

这两天 Uber 的开发团队在一个大会上分享了用 Swift 3 重写客户端的过程, 视频里介绍了一个很黑科技的技巧, 可以极大地加快编译速度, 我自己试了一下之后发现确实有效, 但也有小坑, 在这里跟大家分享一下.
Uber 的开发团队偶然发现如果把所有 Model 文件全部合并到一个文件去编译, 那编译时间会从 1min 35s 减少到 17s, 那么我们如果把所有代码文件都合并到一起, 那就可以极大地优化编译速度了.
WHO(Whole-Module-Optimization) 也会把文件合并起来再进行编译, 实际使用时我们发现编译虽然快了, 但对于编译时间的减少还是远没有直接把文件合并到一起那么有效. 主要原因是因为 WHO 除了合并文件之外, 还会在预编译阶段做这些事情:
- 检测没有被调用的方法和类型, 在预编译期去掉它们
- 给没有被继承的类, 没有被继承的方法加上 final 标签, 给编译器提供更多信息, 以便这些方法被优化为静态调用或者是内联进去
这些优化会对于程序的效率有很大的提升, 但编译时需要加载更多的 context, 每合并一个文件, 就会遍历所有文件进行一次上面的检查, 编译时间会随着文件的增多呈指数级增长.
Uber 的团队发现通过增加一个编译宏就可以做到只合并文件, 而不做优化. 进入工程文件设置 -> Build Setting -> Add User-Defined Settings, key 为 SWIFT_WHOLE_MODULE_OPTIMIZATION, value 设为 YES, 然后把优化级别设为 None 就可以了.
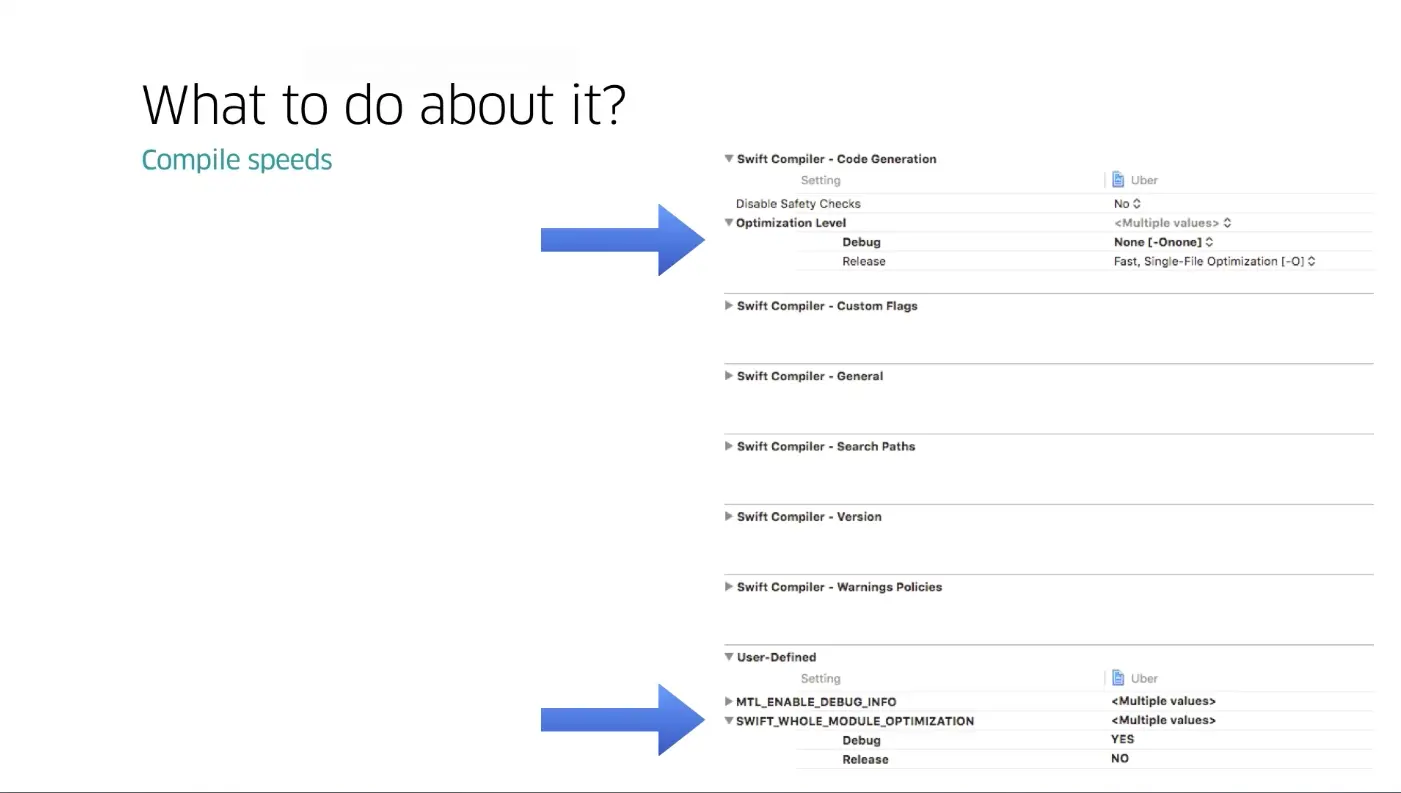
那么问题来了, 为什么 Swift 的编译器没有进行这样的优化呢?
答案很简单, 因为这种优化会让增量编译的颗粒度从 File 级别增大到 Module 级别.
编译的过程一般是每一个文件单独进行编译, 然后再链接到一起. 编译后缓存的是链接前的产物, 而把所有文件都合并到一起再编译, 缓存的就是合并后的文件编译后的产物.
只要修改我们项目里的一个文件, 想要编译 debug 一下, 就又得重新合并文件从头开始编译一次, 而不能读取缓存跳过没有被修改的文件.
但 pod 里的库, storyboard 和 xib 文件就不会受这个影响, 只是我们修改了文件之后, 就得整个 module 从头编译一遍 (我们的项目也是一个 module, 只是 main 函数位于这个 module 而已, 除此之外跟别的 module 没有任何本质区别)
所以这个优化手段其实没想象中那么有用, 反正打包一般都是 CI 去做, 不在本机, 而日常 debug 都会直接增量编译. 只有到了 Uber 这种规模的团队, 每一个 feature branch 都需要到 CI 上打包测试, 使用这种优化手段才比较有现实意义.
非要说对于普通开发者的意义的话, 可能是 flow.ci 那种按照时长计费的方式可以省点钱, 毕竟内部测试的时候对性能要求没那么高. (仔细想想, 好像还可以省蛮多钱的, 小型项目几万行代码使用这种优化的话, 之前编译一次的费用现在可以用三四次, 而且收益也会随着项目增大呈指数级增长)
喜欢我写的文章的话可以关注我的博客
