

机器之心原创
作者:仵冀颍 编辑:Joni Zhong
本文综述了两篇在迁移学习中利用权值调整数据分布的论文。通过这两个重要工作,读者可了解如何在迁移学习中进行微调的方法和理论。
深度神经网络的应用显著改善了各种数据挖掘和计算机视觉算法的性能,因此广泛应用于各类机器学习场景中。然而,深度神经网络方法依赖于大量的标记数据来训练深度学习模型,在实际应用中,获取足够的标记数据往往既昂贵又耗时。因此,一个自然的想法是利用现有数据集(即源域)中丰富的标记样本,辅助在要学习的数据集(即目标域)中的学习。解决这类跨领域学习问题的一种有效方法就是迁移学习:首先在一个大的标记源数据集(如 ImageNet)上训练模型,然后在目标数据集上进行模型调整更新,从而实现将已训练好的模型参数迁移到新的模型来帮助新模型训练。
基于深度神经网络的迁移学习主要有三种方式:一是迁移学习(Transfer Learning),重新训练全连接层,其他预训练模型的卷积层不变;二是特征向量提取(Feature Vector Extraction),利用预训练模型的卷积层提取源和目标数据集的特征向量,之后训练目标域中的全连接网络;三是微调(Fine-tune),重新学习分类层的参数,而其余网络层参数则沿用预训练模型的初始化值。
研究人员发现,仅靠改进迁移学习的方式(如上述三种迁移学习方式)并不能进一步降低目标域中模型的损失值,而选择改进用作模型预训练的源数据集的丰富程度则是一种有效的方法。源数据集的丰富程度并不仅由数据集中数据量的大小决定,而同时取决于用于预训练的数据集是否能够有效捕获到与目标域中数据集相似的差异性特征(因素)。前期的方法主要是通过不同的度量方法找到源数据集与目标数据集中的相似样本数据,例如 [1] 使用滤波器组响应中的特征来选择源数据集中的最近邻样本,与使用整个源数据集相比,该方法具备更好的性能。[2] 利用土方运距(Earth Mover』s Distance,EMD)对源数据集和目标数据集之间的区域相似性进行量化计算,之后利用一个简单的贪婪子集生成选择准则提高目标测试集的性能。然而上述方法只是找到相似的样本数据,无法有效捕获目标数据集中的变化判别因素,因此迁移学习的效果改进有限。这种微调相当于对迁移学习的前两种步骤的改进,进一步提升了迁移学习的性能,因此本文探讨的是改善微调方式的迁移学习。
