


-
集群中随机出现。问题随机出现在该应用集群中的一个或几个实例中,无法提前预知其出现规律。
-
单机出现时间不可预知,现场捕捉困难,捕捉风险大,一般发现已经为事后,无现场第一手数据。从单个机器,或者单个实例看,则是出现概率非常低,出现时间完全随机。这使得蹲点单台机器以捕捉这个问题的思路几乎行不通,策略扩大至整个集群又可能出现稳定性及性能问题。
-
问题出现频率低。出现频率大概在一到两天一次。
-
问题表现复杂。该问题的表现很复杂,不仅从第一眼看去不合常理,JVM内部出现了大量线程在等待一把没有任何线程持有的锁。另外,问题机器的负载非常低,基本上在5%以内,相当于空载,而JVM中线程数却非常多,最多发现过接近4k个线程。
-
问题周边环境复杂。该问题出现前后,应用先后引入了rxjava、协程,应用为早期应用,服务结构复杂,而log4j问题又和网上大量的文章情形不符。
-
验证困难。理论分析完成后,无法在线上复现及验证,安全性、稳定性、数据等都不允许直接在线上验证。
 一般来说,定位问题主要有两个分类,即时定位,事后定位。前一种是指我们实时直接监控JVM信息,在关键信息异常时,即发生动作。配合周期性的信息采集,基本可以对问题发生时刻前后数据精准采集和对比,做法一般是采用JVM代理方式或JMS方式。JVM代理分为C语言和Java语言代理,C语言代理运行在JVM层,可以做到即时Java代码发生故障故障,依然可以正常采集信息。Java代理相对C语言代理来说编写起来方便,实际上C语言部分任务还是通过JNI接口构造Java对象执行的。JMS方式可以实时采集各种指标,也是目前监控主要采用等方式。缺点是对应用的侵入性非常大,不适合解决问题用。事后定位是指通过日志监控等较缓慢的方式去对问题发生时刻定位,由于该问题的特殊性,日志无法提供需要的信息以判断故障,另外,日志无法采集我们需要的信息,尤其是JVM内部线程和锁的信息。在后续现象的观察中,发现了一个比较普遍的现象,应用由正常转为故障需要一个漫长的时间,应用可能在临界区停留相当长的时间,极端例子中应用在线程数提升后依然能够正常运行接近24小时,之后发生了自恢复。另外,在和JVM组同学对接的时候,又被告知阿里jdk对C代理支持可能由于安全原因被关闭。基本上宣布这个问题的研究进入了下一个阶段。
step3. io hang
考虑到大部分实例业务日志打印缓慢或者根本不再打印,可能原因是io方面出了问题,通过查看容器硬件监控及应用火焰图,可以轻松将IO问题排除。
一般来说,定位问题主要有两个分类,即时定位,事后定位。前一种是指我们实时直接监控JVM信息,在关键信息异常时,即发生动作。配合周期性的信息采集,基本可以对问题发生时刻前后数据精准采集和对比,做法一般是采用JVM代理方式或JMS方式。JVM代理分为C语言和Java语言代理,C语言代理运行在JVM层,可以做到即时Java代码发生故障故障,依然可以正常采集信息。Java代理相对C语言代理来说编写起来方便,实际上C语言部分任务还是通过JNI接口构造Java对象执行的。JMS方式可以实时采集各种指标,也是目前监控主要采用等方式。缺点是对应用的侵入性非常大,不适合解决问题用。事后定位是指通过日志监控等较缓慢的方式去对问题发生时刻定位,由于该问题的特殊性,日志无法提供需要的信息以判断故障,另外,日志无法采集我们需要的信息,尤其是JVM内部线程和锁的信息。在后续现象的观察中,发现了一个比较普遍的现象,应用由正常转为故障需要一个漫长的时间,应用可能在临界区停留相当长的时间,极端例子中应用在线程数提升后依然能够正常运行接近24小时,之后发生了自恢复。另外,在和JVM组同学对接的时候,又被告知阿里jdk对C代理支持可能由于安全原因被关闭。基本上宣布这个问题的研究进入了下一个阶段。
