


引言
99大促有淘宝、天猫、聚划算等全员参与,上千个页面形式的展现。其中,测试是保障活动页面的正常发布的一个必不可少的关键环节。传统的测试方法,需要测试人员去分析这个页面是否正常生成,以及是否实现正常地跳转等。这样通常会占用大量的测试资源。 那么能否利用机器学习等相关技术为测试赋能呢?
带着这个问题,我们分析了页面的特性。经过分析后发现页面具有高度的相似性,很多模块是复用的。因此,可以利用机器学习去学习模块特征,进而达到识别这些模块的目的。 最终,我们实现了对淘宝99大促几十个活动页模块的自动识别。
处理流程 深度学习技术通常由两部分构成:模型训练和模型预测。 深度学习通常是有监督学习的方式,因此在模型训练环节中,需要输入训练样本,“告知”它输入和输出是什么。此外,我们还需要选择合适的深度学习网络来训练。相关细节会在后续两个小节中详细描述:样本生成:样本生成过程中使用的三种方法
模型选择:fpn + Cascade R-CNN
模块识别:识别页面中模块类别和位置
元素识别:基于模块的识别区域,识别内部元素
位置修正:通过传统图像的方式修正内部元素位置
模型预测
样本制造
样本制造我们演进了三个版本: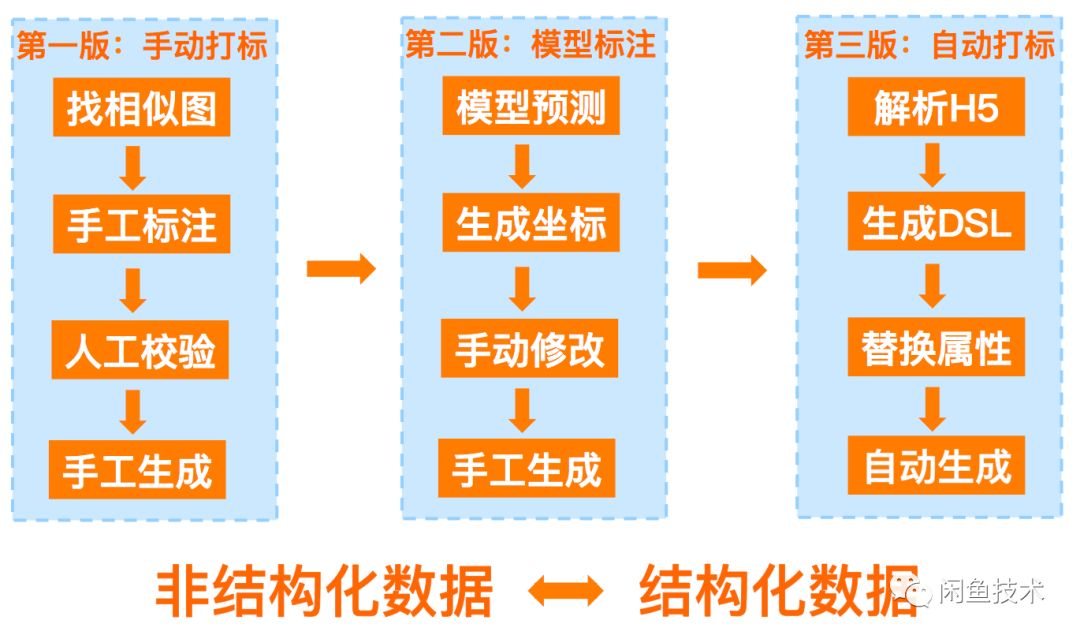 第一个版本是手动打标,基于labelImg等标注工具进行标注。这种打标方式的缺点是需要投入较多的人力资源,且无法满足未上线页面的打标。
第二个版本是模型辅助打标,也就是先训练一个初始可用的模型,然后利用模型预测结果对模型进行初始标注,对不正确的地方作修改,可以不断地迭代优化模型。这种打标方式的缺点是无法满足未上线页面的打标。
第三个版本是自动打标,分析H5页面的代码生成布局DSL,然后通过替换属性的方式自动生成相关代码。这种打标方式的优点是可以解决上述两个版本中“无法满足未上线页面打标”的问题。这种方法也是本文中采用的主要方法。
本文,主要使用了第三种方式去生成训练数据,第一种和第二种更加真实的方式生成验证数据,达到生产环境准确验证的目的。
第一个版本是手动打标,基于labelImg等标注工具进行标注。这种打标方式的缺点是需要投入较多的人力资源,且无法满足未上线页面的打标。
第二个版本是模型辅助打标,也就是先训练一个初始可用的模型,然后利用模型预测结果对模型进行初始标注,对不正确的地方作修改,可以不断地迭代优化模型。这种打标方式的缺点是无法满足未上线页面的打标。
第三个版本是自动打标,分析H5页面的代码生成布局DSL,然后通过替换属性的方式自动生成相关代码。这种打标方式的优点是可以解决上述两个版本中“无法满足未上线页面打标”的问题。这种方法也是本文中采用的主要方法。
本文,主要使用了第三种方式去生成训练数据,第一种和第二种更加真实的方式生成验证数据,达到生产环境准确验证的目的。
模型选择
淘宝99大促活动页需要识别活动页里面有哪些页面模块,且需要知道模块所在的位置。而深度学习的目标检测模型可以在给定的图片中精确找到物体所在位置,并标注出物体的类别。 考虑到对坐标位置和类别有很高的召回率和准确率的要求(IOU0.5:0.95的召回率和准确率都要达到95%以上),本文使用了精度更高的Cascade-RCNN网络。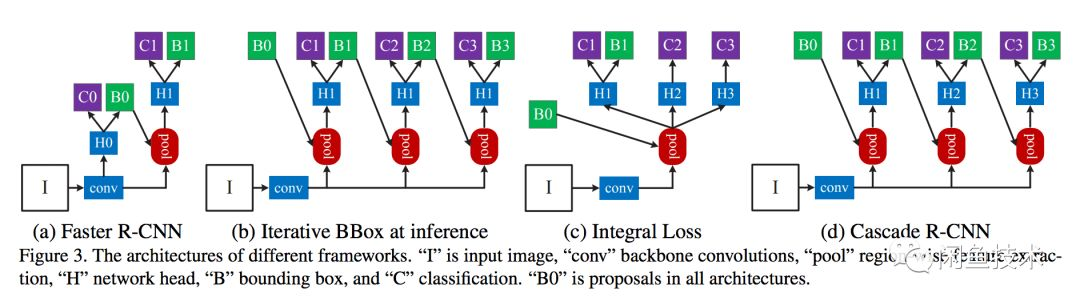 主流的目标检测模型Faster-RCNN的缺点是RPN的proposals大部分质量不高,IOU低阈值会导致很多误检出,而高阈值会导致召回率过低。针对这个问题,Cascade-RCNN使用cascade回归作为一种重采样的机制,逐层提高proposal的IoU值,从而使得前一层重新采样过的proposals能够适应下一层的更高阈值。 这样做的好处是:每个阶段都有不同的IoU阈值,可以更好地去除离群点,适应新的proposal分布。
针对识别模块大小不一这种情况,我们在卷积特征提取网络加入了特征金字塔结构,均衡了不同尺度模块的检出数量(对小模块提升尤为明显),进而提高了召回率和准确率。网络结构如下图所示:
主流的目标检测模型Faster-RCNN的缺点是RPN的proposals大部分质量不高,IOU低阈值会导致很多误检出,而高阈值会导致召回率过低。针对这个问题,Cascade-RCNN使用cascade回归作为一种重采样的机制,逐层提高proposal的IoU值,从而使得前一层重新采样过的proposals能够适应下一层的更高阈值。 这样做的好处是:每个阶段都有不同的IoU阈值,可以更好地去除离群点,适应新的proposal分布。
针对识别模块大小不一这种情况,我们在卷积特征提取网络加入了特征金字塔结构,均衡了不同尺度模块的检出数量(对小模块提升尤为明显),进而提高了召回率和准确率。网络结构如下图所示:
模型识别
模块识别
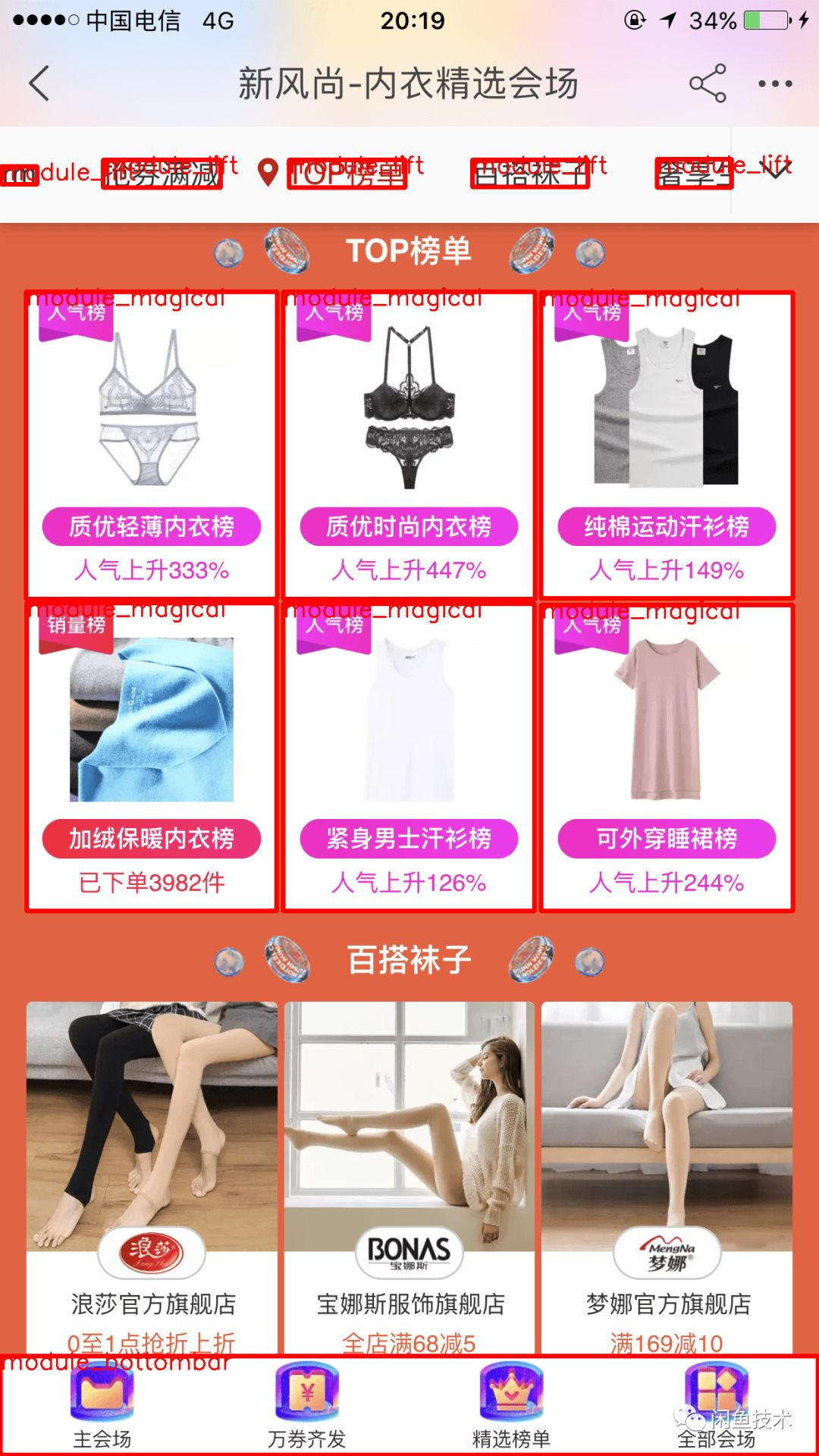
在本期的淘宝99大促中,我们支持了28个模块的识别,类似的模块如下:
 识别的结果如下所示:
识别的结果如下所示:

元素识别
由于页面内容理解部分不止需要识别模块,还需要识别模块内部的元素。如下图所示,我们不仅要识别七巧板模块,也需要识别内部元素的会场导航和商品导航模块。 本文考虑到这两种元素也会在页面中单独出现,采用了Coarse-to-Fine的架构:首先识别七巧板模块,然后通过另一个目标检测网络去识别内部元素。
本文考虑到这两种元素也会在页面中单独出现,采用了Coarse-to-Fine的架构:首先识别七巧板模块,然后通过另一个目标检测网络去识别内部元素。
 识别的最终结果如下图所示:
识别的最终结果如下图所示:
 位置修正
由于目标检测模型本身的局限性,会导致没法达到像素级别的精确性,因此需要对位置做修正。为了近一步提高准确度,采用计算公式如下:
位置修正
由于目标检测模型本身的局限性,会导致没法达到像素级别的精确性,因此需要对位置做修正。为了近一步提高准确度,采用计算公式如下: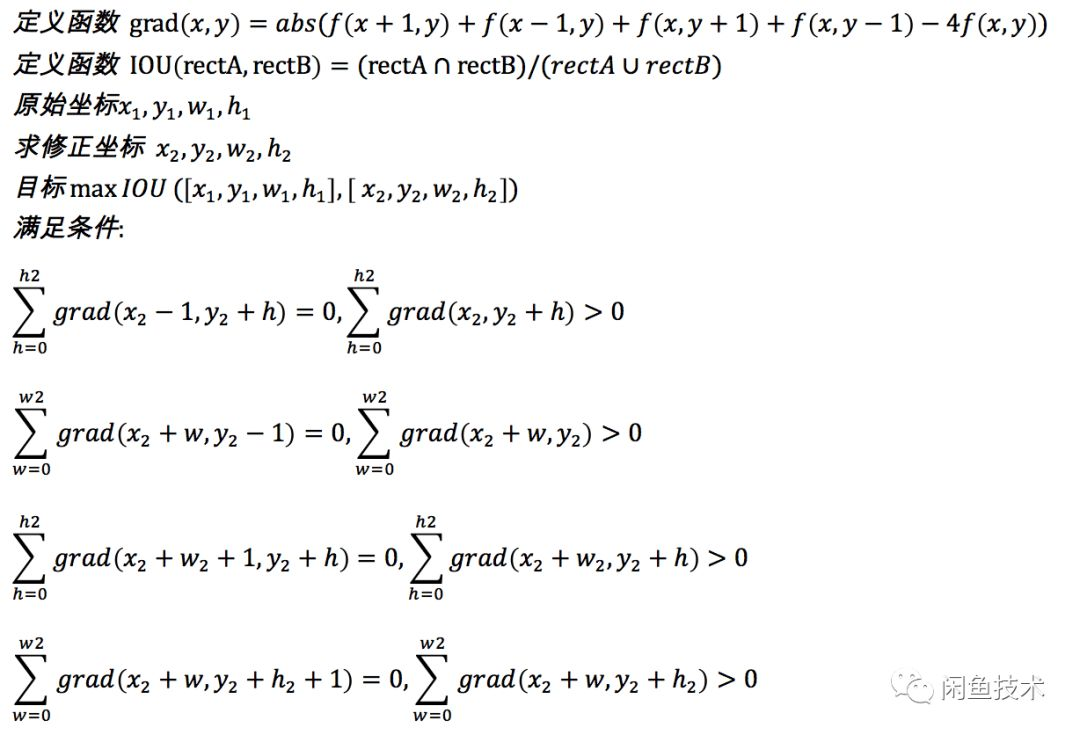

效果
