

本文由 GodPan 发表在 ScalaCool 团队博客。
通过前几篇的学习,相信大家对Akka应该有所了解了,都说解决并发哪家强,JVM上面找Akka,那么Akka到底在解决并发问题上帮我们做了什么呢?
共享内存
众所周知,在处理并发问题上面,最核心的一部分就是如何处理共享内存,很多时候我们都需要花费很多时间和精力在共享内存上,那么在学习Akka对共享内存是如何管理之前,我们先来看看Java中是怎么处理这个问题的。
Java共享内存
相信对Java并发有所了解的同学都应该知道在Java5推出JSR 133后,Java对内存管理有了更高标准的规范了,这使我们开发并发程序也有更好的标准了,不会有一些模糊的定义导致的无法确定的错误。
首先来看看一下Java内存模型的简单构图:
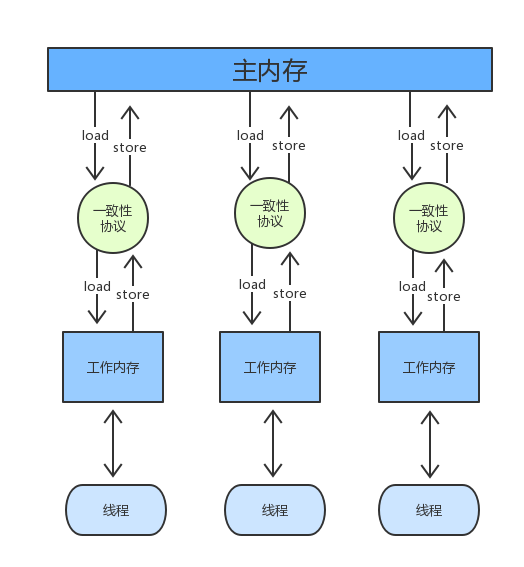
从图中我们可以看到我们线程都有自己的一个工作内存,这就好比高速缓存,它是对主内存部分数据的拷贝,线程对自己工作内存的操作速度远远快于对主内存的操作,但这也往往会引起共享变量不一致的问题,比如以下一个场景:
int a = 0;
public void setA() {
a = a + 1;
}上面是一个很简单的例子,a是一个全局变量,然后我们有一个方法去修改这个值,每次增加一,假如我们用100个线程去运行这段代码,那a最终的结果会是多少呢?
100?显然不一定,它可能是80,90,或者其他数,这就造成共享变量不一致的问题,那么为什么会导致这个问题呢,就是我们上面所说的,线程去修改a的时候可能就只是修改了自己工作内存中a的副本,但并没有将a的值及时的刷新到主内存中,这便会导致其他线程可能读到未被修改a的值,最终出现变量不一致问题。
那么Java中是怎么处理这种问题,如何保证共享变量的一致性的呢?
同步机制
大体上Java中有3类同步机制,但它们所解决的问题并不相同,我们先来看一看这三种机制:
- final关键词
- volatile关键词
- synchronized关键词(这里代表了所有类似监视锁的机制)
1.final关键词
写过Java程序的同学对这个关键词应该再熟悉不过了,其基本含义就是不可变,不可变变量,比如:
final int a = 10;
final String b = "hello";不可变的含义在于当你对这些变量或者对象赋初值后,不能再重新去赋值,但对于对象来说,我们不能修改的是它的引用,但是对象内的内容还是可以修改的。下面是一个简单的例子:
final User u = new User(1,"a");
u.id = 2; //可以修改
u = new User(2,"b"); //不可修改所以在利用final关键词用来保证共享变量的一致性时一定要了解清楚自己的需求,选择合适的方法,另外final变量必须在定义或者构建对象的时候进行初始化,不然会报错。
2.volatile关键词
很多同学在遇到共享变量不一致的问题后,都会说我在声明变量前加一个volatile就好了,但事实真是这样嘛?答案显然不是。那我们来看看volatile到底为我们做了什么。
前面我们说过每个线程都有自己的工作内存,很多时候线程去修改一个变量的值只是修改了自己工作内存中副本的值,这便会导致主内存的值并不是最新的,其他线程读取到的变量便会出现问题。volatile帮我们解决了这个问题,它有两个特点:
- 线程每次都会去主内存中读取变量
- 线程每次修改变量后的值都会及时更新到主内存中去
举个例子:
volatile int a = 0;
public void setA() {
a = a + 1;
}现在线程在执行这段代码时,都会强制去主内存中读取变量的值,修改后也会马上更新到主内存中去,但是这真的能解决共享变量不一致的问题嘛,其实不然,比如我们有这么一个场景:两个线程同时读取了主内存中变量最新的值,这是我们两个线程都去执行修改操作,最后结果会是什么呢?这里就留给大家自己去思考了,其实也很简单的。
那么volatile在什么场景下能保证线程安全,按照官方来说,有以下两个条件:
- 对变量的写操作不依赖于当前值
- 该变量没有包含在具有其他变量的不变式中
多的方面这里我就不展开了,推荐两篇我觉得写的还不错的文章:volatile的使用及其原理volatile的适用场景
3.synchronized关键词
很多同学在学习Java并发过程中最先接触的就是synchronized关键词了,它确实能解决我们上述的并发问题,那它到时如何帮我们保证共享变量的一致性的呢?
