

本文基于 Elastic-Job V2.1.5 版本分享
Elastic-Job-Cloud 源码分析系列(6篇)传送门
- 1. 概述
- 2. 作业执行类型
- 3. Producer 发布任务
- 4. TaskLaunchScheduledService 提交任务
- 5. TaskExecutor 执行任务
- 6. SchedulerEngine 处理任务的状态变更
- 666. 彩蛋
🙂🙂🙂关注微信公众号:【芋道源码】有福利:
- RocketMQ / MyCAT / Sharding-JDBC 所有源码分析文章列表
- RocketMQ / MyCAT / Sharding-JDBC 中文注释源码 GitHub 地址
- 您对于源码的疑问每条留言都将得到认真回复。甚至不知道如何读源码也可以请教噢。
- 新的源码解析文章实时收到通知。每周更新一篇左右。
- 认真的源码交流微信群。
1. 概述
本文主要分享 Elastic-Job-Cloud 调度主流程。对应到 Elastic-Job-Lite 源码解析文章如下:
如果你阅读过以下文章,有助于对本文的理解:
😈 另外,笔者假设你已经对 《Elastic-Job-Lite 源码分析系列》 有一定的了解。
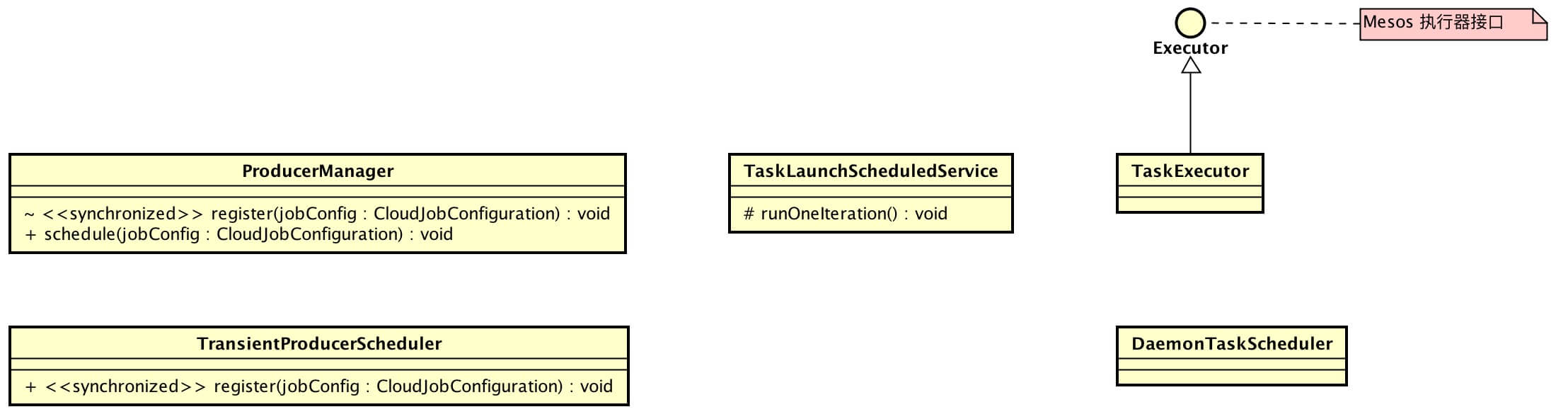
本文涉及到主体类的类图如下( 打开大图 ):
你行好事会因为得到赞赏而愉悦
同理,开源项目贡献者会因为 Star 而更加有动力
为 Elastic-Job 点赞!传送门
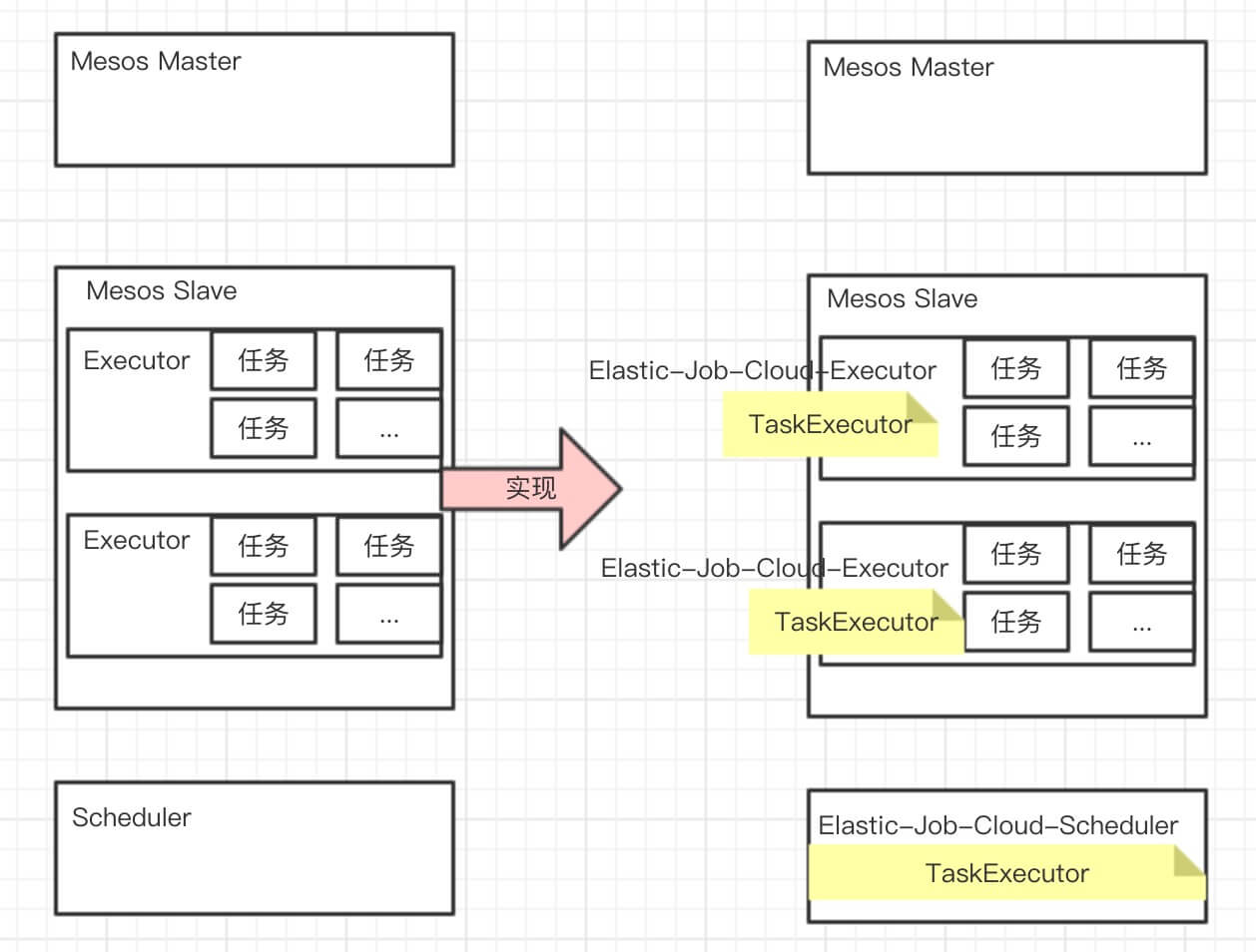
Elastic-Job-Cloud 基于 Mesos 实现分布式作业调度,或者说 Elastic-Job-Cloud 是 Mesos 上的 框架( Framework )。
