前言
相信爬虫(网络爬虫)是开发者们耳熟能详的数据采集技术。其中基于 Python Twisted 异步框架的 Scrapy,是灵活且强大的爬虫框架。而 Scrapyd 是 Scrapy 默认的爬虫管理服务,能够简单的执行、监控爬虫任务,除此之外,Scrapyd 还支持爬虫版本管理功能。后来基于 Scrapyd 的爬虫平台如雨后春笋般涌现出来,前有 SpiderKeeper,后有 Scrapydweb、Gerapy,都是比较优秀的开源爬虫管理平台,但它们都有个共同的问题,就是不能运行 Scrapy 以外的爬虫,导致灵活性不高。去年 3 月开源的分布式爬虫管理平台 Crawlab 就解决了这个问题,主要是通过支持 shell 命令来运行爬虫,因此理论上可以运行任何爬虫。本篇文章将介绍 Crawlab 的新发布功能:Git 集成。这将有效的将爬虫管理很好的集成到 DevOps CI/CD 工作流中。
Crawlab 简介
Crawlab 非常全面,有精美的界面和强大的功能,但有一个缺点,就是无法有效进行爬虫的版本控制。因此,在新版本发布之前,Crawlab 一直无法很好的将爬虫管理集成到 DevOps 工作流中。如果对 DevOps 不了解,可以参考《用开源软件打造企业级 DevOps 工作流(一):概述》这篇文章。在 v0.4.7 版本中,Crawlab 加入了 Git 功能,支持简单的从 Git 仓库同步代码的功能;在 v0.4.8 版本中,Crawlab 又加入了 Log 功能,支持查看 提交(Commits)、分支(Branches)和标签(Tags),并且可以将当前工作树(Work-Tree)切换(Checkout)到任意的 Commit 中。