step3. io hang
考虑到大部分实例业务日志打印缓慢或者根本不再打印,可能原因是io方面出了问题,通过查看容器硬件监控及应用火焰图,可以轻松将IO问题排除。
 step4. 锁分析
锁问题主要包含死锁和丢锁。死锁的特点很明显,一旦发生死锁,则与该锁相关的线程都将停止。首先这点和大量实例运行缓慢不符,其次,这个问题可以轻易通过stack文件排除。丢锁主要和协程有关,和死锁相似,考虑到协程可能在切换过程中发生丢锁,造成的现象和该问题很类似,即没有线程持有的锁。丢锁最主要的问题也是不可恢复,一旦丢锁,则JVM相关线程就永远不可恢复,和该问题不符。另外,观察大部分stack文件发现,此时JVM中的协程数量并不多,线程池Worker实例也在变化。
step4. 锁分析
锁问题主要包含死锁和丢锁。死锁的特点很明显,一旦发生死锁,则与该锁相关的线程都将停止。首先这点和大量实例运行缓慢不符,其次,这个问题可以轻易通过stack文件排除。丢锁主要和协程有关,和死锁相似,考虑到协程可能在切换过程中发生丢锁,造成的现象和该问题很类似,即没有线程持有的锁。丢锁最主要的问题也是不可恢复,一旦丢锁,则JVM相关线程就永远不可恢复,和该问题不符。另外,观察大部分stack文件发现,此时JVM中的协程数量并不多,线程池Worker实例也在变化。
step5. 资源耗尽查看
资源耗尽是指JVM运行过程中由于部分资源紧张,程序虽然可以正常运行,但是限于部分资源紧张,必须等待其他线程释放了持有资源后,当前线程才可以继续运行。资源包括软件资源和硬件资源。软件资源是指在JVM运行过程中,有设定上限的软件资源,如堆、Reserved Code Cache、元数据区等,在实际观察中,发现上述资源均未出现明显的资源耗尽情况。硬件资源主要分析在JVM运行过程中,所在机器硬件资源如CPU、内存、网络等硬件资源使用情况。其中,在观察中发现,内存资源出现了明显的问题,由于问题机器线程数大幅增加,导致问题机器JVM总使用内存超出了机器的物理内存。加上监控进程与机器本身的进程,很容易得出一个结论,JVM此时在将部分资源扇出至page页。实际上,JVM此时在部分基于硬盘运行。如果此时JVM进行一个牵涉面很广的抢锁任务,那么就有可能发生悲剧。而在该问题中,应用采用了log4j作为日志记录工具,查看相关源码可以看出,log4j采用了java monitor来控制日志打印,防止日志结构混乱及数据破坏。而作为流量入口日志,所有的业务线程都会进行进行打印,因此也会进行抢锁。
publicvoid
callAppenders(LoggingEvent event) {
int
writes = 0;
for
(Category c =
this; c != null
; c = c.parent) {
// Protected against simultaneous call to addAppender, removeAppender,...
synchronized
(c) {
if
(c.aai != null) {
writes += c.aai.appendLoopOnAppenders(event);
}
if
(!c.additive) {
break
;
}
}
}
if
(writes == 0) {
repository.emitNoAppenderWarning(