一个 Mesos 框架由两部分组成:
- 控制器部分,称为调度器( Scheduler )。
- 工作单元部分,称为执行器( Executor )。
Elastic-Job-Cloud 由两个项目组成:
- Elastic-Job-Cloud-Scheduler,实现调度器,实现类为
com.dangdang.ddframe.job.cloud.scheduler.mesos.SchedulerEngine。 - Elastic-Job-Cloud-Executor,实现执行器,实现类为
com.dangdang.ddframe.job.cloud.executor.TaskExecutor。
本文略微“啰嗦”,请保持耐心。搭配《用Mesos框架构建分布式应用》一起阅读,理解难度降低 99%。OK,开始我们的 Cloud 之旅。
2. 作业执行类型
在 Elastic-Job-Cloud,作业执行分成两种类型:
- 常驻作业
常驻作业是作业一旦启动,无论运行与否均占用系统资源;
常驻作业适合初始化时间长、触发间隔短、实时性要求高的作业,要求资源配备充足。
- 瞬时作业
瞬时作业是在作业启动时占用资源,运行完成后释放资源。
瞬时作业适合初始化时间短、触发间隔长、允许延迟的作业,一般用于资源不太充分,或作业要求的资源多,适合资源错峰使用的场景。
Elastic-Job-Cloud 不同于 Elastic-Job-Lite 去中心化执行调度,转变为 Mesos Framework 的中心节点调度。这里不太理解,没关系,下文看到具体代码就能明白了。
常驻作业、瞬时作业在调度中会略有不同,大体粗略流程如下:
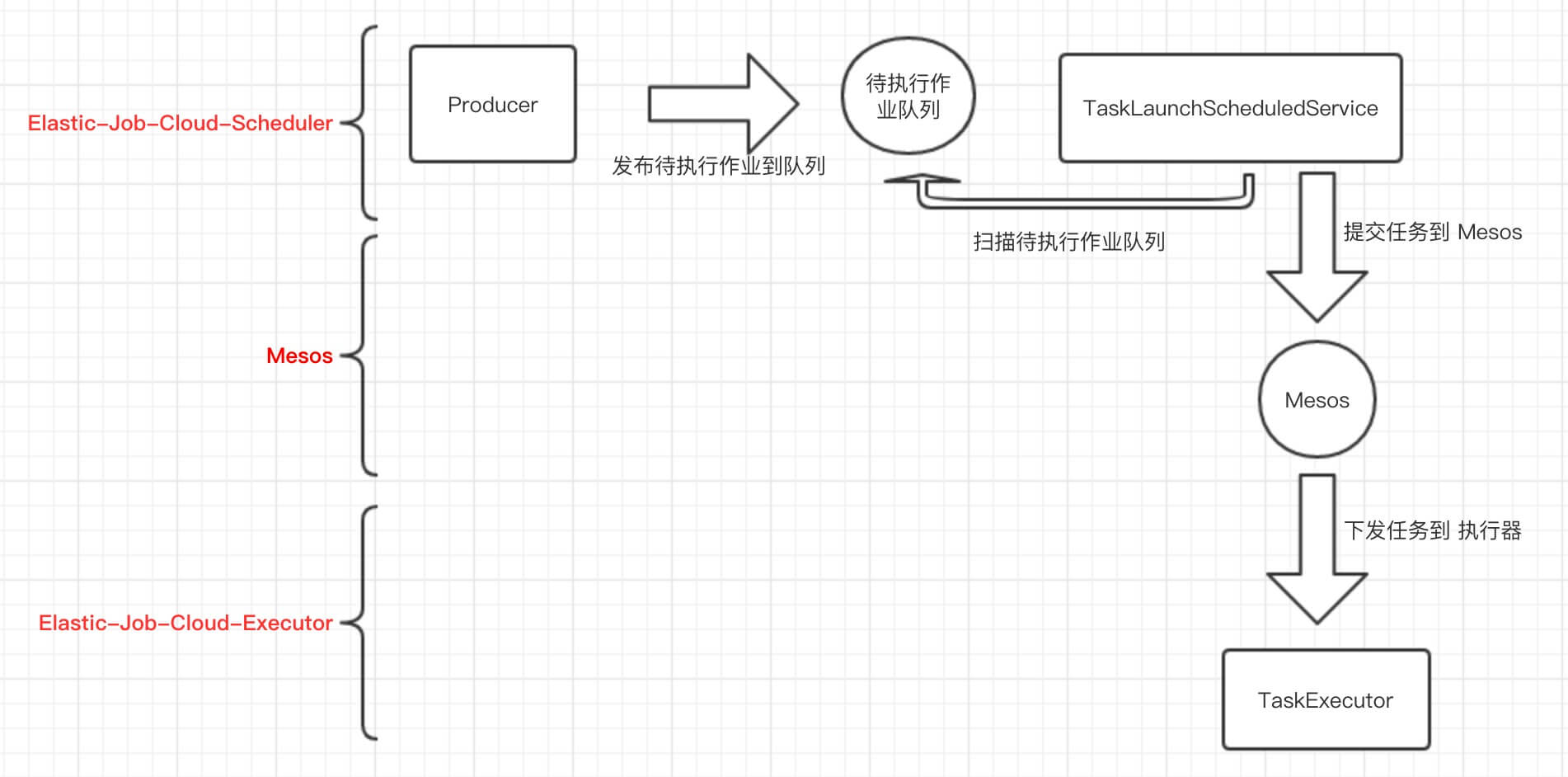
下面,我们针对每个过程一节一节解析。
3. Producer 发布任务
在上文《Elastic-Job-Cloud 源码分析 —— 作业配置》的「3.1.1 操作云作业配置」可以看到添加云作业配置后,Elastic-Job-Cloud-Scheduler 会执行作业调度,实现代码如下:
// ProducerManager.java
/**
* 调度作业.
*
* @param jobConfig 作业配置
*/
public void schedule(final CloudJobConfiguration jobConfig) {
// 应用 或 作业 被禁用,不调度
if (disableAppService.isDisabled(jobConfig.getAppName()) || disableJobService.isDisabled(jobConfig.getJobName())) {
return;
}
if (CloudJobExecutionType.TRANSIENT == jobConfig.getJobExecutionType()) { // 瞬时作业
transientProducerScheduler.register(jobConfig);
} else if (CloudJobExecutionType.DAEMON == jobConfig.getJobExecutionType()) { // 常驻作业
readyService.addDaemon(jobConfig.getJobName());
}
}- 瞬时作业和常驻作业在调度上会有一定的不同。
3.1 常驻作业
常驻作业在调度时,直接添加到待执行作业队列。What?岂不是马上就运行了!No No No,答案在「5. TaskExecutor 执行任务」,这里先打住。
// ReadyService.java
/**
* 将常驻作业放入待执行队列.
