

作者简介
李剑,携程系统研发部技术专家,负责Redis和Mongodb的容器化和服务化工作,喜欢深入分析系统疑难杂症。
前言
随着携程的应用大规模在生产上用容器部署,各种上规模的问题都慢慢浮现,其中比较难定位和解决的就是偶发性超时问题,下面将分析目前为止我们遇到的几种偶发性超时问题以及排查定位过程和解决方法,希望能给遇到同样问题的小伙伴们以启发。
问题描述
某一天接到用户报障说,Redis集群有超时现象发生,比较频繁,而访问的QPS也比较低。紧接着,陆续有其他用户也报障Redis访问超时。在这些报障容器所在的宿主机里面,我们猛然发现有之前因为时钟漂移问题升级过内核到4.14.26的宿主机ServerA,心里突然有一丝不详的预感。
初步分析
因为现代软件部署结构的复杂性以及网络的不可靠性,我们很难快速定位“connect timout”或“connectreset by peer”之类问题的根因。
历史经验告诉我们,一般比较大范围的超时问题要么和交换机路由器之类的网络设备有关,要么就是底层系统不稳定导致的故障。从报障的情况来看,4.10和4.14的内核都有,而宿主机的机型也涉及到多个批次不同厂家,看上去没头绪,既然没什么好办法,那就抓个包看看吧。
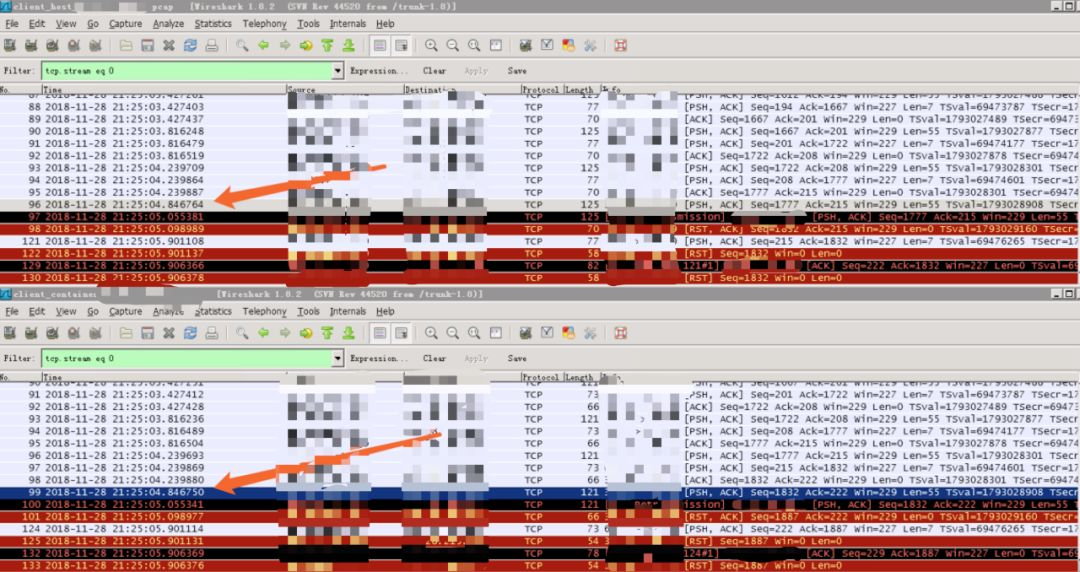
图1
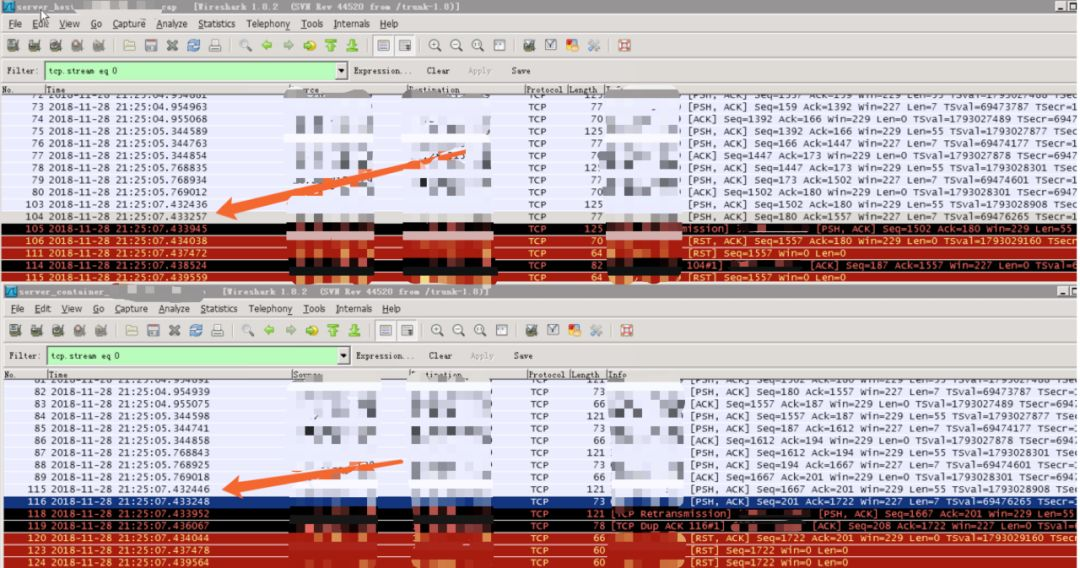
图2
图1是App端容器和宿主机的抓包,图2是Redis端容器和宿主机的抓包。因为APP和Redis都部署在容器里面(图3),所以一个完整请求的包是B->A->C->D,而Redis的回包是D->C->A->B。
