

- 原文地址:From Automatons to Deep Learning
- 原文作者:Mark Aduol
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:Xat_MassacrE
- 校对者:Tina92,Feximin
从金属巨人到深度学习
AI(人工智能)简史
塔罗斯是一个青铜巨人战士,被创造出来守护克里特岛,抵御海盗和入侵者的攻击。他每天绕克里特岛三周,他凶狠的外表迫使海盗去别的地方寻找宝藏。但是在他凶狠外表的背后,塔罗斯根本算不上一个战士。他只是一个机器人。一个按照战士的样子做出来的稻草人。但是我们仍然相信造物主给类似塔罗斯这样的生物注入了非常真实的思考、情感、想法和智慧。这当然是无稽之谈。塔罗斯仅仅是人类历史长河最近的一个关于智能思想的梦想:创造生物的渴望,创造像我们自己一样智能生物的梦想。
用作家 Pamela McCorduck 的话来说就是:"一个模仿上帝的古老愿望。"
科学家、数学家、哲学家和作家们一直在寻找创造“会思考的机器”的秘诀。比人类本身更好的”会思考的机器“。
从创造出塔罗斯这样会动的机器开始,人类中的创造者已经不满足于简单的模仿,而是开始寻求内在的真实。无意识的机器人让它们窥见了智能应该是什么样子,但是这种创造物并不能揭示智能的实质。因此,他们不得不考虑智能最为明显的表现:人类的思想。
但是很快我们发现,人类区别与低等生物的主要原因并不是我们脑容量的大小,也不是我们在地球上生存的经验,而是我们强大的处理各种推理任务的能力。所以当我们构思出第一台可编程的计算机时,并没有什么好惊讶的,并且这个计算机还可以模拟任何正式的推理过程,至少要和人类一样,经考证,单词 "computer" 第一次被使用是在 1940 年代的英格兰,当时它的意思是”一个会计算的机器“。
起初,发展的很慢。马克一号 —1940 年代最先进的机器诞生了 — 它是由数千个机械组件构成的重达 10,000 磅的庞然大物。使用了 500 英里的电线给它供电,但是即使是这样精心制作的配置,每秒钟也只能执行 3 次加法。但是随着摩尔定理的问世,计算机性能飞速发展,并且在各种各样任务的形式推理中拥有着超人表现。研究人员对这一进展既高兴又惊讶,并且指出以目前的进步的速度来看,第一个完全成熟的”会思考的机器“即将诞生。在 1960 年代, 20 世纪人类知识巨匠之一的赫伯特·西蒙曾声称”在 20 年之内,机器将能够胜任任何人类可以做的事情”,毫无疑问,他错了。
事实证明,虽然计算机擅长解决那些被一系列逻辑和数学规则定义的问题,但是更大的挑战则是让计算机解决那些不能被抽象成正规的声明语句的问题。比如识别图片中的人脸或者是翻译人类的语音。
在一个如此嘈杂的世界里,一台能够和超人下国际象棋的机器对于赢得冠军或许是有用的,但是在真实的世界里,它的作用就如同小黄鸭一样不值一提(除非你的工作就是调试小黄鸭)。
