PyCharm下进行Scrapy项目的调试,可以在爬虫项目的根目录创建一个main.py,然后在PyCharm设置下运行路径,那么就不用每次都在命令行运行代码,直接运行main.py就能启动爬虫了。
1、首先创建一个Scrapy项目:
在命令行输入:
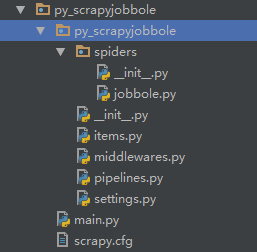
scrapy startproject project_nameproject_name为项目名称,比如我的项目名称为py_scrapyjobbole,生成的目录为:
2、创建新的Spider
在命令行输入:
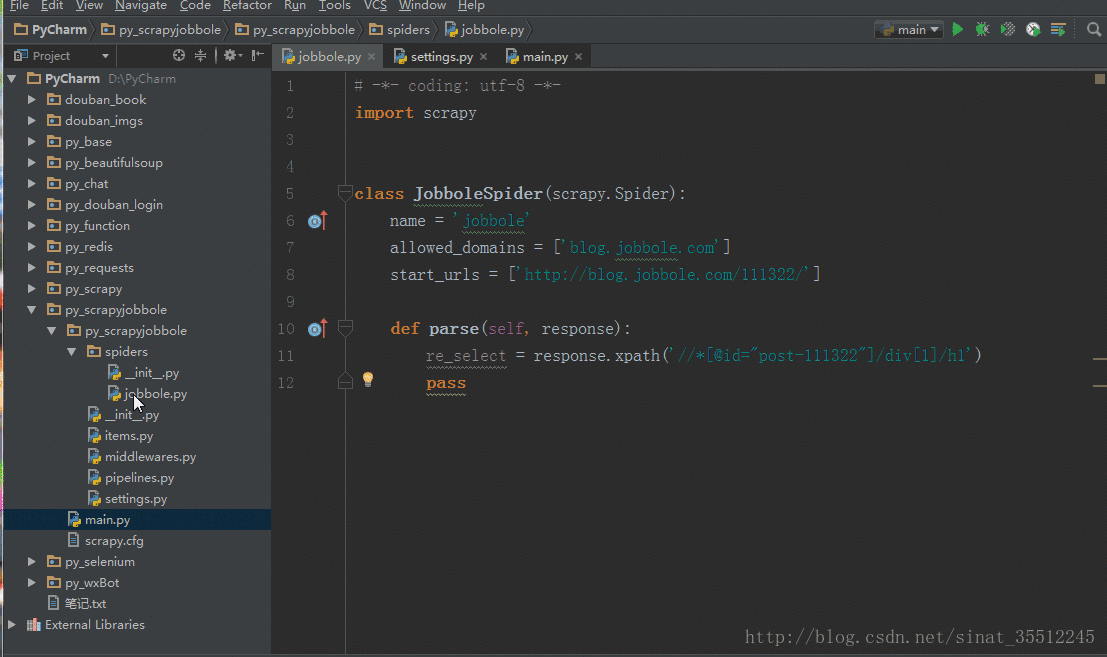
scrapy genspider jobbole(spider名称) blog.jobbole.com(爬取的起始url)# -*- coding: utf-8 -*-
import scrapy
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/111322/']
def parse(self, response):
re_select = response.xpath('//*[@id="post-111322"]/div[1]/h1')
pass3、配置setting.py文件(这步很重要)
BOT_NAME = 'py_scrapyjobbole'
SPIDER_MODULES = ['py_scrapyjobbole.spiders']
NEWSPIDER_MODULE = 'py_scrapyjobbole.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'py_scrapyjobbole (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = FalseROBOTSTXT_OBEY = False一定要设置成 False,断点调试才能正常进行。<>
4、在工程目录下建立main.py文件,稍后将会在这里面进行调试!
from scrapy.cmdline import execute
import sys
import os
# 打断点调试py文件
# sys.path.append('D:\PyCharm\py_scrapyjobbole')
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
print(os.path.dirname(os.path.abspath(__file__)))
execute(['scrapy', 'crawl', 'jobbole'])5、进行断点调试
附录
xpath相关知识
在用Scrapy进行数据爬取时可能会用到xpath相关知识,所以简单地展示一张图:
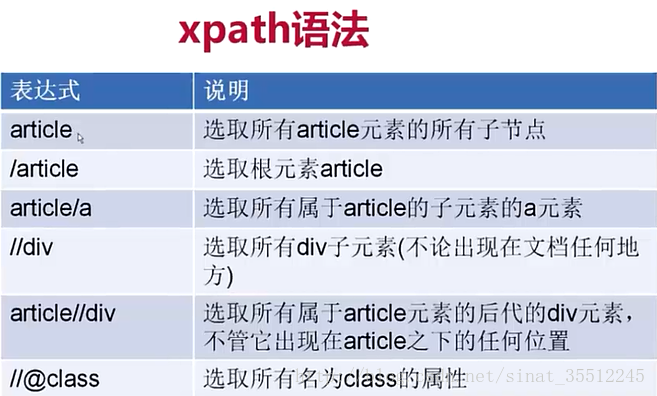
在这里面值得注意的是‘’/“和”//“的区别!
/:代表子元素,选取的元素必须是父子关系
//:代表所有后代元素,选取的元素不一定是父子关系,只要是后代元素即可
不过,大家要是觉得难的话,也可以利用chrome的元素查找功能进行xpath路径的复制: