


我关注的贺老—贺师俊前辈@johnhax 最近发表个这样一条微博:
虽然这条微博没有引起大范围的关注和讨论,但是作为新人,我陷入了思考。究竟 V8 引擎做了哪些魔法,达到了极大限度的优化呢?
这篇文章,将会深入浅出分析这些优化背后的奥秘。希望大神给予斧正和引导,同时对读者有所启发和帮助。
我们到底在讨论什么?
ECMAScript 2015 语言标准规格介绍了几种新的数据结构:比如 Maps 和 Sets(当然还有类似 WeakMaps 和 WeakSets等),而这几个新引入的数据结构有一个共性,那就是都可以根据同样新引入的遍历协议(iteration protocol)进行遍历。这就意味着你可以使用 for...of 循环或者扩展运算符进行操作。举一个 Sets 简单的例子:
const s = new Set([1, 2, 3, 4]);
console.log(...s);
// 1 2 3 4
for (const x of s) console.log(x);
// 1
// 2
// 3
// 4同样对于 Maps:
const m = new Map([[1, "1"], [2, "2"], [3, "3"], [4, "4"]]);
console.log(...m);
// (2) [1, "1"] (2) [2, "2"] (2) [3, "3"] (2) [4, "4"]
console.log(...m.keys());
// 1 2 3 4
console.log(...m.values());
// 1 2 3 4
for (const [x, y] of m) console.log(x, "is", y);
// 1 "is" "1"
// 2 "is" "2"
// 3 "is" "3"
// 4 "is" "4"通过这两个简单的例子,展示了最基本的用法。感兴趣的读者可以参考 ECMA 规范: Map Iterator Objects 和 Set Iterator Objects。
然而不幸的是,这些可遍历的数据结构在 V8 引擎中并没有很好的进行优化。或者说,对于这些实现细节优化程度很差。包括 ECMAScript 成员 Brian Terlson 也曾在 Twitter 上抱怨,指出他使用 Sets 来实现一个正则引擎时遇到了恼人的性能问题。
所以,现在是时间来对他们进行优化了!但在着手优化前,我们需要先彻底认清一个问题:这些数据结构处理慢的真实原因究竟是什么?性能瓶颈到底在哪里?
为了弄清这个问题,我们就需要理解底层实现上,迭代器究竟是如何工作的?
深入主题探索究竟
为此,我们先从一个简单的 for...of 循环说起。
ES6 借鉴 C++、Java、C# 和 Python 语言,引入了 for...of 循环,作为遍历所有数据结构的统一方法。
一个最简单的使用:
function sum(iterable) {
let x = 0;
for (const y of iterable) x += y;
return x;
}将这段代码使用 Babel 进行编译,我们得到:
function sum(iterable) {
var x = 0;
var _iteratorNormalCompletion = true;
var _didIteratorError = false;
var _iteratorError = undefined;
try {
for (var _iterator = iterable[Symbol.iterator](), _step; !(_iteratorNormalCompletion = (_step = _iterator.next()).done); _iteratorNormalCompletion = true) {
var y = _step.value;
x += y;
}
} catch (err) {
_didIteratorError = true;
_iteratorError = err;
} finally {
try {
if (!_iteratorNormalCompletion && _iterator.return) {
_iterator.return();
}
} finally {
if (_didIteratorError) {
throw _iteratorError;
