

前两篇文章,从业务端和技术端分析了秒杀系统的构建中我们可以采用的思路。收到部分同学的留言,问了一些细节上的问题,今天会集中整理一下这些问题,作为秒杀系列的一个收尾。
昨天提到了商品详情页要做静态化的问题。实际上,页面上还是有一些动态数据,例如购买人数,购买比例这样的动态数据(见下图),那么问题就来了,在秒杀条件下,这种频繁更新的动态数据一旦数据更新不及时,会有大量的前端请求,透传到后端来,会不会导致超卖呢?
这是一个很好的问题,我这里的答案是,不会的,最终的一致性不是靠前端来完成的。在读的场景下,为了保证系统的整体性能,我们是可以允许一定的“脏数据”,这里的不一致性的影响是很有限的,只会让少量一些原本已经没有库存的下单请求误认为还有库存而已。在达到CAP的过程中,需要有所平衡和取舍,这里就是通过一致性来换取高可用性做平衡,来解决这种高并发的数据读取问题。
从这个问题,我们可以引申出一个我们秒杀系统中读写数据的原则
读数据: 不做强一致性校验,数据通过分层校验来修正。
写数据: 写数据进行强一致性校验,通过限流保护来保证写数据的成功性。
根据这个原则,在秒杀功能中,我们会分层对数据流进行不同的处理方式:
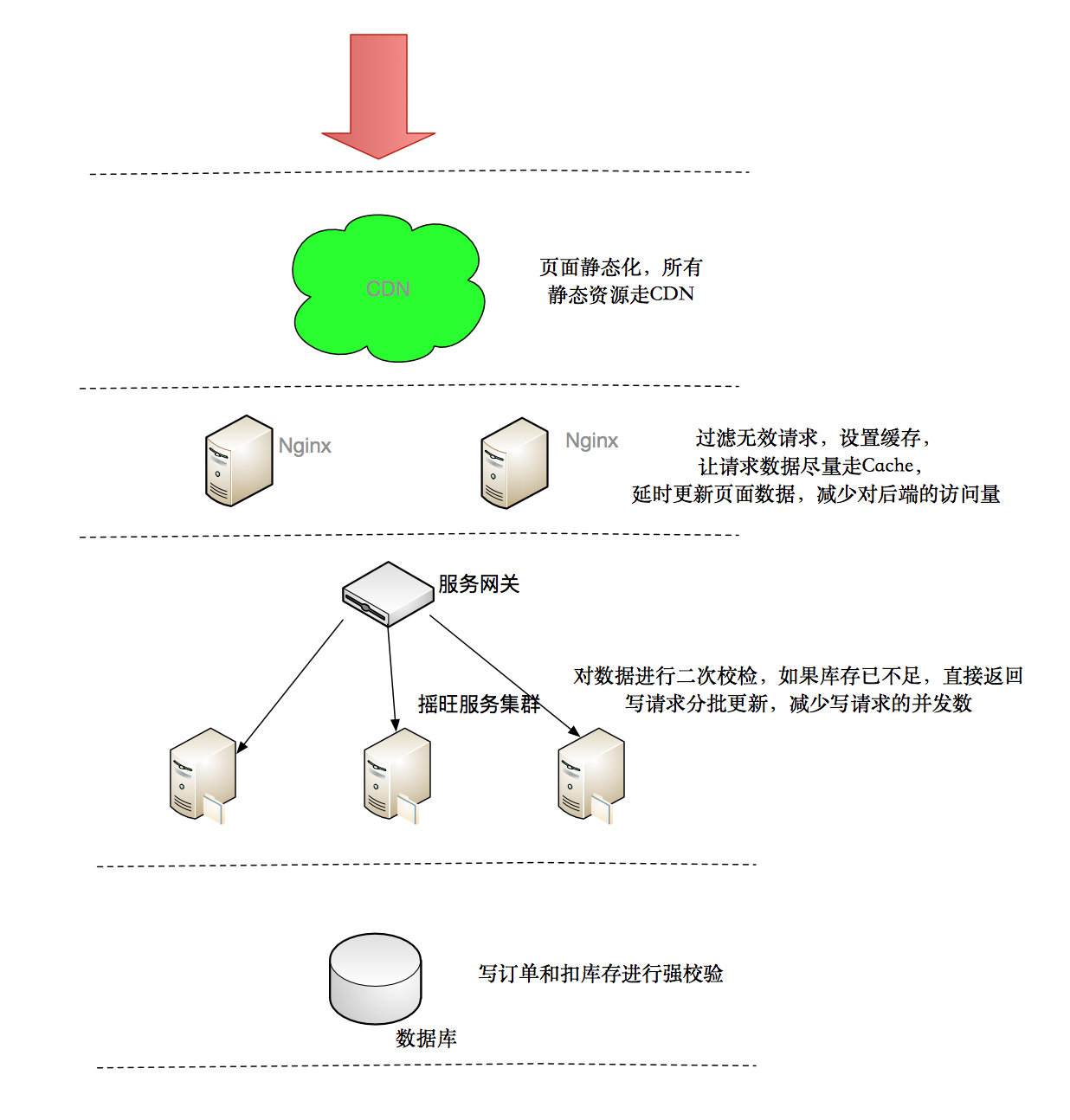
1. 通过CDN,把大量静态不需要检验的数据放在系统之外的地方;减少不必要的流量到服务器端。
2. 预加载用户静态信息,在前端读系统中检验一些基本信息,如用户是否具有秒杀资格、商品状态是否正常、秒杀是否已经结束等;过滤大量无效请求。
3. 在写数据系统中再校验一些如是否是非法请求,写的数据一致性如检查库存是否充足等;
4. 最后在数据库层保证数据最终准确性,避免超卖。
处理并发锁的一个思路
昨天的文章其实已经提到了两个解决的办法,1. 应用层对数据提交排队,走队列,降低并发度。 2. 水平分库,物理上进行分流。
今天再提供一个野路子:
1. 将秒杀产品数据记录A,拆分为10条,A1, A2... A10。
2. 库存数分担到这10条记录中。
3. 订单服务有一个随机函数Rom(),生成订单记录前,根据函数结果决定从某一条记录中扣除库存。
4. 秒杀结束后,通过程序,对订单记录进行一个批量处理,对订单数据进行整合。
这个思路的出发点是以最小的代价降低单条行锁的压力,保证高压下写操作的成功率。当然,这背后是要建立一套产品和订单的归并映射逻辑。
扫描二维码或手动搜索微信公众号【架构栈】: ForestNotes
欢迎转载,带上以下二维码即可