Ngiam et al. 提出了一种利用权值捕获源域和目标域中相似信息从而有效调整数据分布的方法,即基于目标数据集的重要权值域自适应迁移学习方法(Domain Adaptive Transfer Learning,DATL)[1]。DATL 利用概率形态识别源数据集中能够有效捕获目标数据集中变化判别因素的样本数据,使用 JFT 和 ImageNet 数据集作为源训练数据,并考虑一系列用于微调的目标数据集。在微调过程中,对网络中的分类层进行随机初始化训练。在这项工作的基础上,Zhu et al. 提出了共享权值的概念,即对源和目标任务模型之间共享权值联合优化的学习框架(Learning to Transfer Learn,L2TL)[2],其中关于共享权值的计算是利用基于目标数据集的性能度量矩阵的强化学习模块(RL)实现的,从而保证自适应输出每个源数据集中类别的权值。L2TL 基于目标数据集中的测试性能自适应的推断域相似度。本文对 DATL 和 L2TL 进行详细的分析,目的是探讨在迁移学习中利用权值调整数据分布的有效性,以及计算权值的不同方式对迁移学习效果、计算成本等的影响。
1、Domain Adaptive Transfer Learning with Specialist Models
原文地址:https://arxiv.org/pdf/1811.07056.pdf
方法分析
DATL 使用 JFT 和 ImageNet 数据集作为源预训练数据,不在源数据集和目标数据集之间执行任何标签对齐处理。而是利用数据集之间的标签产生的权值进行调整。在微调过程中,对神经网络中的分类层进行随机初始化训练。首先考虑一个简化的设置,即源数据集和目标数据集位于相同的像素 x 和标签 y 值集上。预训练阶段,在源域中优化参数θ以最小化损失函数:
(1)
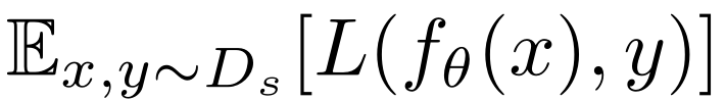
其中 Ds 表示源数据集,L(f_θ(x),y) 为模型 f_θ(y) 的预测与标签真值 y 之间的交叉熵损失函数。源数据集 Ds 中的数据分布与目标数据集 Dt 中的分布可能不同,通过加大与目标数据集最相关的样本的权值来解决这种问题。目标数据集 Dt 中的损失函数为:
(2)
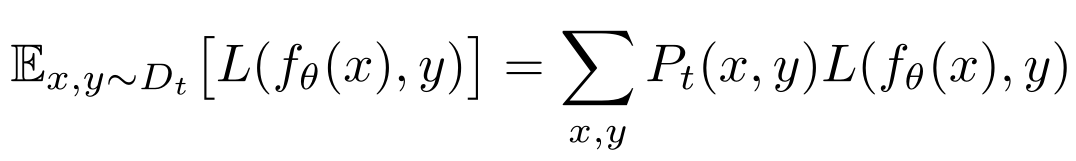
其中 Ps、Pt 分别表示源和目标数据集的概率分布。结合以上两个公式,重新计算(2)包含源数据集 Ds 的损失函数如下:
(3)
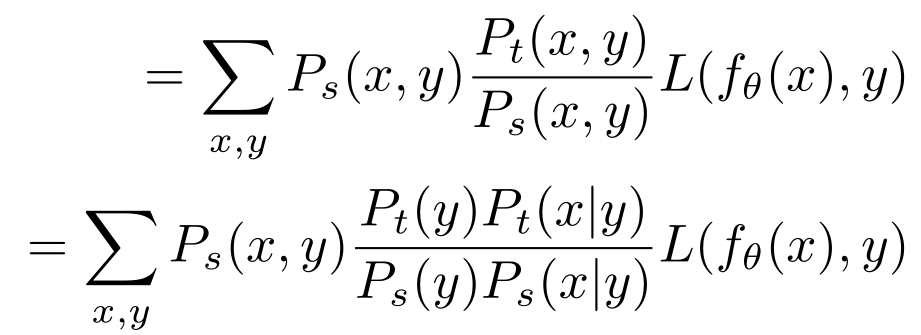
接下来,假设 Ps(x|y) 约等于 Pt(x|y),即在源数据集中给定特定标签的样本分布与目标数据集的近似分布是相同的,(3)可简化为:
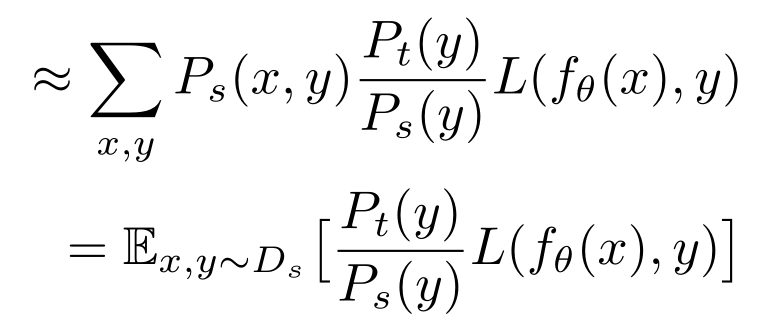
