

前言
任何一个Android 开发者对AsnycTask 都应该不陌生;使用AsyncTask可以很方便的异步处理耗时操作;AsyncTask内部对Handler和Thread进行了封装,简化了Handler的使用方式,使用起来非常方便。首先看一下Android SDK 中关于AsyncTask的使用示例:
private class DownloadFilesTask extends AsyncTask<URL, Integer, Long> {
protected Long doInBackground(URL... urls) {
int count = urls.length;
long totalSize = 0;
for (int i = 0; i < count; i++) {
totalSize += Downloader.downloadFile(urls[i]);
publishProgress((int) ((i / (float) count) * 100));
// Escape early if cancel() is called
if (isCancelled()) break;
}
return totalSize;
}
protected void onProgressUpdate(Integer... progress) {
setProgressPercent(progress[0]);
}
protected void onPostExecute(Long result) {
showDialog("Downloaded " + result + " bytes");
}
}在onCreate中,执行这个任务即可:
new DownloadFilesTask().execute(url1, url2, url3);使用起来,的确是很方便(当然和当下非常流行的Retrofit、Volley相比还是有些繁琐)。
但是你想过下面这些问题吗;为什么doInBackground就可以用来进行耗时操作?为什么onPostExecute和onProgressUpdate就可以进行UI更新?是谁规定了这些方法处于UI线程的?publishProgress 传递的参数是怎样来到onProgressUpdate方法中的?怎样取消一个正在执行的耗时操作?如果你自己去封装Handler和Thread你会怎么做?
好了,带着这些疑问,让我们去看看AsyncTask的实现原理。
AsyncTask的实现原理可以说是十分巧妙,整个代码除去注释仅有300多行,但功能却非常强大,原因就是他用到了Java自带的并发工具包 java.util.concurrent,这个包包含有一系列能够让 Java 的并发编程变得更加简单轻松的类。好了为了方便理解AsyncTask的实现原理,先普及一波AsyncTask中用到一些java基础知识。
基础知识
阻塞队列 BlockingQueue
BlockingQueue 通常用于一个线程生产对象,而另外一个线程消费这些对象的场景。下图是对这个原理的阐述:
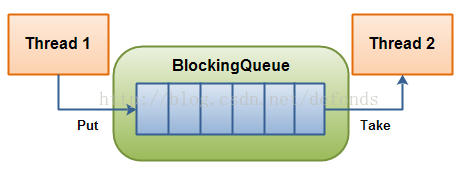
一个线程往里边放,另外一个线程从里边取的一个 BlockingQueue。
一个线程将会持续生产新对象并将其插入到队列之中,直到队列达到它所能容纳的临界点。也就是说,它是有限的。如果该阻塞队列到达了其临界点,负责生产的线程将会在往里边插入新对象时发生阻塞。它会一直处于阻塞之中,直到负责消费的线程从队列中拿走一个对象。
负责消费的线程将会一直从该阻塞队列中拿出对象。如果消费线程尝试去从一个空的队列中提取对象的话,这个消费线程将会处于阻塞之中,直到一个生产线程把一个对象丢进队列。
链阻塞队列 LinkedBlockingQueue
LinkedBlockingQueue 类实现了 BlockingQueue 接口。
LinkedBlockingQueue 内部以一个链式结构(链接节点)对其元素进行存储。如果需要的话,这一链式结构可以选择一个上限。如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限。
LinkedBlockingQueue 内部以 FIFO(先进先出)的顺序对元素进行存储。队列中的头元素在所有元素之中是放入时间最久的那个,而尾元素则是最短的那个。
ArrayDeque
数组队列 ArrayDeque的特点
- 大小自增长的队列
- 内部使用数组存储数据
- 线程不安全
- 内部数组长度为8、16、32….. 2的n次方
- 头指针head从内部数组的末尾开始,尾指针tail从0开始,在头部插入数据时,head减一,在尾部插入数据时,tail加一。当head==tail时说明数组的容量满足不了当前的情况,此时需要扩大容量为原来的二倍。
执行器服务 ExecutorService
java.util.concurrent.ExecutorService 接口表示一个异步执行机制,使我们能够在后台执行任务。因此一个 ExecutorService 很类似于一个线程池。
ExecutorService 简单实现
ExecutorService executorService = Executors.newFixedThreadPool(10);
executorService.execute(new Runnable() {
public void run() {
System.out.println("Asynchronous task");
}
});
executorService.shutdown();首先使用 newFixedThreadPool() 工厂方法创建一个 ExecutorService。这里创建了一个十个线程执行任务的线程池。
然后,将一个 Runnable 接口的匿名实现类传递给 execute() 方法。这将导致 ExecutorService 中的某个线程执行该 Runnable。
线程池执行者 ThreadPoolExecutor
java.util.concurrent.ThreadPoolExecutor 是 ExecutorService 接口的一个实现。ThreadPoolExecutor 使用其内部池中的线程执行给定任务(Callable 或者 Runnable)。
构造方法:
//构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}下面看看几个参数的含义及作用
- corePoolSize — 核心线程数,即允许闲置的线程数目
