

重拾后端之Spring Boot(一):REST API的搭建可以这样简单
重拾后端之Spring Boot(二):MongoDb的无缝集成
重拾后端之Spring Boot(三):找回熟悉的Controller,Service
重拾后端之Spring Boot(四):使用 JWT 和 Spring Security 保护 REST API
重拾后端之 Spring Boot(五) -- 跨域、自定义查询及分页
重拾后端之Spring Boot(六) -- 热加载、容器和多项目
上一节,我们做的那个例子有点太简单了,通常的后台都会涉及一些数据库的操作,然后在暴露的API中提供处理后的数据给客户端使用。那么这一节我们要做的是集成MongoDB ( www.mongodb.com )。
MongoDB是什么?
MongoDB是一个NoSQL数据库,是NoSQL中的一个分支:文档数据库。和传统的关系型数据库比如Oracle、SQLServer和MySQL等有很大的不同。传统的关系型数据库(RDBMS)已经成为数据库的代名词超过20多年了。对于大多数开发者来说,关系型数据库是比较好理解的,表这种结构和SQL这种标准化查询语言毕竟是很大一部分开发者已有的技能。那么为什么又搞出来了这个什么劳什子NoSQL,而且看上去NoSQL数据库正在飞快的占领市场。
NoSQL的应用场景是什么?
假设说我们现在要构建一个论坛,用户可以发布帖子(帖子内容包括文本、视频、音频和图片等)。那么我们可以画出一个下图的表关系结构。
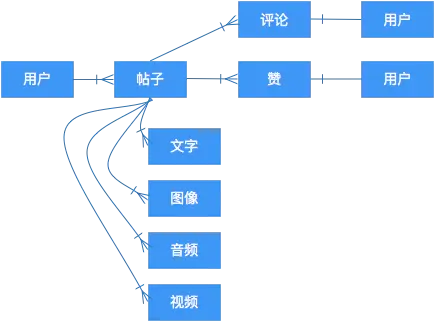
这种情况下我们想一下这样一个帖子的结构怎么在页面中显示,如果我们希望显示帖子的文字,以及关联的图片、音频、视频、用户评论、赞和用户的信息的话,我们需要关联八个表取得自己想要的数据。如果我们有这样的帖子列表,而且是随着用户的滚动动态加载,同时需要监听是否有新内容的产生。这样一个任务我们需要太多这种复杂的查询了。
NoSQL解决这类问题的思路是,干脆抛弃传统的表结构,你不是帖子有一个结构关系吗,那我就直接存储和传输一个这样的数据给你,像下面那样。
{
"id":"5894a12f-dae1-5ab0-5761-1371ba4f703e",
"title":"2017年的Spring发展方向",
"date":"2017-01-21",
"body":"这篇文章主要探讨如何利用Spring Boot集成NoSQL",
"createdBy":User,
"images":["http://dev.local/myfirstimage.png","http://dev.local/mysecondimage.png"],
"videos":[
{"url":"http://dev.local/myfirstvideo.mp4", "title":"The first video"},
{"url":"http://dev.local/mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"http://dev.local/myfirstaudio.mp3", "title":"The first audio"},
{"url":"http://dev.local/mysecondaudio.mp3", "title":"The second audio"}
]
}NoSQL一般情况下是没有Schema这个概念的,这也给开发带来较大的自由度。因为在关系型数据库中,一旦Schema确定,以后更改Schema,维护Schema是很麻烦的一件事。但反过来说Schema对于维护数据的完整性是非常必要的。
一般来说,如果你在做一个Web、物联网等类型的项目,你应该考虑使用NoSQL。如果你要面对的是一个对数据的完整性、事务处理等有严格要求的环境(比如财务系统),你应该考虑关系型数据库。
在Spring中集成MongoDB
在我们刚刚的项目中集成MongoDB简单到令人发指,只有三个步骤:
- 在
build.gradle中更改compile('org.springframework.boot:spring-boot-starter-web')为compile("org.springframework.boot:spring-boot-starter-data-rest") - 在
Todo.java中给private String id;之前加一个元数据修饰@Id以便让Spring知道这个Id就是数据库中的Id - 新建一个如下的
TodoRepository.java
package dev.local.todo;
import org.springframework.data.mongodb.repository.MongoRepository;
import org.springframework.data.rest.core.annotation.RepositoryRestResource;
@RepositoryRestResource(collectionResourceRel = "todo", path = "todo")
public interface TodoRepository extends MongoRepository<Todo, String>{
}此时我们甚至不需要Controller了,所以暂时注释掉 TodoController.java 中的代码。然后我们 ./gradlew bootRun 启动应用。访问 http://localhost:8080/todo 我们会得到下面的的结果。
