

上一篇 一小时搭建微信聊天机器人 介绍了如何搭建一个可用的聊天机器人,但是和机器人聊完你会发现,聊天机器人实在是太傻了,来回就那么几句。这是因为我们给聊天机器人的数据太少,他只能在我们给的训练集中找它认为最合适的。那么,如何导入更多的训练数据呢?
我能想到最简单的方法是找对话的数据,然后把这些数据作为训练数据训练机器人。
感谢 candlewill 已经收集好了大量的训练数据,dialog_corpus https://github.com/candlewill/Dialog_Corpus 。
这个库中包含电影台词、中英文短信息、自然语言处理相关的数据集、小黄鸡语料等。这里我选择电影台词语料。
语料地址为:dgk_lost_conv:https://github.com/rustch3n/dgk_lost_conv
chatterbot 训练逻辑处理模块
这个模块提供训练机器人的方法,chatterbot自带了通过输入list来训练(["你好", "你好啊"] 后者是前者的回答)以及通过导入Corpus格式文件来训练的方式。
这里我们选择使用第一种,通过输入list来训练机器人。
处理训练数据
首先下载数据集:
wget https://codeload.github.com/rustch3n/dgk_lost_conv/zip/master
# 解压
$ unzip dgk_lost_conv-master.zip我们先打开一个文件看下数据结构:
E
M 你得想想办法 我弟弟是无辜的
M 他可是美国公民啊
M 对此我也无能为力
M 你当然能
M 再去犯罪现场看看 定能证实清白
M 你看 我不过是个夜间办事员而已
M 你若真想解决问题
M 最好等领事来
M 他早上才上班
M 我很抱歉
E
M 那我自己来搞定
M 你兄弟
M 关在哪个监狱?
M 索纳监狱
E
M 怎么了?
M 那里关的都是最穷凶极恶的罪犯
M 别的监狱都不收.conv 语料文件中:E 是分隔符 M 表示会话。因为我是使用输入list 的方式训练数据,这时我可以以分隔符E为分隔,将一段对话放入一个list中,那么上述例子中的训练数据应该被格式化为:
convs = [
[
'你得想想办法 我弟弟是无辜的',
'他可是美国公民啊',
'对此我也无能为力',
'你当然能',
'再去犯罪现场看看 定能证实清白',
'你看 我不过是个夜间办事员而已',
'你若真想解决问题',
'最好等领事来',
'他早上才上班',
'我很抱歉'
],
[
'那我自己来搞定',
'你兄弟',
'关在哪个监狱?',
'索纳监狱',
],
[
'怎么了?',
'那里关的都是最穷凶极恶的罪犯',
'别的监狱都不收',
]
]导入训练数据的脚本如下:
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
# 初始化聊天机器人
momo = ChatBot(
'Momo',
