的手机品牌分别是华为,苹果,小米,分别占到了总销量的30.6%,26.5%,21.6%,剩下的品牌销量则远远不及销量前三的品牌。 为了验证以上估计的正确性,我查阅了2019年中国手机市场各个品牌份额的相关资料。发现华为,苹果,小米的占比分别为34%,9%,12%,除华为外,小米和苹果的市场份额数据均有较大出入。而vivo,oppo的市场份额则分别是19%和18%,与原来的数据差距就更大了。 如果京东的评论数量可以大致反映手机线上销售情况的话,我想造成数据有如此大差异的原因可能在于没有考虑中国市场的线下销售。根据平时的生活经验,苹果和小米的线下门店数量(特别是在小城市)是远远不及oppo,vivo的门店数量的。整个手机市场既包括线上市场也包括线下市场,而造成我统计到的数据与权威数据差异的原因,很可能是因为我的数据没有包含线下销售。 如果能够获得线下销售数据,那么也可以对以上推论进行进一步的验证。
还有一点出乎我意料的是,诺基亚和飞利浦手机的估计销量占比竟然也都超过了3%(甚至超过vivo,oppo),于是便想看看这两个品牌分别销售哪种价位手机
data[(data['brand']=='NOKIA')|(data['brand']=='Philips')]['price'].median()#诺基亚和飞利浦手机价格中位数输出结果:
208.5
data[(data['brand']=='NOKIA')|(data['brand']=='Philips')]['price'].mean()#诺基亚和飞利浦手机价格平均数输出结果:
336.1190476190476这样看来,诺基亚和飞利浦的手机价格多在200-300元左右,再根据item id访问京东网站后,发现果不其然,这两个品牌所销售的大多是功能机。(诺基亚有部分智能手机) 在这个智能手机已经全面普及的年代,想不到功能机也还是有它的一亩三分地,并没有完全被市场淘汰(尤其是线上销售渠道)。这可能是因为部分老人仍然更习惯使用功能机,以及功能机待机时间长,铃声音量大,能满足部分人群的特殊需求。
对决定手机价格因素的探索
另一个值得研究的问题便是手机的价格和手机配置参数的关系。为了让我们有一个整体把握,我们会先画出各个数值数据间的correlation matrix,然后再探索非数值数据(categorical data),如品牌,屏幕材料,对价格的影响。
画出Correlation Matrix 并进行分析
由于苹果手机和安卓手机的价格、配置差异较大,而且苹果手机配置参数在我们的数据集中大多缺失,我们研究这个问题时,就暂且只考虑安卓手机。(价格为9999的手机是华为将于2019年7月发行的荣耀X9,由于该型号价格异常,故也将其从我们的分析中排除。)
correlation=data[(data['brand']!='Apple')&(data['price']!=9999)].corr()
#绘制相应correlation matrix的heatmap
fig,axes=plt.subplots(figsize=(8,8))
cax=sns.heatmap(correlation,vmin=-0.25, vmax=1,square=True,annot=True)
axes.set_xticklabels(['RAM', 'ROM', 'battery', 'comments', 'price', 'rear camera',
'resolution', 'screen size', 'weight'])
axes.set_yticklabels(['RAM', 'ROM', 'battery', 'comments', 'price', 'rear camera',
'resolution', 'screen size', 'weight'])
axes.set_title('Heatmap of Correlation Matrix of numerical data')
plt.show()输出结果:
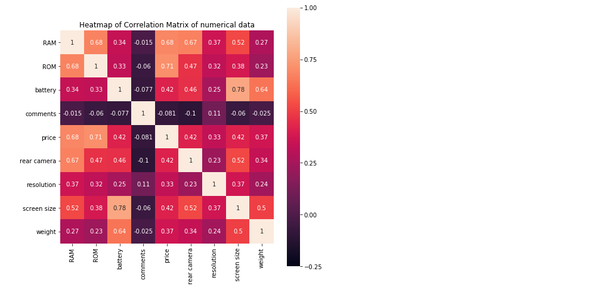
