

作者简介
李剑,携程系统研发部技术专家,负责Redis和Mongodb的容器化和服务化工作,喜欢深入分析系统疑难杂症。
周昕毅,携程系统研发部云平台高级研发经理。现负责携程容器云平台运维,Cloud Storage及Cloud Network基础设施研发及运维。
本文为容器偶发性超时问题案例分析的第二篇,第一篇点这里。
前言
随着内核升级到4.14.67,看上去延迟的问题彻底解决了,然而并没有,只是出现的更加缓慢。几周后,超时报障又找了过来,我们用perf来分析,发现了一些异常。
如图1所示是一个空负载的宿主机升级内核后8天的perf的数据,明显可以看到kworker的max delay已经100ms+,而这次有规律的是,延迟比较大的都是最后四个核,对于12核的节点就是8-11,并且都是同一D厂的宿主机。而上篇中使用新内核后用来验证解决问题的却不是D厂的宿主机,也就是说除了内核,还有其他的因素导致了延迟。

图1
NUMA和CPU亲和性绑定
NUMA全称Non-Uniform Memory Access,NUMA服务器一般有多个节点,每个节点由多个CPU组成,并且具有独立的本地内存,节点内部使用共有的内存控制器,节点之间是通过内部互联(如QPI)进行通信。
然而,访问本地内存的速度远远高于访问其他节点的远地内存的速度,通常有几十倍的性能差异,这也正是NUMA 名称的由来。因为NUMA的这个特性,为了更好地发挥系统性能,应用程序应该尽量减少不同节点CPU之间的信息交互。
无意中发现,D厂的机型与其他机型的NUMA配置不一样。假设12核的机型,D厂的机型NUMA节点分配如下图2所示:

图2
而其他厂家的机型NUMA节点分配如下图3所示:

图3
为什么会出现delay都是最后四个核上的进程呢?
经过深入排查才发现,原来相关同事之前为了让k8s的相关进程和普通的用户的进程相隔离,设置了CPU的亲和性,让k8s的相关进程绑定到宿主机的最后四个核上,用户的进程绑定到其他的核上,但后面这一步并没有生效。
还是拿12核的例子来说,上面的k8s是绑定到8-11核,但用户的进程还是工作在0-11核上,更重要的是,最后4个核在遇到D厂家的这种机型时,实际上是跨NUMA绑定,导致了延迟越来越高,而用户进程运行在相关的核上就会导致超时等各种故障。
确定问题后,解决起来就简单了。将所有宿主机的绑核去掉,延迟就消失了,以下图4是D厂的机型去掉绑核后开机26天perf的调度延迟,从数据上看一切都恢复正常。
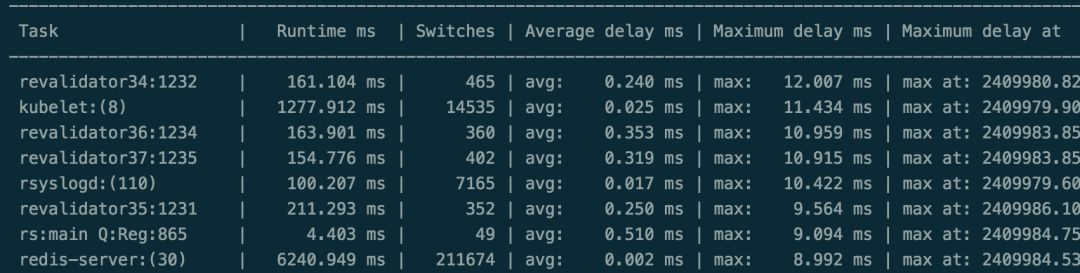
图4
新的问题
大约过了几个月,又有新的超时问题找到我们。有了之前的排查经验,我们觉得这次肯定能很轻易的定位到问题,然而现实无情地给予了我们当头一棒,4.14.67内核的宿主机,还是有大量无规律超时。
深入分析
perf看调度延迟,如图5所示,调度延迟比较大但并没有集中在最后四个核上,完全无规律,同样turbostat依然观察到TSC的频率在跳动。
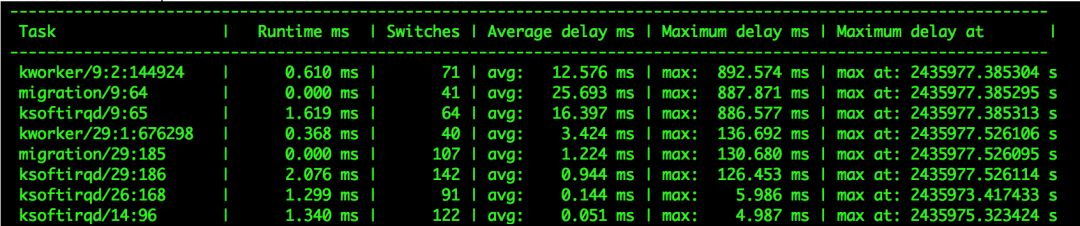
图5
在各种猜想和验证都被一一证否后,我们开始挨个排除来做测试:
1、我们将某台A宿主机实例迁移走,perf看上去恢复了正常,而将实例迁移回来,延迟又出现了。
2、另外一台B宿主机上,我们发现即使将所有的实例都清空,perf依然能录得比较高的延迟。
3、而与B相连编号同一机型的C宿主机迁移完实例后重启,perf恢复正常。这时候看B的TOP,只有一个kubelet在消耗CPU,将这台宿主机上的kubelet停掉,perf正常,开启kubelet后,问题又依旧。
这样我们基本可以确定kubelet的某些行为导致了宿主机卡顿和实例超时,对比正常/非正常的宿主机kubelet日志,每秒钟都在获取所有实例的监控信息,在非正常的宿主机上,会打印以下的日志。如图6所示:

图6
而在正常的宿主机上没有该日志或者该时间比较短,如图7所示:

图7
到这里,我们怀疑这些LOG的行为可能指向了问题的根源。查看k8s代码,可以知道在获取时间超过指定值longHousekeeping (100ms)后,k8s会记录这一行为,而updateStats即获取本地的一些监控数据,如图8代码所示:
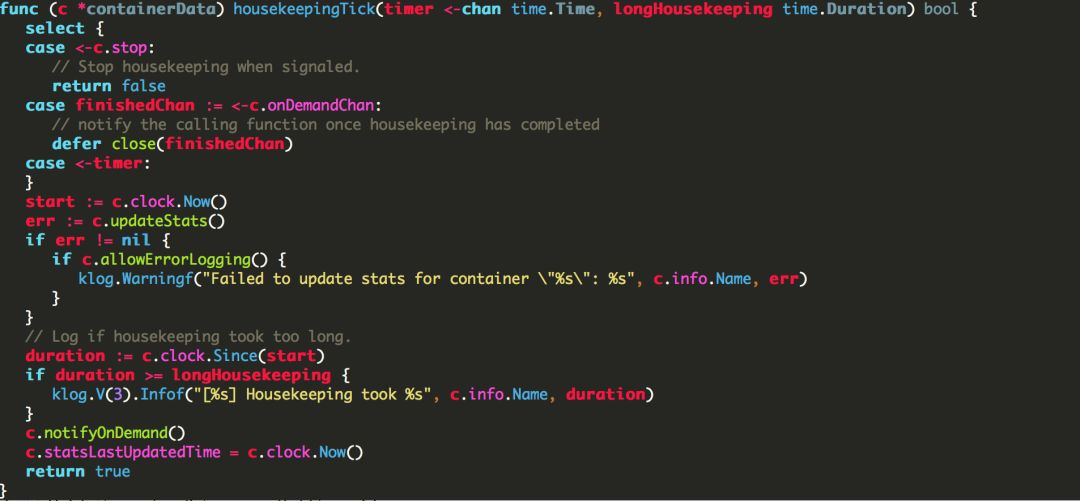
图8
在网上搜索相关issue,问题指向cadvisor的消耗CPU过高,
而在某个issue中指出
echo2 > /proc/sys/vm/drop_caches
可以暂时解决这种问题。我们尝试在有问题的机器上执行清除缓存的指令,超时问题就消失了,如图9所示。而从根本上解决这个问题,还是要减少取metrics的频率,比较耗时的metrics干脆不取或者完全隔离k8s的进程和用户进程才可以。
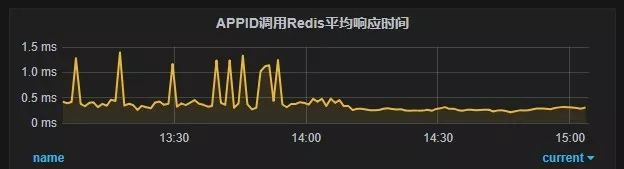
图9
硬件故障
在排查cadvisor导致的延迟的过程中,还发现一部分用户报障的超时,并不是cadvisor导致的,主要表现在没有Housekeeping的日志,并且perf结果看上去完全正常,说明没有调度方面的延迟,但从TSC的获取上还是能观察到异常。
由此我们怀疑这是另一种全新的故障,最重要的是我们将某台宿主机所有业务完全迁移掉,并关闭所有可以关闭的进程,只保留内核的进程后,TSC依然不正常并伴随肉眼可见的卡顿,而这种现象跟之前DBA那台物理机卡顿的问题很相似,这告诉我们很有可能是硬件方面的问题。
从以往的排障经验来看,TSC抖动程度对于我们排查宿主机是否稳定有重要的参考作用。这时我们决定将TSC的检测程序做成一个系统服务,每100ms去取一次系统的TSC值,将TSC的差值大于指定值打印到日志中,并采集单位时间的异常条目数和最大TSC差值,放在监控系统上,来观察异常的规律。如图10所示。
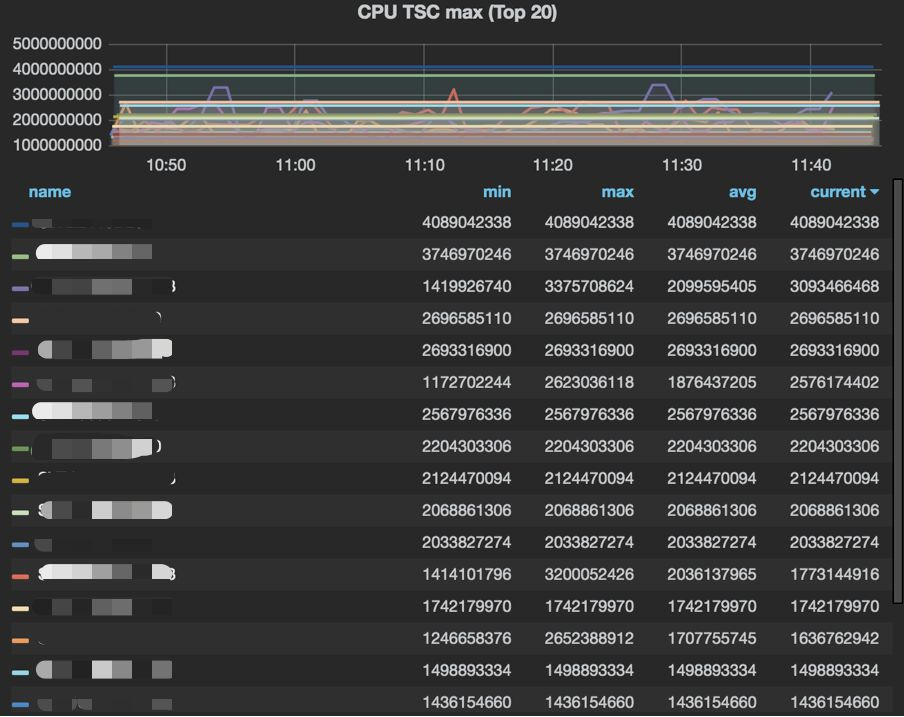
图10
这样采集有几个好处:
1、程序消耗比较小,仅仅消耗几个CPU cycles的时间,完全可以忽略不计;
2、对于正常的宿主机,该日志始终为空;
3、对于有异常的宿主机,因为采集力度足够小,可以很清晰地定位到异常的时间点,这样对于宿主机偶尔抖动情况也能采集到;