其中 Pt(y)/Ps(y) 为我们需要的权值。
为了使 DATL 在实践中适用,需要对简化设置(即源数据集和目标数据集共享相同的标签空间)进行放松假设,放松假设的处理过程具体为:「在真实的应用场景中,源数据集和目标数据集一般具有不同的标签集,解决方案是 Pt(y) 和 Ps(y) 的估计都在源域中进行,而不再基于目标域估计 Pt(y)。通过将标签出现的次数除以源数据集的样本总数计算分母 Ps(y)。为了估计 Pt(y),则使用一个分类器来计算来自源数据集的标签在来自目标数据集的样本上的概率。」
完整的 DATL 方法示例见图 1。为了计算重要性权值 Pt(y)/Ps(y),首先使用在整个 JFT 数据集上预训练的图像模型来评估来自目标数据集的图像。对于每一幅图像,能够得到其对 JFT 中 18291 个类的预测。对这些预测进行平均化处理后得到 Pt(y)。通过将标签在源预训练数据集中出现的次数除以源预训练数据集中的样本总数,直接从源预训练数据集中估计 Ps(y)。因此,权值 Pt(y)/Ps(y) 表示源预训练数据集中给定标签的重要程度。使用这些重要性权值在整个 JFT 数据集上训练生成预训练模型,然后在目标数据集上进行微调。
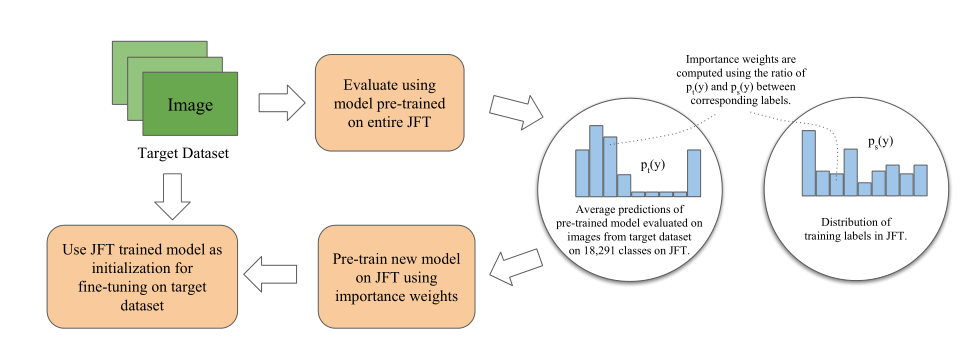
图 1. DATL 方法完整过程
实验分析
本文实验中通过使用重要性权值从源数据集(JFT 和 ImageNet)中采样样本来创建预训练数据集。预训练阶段使用 Inception v3 和 AmoebaNet-B 神经网络模型,微调阶段使用随机初始化的分类层来代替预训练的分类层。利用 SGD 对模型进行 20000 步的训练,每个小批量包含 256 个样本。使用保持验证集(hold-out validation set)计算权值正则化和学习速度参数。
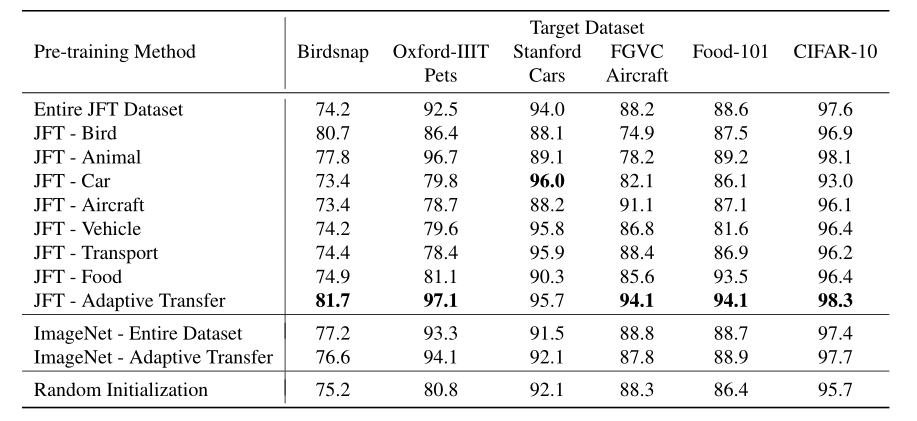
表 1. 使用 Inception v3 的迁移学习结果
表 1 给出使用 Inception v3 的迁移学习结果,每一行对应一个预训练方法,其中 Adaptive Transfer 指的是本文提出的方法。每列对应一个目标数据集。表 1 中结果是除 Oxford-IIIT Pets 外的所有数据集的最高准确度,我们给出了每个类的平均准确度。所有结果均执行 5 次微调处理。由表 1 结果可知,当源数据集与目标数据集完全匹配时,迁移学习效果最优;当源域和目标域不匹配时出现了负迁移。值得注意的是,在预训练阶段使用更多的源数据反而会影响迁移学习的效果。在所有类别情况下,在整个 JFT 数据集上预训练的模型效果都差于在某些具体子集上预训练的模型效果。此外,使用本文提出的 DATL 方法甚至比手动选择标签效果更好。