从上图我们可以看出,价格 price 和存储空间 ROM 以及内存 RAM 的关联度最大,分别达到了0.71和0.68。其次便是电池容量battery,后置摄像头个数rear camera,屏幕大小screen size,关联度都分别达到了0.42。这也比较符合我们常识性的判断。 我们还可以很明显的看到,评价个数comments的column和row都呈现深紫色,代表comments和各个数值参数的关联都很小。 (由于我们的数据集缺失值较多,在舍弃掉部分缺失值的行后,以上correlation matrix的数值会出现一定程度的变化)
手机品牌对手机价格影响的探索
当然,决定手机价格很关键的因素还有一些非数值数据(categorical data)。最容易想到的便是手机的品牌了。
data.groupby(['brand']).median()['price'].sort_values(ascending=False).values.std() #计算不同品牌价格中位数集合的标准差输出结果:
1409.0576123336064以上数据也可以通过柱状图来更直观地展示。
bar_plt=data.groupby(['brand']).median()['price']
fig,axes=plt.subplots(figsize=(20,8))
axes.bar(bar_plt.index,bar_plt.values)
axes.set_title('Median price of handphones of various brands')输出结果:
Text(0.5, 1.0, 'Median price of handphones of various brands')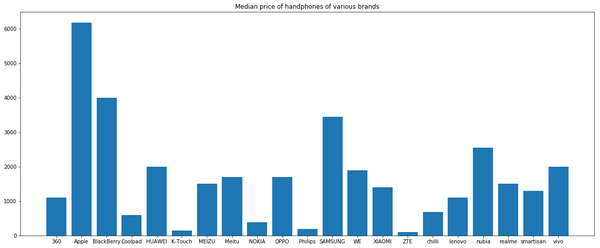
我们可以看到,各个品牌手机中位数价格层次不齐,这也和我们的常识性判断吻合,因为不同手机品牌的定位以及消费群体均有较大差异。
不同屏幕材料对手机价格影响的探索
还有一个很关键的因素其实是手机的屏幕材料,我们也可以用同样的方法比较不同屏幕材料对价格的影响。
data.groupby(['screen material']).median()['price'].sort_values(ascending=False).values.std() #计算不同屏幕材料价格中位数集合的标准差输出结果:
1523.0026019740856各种屏幕材料的手机的价格中位数展示如下
data.groupby(['screen material']).median()['price'].sort_values(ascending=False)输出结果:
screen material
Dynamic AMOLED 5999.0
OLED曲面屏 5488.0
OLED 4288.0
Super AMOLED 2998.0
AMOLED曲面屏 2908.0
LCD 2399.0
AMOLED 2299.0
TFT LCD(IPS) 1999.0
LTPS 1999.0
IPS 1399.0
TFT 1199.0
Name: price, dtype: float64用柱状图展示如下:
bar_plt2=data.groupby(['screen material']).median()['price']
fig,axes=plt.subplots(figsize=(18,8))
axes.bar(bar_plt2.index,bar_plt2.values)
axes.set_title('Median price of handphones of various screen materials')输出结果:
Text(0.5, 1.0, 'Median price of handphones of various screen materials')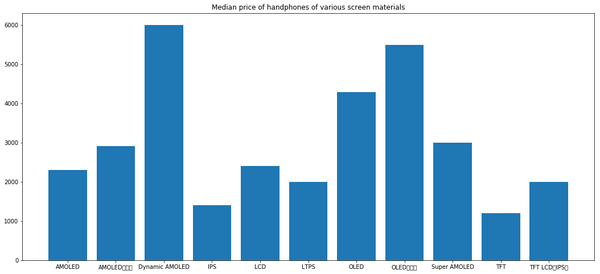
可以注意到的是,以上价格数值均在千元以上,而我们的数据集中还包含有价格很低廉的功能机,那它们的屏幕又都是什么材料呢?
data[(data['brand']=='NOKIA')|(data['brand']=='Philips')]['screen material'].value_counts()输出结果:
TFT 27
IPS 3
TFT LCD(IPS) 1
Name: screen material, dtype: int64可以看到,诺基亚和飞利浦的手机(大多为功能机)的屏幕材料大多为TFT和IPS。
我们又可以反过来看看又到底是哪些价位的手机在使用TFT和IPS呢?