- maximumPoolSize — 最大线程数,即这个线程池的容量
- keepAliveTime — 非核心线程的闲置存活时间
- unit — 上一个参数的单位
- workQueue — 任务队列(阻塞队列)
- threadFacotry — 线程创建工厂
- handler — 当线程池或者任务队列容量已满时用于 reject
Callable&&Future
提到Callable 可能觉得比较陌生,但是Runnable大家应该很熟悉;这么说吧,Callable就是带返回值的Runnable。Callable声明如下:
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}返回值就是Callable 传入的泛型参数的类型。而这个返回值就由Future获取。
FutureTask
FutureTask则是一个RunnableFuture,而RunnableFuture实现了Runnbale又实现了Futrue这两个接口
public class FutureTask<V> implements RunnableFuture<V>
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}另外它还可以包装Runnable和Callable, 由构造函数注入依赖。
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}下面用一个简单的demo,介绍一下Callable与FutureTask的使用
/**
* 定义一个Callable 任务,返回类型为Integer
*/
public class CallableTask implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int hours=5;
int amount = 0;
while(hours>0){
System.out.println("I'm working,rest is "+hours);
amount++;
hours--;
Thread.sleep(1000);
}
return amount;
}
}
public class FutureTaskTest {
public static void main(String args[]) throws ExecutionException {
CallableTask worker = new CallableTask();
FutureTask<Integer> mTasks = new FutureTask<>(worker);
new Thread(mTasks).start();
while (!mTasks.isDone()) {
try {
System.out.println("job has't finsished ..." + mTasks.get());
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
int amount;
try {
amount = mTasks.get();
System.out.println("Job finished commited " + amount);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}我们看一下输出日志:
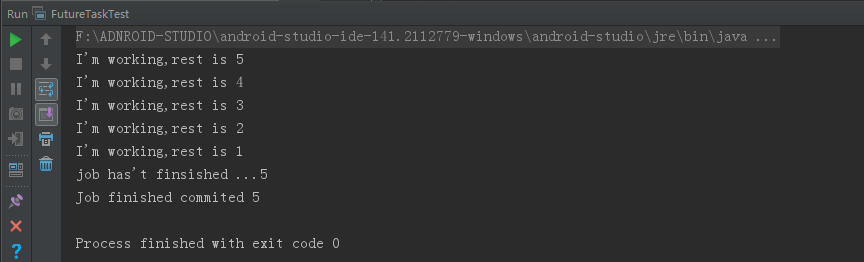
main 方法通过一个新的线程开始执行mTasks ,而mTasks 又会等待worker 的执行完毕,得到其最终执行的结果。
好了关于基础知识的了解到这里就差不多了。
AsyncTask 属性
有了一些基础知识,首先让我们看一下AsyncTask类的声明:
public abstract class AsyncTask<Params, Progress, Result> {
private static final String LOG_TAG = "AsyncTask";
//获取当前的cpu核数
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
private static final int CORE_POOL_SIZE = CPU_COUNT + 1;
private static final int MAXIMUM_POOL_SIZE = CPU_COUNT * 2 + 1;
private static final int KEEP_ALIVE = 1;
//ThreadFactory 线程工厂,通过工厂方法newThread来获取新线程
private static final ThreadFactory sThreadFactory = new ThreadFactory() {
private final AtomicInteger mCount = new AtomicInteger(1);
public Thread newThread(Runnable r) {
return new Thread(r, "AsyncTask #" + mCount.getAndIncrement());
}
};
//创建一个链式阻塞队列,默认大小128
private static final BlockingQueue<Runnable> sPoolWorkQueue =
new LinkedBlockingQueue<Runnable>(128);
/**
* 假设当前所使用手机CPU为4核,那么将创建一个
* 线程池核心容量为5
* 线程池最大容量为9
* 非核心线程空闲时间为1秒
* 任务队列大小为128 ---------- 的线程池(执行器),执行并发任务
*/
public static final Executor THREAD_POOL_EXECUTOR
= new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE,
TimeUnit.SECONDS, sPoolWorkQueue, sThreadFactory);
/**
* An {@link Executor} that executes tasks one at a time in serial
* order. This serialization is global to a particular process.
* 串行任务执行器声明
*/
public static final Executor SERIAL_EXECUTOR = new SerialExecutor();
//消息类型:发送结果
private static final int MESSAGE_POST_RESULT = 0x1;
//消息类型: 发送过程
private static final int MESSAGE_POST_PROGRESS = 0x2;
// 设置默认执行器为串行执行
private static volatile Executor sDefaultExecutor = SERIAL_EXECUTOR;
// 内部Handler实现
private static InternalHandler sHandler;
private final WorkerRunnable<Params, Result> mWorker;
//获取mWorker 执行结果;结束mWorker等功能
private final FutureTask<Result> mFuture;
//任务默认状态为挂起
private volatile Status mStatus = Status.PENDING;
//使用原子Boolean型变量,标记当前任务是否已被取消
private final AtomicBoolean mCancelled = new AtomicBoolean();
//标记当前任务是否已被执行过
private final AtomicBoolean mTaskInvoked = new AtomicBoolean();
private static class SerialExecutor implements Executor {
final ArrayDeque<Runnable> mTasks = new ArrayDeque<Runnable>();
Runnable mActive;
public synchronized void execute(final Runnable r) {
mTasks.offer(new Runnable() {
public void run() {
try {
r.run();
} finally {
scheduleNext();
}
}
});
if (mActive == null) {
scheduleNext();
}
}
protected synchronized void scheduleNext() {
if ((mActive = mTasks.poll()) != null) {
THREAD_POOL_EXECUTOR.execute(mActive);
}
}
}
/**
* Indicates the current status of the task. Each status will be set only once
* during the lifetime of a task.
*/
public enum Status {
/**
* Indicates that the task has not been executed yet.
*/
PENDING,
/**
* Indicates that the task is running.
*/
RUNNING,
/**
* Indicates that {@link AsyncTask#onPostExecute} has finished.
*/
FINISHED,
}
}部分属性已通过注释标记,应该很容易理解;下面主要看一下以下几个声明的具体含义:
SerialExecutor 实现
SerialExecutor 串行执行的线程池,在其内部首先创建一个队列用于存储AsyncTask任务;其中execute方法的作用就是将需要执行的AsyncTask任务添加到这个队列尾部,并立即执行,执行完毕后调用scheduleNext 从队列头部获取下一个任务,如果这个任务不为空;就将任务交给THREAD_POOL_EXECUTOR去处理;这样如果同时有多个AsyncTask执行时,多个添加到mTasks的任务将通过轮询的方式逐一执行完毕,完成串行执行的功能。
WorkerRunnable
这个WorkRunnable又是什么呢?看看他的声明:
private static abstract class WorkerRunnable<Params, Result> implements Callable<Result> {
Params[] mParams;
}这个类继承了Callable,并添加了一个参数;我们知道Callable的参数类型是其call方法的返回类型,那么这个Params参数又有什么意义呢,这个我们后面再看。
最后使用枚举定义了任务的几个状态;PENDING(挂起),RUNNING (正在运行),FINISHED(已完成)。之前的代码也可以看到,默认状态为PENDING。
好了,至此已经完成了AsyncTask 类当中,大部分属性的介绍,下面就来看看他的实现原理。
AsyncTask 实现原理
回到我们一开始提到的那个示例代码,当我们定义了好自己的AsyncTask之后,要开始运行这个任务时非常简单,只需要一行代码:
new DownloadFilesTask().execute(url1, url2, url3);我们就从这行代码出发,看看发生了什么。
构造方法
首先,new DownloadFileTask() ,执行DownloadFileTask的构造方法,因此必然会执行DownloadFileTask的父类AsyncTask的构造方法,也就是 AsyncTask() :
/**
* Creates a new asynchronous task. This constructor must be invoked on the UI thread.