}
}
}
return x;
}需要告诉大家的一个事实是:目前现代 JavaScript 引擎在本质上和 Babel 对 for...of 的去语法糖化处理是相同的,仅仅是在具体一些细节上有差别。
这个事实出处:
All modern JavaScript engines essentially perform the same desugaring that Babel does here to implement for-of (details vary)
上文引自 V8 核心成员,谷歌工程师 Benedikt Meurer。
可是上面经过 Babel 编译后的代码不太好阅读。别急,我删去了烦人的异常处理,只保留了最核心的逻辑供大家参考,以便研究:
function sum(iterable) {
var x = 0;
var iterator = iterable[Symbol.iterator]();
for (;;) {
var iterResult = iterator.next();
if (iterResult.done) break;
x += iterResult.value;
}
return x;
}理解这段代码需要的预备知识需要清楚 for...of 和 Symbol.iterator 方法关系:
一个数据结构只要部署了 Symbol.iterator 属性,就被视为具有 iterator 接口,就可以用 for...of 循环遍历它的成员。也就是说,for...of 循环内部调用的是数据结构的 Symbol.iterator 方法。
for...of 循环可以使用的范围包括数组、Set 和 Map 结构、某些类似数组的对象(比如 arguments 对象、DOM NodeList 对象)、Generator 对象,以及字符串。
我们仔细观察上段段代码,便可以发现迭代器性能优化的关键是:保证在循环中多次重复调用的 iterator.next() 能得到最大限度的优化,同时,最理想的情况是完全避免对 iterResult 的内存分配。能够达到这种目的的几个手段便是使用类似 store-load propagation, escape analysis 和 scalar replacement of aggregates 先进的编译处理技术。
同时,优化后的编译还需要完全消除迭代器本身 —— iterable[Symbol.iterator] 的调用分配,而直接在迭代器 backing-store 上直接操作。
事实上,在数组和字符串迭代器的优化过程中,就是使用了这样的技术和理念。具体的实施文档可以参考这里。
那么具体到 Set 迭代器的性能问题,其实关键原因在与:其实现上混合了 JavaScript 和 C++ 环境。比如,我们看 %SetIteratorPrototype%.next() 的实现:
function SetIteratorNextJS() {
if (!IS_SET_ITERATOR(this)) {
throw %make_type_error(kIncompatibleMethodReceiver,
'Set Iterator.prototype.next', this);
}
var value_array = [UNDEFINED, UNDEFINED];
var result = %_CreateIterResultObject(value_array, false);
switch (%SetIteratorNext(this, value_array)) {
case 0:
result.value = UNDEFINED;
result.done = true;
break;
case ITERATOR_KIND_VALUES:
result.value = value_array[0];
break;
case ITERATOR_KIND_ENTRIES:
value_array[1] = value_array[0];
break;
}
return result;
}这段代码实际上按部就班做了这么几件事情:
- 定义分配了 value_array 数组,初始化时为两项 undefined;
- 定义分配了 result 对象,其格式为 {value: value_array, done: false};