Git 是非常强大的版本控制系统(VCS),我们在《用开源软件打造企业级 DevOps 工作流(二):版本控制》这篇文章中着重介绍了 Git 的功能和用途。而 Crawlab 集成了 Git 做版本控制,这比 Scrapyd 单纯做版本控制要灵活和强大。
当然,Crawlab 不仅仅单纯做版本控制,其核心功能是爬虫管理。如果对 Crawlab 不了解的开发者可以查看 Github 主页 和 官方文档。
Git 集成原理
在开发 Crawlab 的过程中,我们收集了非常多的反馈。其中一个比较常见的问题就是“能否集成 Git”到Crawlab中。这其实很自然,因为我们可以根据这个需求了解到不少爬虫工程师是用 Git 来做版本管理的,这个开发习惯很好,减少了很多因为人为因素导致的管理成本,包括花大量时间回溯代码、环境隔离等等。因此,我们在最新的 2 个版本中开发了 Git 功能,包括 Git 的代码获取和版本切换,这些都让爬虫的版本管理变得轻松。
下图是 Crawlab 的 Git 集成原理示意图。
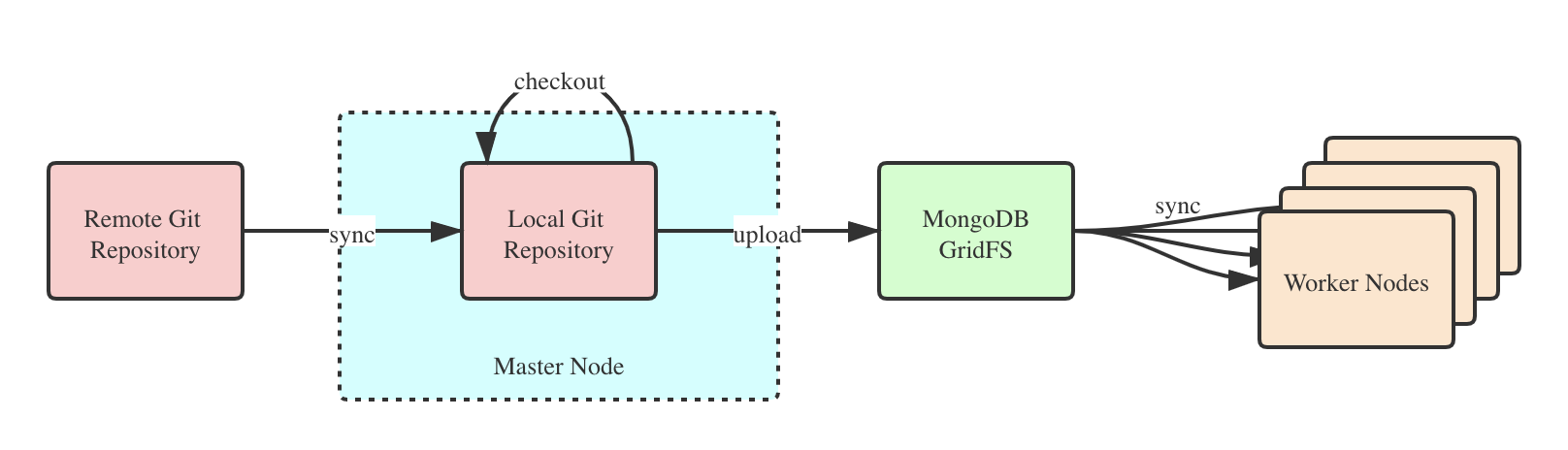
从上图可以看到,集成的步骤如下:
- 主节点(Master Node)从远端 Git 仓库(Remote Git Repository)同步代码到本地仓库(Local Git Repository);
- 主节点将本地仓库的打败打包上传到 MongoDB GridFS;
- 工作节点(Worker Nodes)通过 MongoDB GridFS 同步代码到本地;
- 如果用户希望切换(Checkout)到某一个版本或提交(Commit),只需要执行 Checkout 操作,让主节点将 Work-Tree 指向到目标 Commit,然后主节点重复步骤 2-3 来完成爬虫代码同步。