*/
public AsyncTask() {
mWorker = new WorkerRunnable<Params, Result>() {
public Result call() throws Exception {
//设置当前任务已被执行
mTaskInvoked.set(true);
//设置线程执行的优先级
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
//noinspection unchecked
Result result = doInBackground(mParams);
Binder.flushPendingCommands();
return postResult(result);
}
};
mFuture = new FutureTask<Result>(mWorker) {
@Override
protected void done() {
try {
postResultIfNotInvoked(get());
} catch (InterruptedException e) {
android.util.Log.w(LOG_TAG, e);
} catch (ExecutionException e) {
throw new RuntimeException("An error occurred while executing doInBackground()",
e.getCause());
} catch (CancellationException e) {
postResultIfNotInvoked(null);
}
}
};
}构造方法的工作很简单,就是完成了mWorker 和 mFuture 的初始化工作,也就是Callable和Future 的初始化,并关联他们,让mFuture 可以获取mWorker 的执行结果,或者停止mWorker 的执行。
这里主要由两个方法call()和done(),总的来说当mFuture 开始被执行的时候,call() 就会执行,当这个任务执行完毕后done()方法就会执行。
那么这个mFuture 什么 时候会被执行呢?继续往下看
任务开始真正执行
new DownloadFilesTask().execute(url1, url2, url3);继续看,上面已经完成了构造方法的执行,接下来看execute() 方法:
@MainThread
public final AsyncTask<Params, Progress, Result> execute(Params... params) {
return executeOnExecutor(sDefaultExecutor, params);
}executeOnExecutor
public final AsyncTask<Params, Progress, Result> executeOnExecutor(Executor exec,
Params... params) {
if (mStatus != Status.PENDING) {
switch (mStatus) {
case RUNNING:
throw new IllegalStateException("Cannot execute task:"
+ " the task is already running.");
case FINISHED:
throw new IllegalStateException("Cannot execute task:"
+ " the task has already been executed "
+ "(a task can be executed only once)");
}
}
mStatus = Status.RUNNING;
onPreExecute();
mWorker.mParams = params;
exec.execute(mFuture);
return this;
}到这里就很清楚了,mStatus 默认状态为PENDING,因此任务开始执行后首先将其状态改为RUNNING;同时从异常判断我们也可以看出一个AsyncTask的execute方法不能同时执行两次。
接下来,onPreExecute(),我们是在onCreate 中开启了AsyncTask的任务,因此这个时候,依旧属于主线程,onPreExecute()方法也会工作在主线程,我们可以在这个方法中执行一些预备操作,初始相关内容。
mWorker,前面已经说过他就是实现了Callable接口,并添加了一个参数属性,在这里我们把executor中传入的参数赋给了这个属性。exec=sDefaultExecutor=SerialExecutor ,这里任务就开始真正的执行了;按照之前所说就会开始执行mFuture这个任务,因此就会开始执行mWorker的call方法。
mWorker = new WorkerRunnable<Params, Result>() {
public Result call() throws Exception {
//设置当前任务已被执行
mTaskInvoked.set(true);
//设置线程执行的优先级,被设置在后台进行
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
//noinspection unchecked
Result result = doInBackground(mParams);
Binder.flushPendingCommands();
return postResult(result);
}到这里,我们终于看到了熟悉的doInBackground,这是我们必须实现的一个方法,在其中完成耗时操作,并返回结果。由于已经设置了Process的优先级,因此这个方法会处于后台进程。
在doInBackground 里,我们还可以返回当前执行进度:
protected Long doInBackground(URL... urls) {
int count = urls.length;
