

摘要: 原创出处 www.iocoder.cn/Elastic-Job… 「芋道源码」欢迎转载,保留摘要,谢谢!
本文基于 Elastic-Job V2.1.5 版本分享
1. 概述
在分布式的场景下由于网络、时钟等原因,可能导致 Zookeeper 的数据与真实运行的作业产生不一致,这种不一致通过正向的校验无法完全避免。需要另外启动一个线程定时校验注册中心数据与真实作业状态的一致性,即维持 Elastic-Job 的最终一致性。
涉及到主要类的类图如下( 打开大图 ):
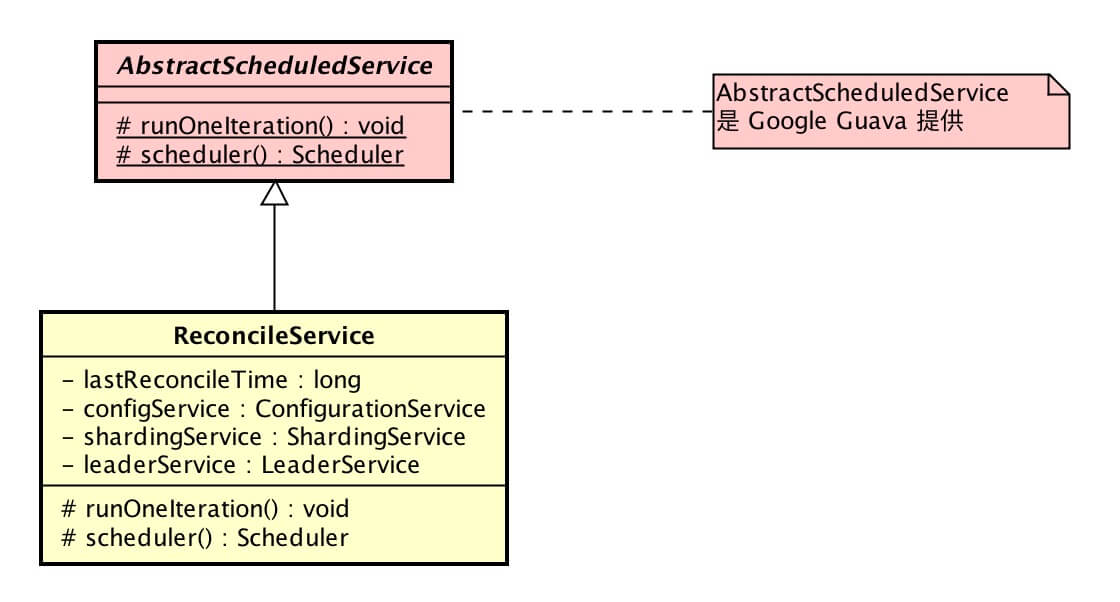
- 在 Elastic-Job-lite 里,调解分布式作业不一致状态服务( ReconcileService ) 实现了自诊断修复功能。
你行好事会因为得到赞赏而愉悦
同理,开源项目贡献者会因为 Star 而更加有动力
为 Elastic-Job 点赞!传送门
2. ReconcileService
ReconcileService,调解分布式作业不一致状态服务。
ReconcileService 继承 Google Guava AbstractScheduledService 抽象类,实现 #scheduler()、#runOneIteration() 方法,达到周期性校验注册中心数据与真实作业状态的一致性。
#scheduler() 方法实现如下:
// ReconcileService.java
@Override
protected Scheduler scheduler() {
return Scheduler.newFixedDelaySchedule(0, 1, TimeUnit.MINUTES);
}
- 每 1 分钟会调用一次
#runOneIteration()方法进行校验。 - Google Guava AbstractScheduledService 相关的知识,有兴趣的同学可以自己 Google 学习哟。
#runOneIteration() 方法实现如下:
// ReconcileService.java
@Override
protected void runOneIteration() throws Exception {
LiteJobConfiguration config = configService.load(true);
int reconcileIntervalMinutes = null == config ? -1 : config.getReconcileIntervalMinutes();
if (reconcileIntervalMinutes > 0 && (System.currentTimeMillis() - lastReconcileTime >= reconcileIntervalMinutes * 60 * 1000)) { // 校验是否达到校验周期
// 设置最后校验时间
lastReconcileTime = System.currentTimeMillis();
if (leaderService.isLeaderUntilBlock() // 主作业节点才可以执行
&& !shardingService.isNeedSharding() // 当前作业不需要重新分片
&& shardingService.hasShardingInfoInOfflineServers()) { // 查询是包含有分片节点的不在线服务器
log.warn("Elastic Job: job status node has inconsistent value,start reconciling...");
// 设置需要重新分片的标记
shardingService.setReshardingFlag();
}
}
}
- 通过作业配置,设置修复作业服务器不一致状态服务调度间隔时间属性(
LiteJobConfiguration.reconcileIntervalMinutes)。 - 调用
ShardingService#setReshardingFlag()方法,设置需要重新分片的标记。这个也是 ReconcileService 最本质的行为,有了这个标记后,作业会重新进行分片,达到作业节点本地分片数据与 Zookeeper 数据一致。作业分片逻辑,在《Elastic-Job-Lite 源码分析 —— 作业分片》有详细解析。 -
调解分布式作业不一致状态服务一共有三个条件:
- 调用
LeaderService#isLeaderUntilBlock()方法,判断当前作业节点是否为主节点。在《Elastic-Job-Lite 源码分析 —— 主节点选举》有详细解析。 - 调用
ShardingService#isNeedSharding()方法,判断当前作业是否需要重分片。如果需要重新分片,就不要重复设置当前作业需要重新分片的标记。 -
调用
ShardingService#hasShardingInfoInOfflineServers()方法,查询是否包含有分片节点的不在线服务器。永久数据节点/${JOB_NAME}/sharding/${ITEM_INDEX}/instance存储分配的作业节点主键(${JOB_INSTANCE_ID}), 不会随着作业节点因为各种原因断开后会话超时移除,而临时数据节点/${JOB_NAME}/instances/${JOB_INSTANCE_ID}会随着作业节点因为各种原因断开后超时会话超时移除。当查询到包含有分片节点的不在线的作业节点,设置需要重新分片的标记后进行重新分片,将其持有的作业分片分配给其它在线的作业节点。// ShardingService.java /** * 查询是包含有分片节点的不在线服务器. * * @return 是包含有分片节点的不在线服务器 */ public boolean hasShardingInfoInOfflineServers() { List<String> onlineInstances = jobNodeStorage.getJobNodeChildrenKeys(InstanceNode.ROOT); // `/${JOB_NAME}/instances/${JOB_INSTANCE_ID}` int shardingTotalCount = configService.load(true).getTypeConfig().getCoreConfig().getShardingTotalCount(); for (int i = 0; i < shardingTotalCount; i++) { if (!onlineInstances.contains(jobNodeStorage.getJobNodeData(ShardingNode.getInstanceNode(i)))) { // `/${JOB_NAME}/sharding/${ITEM_INDEX}/instance` return true; } } return false; }
- 调用
666. 彩蛋
芋道君:【动作:一脚踢开旁白君】,这是对前面解析的主节点选举和作业分片的复习!不是水更!
旁白君:你承认水…【动作:芋道君又来一记千年杀】
道友,赶紧上车,分享一波朋友圈!