Git 集成使用
下面简单介绍一下 Crawlab 的 Git 集成方法。我们只需要在界面上就可以完成操作。
打开 Git 属性
首先,我们需要配置 Git 的信息。创建一个 Git 爬虫或打开爬虫的 Git 属性。

配置 Git 信息
开启 Git 之后,您可以在爬虫详情中看到 “Git 设置” 标签,点开的界面如下图。
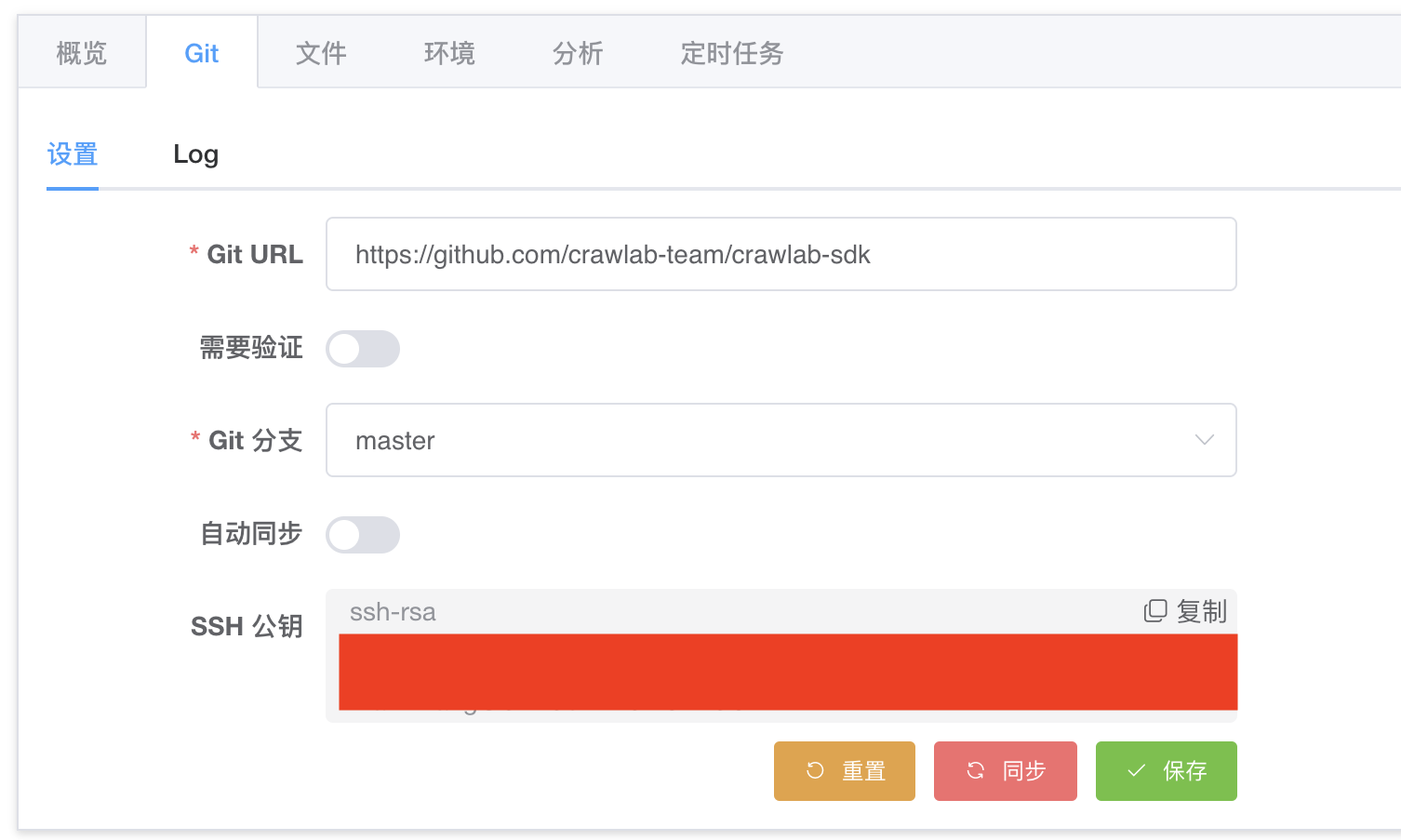
Crawlab 的 Git 同步是同时支持 HTTP 和 SSH 的。
如果您是 HTTP,您可以这样操作:
- 将仓库地址填写在
Git URL输入框; - 然后点开
需要验证,并填写验证信息; - 选择
Git 分支; - 点击
保存按钮。
如果您是 SSH,您可以这样操作:
- 点击
复制按钮,将SSH 公钥加入到 Git 服务(您可以网上搜索一下如何在 Git 服务中添加 SSH 公钥); - 将仓库地址填写在
Git URL输入框; - 选择
Git 分支; - 点击
保存按钮。
自动同步
如果您需要自动同步,您可以打开 “自动同步” 开关,然后选择同步频率。这样,Git 上的爬虫代码一旦有更新,Crawlab 就会按照同步频率自动将其同步回来。
手动同步
点击红色的 “同步” 按钮并确认,即可手动同步 Git 仓库的爬虫代码。
重置
有时候您需要重置代码,也就是清除该仓库的所有代码,只需要点击 “重置” 按钮并确认。
查看版本
在 Log 标签中,您可以看到所有的 Commits,以及其对应的分支(Branches)和版本(Tags),以及谁提交的代码,如下图所示。