this);
}
}
for
(p = w ; p != NULL ; p = p->_next) {
guarantee (p->
TState== ObjectWaiter
::TS_CXQ, "Invariant") ;
p->
TState= ObjectWaiter
::TS_ENTER ;
p->_prev = q ;
q = p ;
}
// Prepend the RATs to the EntryList
if
(_EntryList!= NULL) {
q->_next =
_EntryList;
_EntryList
->_prev = q ;
}
step6. 框架层源码阅读
在前面步骤中大致定位了一个大的方向,线程数增加导致内存不足。接下来需要深入框架层去分析 引起线程数增加的可能原因。先后对HSF、Modulet、Mtop、netty等框架进行了源码级别的分析,主要跟踪各个框架 线程分配策略。其中,HSF默认设置的线程池模型扰动抗性很低。在HSF框架中,netty线程池将任务提交到HSF Provider线程池,HSF Provider线程池采用业务隔离设计,在一次对外服务中,HSF Provider大量调用HSF Consumer,而Consumer会被提交至Consumer线程池中执行。在该应用中,Provider和Consumer线程池容量比例大于200:1。
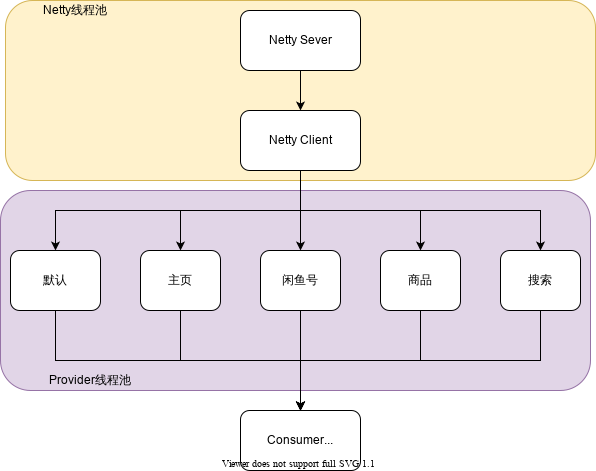
而根据业务实际,合理的比例应该在1:1附近。
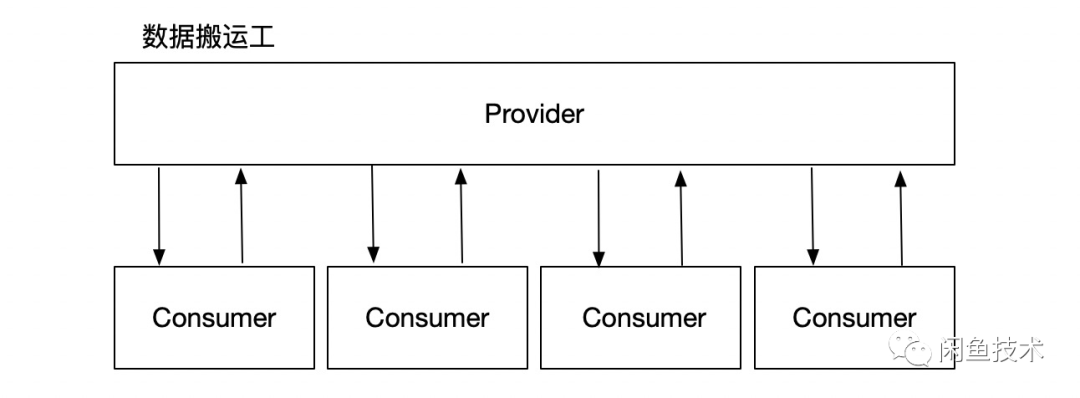
失衡的线程池结构,极容易服务发生网络抖动、回环调用时使Consumer线程池服务能力下降,进而使整个应用实例对外服务能力下降。而有规律的故障不应该和无规律的抖动有关。
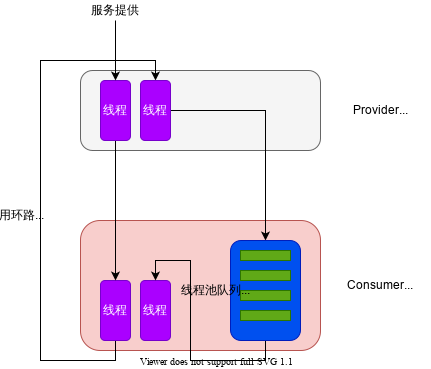
回环与问题出现频率之间读者可以通过概率论进行分析,假定100台机器,则每次请求会有1/100的概率发生回环,同理,每10000次请求就会发生双回环,1M次请求则是3回环。在该问题中,概率论分析和实际情况是契合的。
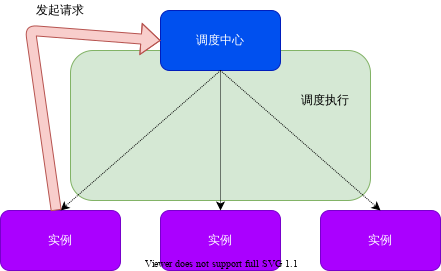
在研究框架层的时候,发现了回环调用对系统的危害。但是还有一个疑问需要回答, 回环调用完成后,应用应该能恢复 ,而线上实际情况是,自恢复是个小概率事件。结合前一节可以得出一个结论,回环调用使应用Consumer线程池处理能力下降,进而使 上游线程池水位逐渐提升直至被打满。 而数量过度增加的线程池使得内存资源紧张,导致JVM基于磁盘运行而抢锁困难,抢锁过程的拉长使得 没有任何线程持有锁这个常规状态下的瞬时状态被拉长,JVM服务能力大打折扣,而duct平台由于策略原因不能应对该问题的特殊情况导致其无法启动切流,流量照常打入JVM。于是就形成了一个恶性循环,线程数提升导致JVM进入一种非常规状态,服务能力下降,而流量照常,导致线程数很难下降。于是,JVM长时间运行在一个非常缓慢的状态,从表现上来看就是 jvm挂起。下表为一个较有代表性的流量对比(实际上故障机状态跨度非常大,这两台机器 较为典型而已)

实验验证
接下来,本文采用阿里PAS压测平台,对预发机器进行了压测验证。由于线上问题复杂,无法复现线上的环境,只能对其诱因进行验证。下表为压测过程中应用的性能表现。由于压测模式限制,所支持的最大tps在超时的情况下非常低,如表所示只有80左右,考虑到压测环境机器数量,回环数量还要打折。