long totalSize = 0;
for (int i = 0; i < count; i++) {
totalSize += Downloader.downloadFile(urls[i]);
publishProgress((int) ((i / (float) count) * 100));
// Escape early if cancel() is called
if (isCancelled()) break;
}
return totalSize;
}我们调用了publishProgress 可以将doInBackground中耗时任务的进度发送出去,大家都知道这个进度会发送到onProgressUpdate() 方法中,在onProgressUpdate我们可以方便的进行UI 更新,比如进度条进度更新等。那么他是怎么实现的呢?这就要看publishProgress这个方法的实现了。
@WorkerThread
protected final void publishProgress(Progress... values) {
if (!isCancelled()) {
getHandler().obtainMessage(MESSAGE_POST_PROGRESS,
new AsyncTaskResult<Progress>(this, values)).sendToTarget();
}
}我们再来分解一下这个方法的实现:
//返回一个InternalHandler对象
private static Handler getHandler() {
synchronized (AsyncTask.class) {
if (sHandler == null) {
sHandler = new InternalHandler();
}
return sHandler;
}
}AsyncTaskResult
AsyncTaskResult 顾名思义,很好理解了,就是AsyncTask的执行结果,这是一个静态的内部类,包括两个属性mTask和mData 。
private static class AsyncTaskResult<Data> {
final AsyncTask mTask;
final Data[] mData;
AsyncTaskResult(AsyncTask task, Data... data) {
mTask = task;
mData = data;
}
}因此publishProgress中 new AsyncTaskResult 就是创建了一个AsyncTaskResult,他的两个两个属性为当前的AsyncTask和任务任务执行进度。
到这里的逻辑很清楚了,如果当前任务没有被取消, 那么就从消息池中获取一个Message的实例,同时设置这个Message对象的msg.what=MESSAGE_POST_PROGRESS,msg.obj为一个AsyncTaskResult对象,最后执行sendToTarget方法,通过之前对Handler实现机制的了解,我们知道sendXXX方法殊途同归,所完成的任务都是将Message对象插入到MessageQueue当中,等着Looper的loop方法一个个取出。由于我们是在主线程开启了AsyncTask任务的执行,因此,一旦我们将一个消息插入到队列,那么就会执行Handler的handleMessage方法。下面就来看看你这个InternalHandler 的实现。
private static class InternalHandler extends Handler {
public InternalHandler() {
super(Looper.getMainLooper());
}
@SuppressWarnings({"unchecked", "RawUseOfParameterizedType"})
@Override
public void handleMessage(Message msg) {
AsyncTaskResult<?> result = (AsyncTaskResult<?>) msg.obj;
switch (msg.what) {
case MESSAGE_POST_RESULT:
// There is only one result
result.mTask.finish(result.mData[0]);
break;
case MESSAGE_POST_PROGRESS:
result.mTask.onProgressUpdate(result.mData);
break;
}
}
}哈哈,很简单;在handleMessage中首先取出结果,并强制转换为AsyncTaskResult对象,在msg.what=MESSAGE_POST_PROGRESS时,就会执行result.mTask.onProgressUpdate(result.mData);
mTask 就是当前AsyncTask,因此就会执行AsyncTask中声明的onProgressUpdate方法。这样,就把参数从一个子线程传递到了UI 线程,非常方便开发人员用这个完成相关业务。
我们再回到mWorker 的call() 方法中,当doInBackground执行完毕后,最后就会执行postResult。
private Result postResult(Result result) {
@SuppressWarnings("unchecked")
Message message = getHandler().obtainMessage(MESSAGE_POST_RESULT,
new AsyncTaskResult<Result>(this, result));
message.sendToTarget();
return result;
}这个方法和publishProgress逻辑一样,懂事把result 封装到一个AsyncTaskResult 对象中,做为一个Message对象的obj属性插入到MessageQueue中,只不过msg.what=MESSAGE_POST_RESULT.