{
_embedded: {
todo: [ ]
},
_links: {
self: {
href: "http://localhost:8080/todo"
},
profile: {
href: "http://localhost:8080/profile/todo"
}
},
page: {
size: 20,
totalElements: 0,
totalPages: 0,
number: 0
}
}我勒个去,不光是有数据集的返回结果 todo: [ ] ,还附赠了一个links对象和page对象。如果你了解 Hypermedia 的概念,就会发现这是个符合 Hypermedia REST API返回的数据。
说两句关于 MongoRepository<Todo, String> 这个接口,前一个参数类型是领域对象类型,后一个指定该领域对象的Id类型。
Hypermedia REST
简单说两句Hypermedia是什么。简单来说它是可以让客户端清晰的知道自己可以做什么,而无需依赖服务器端指示你做什么。原理呢,也很简单,通过返回的结果中包括不仅是数据本身,也包括指向相关资源的链接。拿上面的例子来说(虽然这种默认状态生成的东西不是很有代表性):links中有一个profiles,我们看看这个profile的链接 http://localhost:8080/profile/todo 执行的结果是什么:
{
"alps" : {
"version" : "1.0",
"descriptors" : [
{
"id" : "todo-representation",
"href" : "http://localhost:8080/profile/todo",
"descriptors" : [
{
"name" : "desc",
"type" : "SEMANTIC"
},
{
"name" : "completed",
"type" : "SEMANTIC"
}
]
},
{
"id" : "create-todo",
"name" : "todo",
"type" : "UNSAFE",
"rt" : "#todo-representation"
},
{
"id" : "get-todo",
"name" : "todo",
"type" : "SAFE",
"rt" : "#todo-representation",
"descriptors" : [
{
"name" : "page",
"doc" : {
"value" : "The page to return.",
"format" : "TEXT"
},
"type" : "SEMANTIC"
},
{
"name" : "size",
"doc" : {
"value" : "The size of the page to return.",
"format" : "TEXT"
},
"type" : "SEMANTIC"
},
{
"name" : "sort",
"doc" : {
"value" : "The sorting criteria to use to calculate the content of the page.",
"format" : "TEXT"
},
"type" : "SEMANTIC"
}
]
},
{
"id" : "patch-todo",
"name" : "todo",
"type" : "UNSAFE",
"rt" : "#todo-representation"
},
{
"id" : "update-todo",
"name" : "todo",
"type" : "IDEMPOTENT",
"rt" : "#todo-representation"
},
{
"id" : "delete-todo",
"name" : "todo",
"type" : "IDEMPOTENT",
"rt" : "#todo-representation"
},
{
"id" : "get-todo",
"name" : "todo",
"type" : "SAFE",
"rt" : "#todo-representation"
}
]
}
}这个对象虽然我们暂时不是完全的理解,但大致可以猜出来,这个是todo这个REST API的元数据描述,告诉我们这个API中定义了哪些操作和接受哪些参数等等。我们可以看到todo这个API有增删改查等对应功能。
其实呢,Spring是使用了一个叫 ALPS (alps.io/spec/index.… 的专门描述应用语义的数据格式。摘出下面这一小段来分析一下,这个描述了一个get方法,类型是 SAFE 表明这个操作不会对系统状态产生影响(因为只是查询),而且这个操作返回的结果格式定义在 todo-representation 中了。 todo-representation
{
"id" : "get-todo",
"name" : "todo",
"type" : "SAFE",
"rt" : "#todo-representation"
}还是不太理解?没关系,我们再来做一个实验,启动 PostMan (不知道的同学,可以去Chrome应用商店中搜索下载)。我们用Postman构建一个POST请求:
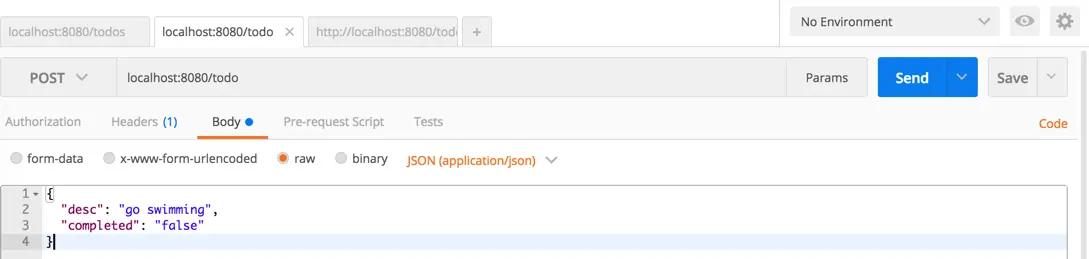
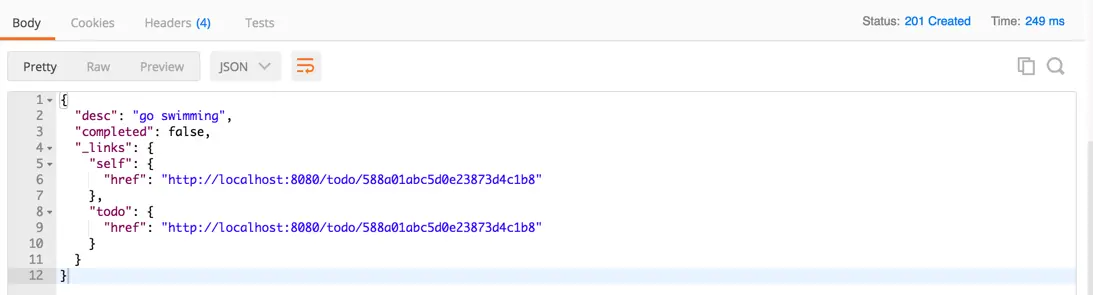