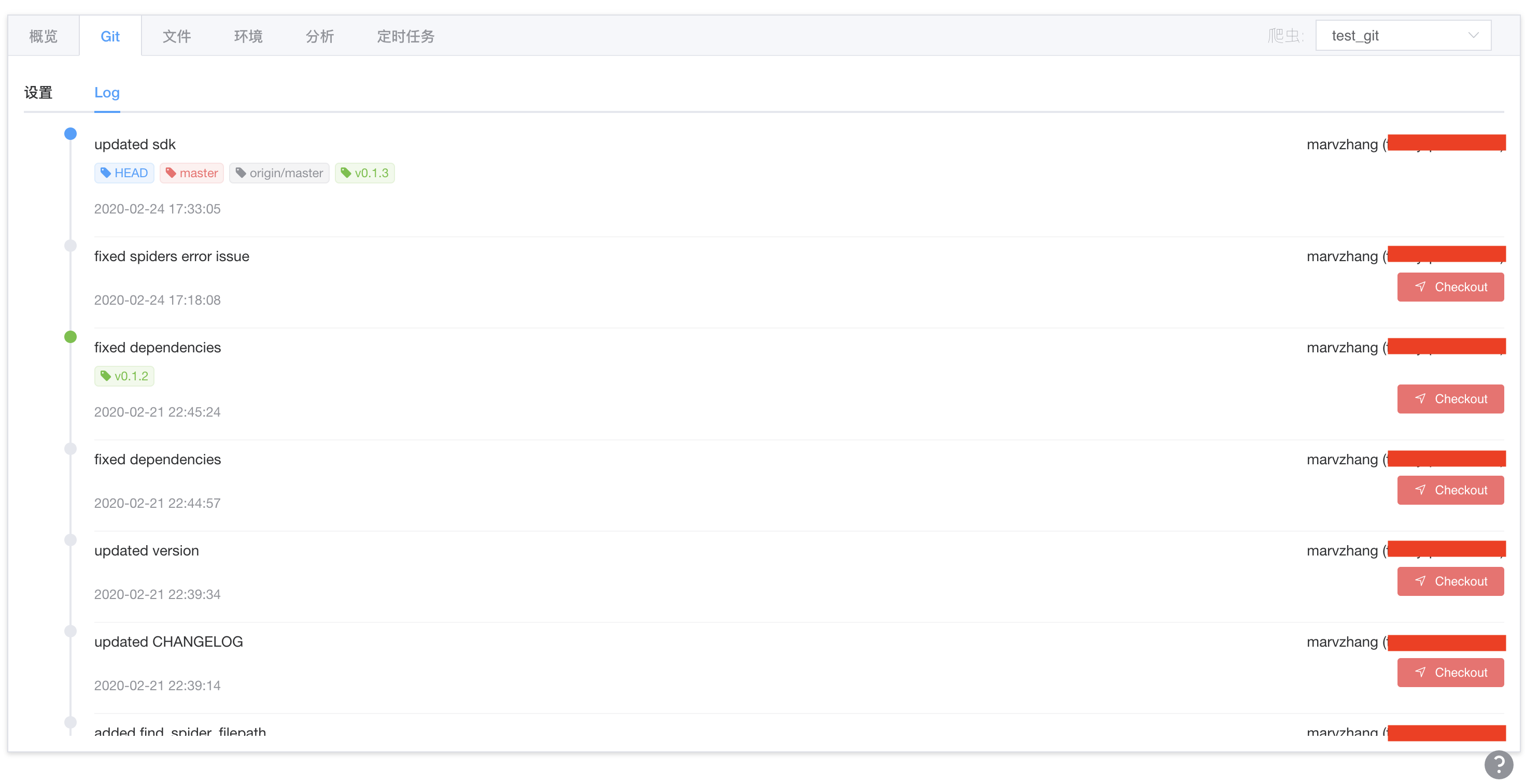
切换版本
同样是在 Log 标签,您可以看到每一个提交(Commit)右下方有一个红色的 Checkout 按钮,点击它即可将爬虫代码切换到该版本。
总结
本文从 Scrapy、Scrapyd 开始,论述了在爬虫管理中集成版本控制系统、引入 DevOps 工作流的重要性。同时,也介绍了强大而灵活的分布式爬虫管理平台 Crawlab。进一步,我们还介绍了 Crawlab 的新特性,即集成 Git 到 CI/CD 工作流,包括其原理和如何使用。相信做过大型项目的开发者对版本控制有着极高的需求。这同样适用于爬虫开发,因为爬虫很多时候会因为各种各样的原因(例如网站样式改变)而需要进行变更,如果将版本控制应用在爬虫管理中,将会很大程度提高爬虫应用的质量和可维护性。同时,如果您在 Crawlab 的 Git 设置中打开了自动同步功能,Crawlab 就不需要手动上传代码,它会自动从 Git 仓库获取代码,是不是很省时间和精力?因此,我推荐每一个爬虫开发工程师都将 Git 版本管理应用在自己的爬虫应用中。
项目地址
- Github: github.com/crawlab-tea…
- Demo: crawlab.cn/demo
- 文档: docs.crawlab.cn
社区
如果您觉得 Crawlab 对您的日常开发或公司有帮助,请加作者微信 tikazyq1 并注明 "Crawlab",作者会将你拉入群。欢迎在 Github 上进行 star,以及,如果遇到任何问题,请随时在 Github 上提 issue。另外,欢迎您对Crawlab 做开发贡献。