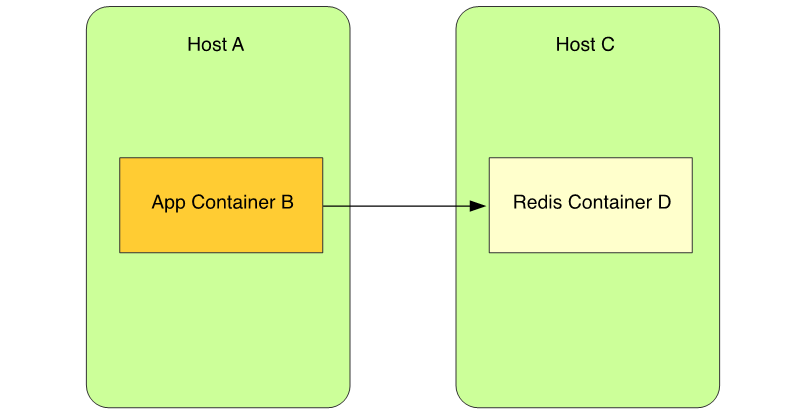
图3
上面抓包的某一条请求如下:
1)B(图1第二个)的请求时间是21:25:04.846750 #99
2)到达A(图1第一个)的时间是21:25:04.846764 #96
3)到达C(图2第一个)的时间是21:25:07.432436 #103
4)到达D(图2第二个)的时间是21:25:07.432446 #115
该请求从D回复如下:
1)D的回复时间是21:25:07.433248 #116
2)到达C的时间是21:25:07.433257 #104
3)到达A点时间是21:25:05:901108 #121
4)到达B的时间是21:25:05:901114 #124
从这一条请求的访问链路我们可以发现,B在200ms超时后等不到回包。在21:25:05.055341重传了该包#100,并且可以从C收到重传包的时间#105看出,几乎与#103的请求包同时到达,也就是说该第一次的请求包在网络上被延迟传输了。大致的示意如下图4所示:

图4
从抓包分析来看,宿主机上好像并没有什么问题,故障在网络上。而我们同时在两边宿主机,容器里以及连接宿主机的交换机抓包,就变成了下面图5所示,假设连接A的交换机为E,也就是说A->E这段的网络有问题。
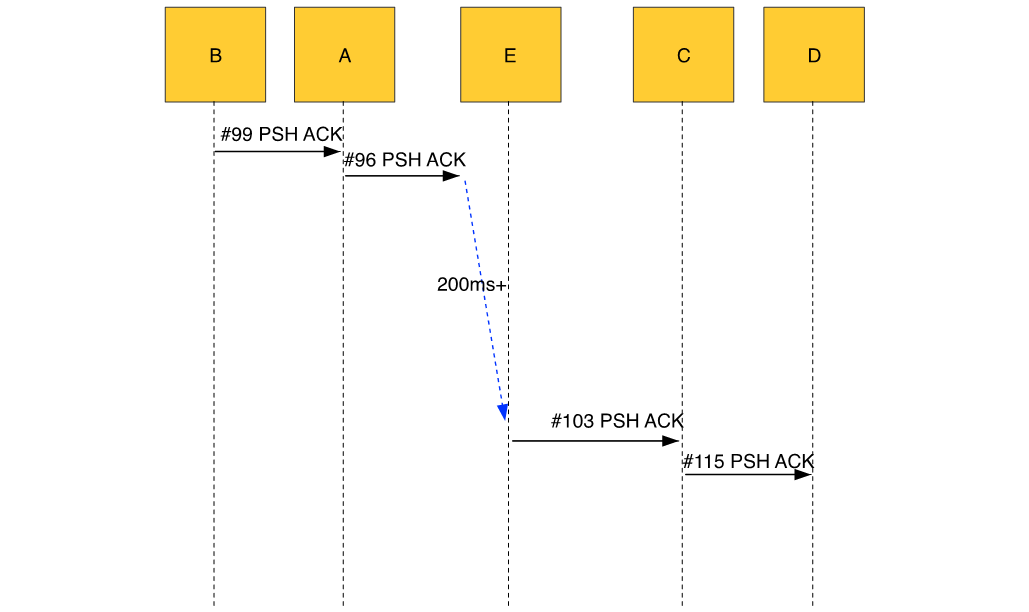
图5
陷入僵局
尽管发现A->E这段有问题,排查却也就此陷入了僵局,因为影响的宿主机遍布多个IDC,这也让我们排除了网络设备的问题。我们怀疑是否跟宿主机的某些TCP参数有关,比如TSO/GSO,一番测试后发现开启关闭TSO/GSO和修改内核参数对解决问题无效,但同时我们也观察到,从相同IDC里任选一台宿主机Ping有问题的宿主机,百分之几的概率看到很高的响应值,如下图6所示:
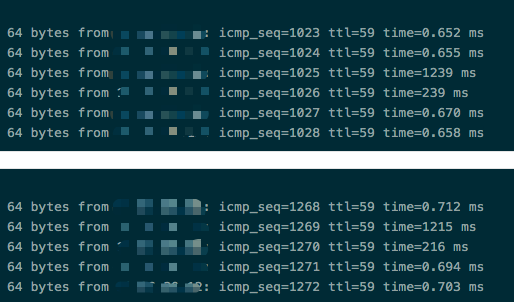
图6
同一个IDC内如此高的Ping响应延迟,很不正常。而这时DBA告诉我们,他们的某台物理机ServerB也有类似的的问题,Ping延迟很大,SSH上去后明显感觉到有卡顿,这无疑给我们解决问题带来了希望,但又更加迷惑:
1)延迟好像跟内核版本没有关系,3.10,4.10,4.14的三个版本内核看上去都有这种问题。
2)延迟和容器无关,因为延迟都在宿主机上到连接宿主机的交换机上发现的。
3)ServerB跟ServerA虽然表现一样,但细节上看有区别,我们的宿主机在重启后基本上都能恢复一段时间后再复现延迟,但ServerB重启也无效。
由此我们判断ServerA和ServerB的症状并不是同一个问题,并让ServerB先升级固件看看。在升级固件后ServerB恢复了正常,那么我们的宿主机是不是也可以靠升级固件修复呢?答案是并没有。升级固件后没过几天,延迟的问题又出现了。
意外发现
回过头来看之前为了排查Skylake时钟漂移问题的ServerA,上面一直有个简单的程序在运行,来统计时间漂移的值,将时间差记到文件中。当时这个程序是为了验证时钟漂移问题是否修复,如图7:
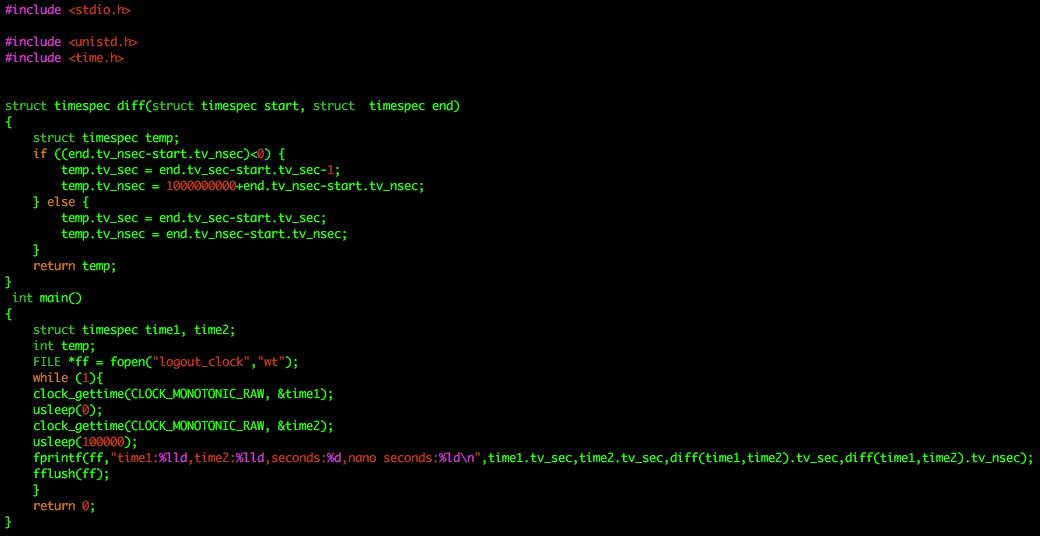
图7