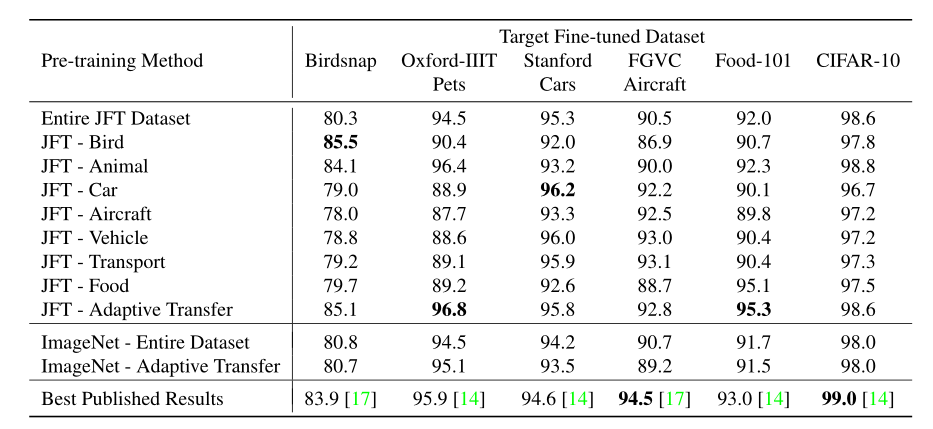
表 2. 使用 AmoebaNet-B 的迁移学习结果
表 2 给出了使用 AmoebaNet-B 的迁移学习结果,实验目的是验证较大模型是否能够更好的捕获更多的变化因素。AmoebaNet-B 上的实验参数超过 5.5 亿。另外,表 2 中的实验结果(AmoebaNet-B)优于表 1 的结果(Inception v3)。说明使用较大的模型能够缩小一般子集和特定子集之间的性能差距。
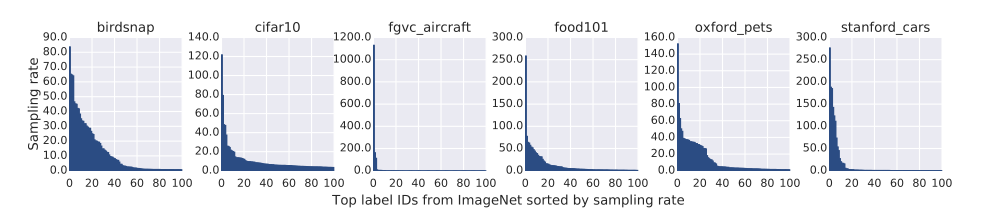
图 2. 使用 ImageNet 作为源预训练数据集时,每个目标数据集的重要性权值分布
最后,图 2 给出了使用 ImageNet 作为源预训练数据集时,每个目标数据集的重要性权值分布。由图 2 可知目标数据集之间的分布差异很大。FGVC Aircraft 只选择了一些粗粒度的标签,而 Oxford Pets 则选择了更广泛的细粒度标签,这反映了 ImageNet 数据集中固有的偏差。
总结
本文提出的 DATL 方法能够有效识别源预训练数据集中包含类别判别信息的数据样本,当未能有效捕获判别信息时迁移学习的效果就会受到影响。此外,本文实验还证明当使用较大的神经网络模型时,在类别子集中预训练的迁移学习效果更好。也就是说,如果是在完整的源数据集中完成预训练,则训练过程还需额外处理细粒度类别间的区别。
2、Learning to Transfer Learn
原文地址:https://arxiv.org/pdf/1908.11406.pdf
方法分析
与 DATL 方法不同,Zhu et al. 提出的 L2TL 方法不再直接计算概率相似度度量(权值),而是提出了一个优化源域及目标域共享权值的框架。预训练目标函数如下:
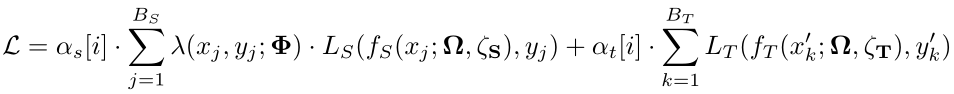
其中,L 为目标函数,由对应源域的目标函数 L_S 和对应目标域的目标函数 L_D 组成。与仅在源域中优化损失函数的 DATL 不同,L2TL 的预训练通过同时在源域和目标域内的联合优化来实现。D_S 和 D_T 分别表示给定的源和目标数据集,B_S 和 B_T 分别表示源和目标批量大小,α_s[i] 和α_t[i] 分别表示第 i 轮迭代时的源域、目标域尺度参数,λ(x,y,Φ) 为控制源域和目标域在优化过程中比重的权值参数,f_S 和 f_T 分别表示利用神经网络求得的源和目标编码函数。整个目标函数的训练参数为Ω、ζ_S 和ζ_T。为了最大程度地受益于源数据集,应当在源域和目标域内共享尽可能多的训练参数。基于预训练目标函数,T2TL 的学习目标是从保持目标验证数据集中推广到未知样本中,并最大化下面的评估指标:
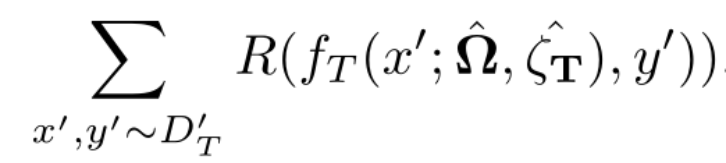
其中 R 是目标性能指标,例如用于分类的 top-1 准确度或曲线下面积(AUC)等指标项。Ω和ζ_T 为预训练优化得到的参数。在微调过程中,首先考虑样本权值λ(x,y)=1 的 Ns 步源数据集的优化,然后考虑使用预训练权值的目标数据集优化:
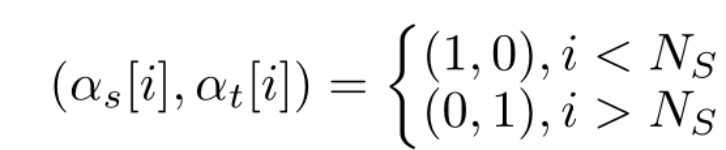
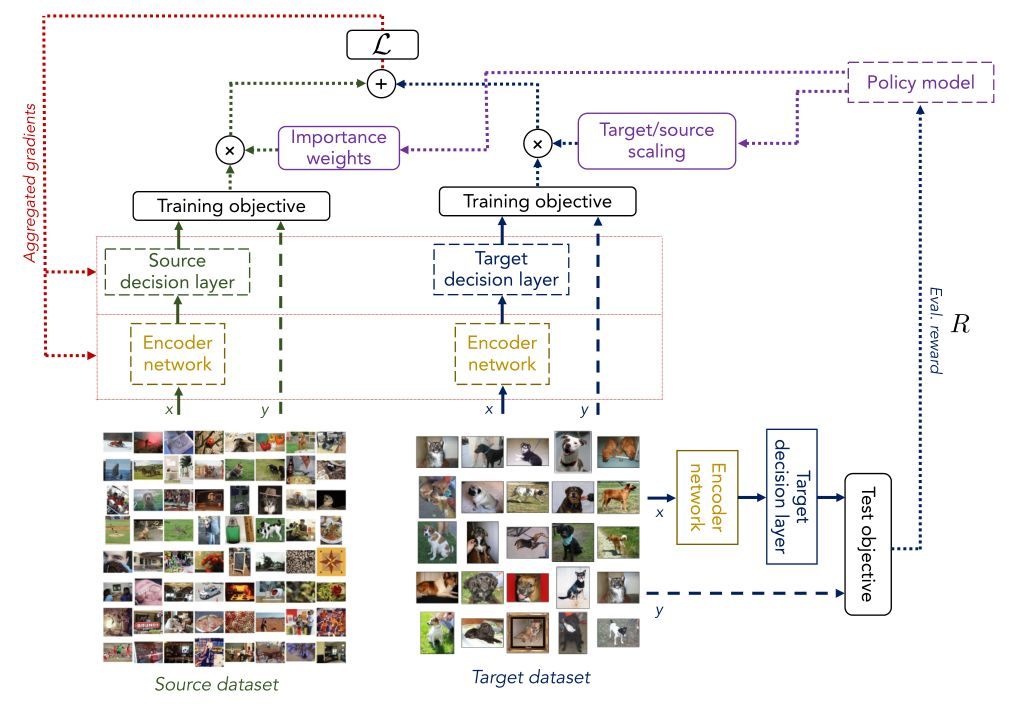
图 1. L2TL 框架总图,其中虚线部分对应预训练过程
图 1 给出了 L2TL 的处理框架图,目的是自适应学习权值分配,而不是使用固定的权值分配函数λ测量源域和目标域的相关性。保持目标验证数据集的处理效果(使用给定度量 R 量化)影响了 L2TL 中自适应权值的学习。因此,除了针对一般关联性,L2TL 框架还直接处理特定的关联性以提高目标评价绩效的具体目标。
在预训练迭代的第一阶段,使用基于梯度下降的优化方法优化损失函数,从而得出学习编码器Ω的权值以及分类器权值ζ_S 和ζ_T:
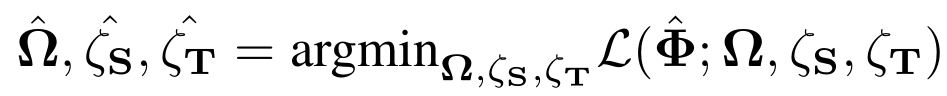
在这个阶段,神经网络模型是固定的,通过对它的动作采样以确定各个权值。当源数据集的某一个批次中的样本不相关,而一些批次中包含了更多相关性样本,则可能会出现损失函数的倾斜。为了解决这个问题,本文建议可以扩大采样的批次大小并动态地选择更多的相关样本。在每次迭代中,抽取一批大小为 M_s * B_s 的训练样本,并使用其中权值最高的 B_s 部分进行训练更新,其中 M_S 表示批量倍数,目的是扩大采样的批次大小,在本文实验中 M_S 取值均为 5。这种处理同时也有利于减小计算成本,因为在收敛之前,大多数源数据集样本的梯度都不需计算。
预训练迭代的第二阶段目标是优化策略权值Φ,该策略权值基于上一阶段中计算得到的编码器权值(Ω、ζ_S、ζ_T)的目标验证集上的评估度量 R 最大化:
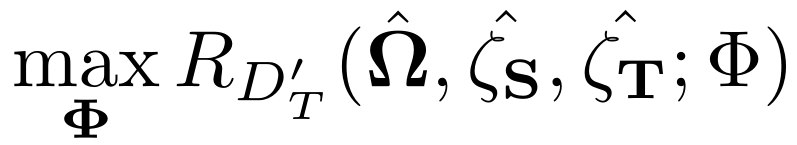