storage_adapter='chatterbot.storage.MongoDatabaseAdapter', # 使用mongo存储数据
logic_adapters=[ # 指定逻辑处理模块
"chatterbot.logic.BestMatch",
"chatterbot.logic.MathematicalEvaluation",
"chatterbot.logic.TimeLogicAdapter",
],
input_adapter='chatterbot.input.VariableInputTypeAdapter',
output_adapter='chatterbot.output.OutputAdapter',
database='chatterbot', # 指定数据库
read_only=True
)
# 读取.conv 数据文件,因为我服务器配置较低,所以选择了一个内容较少的文件
# 这个函数是一个生成器
def read_conv(filename='prisonb.conv'):
with open(filename, 'rt') as f:
conv = []
# 逐行读取
for line in f:
_line = line.replace('\n', '').strip() # 预处理字符串 去掉首位空格
if _line == 'E': # 如果是分隔符 表示对话结束 返回对话列表
yield conv
conv = [] # 重置对话列表
else: # 不是分隔符则将内容加入对话列表
c = _line.split()[-1] # 其实这里如果对话中包含空格 对话数据会不完整,应该只去掉M和开头的空格
conv.append(c)
def traine_momo():
for conv in read_conv():
print(conv)
momo.set_trainer(ListTrainer) # 指定训练方式
momo.train(conv) # 训练数据
def main():
traine_momo()
if __name__ == '__main__':
main()这个脚本比较简单,只是简单的将数据从对话文件中读取出来,然后拼接为对话列表输入聊天机器人。
由于这里对话大部分都是多行数据,聊天机器人匹配结果时运算量会大幅提升,我单核cpu的服务器在导入一个700k 的语料文件后每次聊天都会让cpu飚到100%!🤦 无奈之下只能删掉大半数据。
对话示例如图:
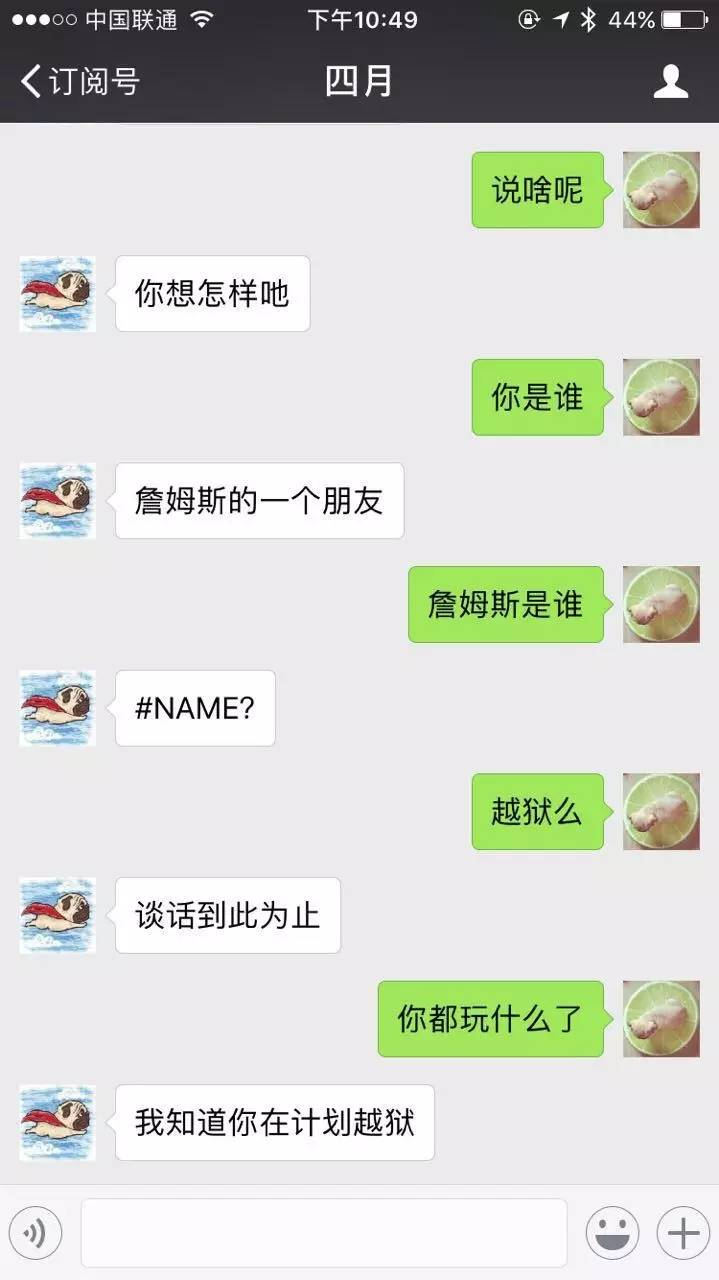
导入电影台词后,虽然训练数据大幅提升,但是你会发现聊天机器人开始答非所问了,这是因为聊天数据噪音太大,对白也有点问题。
使用图灵机器人训练
之前在对比聊天机器人实现方案的时候,我试用过 图灵机器人,他们号称中文语境下智能渡最高的机器人大脑。他们的对话比我自己的搭建的靠谱很多,那么我们是不是可以利用一下他的数据呢?