执行后的结果如下,我们可以看到返回的links中包括了刚刚新增的Todo的link http://localhost:8080/todo/588a01abc5d0e23873d4c1b8 ( 588a01abc5d0e23873d4c1b8 就是数据库自动为这个Todo生成的Id),这样客户端可以方便的知道指向刚刚生成的Todo的API链接。
再举一个现实一些的例子,我们在开发一个“我的”页面时,一般情况下除了取得我的某些信息之外,因为在这个页面还会有一些可以链接到更具体信息的页面链接。如果客户端在取得比较概要信息的同时就得到这些详情的链接,那么客户端的开发就比较简单了,而且也更灵活了。
其实这个描述中还告诉我们一些分页的信息,比如每页20条记录(size: 20)、总共几页(totalPages:1)、总共多少个元素(totalElements: 1)、当前第几页(number: 0)。当然你也可以在发送API请求时,指定page、size或sort参数。比如 http://localhost:8080/todos?page=0&size=10 就是指定每页10条,当前页是第一页(从0开始)。
魔法的背后
这么简单就生成一个有数据库支持的REST API,这件事看起来比较魔幻,但一般这么魔幻的事情总感觉不太托底,除非我们知道背后的原理是什么。首先再来回顾一下 TodoRepository 的代码:
@RepositoryRestResource(collectionResourceRel = "todo", path = "todo")
public interface TodoRepository extends MongoRepository<Todo, String>{
}Spring是最早的几个IoC(控制反转或者叫DI)框架之一,所以最擅长的就是依赖的注入了。这里我们写了一个Interface,可以猜到Spring一定是有一个这个接口的实现在运行时注入了进去。如果我们去 spring-data-mongodb 的源码中看一下就知道是怎么回事了,这里只举一个小例子,大家可以去看一下 SimpleMongoRepository.java ( 源码链接 ),由于源码太长,我只截取一部分:
public class SimpleMongoRepository<T, ID extends Serializable> implements MongoRepository<T, ID> {
private final MongoOperations mongoOperations;
private final MongoEntityInformation<T, ID> entityInformation;
/**
* Creates a new {@link SimpleMongoRepository} for the given {@link MongoEntityInformation} and {@link MongoTemplate}.
*
* @param metadata must not be {@literal null}.
* @param mongoOperations must not be {@literal null}.
*/
public SimpleMongoRepository(MongoEntityInformation<T, ID> metadata, MongoOperations mongoOperations) {
Assert.notNull(mongoOperations);
Assert.notNull(metadata);
this.entityInformation = metadata;
this.mongoOperations = mongoOperations;
}
/*
* (non-Javadoc)
* @see org.springframework.data.repository.CrudRepository#save(java.lang.Object)
*/
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null!");
if (entityInformation.isNew(entity)) {
mongoOperations.insert(entity, entityInformation.getCollectionName());
} else {
mongoOperations.save(entity, entityInformation.getCollectionName());
}
return entity;
}
...
public T findOne(ID id) {
Assert.notNull(id, "The given id must not be null!");
return mongoOperations.findById(id, entityInformation.getJavaType(), entityInformation.getCollectionName());
}
private Query getIdQuery(Object id) {
return new Query(getIdCriteria(id));
}
private Criteria getIdCriteria(Object id) {
return where(entityInformation.getIdAttribute()).is(id);
}
...
}也就是说其实在运行时Spring将这个类或者其他具体接口的实现类注入了应用。这个类中有支持各种数据库的操作。我了解到这步就觉得ok了,有兴趣的同学可以继续深入研究。
虽然不想在具体类上继续研究,但我们还是应该多了解一些关于 MongoRepository 的东西。这个接口继承了 PagingAndSortingRepository (定义了排序和分页) 和 QueryByExampleExecutor。而 PagingAndSortingRepository 又继承了 CrudRepository (定义了增删改查等)。
第二个魔法就是 @RepositoryRestResource(collectionResourceRel = "todo", path = "todo") 这个元数据的修饰了,它直接对MongoDB中的集合(本例中的todo)映射到了一个REST URI(todo)。因此我们连Controller都没写就把API搞出来了,而且还是个Hypermedia REST。
其实呢,这个第二个魔法只在你需要变更映射路径时需要。本例中如果我们不加 @RepositoryRestResource 这个修饰符的话,同样也可以生成API,只不过其路径按照默认的方式变成了 todoes ,大家可以试试把这个元数据修饰去掉,然后重启服务,访问 http://localhost:8080/todoes 看看。
说到这里,顺便说一下REST的一些约定俗成的规矩。一般来说如果我们定义了一个领域对象 (比如我们这里的Todo),那么这个对象的集合(比如Todo的列表)可以使用这个对象的命名的复数方式定义其资源URL,也就是刚刚我们访问的 http://localhost:8080/todoes,对于新增一个对象的操作也是这个URL,但Request的方法是POST。
而这个某个指定的对象(比如指定了某个ID的Todo)可以使用 todoes/:id 来访问,比如本例中 http://localhost:8080/todoes/588a01abc5d0e23873d4c1b8。对于这个对象的修改和删除使用的也是这个URL,只不过HTTP Request的方法变成了PUT(或者PATCH)和DELETE。
这个里面默认采用的这个命名 todoes 是根据英语的语法来的,一般来说复数是加s即可,但这个todo,是辅音+o结尾,所以采用的加es方式。 todo 其实并不是一个真正意义上的单词,所以我认为更合理的命名方式应该是 todos。所以我们还是改成 @RepositoryRestResource(collectionResourceRel = "todos", path = "todos")
无招胜有招
刚才我们提到的都是开箱即用的一些方法,你可能会想,这些东西看上去很炫,但没有毛用,实际开发过程中,我们要使用的肯定不是这么简单的增删改查啊。说的有道理,我们来试试看非默认方法。那么我们就来增加一个需求,我们可以通过查询Todo的描述中的关键字来搜索符合的项目。
显然这个查询不是默认的操作,那么这个需求在Spring Boot中怎么实现呢?非常简单,只需在 TodoRepository 中添加一个方法:
...
public interface TodoRepository extends MongoRepository<Todo, String>{
List<Todo> findByDescLike(@Param("desc") String desc);
}太不可思议了,这样就行?不信可以启动服务后,在浏览器中输入 http://localhost:8080/todos/search/findByDescLike?desc=swim 去看看结果。是的,我们甚至都没有写这个方法的实现就已经完成了该需求(题外话,其实 http://localhost:8080/todos?desc=swim 这个URL也起作用)。
你说这里肯定有鬼,我同意。那么我们试试把这个方法改个名字 findDescLike ,果然不好用了。为什么呢?这套神奇的疗法的背后还是那个我们在第一篇时提到的 Convention over configuration,要神奇的疗效就得遵循Spring的配方。这个配方就是方法的命名是有讲究的:Spring提供了一套可以通过命名规则进行查询构建的机制。这套机制会把方法名首先过滤一些关键字,比如 find…By, read…By, query…By, count…By 和 get…By 。系统会根据关键字将命名解析成2个子语句,第一个 By 是区分这两个子语句的关键词。这个 By 之前的子语句是查询子语句(指明返回要查询的对象),后面的部分是条件子语句。如果直接就是 findBy… 返回的就是定义Respository时指定的领域对象集合(本例中的Todo组成的集合)。
一般到这里,有的同学可能会问 find…By, read…By, query…By, get…By 到底有什么区别啊?答案是。。。木有区别,就是别名,从下面的定义可以看到这几个东东其实生成的查询是一样的,这种让你不用查文档都可以写对的方式也比较贴近目前流行的自然语言描述风格(类似各种DSL)。
private static final String QUERY_PATTERN = "find|read|get|query|stream";刚刚我们实验了模糊查询,那如果要是精确查找怎么做呢,比如我们要筛选出已完成或未完成的Todo,也很简单:
List<Todo> findByCompleted(@Param("completed") boolean completed);嵌套对象的查询怎么搞?