简而言之的说,线程在访问请求用synchronized关键词修饰的方法,代码块都会要求获得一个监视器锁,当线程获得了监视器锁后,它才有权限去执行相应的方法或代码块,并在执行结束后释放监视器锁,这便能保证共享内存的一致性了,因为本文主要是讲Akka的共享内存,过多的篇幅就不展开了,这里推荐一篇解析synchronized原理很不错的文章,有兴趣的同学可以去看看:Synchronized及其实现原理
Akka共享内存
Akka中的共享内存是基于Actor模型的,Actor模型提倡的是:通过通讯来实现共享内存,而不是用共享内存来实现通讯,这点是跟Java解决共享内存最大的区别,举个例子:
在Java中我们要去操作共享内存中数据时,每个线程都需要不断的获取共享内存的监视器锁,然后将操作后的数据暴露给其他线程访问使用,用共享内存来实现各个线程之间的通讯,而在Akka中我们可以将共享可变的变量作为一个Actor内部的状态,利用Actor模型本身串行处理消息的机制来保证变量的一致性。
当然要使用Akka中的机制也必须满足一下两条原则:
- 消息的发送必须先于消息的接收
- 同一个Actor对一条消息的处理先于下一条消息处理
第二个原则很好理解,就是上面我们说的Actor内部是串行处理消息,那我们来看看第一个原则,为什么要保证消息的发送先于消息的接收,是为了防止我们在创建消息的时候发生了不确定的错误,接收者将可能接收到不正确的消息,导致发生奇怪的异常,主要表现为消息对象未初始化完整时,若没有这条规则保证,Actor收到的消息便会不完整。
通过前面的学习我们知道Actor是一种比线程更轻量级,抽象程度更高的一种结构,它帮我们规避了我们自己去操作线程,那么Akka底层到底是怎么帮我们去保证共享内存的一致性的呢?
一个Actor它可能会有很多线程同时向它发送消息,之前我们也说到Actor本身是串行处理的消息的,那它是如何保障这种机制的呢?
Mailbox
Mailbox在Actor模型是一个很重要的概念,我们都知道向一个Actor发送的消息首先都会被存储到它所对应的Mailbox中,那么我们先来看看MailBox的定义结构(本文所引用的代码都在akka.dispatch.Mailbox.scala中,有兴趣的同学也可以去研究一下):
private[akka] abstract class Mailbox(val messageQueue: MessageQueue)
extends ForkJoinTask[Unit] with SystemMessageQueue with Runnable {}很清晰Mailbox内部维护了一个messageQueue这样的消息队列,并继承了Scala自身定义的ForkJoinTask任务执行类和我们很熟悉的Runnable接口,由此可以看出,Mailbox底层还是利用Java中的线程进行处理的。那么我们先来看看它的run方法:
override final def run(): Unit = {
try {
if (!isClosed) { //Volatile read, needed here
processAllSystemMessages() //First, deal with any system messages
processMailbox() //Then deal with messages
}
} finally {
setAsIdle() //Volatile write, needed here
dispatcher.registerForExecution(this, false, false)
}
}为了配合理解,我们这里先来看一下定义:
@inline
final def currentStatus: Mailbox.Status = Unsafe.instance.getIntVolatile(this, AbstractMailbox.mailboxStatusOffset)
@inline
final def isClosed: Boolean = currentStatus == Closed这里我们可以看出Mailbox本身会维护一个状态Mailbox.Status,是一个Int变量,而且是可变的,并且用到volatile来保证了它的可见性:
@volatile
protected var _statusDoNotCallMeDirectly: Status = _ //0 by default现在我们在回去看上面的代码,run方法的执行过程,首先它会去读取MailBox此时的状态,因为是一个Volatile read,所以能保证读取到的是最新的值,然后它会先处理任何的系统消息,这部分不需要我们太过关心,之后便是执行我们发送的消息,这里我们需要详细看一下processMailbox()的实现:
@tailrec private final def processMailbox(