#绘制屏幕材料为IPS或TFT手机的价格分布图
hist_plot=data[(data['screen material']=='IPS')|(data['screen material']=='TFT')]['price']#查看所有屏幕材料为IPS或TFT手机的价格
sns.distplot(hist_plot)
plt.title('Price Distribution Plot of Handphones Whose Screen Material is TFT or IPS ')输出结果:
Text(0.5, 1.0, 'Price Distribution Plot of Handphones Whose Screen Material is TFT or IPS ')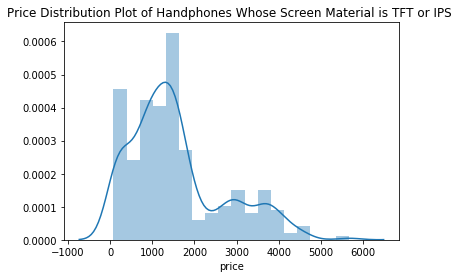
通过观察以上分布图以及进一步在数据集data中查看屏幕材料为TFT或IPS的手机发现,IPS主要用于华为的中低端手机,价格在千元以下,或者1300元左右。其中,价格在200元以下的功能机的屏幕材料均为TFT。 出乎我意料的是,也有部分高端手机使用的是IPS或TFT材料,比如华为的荣耀V20,苹果的iphone 8,使用的是IPS材料;华为mate20和华为p20使用的均为TFT材料,这些手机的价格都在3500元以上。 通过以上的探索分析我们可以知道,高端智能机和低端功能机所使用的屏幕材料也很可能是一样的。当然我们也不排除,同样是TFT或IPS材料,它们内部也可能有区别。
尝试用机器学习方法预测手机价格
在前面的小节中,我们探索了决定手机价格的几大因素,手机存储空间ROM,内存RAM,以及品牌,屏幕材料等都是决定手机价格的关键因素。 在这一小节中,我会使用回归决策树(Regression Decision Tree)的算法仅仅根据手机的外部特征来预测手机的价格。决策数的特征值仅仅采用了手机的品牌brand、后置摄像头数量rear camera、以及手机重量weight作为我们的特征(feature),目标(target)当然则是我们的价格price 这样做的原因一来是因为ROM和RAM存在太多的缺失值。如果选取这两个值做为特征,那么我们会丢失掉太多训练数据。 二来是想尝试在不知道手机具体配置,仅仅通过观察测量手机外部特征能否较为准确地预测手机价格。 以下数据显示,如果选用ROM、RAM、和brand作为特征,那么我们只能得到原数据集31%左右的数据用作训练和测试。
data.dropna(subset=['ROM','RAM','brand','price']).shape[0]/data.shape[0]输出结果:
0.30692243536280234所有列缺失值数据统计:
data.isnull().sum().sort_values(ascending=False)输出结果:
CPU freq 998
CPU cores 824
front camera 773
RAM 720
rear camera specs 710
ROM 667
CPU model 479
screen material 381
brand 347
rear camera 249
battery 177
resolution 134
month 115
charging port 99
screen size 85
model 70
weight 66
SIM cards 56
year 6
price 3
comments 0
dtype: int64品牌brand对价格影响非常明显,所以虽然缺失值较多,我们也必须考虑这个特征。
考虑到品牌brand是非数值数据,我们选取使用回归决策树算法来进行机器学习建模。
从原来的数据集提取我们需要的数据
df=data.loc[:,['price','rear camera','brand','weight']].dropna()由于回归决策树只接受数值型数据(numerical data),我们需要对brand进行独热编码(one-hot encoding)
to_model=pd.get_dummies(df)#对非数值型数据进行独热编码提取特征值和目标值。 (考虑到各种手机品牌的型号数量毕竟很有限,而且部分品牌数据量较少,我们在这里就没有划分训练集和测试集了)
x=to_model.iloc[:,1:].values
y=to_model.iloc[:,0].values训练回归决策数模型
model=DecisionTreeRegressor()
model.fit(x,y)输出结果:
DecisionTreeRegressor(criterion='mse', max_depth=None, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')检验我们的模型对各个品牌的预测准确性。
error_list=[]
for each in df['brand'].value_counts().index:
to_fill='brand_{}'.format(each)
x_data=to_model[to_model[to_fill]==1].iloc[:,1:].values
y_data=to_model[to_model[to_fill]==1].iloc[:,0].values
test_result=model.predict(x_data)