看到这里你会问,这都是简单类型,如果复杂类型怎么办?嗯,好的,我们还是增加一个需求看一下:现在需求是要这个API是多用户的,每个用户看到的Todo都是他们自己创建的项目。我们新建一个User领域对象:
package dev.local.user;
import org.springframework.data.annotation.Id;
public class User {
@Id private String id;
private String username;
private String email;
//此处为节省篇幅省略属性的getter和setter
}为了可以添加User数据,我们需要一个User的REST API,所以添加一个 UserRepository
package dev.local.user;
import org.springframework.data.mongodb.repository.MongoRepository;
public interface UserRepository extends MongoRepository<User, String> {
}然后给 Todo 领域对象添加一个User属性。
package dev.local.todo;
//省略import部分
public class Todo {
//省略其他部分
private User user;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
}接下来就可以来把 TodoRepository 添加一个方法定义了,我们先实验一个简单点的,根据用户的email来筛选出这个用户的Todo列表:
public interface TodoRepository extends MongoRepository<Todo, String>{
List<Todo> findByUserEmail(@Param("userEmail") String userEmail);
}现在需要构造一些数据了,你可以通过刚刚我们建立的API使用Postman工具来构造:我们这里创建了2个用户,以及一些Todo项目,分别属于这两个用户,而且有部分项目的描述是一样的。接下来就可以实验一下了,我们在浏览器中输入 http://localhost:8080/todos/search/findByUserEmail?userEmail=peng@gmail.com ,我们会发现返回的结果中只有这个用户的Todo项目。
{
"_embedded" : {
"todos" : [ {
"desc" : "go swimming",
"completed" : false,
"user" : {
"username" : "peng",
"email" : "peng@gmail.com"
},
"_links" : {
"self" : {
"href" : "http://localhost:8080/todos/58908a92c5d0e2524e24545a"
},
"todo" : {
"href" : "http://localhost:8080/todos/58908a92c5d0e2524e24545a"
}
}
}, {
"desc" : "go for walk",
"completed" : false,
"user" : {
"username" : "peng",
"email" : "peng@gmail.com"
},
"_links" : {
"self" : {
"href" : "http://localhost:8080/todos/58908aa1c5d0e2524e24545b"
},
"todo" : {
"href" : "http://localhost:8080/todos/58908aa1c5d0e2524e24545b"
}
}
}, {
"desc" : "have lunch",
"completed" : false,
"user" : {
"username" : "peng",
"email" : "peng@gmail.com"
},
"_links" : {
"self" : {
"href" : "http://localhost:8080/todos/58908ab6c5d0e2524e24545c"
},
"todo" : {
"href" : "http://localhost:8080/todos/58908ab6c5d0e2524e24545c"
}
}
}, {
"desc" : "have dinner",
"completed" : false,
"user" : {
"username" : "peng",
"email" : "peng@gmail.com"
},
"_links" : {
"self" : {
"href" : "http://localhost:8080/todos/58908abdc5d0e2524e24545d"
},
"todo" : {
"href" : "http://localhost:8080/todos/58908abdc5d0e2524e24545d"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:8080/todos/search/findByUserEmail?userEmail=peng@gmail.com"
}
}
}看到结果后我们来分析这个 findByUserEmail 是如何解析的:首先在 By 之后,解析器会按照 camel (每个单词首字母大写)的规则来分词。那么第一个词是 User,这个属性在 Todo 中有没有呢?有的,但是这个属性是另一个对象类型,所以紧跟着这个词的 Email 就要在 User 类中去查找是否有 Email 这个属性。聪明如你,肯定会想到,那如果在 Todo 类中如果还有一个属性叫 userEmail 怎么办?是的,这种情况下 userEmail 会被优先匹配,此时请使用 _ 来显性分词处理这种混淆。也就是说如果我们的 Todo 类中同时有 user 和 userEmail 两个属性的情况下,我们如果想要指定的是 user 的 email ,那么需要写成 findByUser_Email。