 从下图可以看出,平均RT为2500ms左右,绝大多数请求都在超时状态。
从下图可以看出,平均RT为2500ms左右,绝大多数请求都在超时状态。
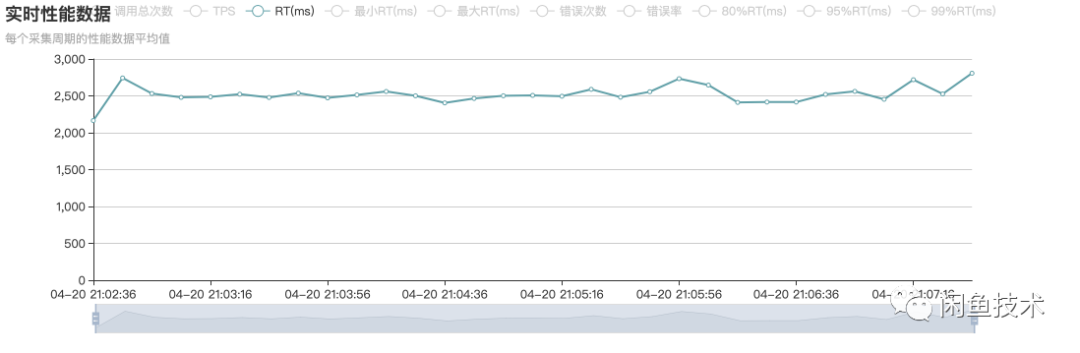 压测结果表明,回环不需要多高的流量,就能把应用实际服务能力大打折扣。考虑到线上还有其他类型的请求,填充在回环之间,这会使线程池迅速打满,并使得处理回环请求的时间加长,恶化应用从回环调用中恢复的能力。
总结和思考
在JVM出现问题的时候,首先要阅读业务代码,这个虽然看似作用不大,却有可能以相当低廉的代价解决问题。之后,主要思路就是捕获现场,现场捕获将极大程度上有助于问题的解决。如果该步骤不可行,或者成本相对较高,可以先去排查周边原因。这主要包括IO、锁、硬软件资源,在执行这些排查的时候,要留意这些方面出问题的表现和实际问题的表现契合度。比较明显的就是一旦死锁、丢锁,或者IO
hang,则程序无法从故障状态恢复,相关线程也不能继续执行。这些特点可以协助排除部分大的方向。最后,对资源耗尽的排查,则是基于本文所述问题的一个基本特点,绝大多数JVM运行缓慢而不是停止运行。所以,资源紧张成为一个解决问题的大方向,并最终定位了问题。深入到框架层主要是从理论上分析问题产生的原因,然后在结合实际情况,分析整个解决思路的正确性。读者在遇到类似JVM问题时,可参考本文所述的方法与步骤,对实际问题进行分析与研究。
压测结果表明,回环不需要多高的流量,就能把应用实际服务能力大打折扣。考虑到线上还有其他类型的请求,填充在回环之间,这会使线程池迅速打满,并使得处理回环请求的时间加长,恶化应用从回环调用中恢复的能力。
总结和思考
在JVM出现问题的时候,首先要阅读业务代码,这个虽然看似作用不大,却有可能以相当低廉的代价解决问题。之后,主要思路就是捕获现场,现场捕获将极大程度上有助于问题的解决。如果该步骤不可行,或者成本相对较高,可以先去排查周边原因。这主要包括IO、锁、硬软件资源,在执行这些排查的时候,要留意这些方面出问题的表现和实际问题的表现契合度。比较明显的就是一旦死锁、丢锁,或者IO
hang,则程序无法从故障状态恢复,相关线程也不能继续执行。这些特点可以协助排除部分大的方向。最后,对资源耗尽的排查,则是基于本文所述问题的一个基本特点,绝大多数JVM运行缓慢而不是停止运行。所以,资源紧张成为一个解决问题的大方向,并最终定位了问题。深入到框架层主要是从理论上分析问题产生的原因,然后在结合实际情况,分析整个解决思路的正确性。读者在遇到类似JVM问题时,可参考本文所述的方法与步骤,对实际问题进行分析与研究。
闲鱼技术团队不仅是阿里巴巴集团旗下闲置交易社区的创造者,更是移动与高并发大数据应用新技术的引导者与创新者。我们与 Google Flutter/Dart小组密切合作,为社区贡献了多个高 star的项目和大量 PR。我们正在积极探索深度学习和视觉技术在互动、交易、社区场景的创新应用。闲鱼技术与集团中间件团队共同打造的 FaaS平台每天支持数以千万级用户的高并发访问场景。
就是现在! 客户端/服务端java/架构/前端/质量 工程师面向社会+校园招聘,base杭州阿里巴巴西溪园区,一起做有创想空间的社区产品、做深度顶级的开源项目,一起拓展技术边界成就极致!
*投喂简历给小闲鱼→ guicai.gxy@alibaba-inc.com

 开源项目、峰会直击、关键洞察、深度解读
请认准
闲鱼技术
开源项目、峰会直击、关键洞察、深度解读
请认准
闲鱼技术