我的方案是这样的,在图灵机器人新建两个机器人教练A 和 教练B,让两个机器人互相对话,然后把训练数据导入chatterbot。
- 打开 www.tuling123.com,注册账号
- 新建两个机器人(免费用户最多可以创建5个,每个机器人每天最多请求5000次)
- 调用对话API,让两个机器人互相聊天
建好机器人后的界面:

训练示例代码如下:
# tuling_trainer.py
import sys
from time import sleep
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
import requests
API_URL = "http://www.tuling123.com/openapi/api"
API_KEY0 = "" # 机器人1 的key
API_KEY1 = "" # 机器人2 的key
# 初始化chatterbot
momo = ChatBot(
'Momo',
storage_adapter='chatterbot.storage.MongoDatabaseAdapter',
logic_adapters=[
"chatterbot.logic.BestMatch",
"chatterbot.logic.MathematicalEvaluation",
"chatterbot.logic.TimeLogicAdapter",
],
input_adapter='chatterbot.input.VariableInputTypeAdapter',
output_adapter='chatterbot.output.OutputAdapter',
database='chatterbot',
read_only=True
)
# 请求图灵机器人接口
def ask(question, key, name):
params = {
"key": key,
"userid": name,
"info": question,
}
res = requests.post(API_URL, json=params)
result = res.json()
answer = result.get('text')
return answer
def A(bsay):
# 打印 A 和 B 的对话内容
print('B:', bsay)
answer = ask(bsay, API_KEY0, 'momo123')
print('A:', answer)
return answer
def B(asay):
print('A:', asay)
answer = ask(asay, API_KEY1, 'momo456')
print('B', answer)
return answer
def tariner(asay):
momo.set_trainer(ListTrainer) # 设置处理方式
while True: # 两个机器人训练的主循环
conv = []
conv.append(asay) # 先把 A 说的第一句加入到对话列表
bsay = B(asay) # A 先问 B
conv.append(bsay) # 将B 的回答加入到对话列表
momo.train(conv) # 将对话用于训练
print(conv)
conv = []
conv.append(bsay) # 用B的对话 去问 A 步骤和上述方式一致
asay = A(bsay)
conv.append(asay)
momo.train(conv)
print(conv)
sleep(5) # 控制频率
def main(asay):
tariner(asay)
if __name__ == '__main__':
main(*sys.argv[1:]) # 接收参数作为开始的第一句话
# 执行脚本
# python tuling_trainer.py 你好?使用图灵聊天机器人训练的时候是需要监测的,因为如果两个机器人说的内容一样的时候,机器人可能会一直重复同一句话,直到调用次数耗尽,你需要看一下两个机器人的对话是否陷入了僵局。
当然也可以在程序中加入判断,先多设定几个开始打招呼的句子,如果一句话连续出现多次的时候,换下一个句子纠正他们。
以下是我训练了两天之后的结果:
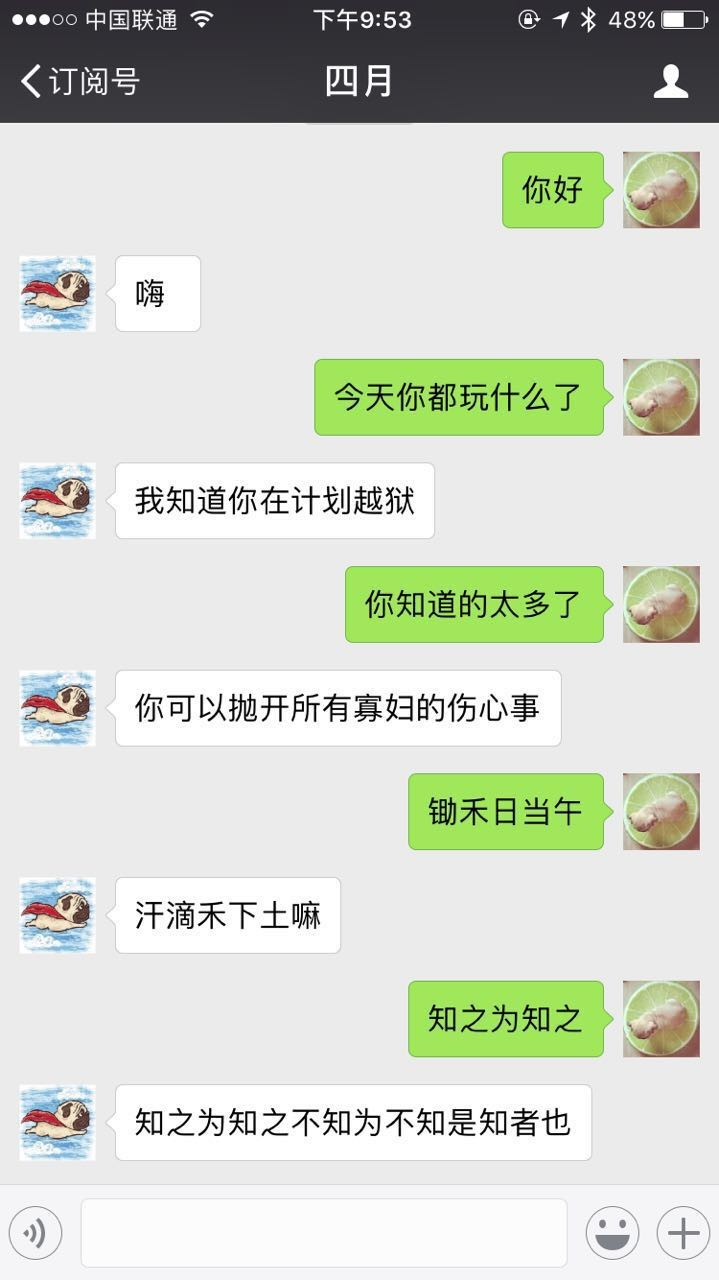
虽然还是答非所问,但是已经比之前像样了。
图灵聊天机器人免费版每天可调用5000 次,如果觉得次数太少可以多新建几个轮流使用
聊天机器人的配置及训练方式就到这里了,接下来介绍个更实用的功能,如何让微信公号变成图床。
如何让微信公号化身图片上传助手
在使用 markdown 格式来写文章的过程中,发现图片地址是一个比较麻烦的事情,每次贴图获取图片URL都是一个比较麻烦的过程。
以我使用的七牛为例,获取图片地址的步骤如下:
- 登录七牛网站,打开存储空间>内容管理
- 上传文件
- 返回内容管理找到刚才上传的文件,获取外链
按照这个步骤上传一张图片至少耗时半分钟。
那能不能简化这个步骤呢?
答案是可以!
微信公号是可以发送图片消息的,我的做法是
- 将图片发送到公号
- 服务器获取触发图片消息的处理逻辑> 将图片使用七牛提供的
第三方资源抓取API另存到,七牛存储空间 - 将设定好的图片地址返回给微信,发送到公号消息对话中
示例如下图所示:
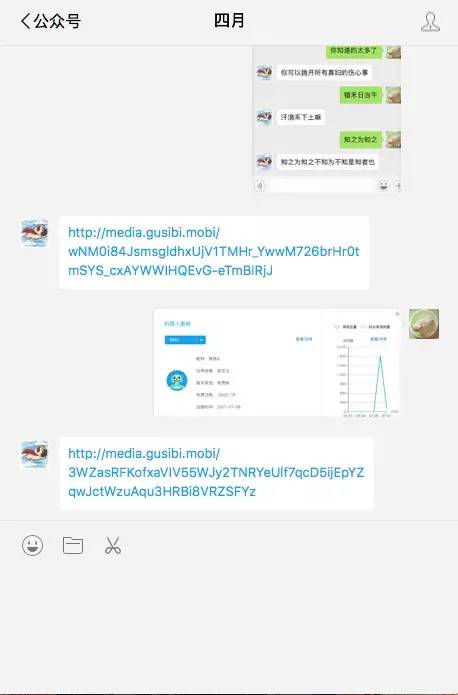
实现步骤
- 注册个七牛账号
- 新建存储空间
- 在个人中心秘钥管理获取 AccessKey 和 SecreKey
- pip install qiniu
代码实现如下:
# media.py
# 图片抓取逻辑处理
from qiniu import Auth, BucketManager
from momo.settings import Config
def qiniu_auth():
access_key = str(Config.QINIU_ACCESS_TOKEN)
secret_key = str(Config.QINIU_SECRET_TOKEN)
auth = Auth(access_key, secret_key)
return auth
def media_fetch(media_url, media_id):
'''抓取url的资源存储在库'''
auth = qiniu_auth()
bucket = BucketManager(auth)
bucket_name = Config.QINIU_BUCKET # 存储空间名称
ret, info = bucket.fetch(media_url, bucket_name, media_id) # 参数依次是第三方图片地址,空间名称,目标文件名
if info.status_code == 200:
return True, media_id # 如果上传成功,返回文件名
return False, None抓取第三方图片文档地址为:第三方资源抓取 https://developer.qiniu.com/kodo/api/1263/fetch。
微信图片消息处理逻辑代码:
class WXResponse(_WXResponse):
def _image_msg_handler(self):
media_id = self.data['MediaId']
picurl = None
if not picurl:
picurl = self.data['PicUrl'] # 从消息中获取图片地址
is_succeed, media_key = media_fetch(picurl, media_id) # 使用图片抓取接口将图片存储到七牛并获取图片文件名
if is_succeed:
qiniu_url = '{host}/{key}'.format(host=Config.QINIU_HOST, key=media_key) # 拼接图片地址
else:
qiniu_url = '图片上传失败,请重新上传'
self.reply_params['content'] = qiniu_url # 返回图片地址
self.reply = TextReply(**self.reply_params).render()代码已开源道github,详细代码逻辑参考 gusibi/momo: https://github.com/gusibi/momo/tree/chatterbot
欢迎试用体验:
- 请不要上传高清图片,微信会压缩损坏图片质量
- 也不要上传太个人的图片,毕竟内容我能看到
总结
这一篇主要提供了两个训练 chatterbot 的思路,以及使用公号作为图片上传客户端提高上传图片的效率的解决方法。
接下来公号还是继续开发,准备给公号加一个记账功能,促使自己养成记账的习惯。
预告
下一篇的公号DIY 将介绍 记账的功能设计以及实现思路。
最后,感谢女朋友支持。
| 欢迎关注(April_Louisa) | 请我喝芬达 |
|---|---|
 |
 |