还有一个问题,我估计很多同学现在已经在想了,那就是我们的这个例子中并没有使用 user 的 id,这不科学啊。是的,之所以没有在上面使用 findByUserId 是因为要引出一个易错的地方,下面我们来试试看,将 TodoRepository 的方法改成
public interface TodoRepository extends MongoRepository<Todo, String>{
List<Todo> findByUserId(@Param("userId") String userId);
}你如果打开浏览器输入 http://localhost:8080/todos/search/findByUserId?userId=589089c3c5d0e2524e245458 (这里的Id请改成你自己mongodb中的user的id),你会发现返回的结果是个空数组。原因是虽然我们在类中标识 id 为 String 类型,但对于这种数据库自己生成维护的字段,它在MongoDB中的类型是ObjectId,所以在我们的接口定义的查询函数中应该标识这个参数是 ObjectId。那么我们只需要改动 userId 的类型为 org.bson.types.ObjectId 即可。
package dev.local.todo;
import org.bson.types.ObjectId;
import org.springframework.data.mongodb.repository.MongoRepository;
import org.springframework.data.repository.query.Param;
import org.springframework.data.rest.core.annotation.RepositoryRestResource;
import java.util.List;
@RepositoryRestResource(collectionResourceRel = "todos", path = "todos")
public interface TodoRepository extends MongoRepository<Todo, String>{
List<Todo> findByUserId(@Param("userId") ObjectId userId);
}再复杂一些行不行?
好吧,到现在我估计还有一大波攻城狮表示不服,实际开发中需要的查询比上面的要复杂的多,再复杂一些怎么办?还是用例子来说话吧,那么现在我们想要模糊搜索指定用户的Todo中描述的关键字,返回匹配的集合。这个需求我们只需改动一行,这个以命名规则为基础的查询条件是可以加 And、Or 这种关联多个条件的关键字的。
List<Todo> findByUserIdAndDescLike(@Param("userId") ObjectId userId, @Param("desc") String desc);当然,还有其他操作符:Between (值在两者之间), LessThan (小于), GreaterThan (大于), Like (包含), IgnoreCase (b忽略大小写), AllIgnoreCase (对于多个参数全部忽略大小写), OrderBy (引导排序子语句), Asc (升序,仅在 OrderBy 后有效) 和 Desc (降序,仅在 OrderBy 后有效)。
刚刚我们谈到的都是对于查询条件子语句的构建,其实在 By 之前,对于要查询的对象也可以有限定的修饰词 Distinct (去重,如有重复取一个值)。比如有可能返回的结果有重复的记录,可以使用 findDistinctTodoByUserIdAndDescLike。
我可以直接写查询语句吗?几乎所有码农都会问的问题。当然可以咯,也是同样简单,就是给方法加上一个元数据修饰符 @Query
public interface TodoRepository extends MongoRepository<Todo, String>{
@Query("{ 'user._id': ?0, 'desc': { '$regex': ?1} }")
List<Todo> searchTodos(@Param("userId") ObjectId userId, @Param("desc") String desc);
}采用这种方式我们就不用按照命名规则起方法名了,可以直接使用MongoDB的查询进行。上面的例子中有几个地方需要说明一下
?0和?1是参数的占位符,?0表示第一个参数,也就是userId;?1表示第二个参数也就是desc。- 使用
user._id而不是user.id是因为所有被@Id修饰的属性在Spring Data中都会被转换成_id - MongoDB中没有关系型数据库的Like关键字,需要以正则表达式的方式达成类似的功能。
其实,这种支持的力度已经可以让我们写出相对较复杂的查询了。但肯定还是不够的,对于开发人员来讲,如果不给可以自定义的方式基本没人会用的,因为总有这样那样的原因会导致我们希望能完全掌控我们的查询或存储过程。但这个话题展开感觉就内容更多了,后面再讲吧。
重拾后端之Spring Boot(一):REST API的搭建可以这样简单
重拾后端之Spring Boot(二):MongoDb的无缝集成
重拾后端之Spring Boot(三):找回熟悉的Controller,Service
重拾后端之Spring Boot(四):使用 JWT 和 Spring Security 保护 REST API