在 L2TL 中,这一步处理看作是一个强化学习 RL 问题,即利用策略模型求出λ(x,y;Φ) 和α以实现奖励优化。与 Ngiam 文章中的处理类似,即「需要对简化设置(即源数据集和目标数据集共享相同的标签空间)进行放松假设」,本文有λ(x,y;Φ)=λ(y;Φ)。将λ(y;Φ) 的可能值离散化处理为预定义的行为数量,取值范围为λ(y)∈[0,1]。本文定义 n 个动作,使得每个动作 k∈[0,n-1] 对应于一个权值 k/(n-1)。此外对α的可能值也进行类似的离散化处理。在训练策略模型时,使用卷积编码器的评估模式,同时对目标数据集 D_T』上的奖励进行梯度最大化处理,使用批量大小为 Bp。在更新迭代 t 中,表示优势 At=Rt-Bt,其中 Bt 是基线。本文使用 Reinforce[5] 计算 policy 梯度,并使用 Adam 优化器进行优化 [6]。
实验分析
本文实验中使用源数据集 JFT 和 ImageNet,策略模型使用随机变量初始化模型参数。L2TL 首先基于验证集的奖励进行训练。然后,利用学习到的控制变量对关联模型进行训练和验证。对于给出的微调方法实验结果,均使用在目标数据集上评估的最佳超参数集。结果用三次运行求平均值。本文对五个不同子集的数据集进行评估,详细的数据集拆分如表 1 所示。奖励在目标数据集上使用 top-1 准确度进行测量。
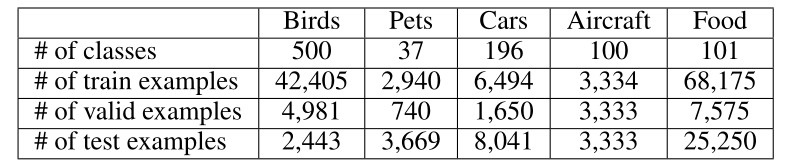
表 1:五个细粒度数据集的详细信息
L2TL 以及经典微调方法、DATL 的结果如表 2 所示。可以看出,与经典的微调方法相比 L2TL 在所有数据集上的表现都更优,这就证明了 L2TL 在跨域选择相关源数据样本方面的优势。DATL 在鸟巢(Birdsnap)和飞机(Aircraft)上的性能比经典微调方法差,这突出了除了考虑标签匹配因素之外有效利用视觉相似性的重要性。此外,表 3 给出了使用 JFT-300M 的结果,结果证明 L2TL 在学习更大规模数据集的相关性方面具有优势。
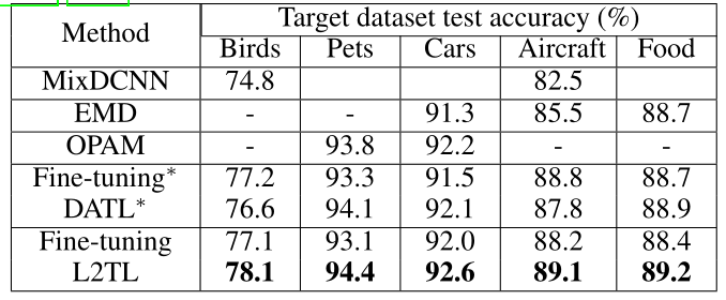
表 2. ImageNet 源数据集的迁移学习性能
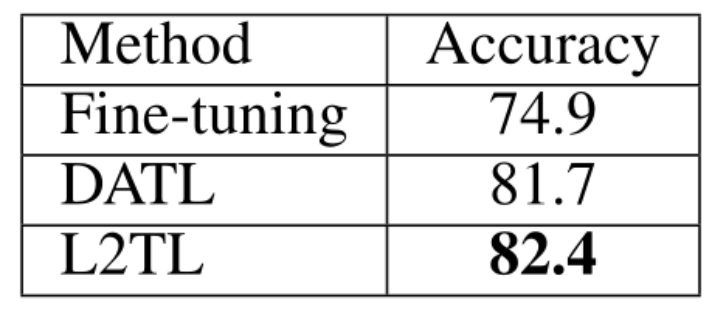
表 3. 使用 JFT-300M 图像的鸟巢测试集结果
表 3 中列出了微调、DATL 和 L2TL 不同方法的计算成本。应用 DATL 方法,给定一个新的目标数据集,须对重新采样的数据训练一个新的模型,这种处理对于大规模源数据集来说非常耗时。L2TL 需要同时在源数据集和目标数据集上进行计算,其迁移学习步骤比微调更复杂。但是它只需要对源数据集进行一次训练,因此所需的训练时间比 DATL 要少得多。