merror=mae(y_data.reshape(len(y_data),1),test_result.flatten())
error=(np.abs(test_result-y_data)/y_data).mean()
print(each,end=' : ')
print(np.round(merror,2),end=', ')
print(str(np.round(error*100,3))+'%')
error_list.append([each,merror,error])输出结果:
HUAWEI : 238.55, 15.16%
XIAOMI : 202.0, 12.277%
Apple : 663.28, 8.087%
OPPO : 177.65, 9.582%
vivo : 134.78, 8.747%
Philips : 7.01, 2.841%
MEIZU : 51.79, 3.009%
SAMSUNG : 269.2, 3.24%
K-Touch : 7.23, 4.144%
NOKIA : 12.5, 1.321%
lenovo : 33.33, 3.374%
Meitu : 120.0, 6.141%
smartisan : 0.0, 0.0%
realme : 0.0, 0.0%
nubia : 0.0, 0.0%
360 : 0.0, 0.0%
BlackBerry : 0.0, 0.0%
Coolpad : 0.0, 0.0%
ZTE : 0.0, 0.0%
chilli : 0.0, 0.0%
error_df=pd.DataFrame(error_list,columns=['brand','mean_absolute_error','mean_proportional_error'])
error_df输出结果:
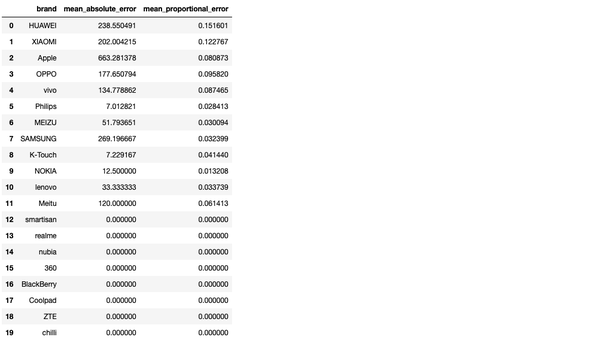
以上的 DataFrame error_df 表示该决策树模型对于每个品牌手机预测的准确性,误差都均在 15% 以内,这个模型还是相对比较准确的。 实际上这个模型最关键的是提取了手机的重量weight这一关键信息,因为每个型号的手机重量多少是有些区别的,拿一个稍微精确一点的电子秤便能量出区别,决策数只不过是记住了数据而已。造成预测结果误差的原因我想多半还是因为不同的卖家对同一型号手机的标价不同吧。
项目总结
虽然没有详细地呈现数据采集以及数据清理的过程,但是这两个步骤确是所花时间最多的步骤。虽然京东的网页对于爬虫新手已经十分友好,但是头一回爬取 javascript 渲染后的价格、评论数据还是颇有挑战性。数据清理主要难点在于数据大多以自然语言呈现,要找到实际上的缺失值,以及将自然语言转变为数值(比如评论数 comments,后置摄像头数量 rear cameras )。除去写这个 kaggle kernel,这两个步骤大概花了所有时间的70%。 对于采集到的数据进行分析也不是之前想象到的那么容易,为了发掘更深一层次的信息,对于每一次通过 pandas 函数得到的结果都需要认真地分析结果,思考为什么会有这个结果。 总之,这次项目挑战收获还是比较大,也是头一次自己完成数据的采集,清洗,以及分析的全过程。
《楼+之数据分析与挖掘实战》分为三个阶段,6 周课程内容包含 35 个实验,20 个挑战,5 个综合项目,1 个大项目。完成课程可满足无需强专业背景的数据分析或数据挖掘初级工程师职位要求。
一、基础知识技能准备阶段
Python作为代码实战过程中的唯一编程语言,需要你熟悉使用 Python 构建机器学习模型的常用工具模块,包括 NumPy 和 Pandas 。
二、数据挖掘流程学习阶段
围绕着数据挖掘经典流程,学习并掌握数据采集、数据预处理、数据建模以及数据可视化等内容。阶段将涉及大量的数据分析、机器学习、Python 模块、及常用方法的介绍和使用。
- 数据采集与查询:使用 Python 采集数据的相关方法,数据库及 SQL 基础语法知识,以及学习使用 API 或爬虫采集网络数据的相关模块。
- 数据清洁及预处理:将从数据预处理的 4 个大方向出发,熟悉数据清洗、数 据集成、数据转换、数据规约等涉及到的数十项不同的手段和方法。
- 机器学习建模方法:通过现有数据去预测,去挖掘更多有价值的信息。本周内容将涉及常用的机器学习分类、回归、聚类算法和原理,并对关联规则等其他数据挖掘方法进行介绍。
- 时间序列处理:学习时间序列处理中涉及到的基本概念和方法,并掌握使用 Pandas进行时间序列数据处理的方法和手段,同时学习使用 Facebook 开源的时间序列处理工具完成时序数据分析建模。
三、数据挖掘项目实战阶段
依托于数据挖掘流程,对不同领域的数个数据挖掘实战项目进行综合学习运行。于此同时,你将会了解到数据挖掘过程中相关的理论和方法,例如数据分析报告撰写、BI 工具使用等。 最终,课程将通过独立完成数据挖掘项目的方式检验学习成果,并将最终的数据挖掘报告提交给我们进行人工评阅。
- 数据挖掘项目实战:将从数据采集、数据预处理、数据建模、数据可视化方面进行完整运用,这将为独立承担数据分析任务打下基础。
- 数据挖掘项目作业:提供数个可供选择的数据挖掘题目,你将利用 1 周的时间来独立完成并将最终的数据挖掘报告提交给我们进行人工评阅。
报名方式:请戳我直接报名,或添加助教小姐姐微信(sylmm002)进行咨询/索要优惠。