这样就会来到InternalHandler 的handleMessage中,这一次msg.what=MESSAGE_POST_RESULT.时执行result.mTask.finish(result.mData[0]);
private void finish(Result result) {
if (isCancelled()) {
onCancelled(result);
} else {
onPostExecute(result);
}
mStatus = Status.FINISHED;
}这个方法也很简单,任务未取消时,onPostExecute(result) 方法被执行。这个onPostExecute(result)就是我们最后要执行的方法,在这个方法中得到最终的执行结果;并将任务状态标记为FINISHED。
到这里,终于完成了对AsyncTask常规用法的总结。先缓口气。。。。。。,如果再来一遍你会发现,有个东西好像被遗忘了,什么呢?就是mFuture,我们在mWorker的call 执行到最后时,通过postResult方法将结果返回到了Handler中,依然实现了完成了任务,那么这个mFuture 还有什么用呢?我们再看一篇AsyncTask的构造方法
public AsyncTask() {
mWorker = new WorkerRunnable<Params, Result>() {
public Result call() throws Exception {
//设置当前任务已被执行
mTaskInvoked.set(true);
.....省略。。。。
return postResult(result);
}
};
mFuture = new FutureTask<Result>(mWorker) {
@Override
protected void done() {
try {
postResultIfNotInvoked(get());
。。。。
省略。。。。
}
};
}
private void postResultIfNotInvoked(Result result) {
final boolean wasTaskInvoked = mTaskInvoked.get();
if (!wasTaskInvoked) {
postResult(result);
}
}我们看一下这段代码,就会发现这个postResultIfNotInvoked 内部的if语句条件不满足,什么都不会执行,也就意味着mFuture的done 这个方法也什么都不会做。这段代码的确十分诡异,不知道是何用意。或者说是我没理解其中的奥义。╮(╯_╰)╭。
这么说来,搞了半天这个mFuture貌似没什么卵用,其实也不是。回到我们一开始提出的一个问题,如何去终止一个正在执行的耗时任务,这个问题说白了就是如何去停止一个线程。通过一个外部方法让一个正在运行的线程停止其实应该是一件很讲究的事情,这个时候mFuture 就可以大显身手了。
public final boolean cancel(boolean mayInterruptIfRunning) {
mCancelled.set(true);
return mFuture.cancel(mayInterruptIfRunning);
}AsyncTask cancel的实现,是靠mFuture 完成的。
这样,平时使用AsyncTask时,常用的几个方法是怎样实现的我们都了解了。
玩一玩AsyncTask
通过上面的内容,我们已经了解了AsyncTask的实现机制。下面通过一个demo来感受一下AsyncTask的奥秘。
class MyAsyncTask extends AsyncTask<String, Integer, String> {
@Override
protected String doInBackground(String... params) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
publishProgress();
return params[0];
}
@Override
protected void onPostExecute(String s) {
super.onPostExecute(s);
SimpleDateFormat df = new SimpleDateFormat("HH:mm:ss", Locale.CHINA);
Log.e(TAG, s + "execute finish at " + df.format(new Date()));
}
}这里定义一个AsyncTask任务,实现逻辑很简单,间隔一秒返回执行任务时传进来的参数,在onPostExecute中打印方法执行时间和执行结果。
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_at);
result = (TextView) findViewById(R.id.result);
findViewById(R.id.execute).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Log.e(TAG, "onClick: " + Runtime.getRuntime().availableProcessors());