当源数据集为 ImageNet 时,在 Cloud TPUv2 上使用 Inception-v3 进行训练的计算成本
最后,本文考虑其类在源数据集中不存在的目标数据集情况。本文构建两个目标数据集:可描述的纹理数据集(Describable Textures Dataset,DTD)和胸片数据集(Chest X-Ray Dataset,CheXpert)。DTD 的结果如表 4 所示。我们观察到与随机初始化的方法相比,基于 ImageNet 的微调方法大大提高了分类准确度,而使用 L2TL 进一步将微调基线准确度提高了 1.5%,这是由于 L2TL 考虑了具有相关性的源类信息,而不是直接使用所有类的信息。图 2 中展示了 ImageNet 的顶级相关类,这些结果表明 L2TL 能够有效利用源类和目标类之间的视觉相似性。
表 4. SPLIT1 上 DTD 测试集的结果

图 2. 从 ImageNet 迁移到 DTD 目标时的前四个相关类
在 CheXpert 数据集上,使用平均 AUC 作为奖励,卷积结构为 DenseNet-121,具体结果见表 5。L2TL 的性能比微调基线提升 0.7%。从 ImageNet 中识别出与 CheXpert 相关的相似人类视觉信息并不多,但 L2TL 仍然能够发现图像中隐藏的模式从而获得较好的处理效果。

表 5. CheXpert 数据集上的 AUC 比较
总结
本文提出的 L2TL 实现了源任务和目标任务模型的联合优化,同时使用自适应权值控制联合损失。此外,使用目标数据集上的性能度量作为奖励来训练策略模型,从而自适应地输出每个源类对应的权值。目标数据集越小,L2TL 的性能优势越显著。L2TL 框架不使用类似于 DATL 的显式相似性度量,而是学习源类权值直接优化目标数据集的性能。因此,在源数据集和目标数据集来自不同领域的情况下,L2TL 仍然有明显的改进。以本文的工作为基础,后续可以考虑使用源数据集中更高优化粒度的搜索空间以改进效果。对于类内方差较大的源数据集,利用策略梯度模拟λ(x,y;Φ) 函数对 x 的依赖性可以进一步提升 L2TL 的性能,但这种计算过程可能会增大计算压力。
文章小结
本文针对两篇关于迁移学习的文章进行了详细阐述,这两篇文章的核心思想是「在迁移学习中利用权值调整源数据集和目标数据集的数据分布」,通过定义权值在微调阶段的损失函数,完成对两个数据集中不同分布的平衡化处理,从而使得基于源数据集的预训练模型能够有效捕获目标数据集中的变化判别因素。