这个程序跑在宿主机上,每个机器各有差异,但正常的时间差应该是100us以内,但1个多月后,时间差异越来越大,如图8,最大能达到几百毫秒以上。这告诉我们可能通过这无意中的log来找到根因,而且验证了上面3的这个猜想,宿主机是运行一段时间后逐渐出问题,表现为第一次打点到第二次打点之间,调度会自动delay第二次打点。

图8
TSC和Perf
Turbostat是intel开发的,用来查看CPU状态以及睿频的工具,同样可以用来查看TSC的频率。而关于TSC,之前的文章《携程一次Redis迁移容器后Slowlog“异常”分析》中有过相关介绍,这里就不再展开。
在有问题的宿主机上,TSC并不是恒定的,如图9所示,这个跟相关资料有出入,当然我们分析更可能的原因是,turbostat两次去取TSC的时候,被内核调度delay了,如果第一次取时被delay导致取的结果比实际TSC的值要小,而如果第二次取时被delay会导致取的结果比实际值要大。
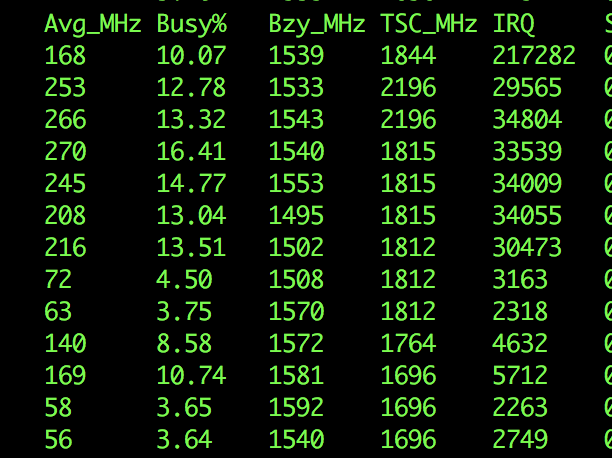
图9
Perf 是内置于Linux上的基于采样的性能分析工具,一般随着内核一起编译出来,具体的用法可以搜索相关资料,这里也不展开。用perf sched record -a sleep 60和perf sched latency -s max来查看linux的调度延迟,发现最大能录得超过1s的延迟,如图10和图11所示。用户态的进程有时因为CPU隔离和代码问题导致比较大的延迟还好理解,但这些进程都是内核态的。尽管linux的CFS调度并非实时的调度,但在负载很低的情况下超过1s的调度延迟也是匪夷所思的。
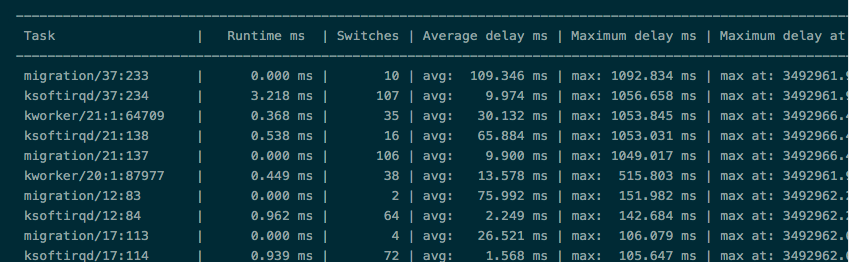
图10

图11