这个认识导致几个 AI 研究员否认了符号 AI(曾经一度统治 AI 研究的形式推理方法的一个术语)是创造人造智能机器最好方法的基本原则。符号 AI 的基石像情景推演和谓词逻辑都被证明太严苛以致于不能捕捉到现实世界中所有的不确定因素。AI 领域需要一个全新的方法。
一些研究员决定使用一个叫做“模糊逻辑”的方法来寻求答案,模糊逻辑是一种真值不仅仅是 0 或者 1 还可以是任何中间值的逻辑范式。另外一些研究员则把所有努力都放在了叫做“机器学习”的新兴领域。
机器学习是由于形式推理处理真实世界的不确定性因素的不足而诞生的。它不是将世界上的知识进行一个严格的逻辑公式的绑定,而是让计算机自己去学习知识。不是简单的告诉它“这是椅子”,"这是桌子",而是教计算机学习椅子和桌子概念的区别 。机器学习研究员们一直避免使用必然的事件来代表世界,因为严格的特征条件并不是真实世界的本质。
相反,他们决定用统计和概率来模型化这个世界。
机器学习算法不是使用真和假来判断,而是使用真假的程度来判断。换句话说就是 — 概率。
使用概率来量化真实世界的不确定性使得贝叶斯统计成为了机器学习的基石。对此,“频率学派” 也是有话要说的,但是关于频率学派和贝叶斯学派的争论我们最好在另一篇文章详述。
很快,像”逻辑回归“和”朴素贝叶斯“这样的简单的机器学习算法就已经可以告诉计算机如何过滤垃圾邮件以及根据房屋大小来预估价格了。逻辑回归是一个非常直接的算法:给一个输入向量 x,模型只需要将 x 分类到 {1, 2, …, k} 中的一个就可以了。
不过有一个条件。
这些简单算法的表现严重依赖于训练数据的表现。(Goodfellow et al. 2017)
总的来说就是,想象这样一个场景,你做了一个使用逻辑回归来决定是否剖腹产的机器学习系统。这个系统无法直接检测病人,而是由一个医生来给这个系统喂信息。这些信息可能会包含子宫疤痕、怀孕了几个月以及病人的年龄。每一个单独的信息都是一个特征,把它们合在一起,对于 AI 系统来说就是这个病人的表示。
通过一些训练数据的训练,逻辑回归可以获得病人的这些特征中每一项与不同结果的关系。举例来说就是如果训练数据中没有包含分娩过程中恶心的概率和母亲年龄增长之间的关系的话,那么这个算法就不太可能为年纪大的病人推荐处理流程。
虽然逻辑回归可以将表示映射到结果上,但t实际上它并不能真切地影响到构成病人表示的特征。
如果逻辑回归不是从医生那里获得一份正式的报告,而是只有一张病人的核磁共振扫描结果,那么它就不能做出有用的预测。(Goodfellow et al. 2017)
在分娩时期病人是否会有并发症的风险这个方面,核磁共振图的每一个独立的像素能告诉我们的信息太少了。
这取决于有一个良好的表示,如果有优秀的表现那么无论对于计算机科学还是每日的生活都是一个伟大的贡献。举例来说就是你可以在 Spotify 上快速的搜索到你想要找的歌曲,因为它们的音乐集是使用一种类似于三叉树的智能数据结构,而不是用类似于乱序数据的粗旷结构来存储的。还有一个例子就是,学校里的孩子可以轻松的处理阿拉伯数字的算术,而处理罗马数字的算术却异常困难。机器学习没什么不同,输入表示的不同将会对你的学习算法的表现产生巨大的影响。
