

近期工作中要做一些图谱的应用,于是这几天就调研了下图数据库,最后就有了本文。ps:本人第一次做图谱相关的应用,具体怎么构建也还不清楚,大家有什么资料、建议欢迎私信、留言的。
图领域的问题
整个图领域,所有要解决问题都能分为两大类:
- Technologies used primarily for transactional online graph persistence, typically accessed directly in real time from an application(在线处理)
- Technologies used primarily for offline graph analytics, typically performed as a series of batch steps(离线分析)
另一种分类是从采用的技术上,3 种主要的图数据模型:
- property graph
- Resource Description Framework (RDF) triples
- hypergraphs
市面上大多数图数据库都是基于 property graph 来做的。
图数据库
看图数据库的时候,我们从两个技术点切入:
- The underlying storage
- The processing engine
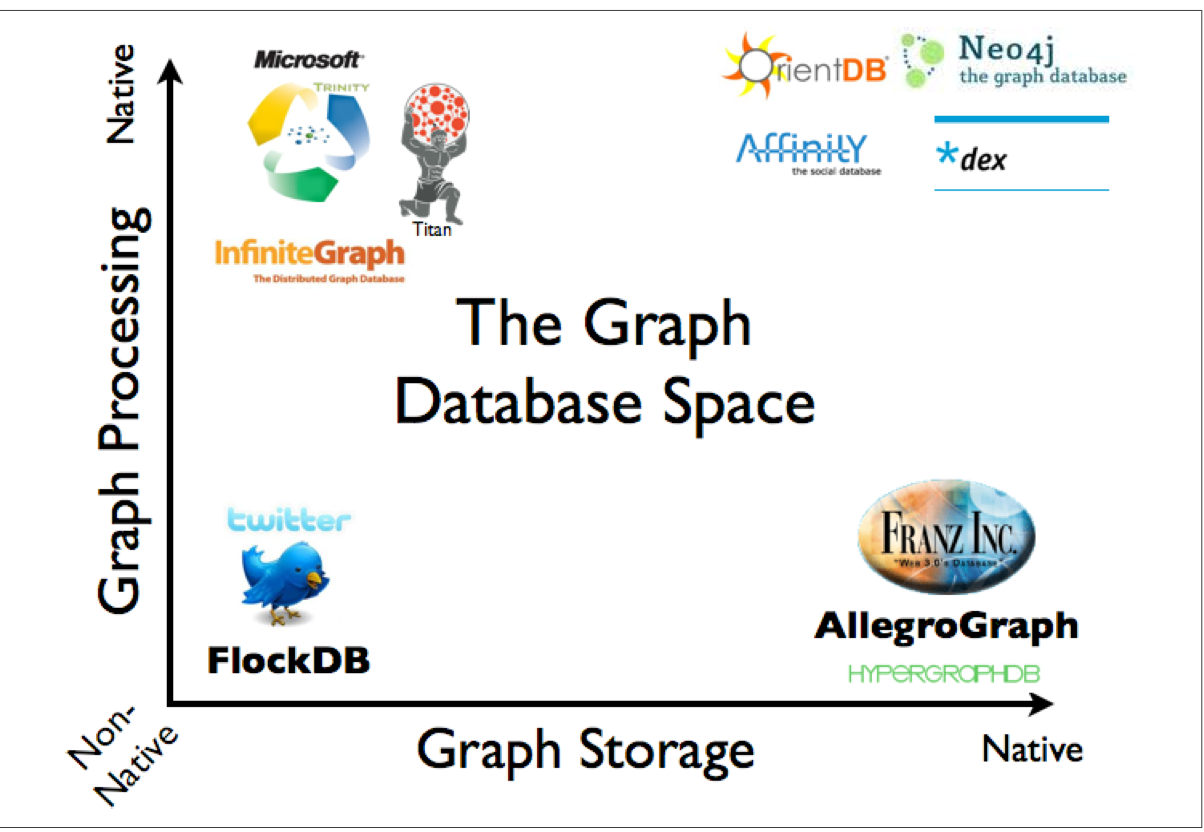
像 Titan 使用的不是 native 存储,后端可以使用
- Apache Cassandra
- Apache HBase
- Oracle BerkeleyDB
而 neo4j 用的就都是 native graph storage and native graph processing
此处解释下什么叫 native graph storage 和 native graph processing
native graph processing
如果存储具有 index-free adjacency 属性,则称为具有 native processing 属性。
那什么叫 index-free adjacency?