left: Int = java.lang.Math.max(dispatcher.throughput, 1),
deadlineNs: Long = if (dispatcher.isThroughputDeadlineTimeDefined == true) System.nanoTime + dispatcher.throughputDeadlineTime.toNanos else 0L): Unit =
if (shouldProcessMessage) {
val next = dequeue() //去出下一条消息
if (next ne null) {
if (Mailbox.debug) println(actor.self + " processing message " + next)
actor invoke next
if (Thread.interrupted())
throw new InterruptedException("Interrupted while processing actor messages")
processAllSystemMessages()
if ((left > 1) && ((dispatcher.isThroughputDeadlineTimeDefined == false) || (System.nanoTime - deadlineNs) < 0))
processMailbox(left - 1, deadlineNs) //递归处理下一条消息
}
}从上述代码中我们可以清晰的看到,当满足消息处理的情况下就会进行消息处理,从消息队列列取出下一条消息就是上面的dequeue(),然后将消息发给具体的Actor进行处理,接下去又是处理系统消息,然后判断是否还有满足情况需要下一条消息,若有则再次进行处理,可以看成一个递归操作,@tailrec也说明了这一点,它表示的是让编译器进行尾递归优化。
现在我们来看一下一条消息从发送到最终处理在Akka中到底是怎么执行的,下面的内容是我通过阅读Akka源码加自身理解得出的,这里先画了一张流程图:
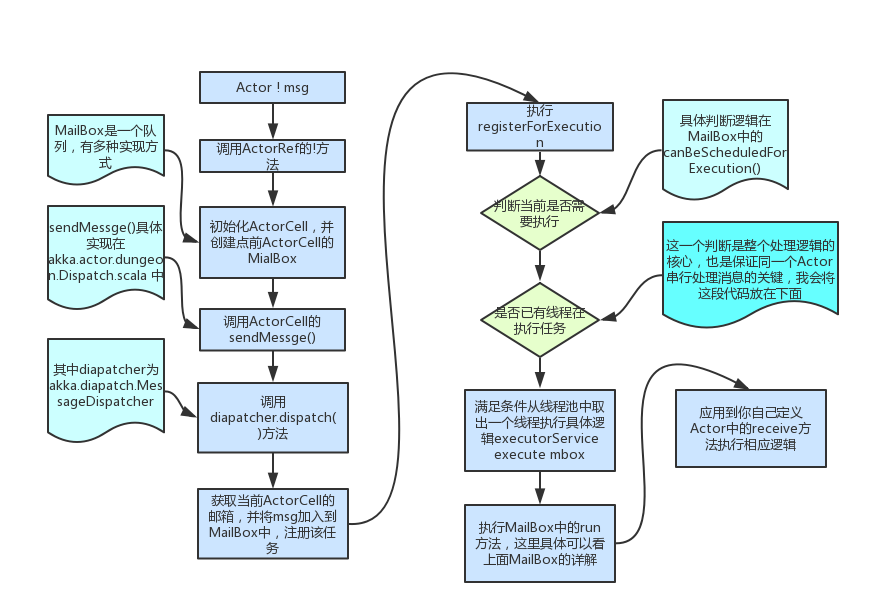
消息的大致流程我都在图中给出,还有一些细节,必须序列化消息,获取状态等就没有具体说明了,有兴趣的同学可以自己去阅读以下Akka的源码,个人觉得Akka的源码阅读性还是很好的,比如:
- 基本没有方法超过20行
- 不会有过多的注释,但关键部分会给出,更能加深自己的理解
当然也有一些困扰,我们在不了解各个类,接口之间的关系时,阅读体验就会变得很糟糕,当然我用IDEA很快就解决了这个问题。
我们这里来看看关键的部分:Actor是如何保证串行处理消息的?
上图中有一根判定,是否已有线程在执行任务?我们来看看这个判定的具体逻辑:
@tailrec
final def setAsScheduled(): Boolean = { //是否有线程正在调度执行该MailBox的任务
val s = currentStatus
/*
* Only try to add Scheduled bit if pure Open/Suspended, not Closed or with
* Scheduled bit already set.
*/
if ((s & shouldScheduleMask) != Open) false
else updateStatus(s, s | Scheduled) || setAsScheduled()
}从注释和代码的逻辑上我们可以看出当已有线程在执行返回false,若没有则去更改状态为以调度,直到被其他线程抢占或者更改成功,其中updateStatus()是线程安全的,我们可以看一下它的实现,是一个CAS操作:
@inline
protected final def updateStatus(oldStatus: Status, newStatus: Status): Boolean =
Unsafe.instance.compareAndSwapInt(this, AbstractMailbox.mailboxStatusOffset, oldStatus, newStatus)到这里我们应该可以大致清楚Actor内部是如何保证共享内存的一致性了,Actor接收消息是多线程的,但处理消息是单线程的,利用MailBox中的Status来保障这一机制。
总结
通过上面的内容我们可以总结出以下几点:
- Akka并不是说用了什么特殊魔法来保证并发的,底层使用的还是Java和JVM的同步机制
- Akka并没有使用任何的锁机制,这就避免了死锁的可能性
- Akka并发执行的处理并没有使用线程切换,不仅提高了线程的使用效率,也大大减少了线程切换消耗
- Akka为我们提供了更高层次的并发抽象模型,让我们不必关心底层的实现,只需着重实现业务逻辑就行,遵循它的规范,让框架帮我们处理一切难点吧