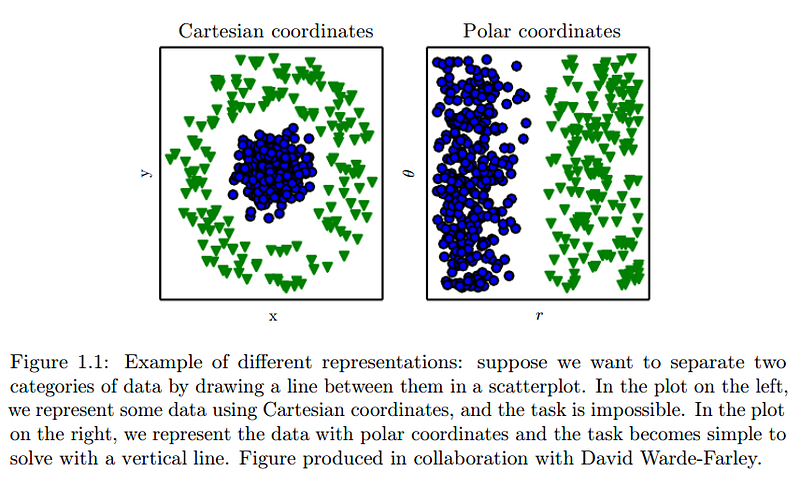
David Warde-Farley, Goodfellow et al. 2017
由于这个原因,在人工智能领域中很多问题最后都可以归结为寻找合适的表示并把它作为输入数据。举个例子,假设我们设计了一个算法用于识别 Instagram 照片中的汉堡。首先,我们要根据所有的汉堡构建出一个特征集。首先我们要尝试的或许就是通过图片的原始像素的值来描述汉堡。起初这或许是一个明智的做法,但是很快你就会发现并不是。
单纯凭借原始像素来描述汉堡长啥样是十分困难的,其实你可以想一下在麦当劳点汉堡的情景。当你点你想要的汉堡时,你应该会通过各种”特征“来描述要点的汉堡,比如奶酪、中间的肉饼、芝麻、生菜、红洋葱以及其他的调味料。我们可以通过不同的成分的集合来描述汉堡,每一个成分又可以用它本身的特征集来描述。大部分汉堡的成分可以用它们的的颜色和外形来描述,那么一个汉堡就可以它的不同的成分的颜色和外形来描述了。
但是当汉堡不在图片的中心位置,或者被放置在一个与之颜色相近的食物旁边,又或者在一个异域风情的饭店里汉堡是被分开提供的时候会发生什么呢?这时我们的算法又将如何区分以及解构汉堡呢?一个显而易见的办法是添加更多的(不同的)特征,但是这只是临时的解决办法。很快,我们就会发现更多的边界条件,然后我们就又要在我们的特征集里面添加更多的特征来区别相似的图片。随着输入表示的复杂,计算成本也随之提高,事情就变的更加复杂了。现在的开发者不仅要关注特征的数量还要还要关注输入表示的所有特征的表达力是否足够。寻找完美特征集对于任何机器学习算法来说都是一个艰苦卓绝的任务,研究人员同时也耗时耗力。一个经验丰富的社区可能都要研究几十年。
对于学习算法来说衡量表示输入好坏的问题又被称作表示问题。
从 1990 年后期到 2000 年早期,机器学习算法在处理不完美输入表示的弱点本质上其实是 AI 领域研究过程中的瓶颈。当设计输入特征的表示时,为了弥补算法上的弱点,工程师们除了依赖于人类的灵感和问题领域的前置知识以外别无他法。从长远来看,这样的"特征工程"其实是站不住脚的。如果一个学习算法不能够从原始数据和未被过滤的数据中获取有利信息,那么从一个更哲学角度讲,这些算法是不能理解这个世界的。
尽管有这么多的障碍,研究人员们依然很快就发现了解决问题的方法。如果一个机器学习算法可以把表示映射到输出,那么为什么让这些算法学习表示本身呢。这就是表示学习。关于表示学习最著名的例子应该就是自编码(神经网络的一种)了,它是基于人类大脑和神经系统建模的计算机系统。
一个自编码实际上就是一个可以将输入转化为不同表示的编码函数和一个可以将这个中间表示转换回它的原始格式(尽可能多的保留信息)的解码函数的组合。结果就是我们会得到一个在编码器和解码器之间正确的分割,它可以将用来训练的的”噪音“图片的解码成更有用的表示。举例来说就是一张拥有在相似颜色中隐藏的汉堡的 Instagram 图片。这个解码器将会消除这个”噪音“,仅仅保留可以描述汉堡本身的的特征。