这两篇文章的区别在于:DATL 在利用概率形态对比源和目标数据集中相似样本数据的同时引入权值调整数据分布,而 T2TL 则是直接将源和目标数据集中的共享权值进行联合优化,即不使用概率形态作为权值度量,而是提出了一个直接优化目标数据集中权值度量的框架。由实验可知,DATL 使用源和目标数据集中概率分布的匹配程度作为权值,而未考虑两个数据集间的视觉相似性等其它信息。而 T2TL 则是对两个数据集共享权值的联合优化,其效果优于 DATL。另一方面,从计算成本角度考虑,给定一个新的目标数据集 DATL 须对重新采样的数据训练一个新的模型,这种处理对于大规模源数据集来说非常耗时。L2TL 只需要对源数据集进行一次训练,因此所需的训练时间比 DATL 要少得多,计算成本较低。
参考文献
[1] W. Ge and Y . Y u. Borrowing treasures from the wealthy: Deep transfer learning through selective joint fine-tuning. In CVPR, 2017.
[2] Y . Cui, Y . Song, C. Sun, A. Howard, and S. Belongie. Large scale fine-grained categorization and domain-specific transfer learning. In CVPR, 2018.
[3] J. Ngiam, D. Peng, V . V asudevan, S. Kornblith, Q. V . Le, and R. Pang. Domain adaptive transfer learning with specialist models. arXiv preprint arXiv:1811.07056, 2018.
[4] L.Zhu, S.O.Arik, Y.Yang, T.Pfister. Learning to Transfer Learn. arXiv preprint arXiv:1908.11406, 2019.
[5] R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 1992.
[6] D. P . Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, 2014.
AI 给游戏加点料,是不是变得很好玩。本周四,华为云·云享专家钱希睿老师将带来一场线上分享,详解「如何用AI开发平台实现LOL小地图英雄头像分析」 ,点击阅读原文,立即报名。