根据之前的打点信息和turbostat以及perf的数据,我们非常有理由怀疑是内核的调度有问题,这样我们就用基于rdtscp指令更精准地来获取TSC值来检测CPU是否卡顿。rdtscp指令不仅可以获得当前TSC的值,并且可以得到对应的CPU ID。如图12所示:
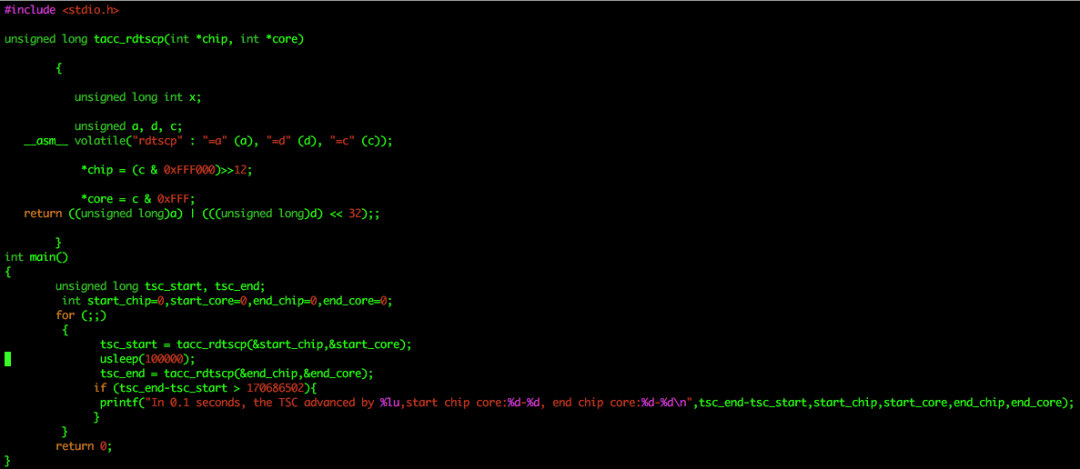
图12
上面的程序编译后,放在宿主机上依次绑核执行,我们发现在问题的宿主机上可以打印出比较大的TSC的值。每间隔100ms去取TSC的值,将获得的相减,在正常的宿主机上它的值应该跟CPU的TSC紧密相关,比如我们的宿主机上TSC是1.7GHZ的频率,那么0.1s它的累加值应该是170000000,正常获得的值应该是比170000000多一点,图13的第五条的值本身就说明了该宿主机的调度延迟在2s以上。
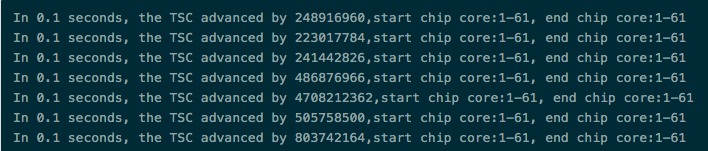
图13
真相大白
通过上面的检测手段,可以比较轻松地定位问题所在,但还是找不到根本原因。这时我们突然想起来,线上Redis大规模使用宿主机的内核4.14.67并没有类似的延迟,因此我们怀疑这种延迟问题是在4.14.26到4.14.67之间的bugfix修复掉了。
查看commit记录,先二分查找大版本,再将怀疑的点单独拎出来patch测试,终于发现了这个4.14.36-4.14.37之间的(图14)commit:

图14
从该commit的内容来看,修复了无效的apic id会导致possible CPU个数不正确的情况,那么什么是x2apic呢?什么又是possible CPU?怎么就导致了调度的延迟呢?