本篇我们基于FPN+Cascade网络去预测淘宝99大促模块,在验证集近千张的样本量的情况下,采用了coco的验证标准,达到了如下的准确率:Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.982 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.989Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.984 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.989Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.423 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.986Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.993 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.993Average Recall (AR) @[ IoU=0.50 | area= large | maxDets=100 ] = 1.000
由上面的数据我们可以知道,页面和相应元素识别的召回率和准确率达到了98%左右,满足了识别精度的要求。此外,该流程符合Coarse-to-Fine的架构(由粗粒度到细粒度),对于相类似的问题也可以采用该方法处理。
后续计划
我们后续会尝试将本文的方法推广应用到更多的业务场景中去,例如双十一活动页模块识别等。由于本文的方法相对耗时(GPU机器几百毫秒级别),后续会在效果和效率的均衡上作更多的尝试,也希望大家能够关注我们后续的系列文章。闲鱼团队是Flutter+Dart FaaS前后端一体化新技术的行业领军者,就是现在!客户端/服务端java/架构/前端/质量工程师 通通期待你的加入,base杭州阿里巴巴西溪园区,一起做有创想空间的社区产品、做深度顶级的开源项目,一起拓展技术边界成就极致!
*投喂简历给小闲鱼→guicai.gxy@alibaba-inc.com


更多系列文章、开源项目、关键洞察、深度解读
请认准 闲鱼技术