如果每个节点直接指向关联的节点,相当于每个节点都有一个自己的局部索引,比起全局索引来说,成本更低,因此速度也更快

native graph storage
index-free adjacency 是图数据库相比于传统的 mysql 的优势的核心 key,那么图数据库用什么结构去存储 index-free adjacency 是关键设计点。

架构上生层是对外访问的 api,右边是事务管理,左边有 cache 等,下面我们看下 disk 上存储的结构:
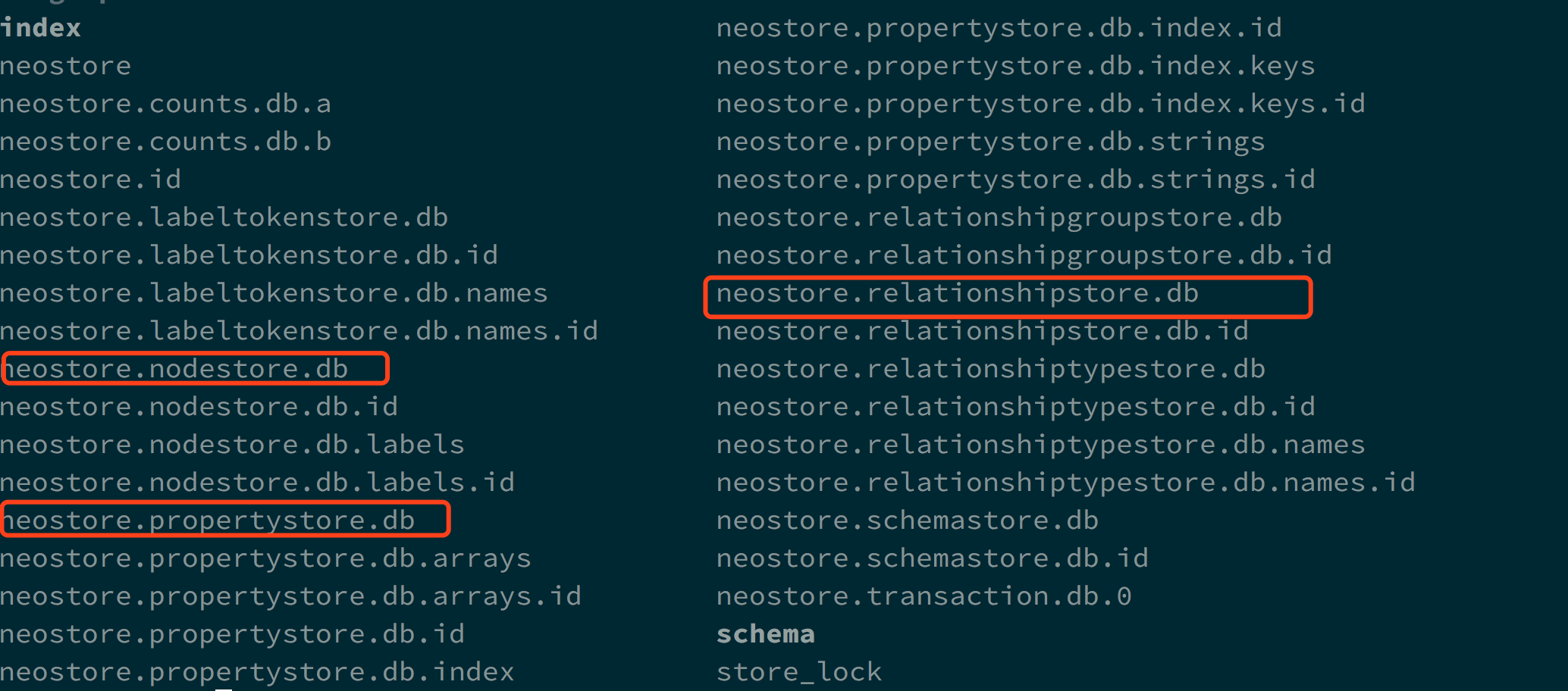
neo4j 在磁盘上会分不同的 store file 存储
- neostore.nodestore.db:存储 node
- neostore.propertystore.db:存储属性
- neostore.relationshipstore.db:存储关系
一个重要的设计点是 store 中存储的 record 都是固定大小的,固定大小带来的好处是:因为每个 record 的大小固定,因此给定 id
就能快速进行定位。
具体结构是:
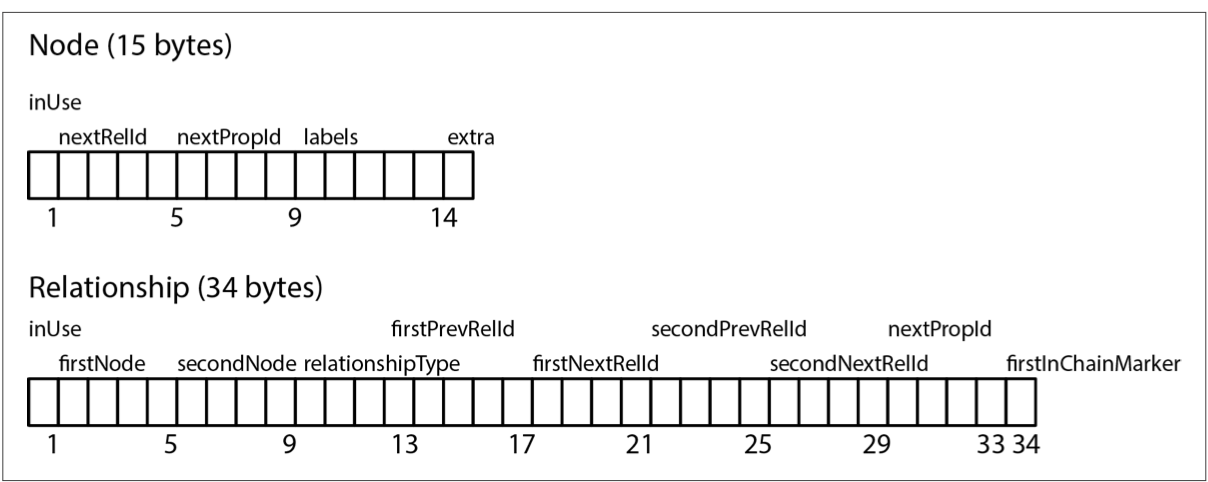
上图第一个是 node record 的结构:
- 1byte:in-use flag,表明该 node 是否在使用
- 4byte:第一个 relation id
- 4byte:第一个 property id
- 5byte:label 信息(可能直接 inline 存储)
- 1byte:reversed
下面是 relation record 的结构:
刚开始是开始和结束节点的 node id,接着是 relation type pointer,然后开始和结束节点的前驱和后继 relation id
更形象一点的图
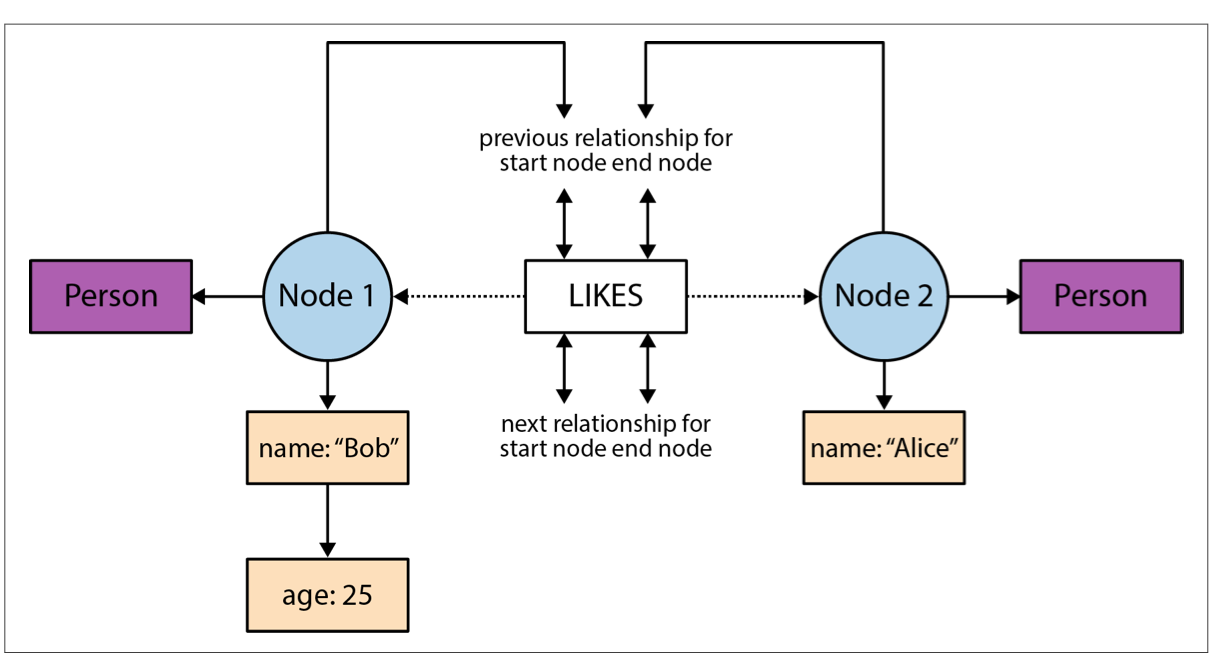
一个可能的搜索过程是:对于给定的一个 node record,可以通过 id 进行简单的偏移计算得到 node,然后通过 relation_id 定位到 relation record,然后得到 end node id,通过偏移计算得到 node
双向存储
还有一个问题:图中节点的关系是有方向的,怎么记录这种方向呢?如果方向是双向的,我们难道要存储两个 relation 吗?
看例子:
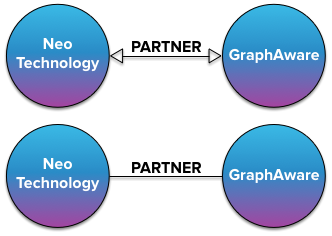
这种 partner 的关系天然就是双向的,但是我们存储的时候,难道要存储两个关系吗,如下图:
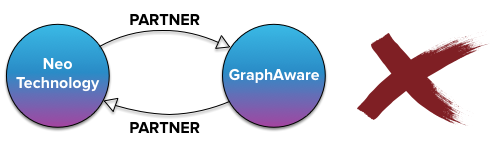