for (int i = 0; i < 127; i++) {
new MyAsyncTask().execute("Task#" + i);
}
}
});
}我们通过一个for 循环会执行127个MyAsyncTask任务,看一下日志:
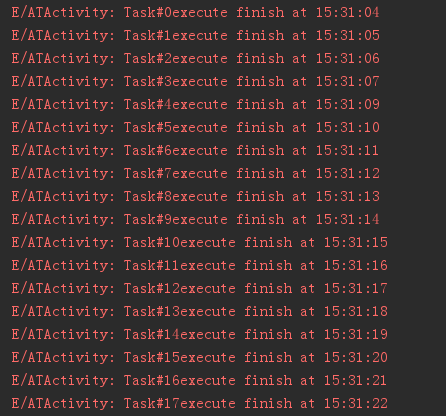
很明显,一秒一个,默认就是串行执行。前面提到了ArrayDeque 是一个自增长的队列。因此,默认情况下,可以创建无数个AsyncTask任务。
这127个任务串行执行下去,要等到他们都执行完毕,得2分多钟,不行我不想等了,我想要并行,那也不难,虽然
AsyncTask默认的执行器是串行执行,但是我们可以这样做:
for (int i = 0; i < 127; i++) {
new MyAsyncTask().executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR, "AsyncTask#" + i);
}我们可以去修改execute 的实现方法,替换默认的sDefaultExecutor为AsyncTask.THREAD_POOL_EXECUTOR,再次执行我们看一下日志:
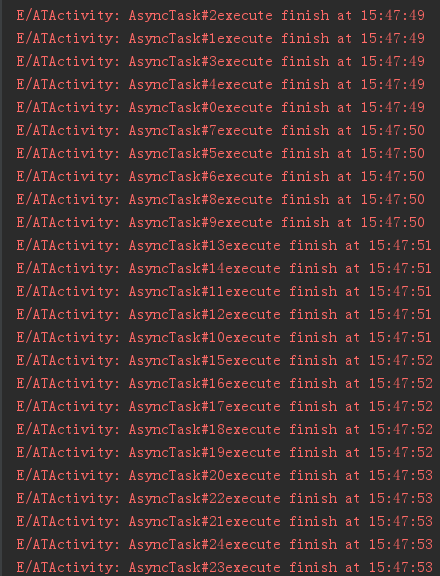
可以看到每一秒有5个线程同时执行,这样127个线程用26秒就可以执行完了,比串行执行快了差不多5倍。为什么是5倍呢?这就要回到我们之前AsyncTask 属性定义当中了。
在定义并行执行的线程池当时, CORE_POOL_SIZE = CPU_COUNT + 1; 线程池核心程数为CPU 核心数+1,因此在我当前的4核手机上最大线程数为5。
串行执行的时候由于ArrayDeque 的优点,可以依次执行很多个任务,那并行呢?这里先说一下结论,以CPU 核心数为4的手机为例,最多一次可以执行137个任务。这个也很好理解,
线程池最大容量为9,阻塞队列容量为128,也就说在并行的时候,最多允许137个任务被阻塞,再多就不行了。
修改之前的代码:
for (int i = 0; i < 138; i++) {
new MyAsyncTask().executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR, "AsyncTask#" + i);
}运行程序时,会抛出异常:
java.util.concurrent.RejectedExecutionException: Task android.os.AsyncTask$3@1429681 rejected from java.util.concurrent.ThreadPoolExecutor@bfb9326[Running, pool size = 9, active threads = 9, queued tasks = 128, completed tasks = 0]public interface RejectedExecutionHandler {
/**
* Method that may be invoked by a {@link ThreadPoolExecutor} when
* {@link ThreadPoolExecutor#execute execute} cannot accept a
* task. This may occur when no more threads or queue slots are
* available because their bounds would be exceeded, or upon
* shutdown of the Executor.
*
* <p>In the absence of other alternatives, the method may throw
* an unchecked {@link RejectedExecutionException}, which will be
* propagated to the caller of {@code execute}.
*
* @param r the runnable task requested to be executed
* @param executor the executor attempting to execute this task
* @throws RejectedExecutionException if there is no remedy
*/
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}很明显,这次是因为我们要执行的任务数已经超过了线程池能够承载的最多量,因此抛出了异常。
最后
AsyncTask 的实现说起来很简单,就是封装了Handler+Thread,但是其细节部分的实现,有许多地方值得去深究。写代码的思路值得借鉴。
AsyncTask 这个类的代码在不同版本的SDK 有着些许差异,以上分析是基于 Android 6.0 ,也就是Android SDK 23 得出。