*
* @param jobName 作业名称
*/
public void addDaemon(final String jobName) {
if (regCenter.getNumChildren(ReadyNode.ROOT) > env.getFrameworkConfiguration().getJobStateQueueSize()) {
log.warn("Cannot add daemon job, caused by read state queue size is larger than {}.", env.getFrameworkConfiguration().getJobStateQueueSize());
return;
}
Optional<CloudJobConfiguration> cloudJobConfig = configService.load(jobName);
if (!cloudJobConfig.isPresent() || CloudJobExecutionType.DAEMON != cloudJobConfig.get().getJobExecutionType() || runningService.isJobRunning(jobName)) {
return;
}
// 添加到待执行队列
regCenter.persist(ReadyNode.getReadyJobNodePath(jobName), "1");
}
// ReadyNode.java
final class ReadyNode {
static final String ROOT = StateNode.ROOT + "/ready";
private static final String READY_JOB = ROOT + "/%s"; // %s = ${JOB_NAME}
}- ReadyService,待执行作业队列服务,提供对待执行作业队列的各种操作方法。
待执行作业队列存储在注册中心( Zookeeper )的持久数据节点
/${NAMESPACE}/state/ready/${JOB_NAME},存储值为待执行次数。例如此处,待执行次数为1。使用 zkClient 查看如下:[zk: localhost:2181(CONNECTED) 4] ls /elastic-job-cloud/state/ready [test_job_simple] [zk: localhost:2181(CONNECTED) 5] get /elastic-job-cloud/state/ready/test_job_simple 1在运维平台,我们可以看到待执行作业队列:

从官方的 RoadMap 来看,待执行作业队列未来会使用 Redis 存储以提高性能。
FROM elasticjob.io/docs/elasti…
Redis Based Queue Improvement
3.2 瞬时作业
瞬时作业在调度时,使用发布瞬时作业任务的调度器( TransientProducerScheduler )调度作业。当瞬时作业到达作业执行时间,添加到待执行作业队列。
3.2.1 TransientProducerScheduler
TransientProducerScheduler,发布瞬时作业任务的调度器,基于 Quartz 实现对瞬时作业的调度。初始化代码如下:
// TransientProducerScheduler.java
void start() {
scheduler = getScheduler();
try {
scheduler.start();
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
private Scheduler getScheduler() {
StdSchedulerFactory factory = new StdSchedulerFactory();
try {
factory.initialize(getQuartzProperties());
return factory.getScheduler();
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
private Properties getQuartzProperties() {
Properties result = new Properties();
result.put("org.quartz.threadPool.class", SimpleThreadPool.class.getName());
result.put("org.quartz.threadPool.threadCount", Integer.toString(Runtime.getRuntime().availableProcessors() * 2)); // 线程池数量
result.put("org.quartz.scheduler.instanceName", "ELASTIC_JOB_CLOUD_TRANSIENT_PRODUCER");
result.put("org.quartz.plugin.shutdownhook.class", ShutdownHookPlugin.class.getName());
result.put("org.quartz.plugin.shutdownhook.cleanShutdown", Boolean.TRUE.toString());
return result;
}3.2.2 注册瞬时作业
调用 TransientProducerScheduler#register(...) 方法,注册瞬时作业。实现代码如下:
// TransientProducerScheduler.java
private final TransientProducerRepository repository;
synchronized void register(final CloudJobConfiguration jobConfig) {
String cron = jobConfig.getTypeConfig().getCoreConfig().getCron();
// 添加 cron 作业集合
JobKey jobKey = buildJobKey(cron);
repository.put(jobKey, jobConfig.getJobName());
// 调度 作业
try {
if (!scheduler.checkExists(jobKey)) {
scheduler.scheduleJob(buildJobDetail(jobKey), buildTrigger(jobKey.getName()));
}
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}- 调用
#buildJobKey(...)方法,创建 Quartz JobKey。你会发现很有意思的使用的是cron参数作为主键。Why?在看下!scheduler.checkExists(jobKey)处,相同 JobKey(cron) 的作业不重复注册到 Quartz Scheduler。Why?此处是一个优化,相同cron使用同一个 Quartz Job,Elastic-Job-Cloud-Scheduler 可能会注册大量的瞬时作业,如果一个瞬时作业创建一个 Quartz Job 太过浪费,特别是cron每分钟、每5分钟、每小时、每天已经覆盖了大量的瞬时作业的情况。因此,相同cron使用同一个 Quartz Job。 调用
TransientProducerRepository#put(...)以 Quartz JobKey 为主键聚合作业。final class TransientProducerRepository { /** * cron 作业集合 * key:作业Key */ private final ConcurrentHashMap<JobKey, List<String>> cronTasks = new ConcurrentHashMap<>(256, 1); synchronized void put(final JobKey jobKey, final String jobName) { remove(jobName); List<String> taskList = cronTasks.get(jobKey); if (null == taskList) { taskList = new CopyOnWriteArrayList<>(); taskList.add(jobName); cronTasks.put(jobKey, taskList); return; } if (!taskList.contains(jobName)) { taskList.add(jobName); } } }调用
#buildJobDetail(...)创建 Quartz Job 信息。实现代码如下:private JobDetail buildJobDetail(final JobKey jobKey) { JobDetail result = JobBuilder.newJob(ProducerJob.class) // ProducerJob.java .withIdentity(jobKey).build(); result.getJobDataMap().put("repository", repository); result.getJobDataMap().put("readyService", readyService); return result; }JobBuilder#newJob(...)的参数是 ProducerJob,下文会讲解到。
调用
#buildTrigger(...)创建 Quartz Trigger。实现代码如下:private Trigger buildTrigger(final String cron) { return TriggerBuilder.newTrigger() .withIdentity(cron) .withSchedule(CronScheduleBuilder.cronSchedule(cron) // cron .withMisfireHandlingInstructionDoNothing()) .build(); }
3.2.3 ProducerJob
ProducerJob,当 Quartz Job 到达 cron 执行时间( 即作业执行时间),将相应的瞬时作业添加到待执行作业队列。实现代码如下:
public static final class ProducerJob implements Job {
private TransientProducerRepository repository;
private ReadyService readyService;
@Override
public void execute(final JobExecutionContext context) throws JobExecutionException {
List<String> jobNames = repository.get(context.getJobDetail().getKey());
for (String each : jobNames) {
readyService.addTransient(each);
}
}
}调用
TransientProducerRepository#get(...)方法,获得该 Job 对应的作业集合。实现代码如下:final class TransientProducerRepository { /** * cron 作业集合 * key:作业Key */ private final ConcurrentHashMap<JobKey, List<String>> cronTasks = new ConcurrentHashMap<>(256, 1); List<String> get(final JobKey jobKey) { List<String> result = cronTasks.get(jobKey); return null == result ? Collections.<String>emptyList() : result; } }调用
ReadyService#addTransient(...)方法,添加瞬时作业到待执行作业队列。实现代码如下:/** * 将瞬时作业放入待执行队列. * * @param jobName 作业名称 */ public void addTransient(final String jobName) { // if (regCenter.getNumChildren(ReadyNode.ROOT) > env.getFrameworkConfiguration().getJobStateQueueSize()) { log.warn("Cannot add transient job, caused by read state queue size is larger than {}.", env.getFrameworkConfiguration().getJobStateQueueSize()); return; } // Optional<CloudJobConfiguration> cloudJobConfig = configService.load(jobName); if (!cloudJobConfig.isPresent() || CloudJobExecutionType.TRANSIENT != cloudJobConfig.get().getJobExecutionType()) { return; } // String readyJobNode = ReadyNode.getReadyJobNodePath(jobName); String times = regCenter.getDirectly(readyJobNode); if (cloudJobConfig.get().getTypeConfig().getCoreConfig().isMisfire()) { regCenter.persist(readyJobNode, Integer.toString(null == times ? 1 : Integer.parseInt(times) + 1)); } else { regCenter.persist(ReadyNode.getReadyJobNodePath(jobName), "1"); } }- 添加瞬时作业到待执行作业队列 和 添加常驻作业到待执行作业队列基本是一致的。
- TODO :misfire
3.3 小结
无论是常驻作业还是瞬时作业,都会加入到待执行作业队列。目前我们看到瞬时作业的每次调度是 TransientProducerScheduler 负责。那么常驻作业的每次调度呢?「5. TaskExecutor 执行任务」会看到它的调度,这是 Elastic-Job-Cloud 设计巧妙有趣的地方。
4. TaskLaunchScheduledService 提交任务
TaskLaunchScheduledService,任务提交调度服务。它继承 Guava AbstractScheduledService 实现定时将待执行作业队列的作业提交到 Mesos 进行调度执行。实现定时代码如下:
public final class TaskLaunchScheduledService extends AbstractScheduledService {
@Override
protected String serviceName() {
return "task-launch-processor";
}
@Override
protected Scheduler scheduler() {
return Scheduler.newFixedDelaySchedule(2, 10, TimeUnit.SECONDS);
}
@Override
protected void runOneIteration() throws Exception {
// .... 省略代码
}
// ... 省略部分方法
}- 每 10 秒执行提交任务(
#runOneIteration())。对 Guava AbstractScheduledService 不了解的同学,可以阅读完本文后 Google 下。
#runOneIteration() 方法相对比较复杂,我们一块一块拆解,耐心理解。实现代码如下:
@Override
protected void runOneIteration() throws Exception {
try {
System.out.println("runOneIteration:" + new Date());
// 创建 Fenzo 任务请求
LaunchingTasks launchingTasks = new LaunchingTasks(facadeService.getEligibleJobContext());
List<TaskRequest> taskRequests = launchingTasks.getPendingTasks();
// 获取所有正在运行的云作业App https://github.com/Netflix/Fenzo/wiki/Constraints
if (!taskRequests.isEmpty()) {
AppConstraintEvaluator.getInstance().loadAppRunningState();
}
// 将任务请求分配到 Mesos Offer
Collection<VMAssignmentResult> vmAssignmentResults = taskScheduler.scheduleOnce(taskRequests, LeasesQueue.getInstance().drainTo()).getResultMap().values();
// 创建 Mesos 任务请求
List<TaskContext> taskContextsList = new LinkedList<>(); // 任务运行时上下文集合
Map<List<Protos.OfferID>, List<Protos.TaskInfo>> offerIdTaskInfoMap = new HashMap<>(); // Mesos 任务信息集合
for (VMAssignmentResult each: vmAssignmentResults) {
List<VirtualMachineLease> leasesUsed = each.getLeasesUsed();
List<Protos.TaskInfo> taskInfoList = new ArrayList<>(each.getTasksAssigned().size() * 10);
taskInfoList.addAll(getTaskInfoList(
launchingTasks.getIntegrityViolationJobs(vmAssignmentResults), // 获得作业分片不完整的作业集合
each, leasesUsed.get(0).hostname(), leasesUsed.get(0).getOffer()));
for (Protos.TaskInfo taskInfo : taskInfoList) {
taskContextsList.add(TaskContext.from(taskInfo.getTaskId().getValue()));
}
offerIdTaskInfoMap.put(getOfferIDs(leasesUsed), // 获得 Offer ID 集合
taskInfoList);
}
// 遍历任务运行时上下文
for (TaskContext each : taskContextsList) {
// 将任务运行时上下文放入运行时队列
facadeService.addRunning(each);
// 发布作业状态追踪事件(State.TASK_STAGING)
jobEventBus.post(createJobStatusTraceEvent(each));