那肯定是不需要的,这种存储就是一种浪费,那到底 neo4j 中是怎么存储 partner 这种双向关系的呢?
答案是:以任意一个节点为开端,另一个为尾端,即存储成为单向的关系
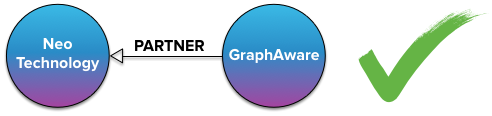
在 neo4j 中任意的关系都有一个 start node 和一个 end node,而且 start node 和 end node 都会有个关联的双向链表,这个双向链表中就记录了从该节点出去和进入的所有关系,一个实例是:
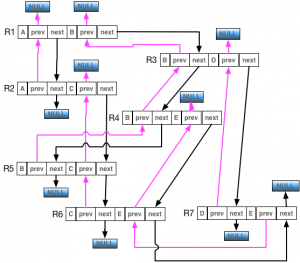
图片来自:neo4j 底层存储结构分析 (1)
上图中 B 节点的 prev 和 next 我们就能看到在这个链表中,B 有时候是 start node 有时候是 end node。
至此我们就对图数据库有了个大概的了解了,后续的分析会随着项目的推进持续输出。
待完成
下面是今后需要跟进的一些工作
- 性能测试
- 分布式方案
- Titan 调研
- ....
参考
neo4j 底层存储结构分析 (1)
Modelling Data in Neo4j: Bidirectional Relationships
graph database