- 调用 C++ %SetIteratorNext runtime 函数,将迭代器的 this 和 value_array 作为参数传递。
- 根据 C++ %SetIteratorNext runtime 函数返回结果,将 result 正确赋值
这就造成什么样的后果呢?遍历的每一步我们都在不断地分配两个对象:value_array 和 result。不管是 V8 的 TurboFan 还是 Crankshaft (V8的优化编译器) 我们都无法消除这样的操作。更糟糕的是,每一步遍历我们都要在 JavaScript 和 C++ 之间进行切换。下面的图,简要表示了一个简单的 SUM 函数在底层的运行流程:
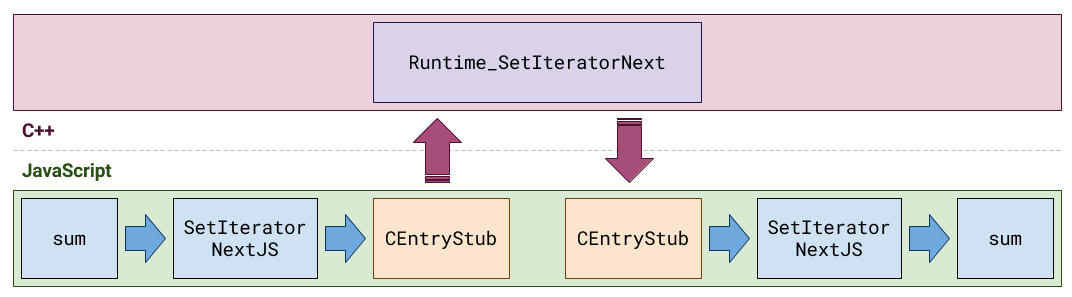
在 V8 执行时,总处在两个状态(事实上更多):执行 C++ 代码和执行 JavaScript 当中。这两个状态之间的转换开销巨大。从 JavaScript 到 C++,是依赖所谓的 CEntryStub 完成,CEntryStub 会触发 C++ 当中指定的 Runtime_Something 函数(本例中为 Runtime_SetIteratorNext)。所以,是否可以避免这种转换,以及避免 value_array 和 result 对象的分配又决定了性能的关键。
最新的 %SetIteratorPrototype%.next() 实现正是切中要害,做了这个“关键”的处理。我们想要执行的代码在调用之前就会变得 hot (热处理),TurboFan 进而最终得以热处理优化。借助所谓的 CodeStubAssembler,baseline implementation,现在已经完全在 JavaScript 层面实现接入。这样我们仅仅只需要调用 C++ 来做垃圾回收(在可用内存耗尽时)以及异常处理的工作。
基于回调函数的遍历
在遍历协议中,JavaScript 同样提供 Set.prototype.forEach 和 Map.prototype.forEach 方法,来接收一个回调函数。这些同样依赖于 C++ 的处理逻辑,这样不仅仅需要我们将 JavaScript 转换为 C++,还要处理回调函数转换为 Javascript,这样的工作模式如下图:
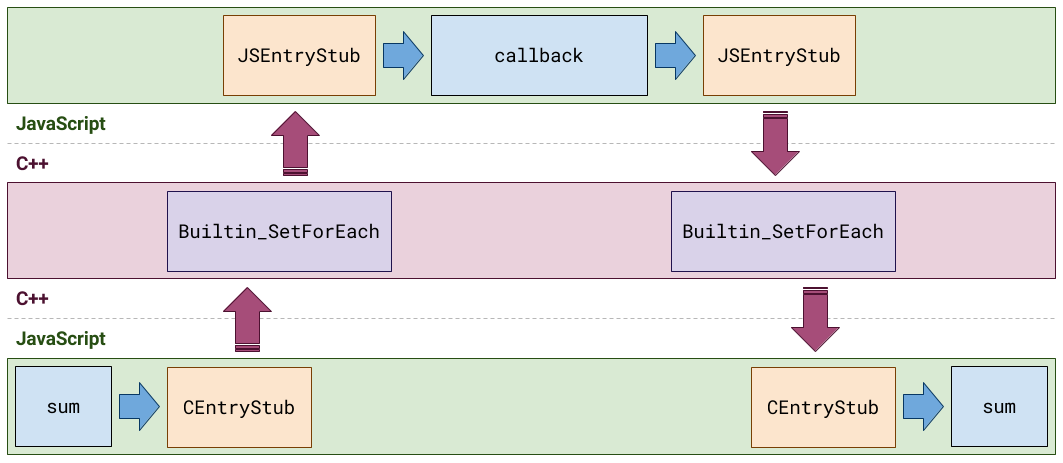
所以,上面使用 CodeStubAssembler 的方式只能处理简单的非回调函数场景。真正完全意义上的优化,包括 forEach 方法的 TurboFan 化还需要一些待开发的魔法。
优化提升 Benchmark
我们使用下面的 benchmark 代码进行优化程度的评测:
const s = new Set;
const m = new Map;
for (let i = 0; i < 1e7; ++i) {
m.set(i, i);
s.add(i);
}
function SetForOf() {
for (const x of s) {}
}
function SetForOfEntries() {
for (const x of s.entries()) {}
}
function SetForEach() {
s.forEach(function(key, key, set) {});
}
function MapForOf() {
for (const x of m) {}
}
function MapForOfKeys() {
for (const x of m.keys()) {}
}
function MapForOfValues() {
for (const x of m.values()) {}
}
function MapForEach() {
m.forEach(function(val, key, map) {});
}
const TESTS = [
SetForOf,
SetForOfEntries,
SetForEach,
MapForOf,
MapForOfKeys,
MapForOfValues,
MapForEach
];
// Warmup.
for (const test of TESTS) {
for (let i = 0; i < 10; ++i) test();
}
// Actual tests.
for (const test of TESTS) {
console.time(test.name);
test();
console.timeEnd(test.name);
}在 Chrome60 和 Chrome61 版本的对比中,得到下面图标结论:
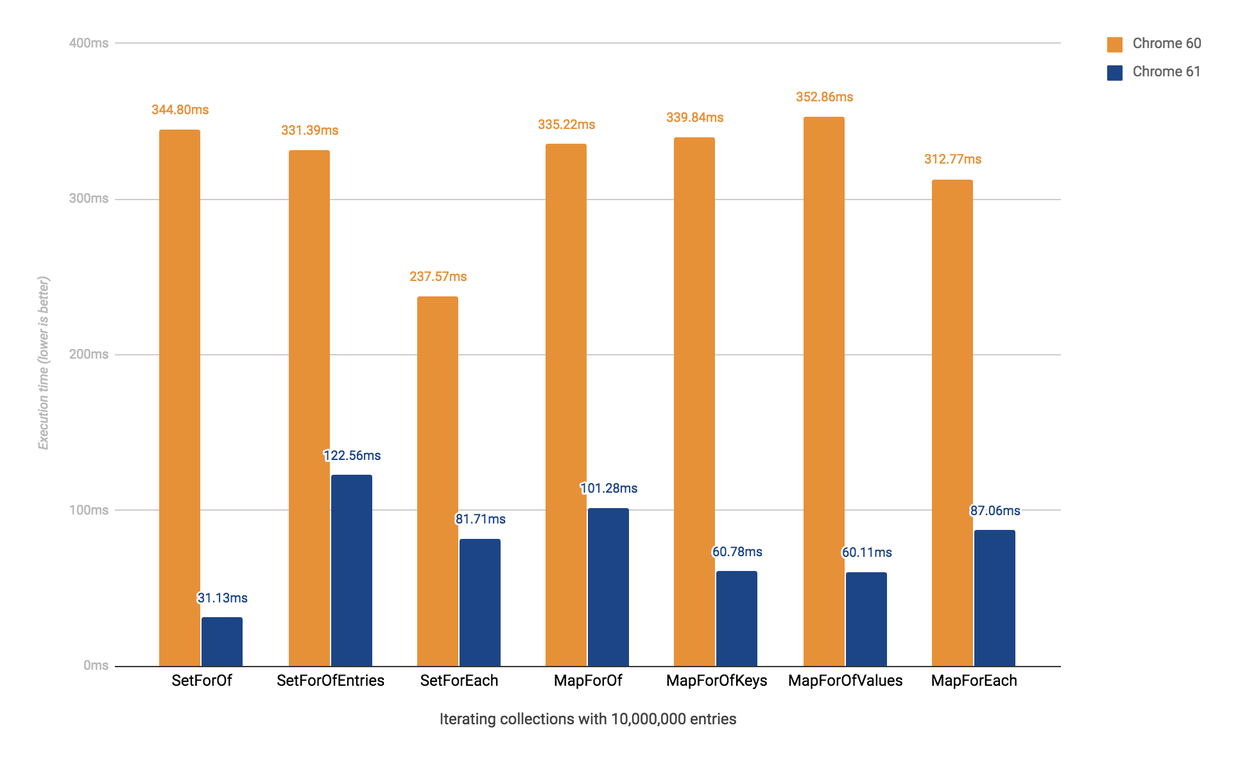
可见,虽然大幅提升,但是我们还是得到了一些不太理想的结果。尤其体现在 SetForOfEntries 和 MapForOf 上。但是这将会在更长远的计划上进行处理。
总结
这篇文章只是在大面上介绍了遍历器性能所面临的瓶颈和现有的解决方案。通过贺老的微博,对一个问题进行探究,最终找到 V8 核心成员 Benedikt Meurer 的 Faster Collection Iterators一文,进行参考并翻译。想要完全透彻理解原文章中内容,还需要扎实的计算机基础、v8
引擎工作方式以及编译原理方面的知识储备。
因我才疏学浅,入行也不到两年,更不算计算机科班出身,拾人牙慧的同时难免理解有偏差和疏漏。更多 V8 引擎方面的知识,建议大家更多关注@justjavac,编译方面的知识关注 Vue 作者@尤雨溪 以及他在 JS Conf 上的演讲内容: 前端工程中的编译时优化。毕竟,我们关注前端大 V、网红的根本并不是为了看热闹、看撕 b,而是希望在前辈身上学习到更多知识、得到更多启发。
最后,随着 ECMAScript 的飞速发展,让每一名前端开发者可能都会感觉到处在不断地学习当中,甚至有些疲于奔命。但是在学习新的特性和语法之外,理解更深层的内容才是学习进阶的关键。
我同样不知道什么是海,
赤脚站在沙滩上,
急切地等待着黎明的到来。
Happy Coding!