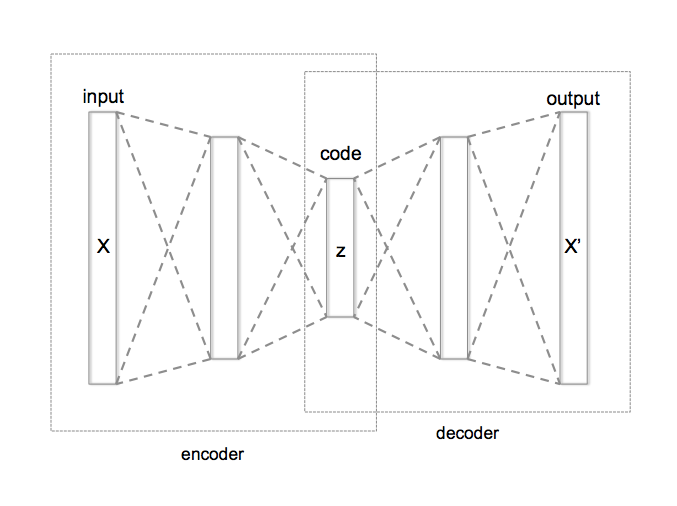
By Chervinskii — Own work, CC BY-SA 4.0, commons.wikimedia.org/w/index.php…
但是对于自编码来说,问题仍然存在。为了消除噪音,自编码和一些其他的表示学习算法必须能够准确的决定对于输入数据的描述来说什么是最重要的因素。我们想要我们的算法更好的分辨出哪些是我们感兴趣的图片(包含汉堡的)和哪些是我们不感兴趣的图片。对于这个例子来说,如果我们不是关注图片原始像素的值,而是将更多的注意力放在图片成分的外形和颜色上,那么在分辨有汉堡图片和无汉堡图片这个问题上显然更有优势。当然了,说比做总是要容易的多。关键点就是告诉算法如何从没用的因子中解构出有用的因子,这就是变量因子。
乍一看,表示学习似乎无法为我们提供帮助,但是让我们再研究研究。
一个编码器通过隐藏层(中间层)获取一个输入表示,将这个输入压缩成一个较小的格式。解码器做一个相反的事情:将输入解压回到原来的格式,尽可能多的保留数据。在这两个情况下,如果隐藏层知道哪些因子是描述输入最重要的,那么输入的信息将会得到最好的保留,然后确保这些因子没有在输入中被清除并传递到下一层。
在上面的图标中,编码器和解码器都只包含一个隐藏层,一个被压缩,一个被解压。层的数量导致粒度的匮乏意味着这个算法为了最大限度的保留信息,会在判断输入的压缩和解压的好坏时弹性不足。但是如果我们做一个小调整,将几个隐藏层堆叠起来,一个接一个,那么我们就会给算法提供更大的自由度,同时算法也会在选择权重因子时对输入的压缩和解压达到最好的效果。
这种使用多个隐藏层的神经网络算法就是深度学习。
但是这并没有结束,深度学习还要再深入一步。在使用多个隐藏层时,我们可以组合多个简单的层来构建复杂的表示。通过一个一个的堆叠隐藏层,我们可以分辨出每一个层的变量因子。这会让我们的算法拥有用通过多个简单层的来表达高深复杂的概念的能力。
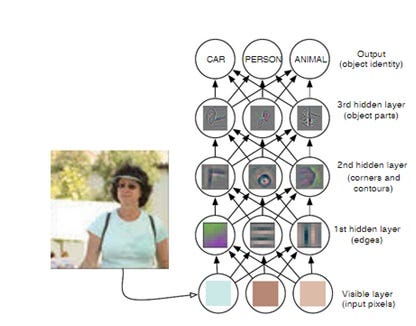
Zeiler and Fergus (2014)
深度学习历史悠久。这个领域的核心观点在 1960 年代就通过多层感知器被提出来了。反向传播算法在 1970 年被正式提出,1980 年代各种人工神经网络也开始陆续登场。但是这些早期的成果又经历了几十年才在实践中得以运用。没有差的算法(有些人并不这样认为),只是我们还没有意识到需要多大的数据量才能让它们变的有用。
越小的数据样本越容易产生极端的结果(因为在统计噪音上会有更大的影响)。越大的数据样本则会减弱噪音的影响并让深度学习模型更精确的知道哪些因子可以最好的描述输入。
在 21 世纪初期深度学习取得如此成就一点也不意外,而几乎同时,大部分科技公司也都发现了它们正坐在一座座未被开发的数据的金山上。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、React、前端、后端、产品、设计 等领域,想要查看更多优质译文请持续关注 掘金翻译计划。