说到x2apic,就必须先知道apic, 翻查网上的资料就发现,apic全称Local Advanced ProgrammableInterrupt Controller,是一种负责接收和发送中断的芯片,集成在CPU内部,每个CPU有一个属于自己的local apic。它们通过apic id进行区分。而x2apic是apic的增强版本,将apic id扩充到32位,理论上支持2^32-1个CPU。简单的说,操作系统通过apic id来确定CPU的个数。
而possible CPU则是内核为了支持CPU热插拔特性,在开机时一次载入,相应的就有online,offline CPU等,通过修改/sys/devices/system/cpu/cpu9/online可以动态关闭或打开一个CPU,但所有的CPU个数就是possible CPU,后续不再修改。
该commit指出,因为没有忽略apic id为0xffffffff的值,导致possible CPU不正确。此commit看上去跟我们的延迟问题找不到关联,我们也曾向该issue的提交者请教调度延迟的问题,对方也不清楚,只是表示在自己环境只能复现possible CPU增加4倍,vmstat的运行时间增加16倍。
这时我们查看有问题的宿主机CPU信息,奇怪的事情发生了,如图15所示,12核的机器上possbile CPU居然是235个,而其中12-235个是offline状态,也就是说真正工作的只有12个,这么说好像还是跟延迟没有关系。
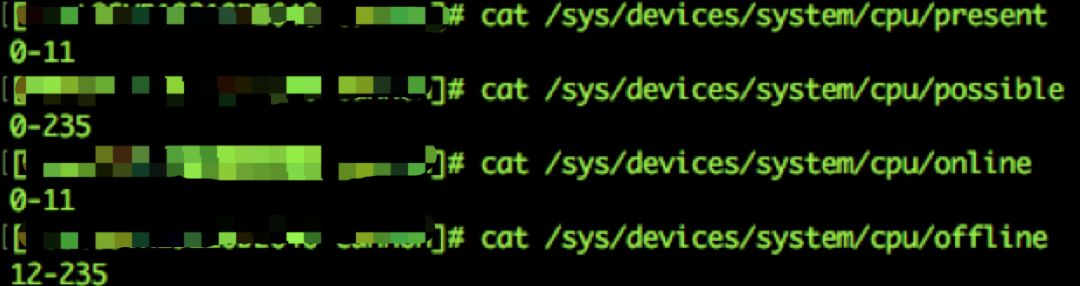
图15
继续深入研究possbile CPU,我们发现了一些端倪。从内核代码来看,引用for_each_possible_cpu()这个函数的有600多处,遍布各个内核子模块,其中关键的核心模块比如vmstat,shed,以及loadavg等都有对它的大量调用。而这个函数的逻辑也很简单,就是遍历所有的possible CPU,那么对于12核的机器,它的执行时间是正常宿主机执行时间的将近20倍!该commit的作者也指出太多的CPU会浪费向量空间并导致BUG( lkml.org/lkml/2018/5…),而BUG就是调度系统的缓慢延迟。
以下图16,图17是对相同机型相同厂商的两台空负载宿主机的kubelet的perf数据(perf stat -p $pid sleep 60),图16是uptime 2天的,而图17是uptime 89天的。
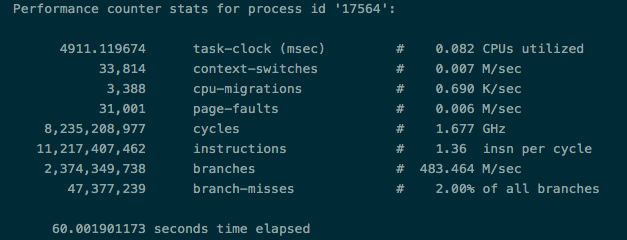
图16
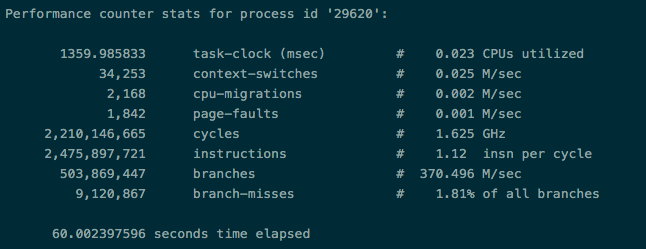
图17
我们一眼就看出图16的宿主机不正常,因为无论是CPU的消耗,上下文的切换速度,指令周期,都远劣于图17的宿主机,并且还在持续恶化,这就是宿主机延迟的根本原因。而图17宿主机恰恰只是图16的宿主机打上图14的patch后的内核,可以看到,possible CPU恢复正常(图18),至此超时问题的排查告一段落。

图18
总结
我们排查发现,不是所有的宿主机,所有的内核都在此BUG的影响范围内,具体来说4.10(之前的有可能会有影响,但我们没有类似的内核,无法测试)-4.14.37(因为是stable分支,所以master分支可能更靠后)的内核,CPU为skylake及以后型号的某些厂商的机型会触发这个BUG。
确认是否受影响也比较简单,查看possible CPU是否是真实CPU即可。
【推荐阅读】

关注“携程技术中心”公众号
了解携程技术一手动态