恰好TSC检测的服务上线不久,一次明显的故障说明了它检测宿主机是否稳定的有效性。如图11,在某日8点多时,一台宿主机TSC突然升高,与应用的告警邮件和用户报障同一时刻到来。如图12所示:
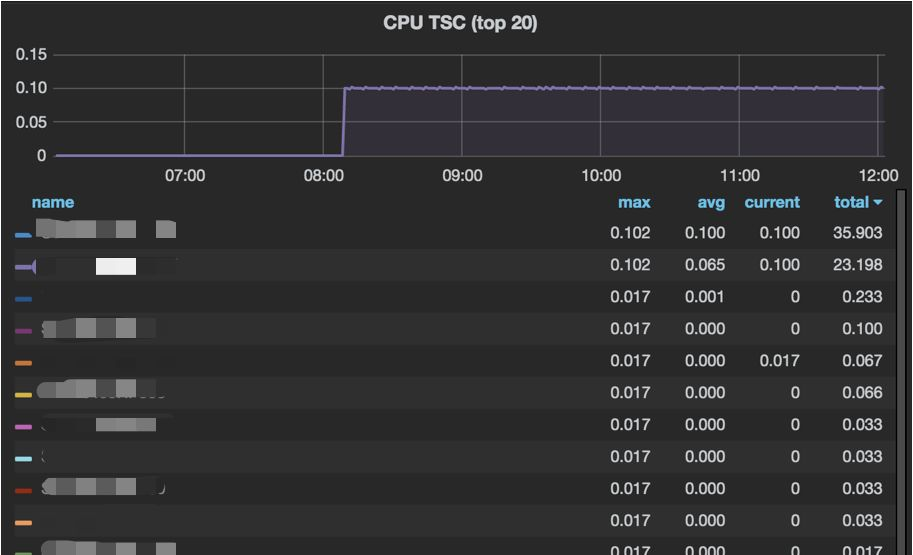
图11
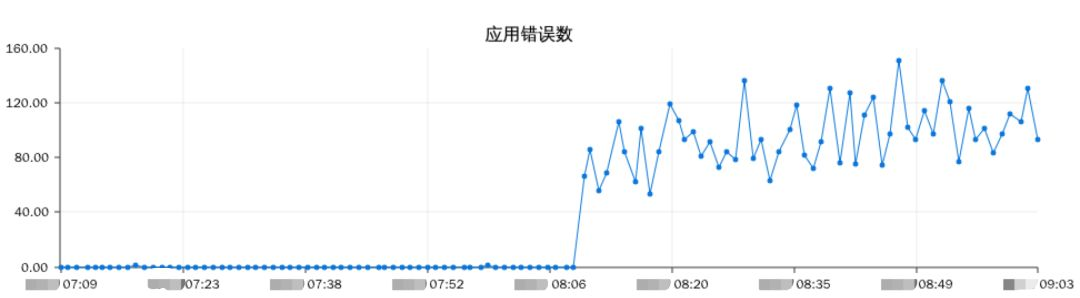
图12
将采集的日志这样展示后,我们一眼就发现问题都集中在某几批次的同一厂商的宿主机上,并且我们找到之前DBA卡顿的物理机,也是这几批次中的一台。我们收集了几台宿主机的日志详情,反馈给厂商后,确认是硬件故障,无规律并且随时可能触发,需升级BIOS,如图13厂商技术人员答复的邮件所示,至此问题得到最终解决。

图13
总结
本系列的两篇文章基本上描述了我们遇到的容器偶发性超时问题分析的大部分过程,但排障过程远比写出来要艰难。
总的原则还是大胆假设,小心求证,设法找到无规律中的规律性,保持细致耐心的钻研精神,相信这些疑难杂症终会被一一解决。
【推荐阅读】

关注“携程技术中心”公众号
了解携程技术一手动态