}
// 从队列中删除已运行的作业
facadeService.removeLaunchTasksFromQueue(taskContextsList);
// 提交任务给 Mesos
for (Entry<List<OfferID>, List<TaskInfo>> each : offerIdTaskInfoMap.entrySet()) {
schedulerDriver.launchTasks(each.getKey(), each.getValue());
}
} catch (Throwable throwable) {
log.error("Launch task error", throwable);
} finally {
// 清理 AppConstraintEvaluator 所有正在运行的云作业App
AppConstraintEvaluator.getInstance().clearAppRunningState();
}
}4.1 创建 Fenzo 任务请求
// #runOneIteration()
LaunchingTasks launchingTasks = new LaunchingTasks(facadeService.getEligibleJobContext());
List<TaskRequest> taskRequests = launchingTasks.getPendingTasks();调用
FacadeService#getEligibleJobContext()方法,获取有资格运行的作业。// FacadeService.java /** * 获取有资格运行的作业. * * @return 作业上下文集合 */ public Collection<JobContext> getEligibleJobContext() { // 从失效转移队列中获取所有有资格执行的作业上下文 Collection<JobContext> failoverJobContexts = failoverService.getAllEligibleJobContexts(); // 从待执行队列中获取所有有资格执行的作业上下文 Collection<JobContext> readyJobContexts = readyService.getAllEligibleJobContexts(failoverJobContexts); // 合并 Collection<JobContext> result = new ArrayList<>(failoverJobContexts.size() + readyJobContexts.size()); result.addAll(failoverJobContexts); result.addAll(readyJobContexts); return result; }- 调用
FailoverService#getAllEligibleJobContexts()方法,从失效转移队列中获取所有有资格执行的作业上下文。TaskLaunchScheduledService 提交的任务还可能来自失效转移队列。本文暂时不解析失效转移队列相关实现,避免增加复杂度影响大家的理解,在《Elastic-Job-Cloud 源码分析 —— 作业失效转移》详细解析。 调用
ReadyService#getAllEligibleJobContexts(...)方法,从待执行队列中获取所有有资格执行的作业上下文。// ReadyService.java /** * 从待执行队列中获取所有有资格执行的作业上下文. * * @param ineligibleJobContexts 无资格执行的作业上下文 * @return 有资格执行的作业上下文集合 */ public Collection<JobContext> getAllEligibleJobContexts(final Collection<JobContext> ineligibleJobContexts) { // 不存在 待执行队列 if (!regCenter.isExisted(ReadyNode.ROOT)) { return Collections.emptyList(); } // 无资格执行的作业上下文 转换成 无资格执行的作业集合 Collection<String> ineligibleJobNames = Collections2.transform(ineligibleJobContexts, new Function<JobContext, String>() { @Override public String apply(final JobContext input) { return input.getJobConfig().getJobName(); } }); // 获取 待执行队列 有资格执行的作业上下文 List<String> jobNames = regCenter.getChildrenKeys(ReadyNode.ROOT); List<JobContext> result = new ArrayList<>(jobNames.size()); for (String each : jobNames) { if (ineligibleJobNames.contains(each)) { continue; } // 排除 作业配置 不存在的作业 Optional<CloudJobConfiguration> jobConfig = configService.load(each); if (!jobConfig.isPresent()) { regCenter.remove(ReadyNode.getReadyJobNodePath(each)); continue; } if (!runningService.isJobRunning(each)) { // 排除 运行中 的作业 result.add(JobContext.from(jobConfig.get(), ExecutionType.READY)); } } return result; }JobContext,作业运行上下文。实现代码如下:
// JobContext.java public final class JobContext { private final CloudJobConfiguration jobConfig; private final List<Integer> assignedShardingItems; private final ExecutionType type; /** * 通过作业配置创建作业运行上下文. * * @param jobConfig 作业配置 * @param type 执行类型 * @return 作业运行上下文 */ public static JobContext from(final CloudJobConfiguration jobConfig, final ExecutionType type) { int shardingTotalCount = jobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount(); // 分片项 List<Integer> shardingItems = new ArrayList<>(shardingTotalCount); for (int i = 0; i < shardingTotalCount; i++) { shardingItems.add(i); } return new JobContext(jobConfig, shardingItems, type); } }
- 调用
LaunchingTasks,分配任务行为包。创建 LaunchingTasks 代码如下:
public final class LaunchingTasks { /** * 作业上下文集合 * key:作业名 */ private final Map<String, JobContext> eligibleJobContextsMap; public LaunchingTasks(final Collection<JobContext> eligibleJobContexts) { eligibleJobContextsMap = new HashMap<>(eligibleJobContexts.size(), 1); for (JobContext each : eligibleJobContexts) { eligibleJobContextsMap.put(each.getJobConfig().getJobName(), each); } } }调用
LaunchingTasks#getPendingTasks()方法,获得待执行任务集合。这里要注意,每个作业如果有多个分片,则会生成多个待执行任务,即此处完成了作业分片。实现代码如下:// LaunchingTasks.java /** * 获得待执行任务 * * @return 待执行任务 */ List<TaskRequest> getPendingTasks() { List<TaskRequest> result = new ArrayList<>(eligibleJobContextsMap.size() * 10); for (JobContext each : eligibleJobContextsMap.values()) { result.addAll(createTaskRequests(each)); } return result; } /** * 创建待执行任务集合 * * @param jobContext 作业运行上下文 * @return 待执行任务集合 */ private Collection<TaskRequest> createTaskRequests(final JobContext jobContext) { Collection<TaskRequest> result = new ArrayList<>(jobContext.getAssignedShardingItems().size()); for (int each : jobContext.getAssignedShardingItems()) { result.add(new JobTaskRequest(new TaskContext(jobContext.getJobConfig().getJobName(), Collections.singletonList(each), jobContext.getType()), jobContext.getJobConfig())); } return result; } // TaskContext.java public final class TaskContext { /** * 任务编号 */ private String id; /** * 任务元信息 */ private final MetaInfo metaInfo; /** * 执行类型 */ private final ExecutionType type; /** * Mesos Slave 编号 */ private String slaveId; /** * 是否闲置 */ @Setter private boolean idle; public static class MetaInfo { /** * 作业名 */ private final String jobName; /** * 作业分片项 */ private final List<Integer> shardingItems; } // ... 省略部分方法 } // JobTaskRequest.JAVA public final class JobTaskRequest implements TaskRequest { private final TaskContext taskContext; private final CloudJobConfiguration jobConfig; @Override public String getId() { return taskContext.getId(); } @Override public double getCPUs() { return jobConfig.getCpuCount(); } @Override public double getMemory() { return jobConfig.getMemoryMB(); } // ... 省略部分方法 }- 调用
#createTaskRequests(...)方法,将单个作业按照其作业分片总数拆分成一个或多个待执行任务集合。 - TaskContext,任务运行时上下文。
- JobTaskRequest,作业任务请求对象。
- 调用
- 因为对象有点多,我们来贴一个
LaunchingTasks#getPendingTasks()方法的返回结果。
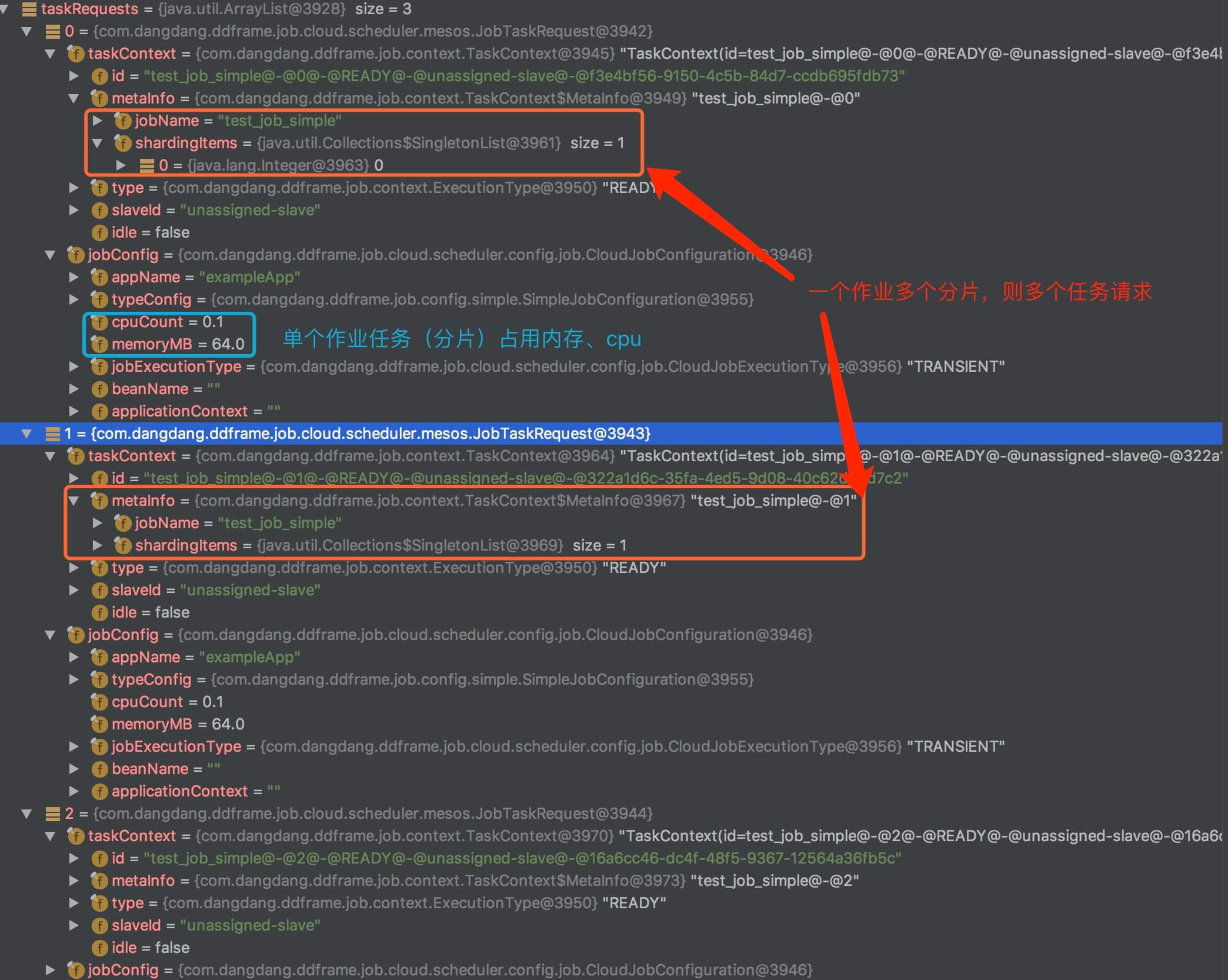
友情提示,代码可能比较多,请耐心观看。
4.2 AppConstraintEvaluator
在说 AppConstraintEvaluator 之前,我们先一起了简单解下 Netflix Fenzo。
FROM dockone.io/article/636
Fenzo是一个在Mesos框架上应用的通用任务调度器。它可以让你通过实现各种优化策略的插件,来优化任务调度,同时这也有利于集群的自动缩放。
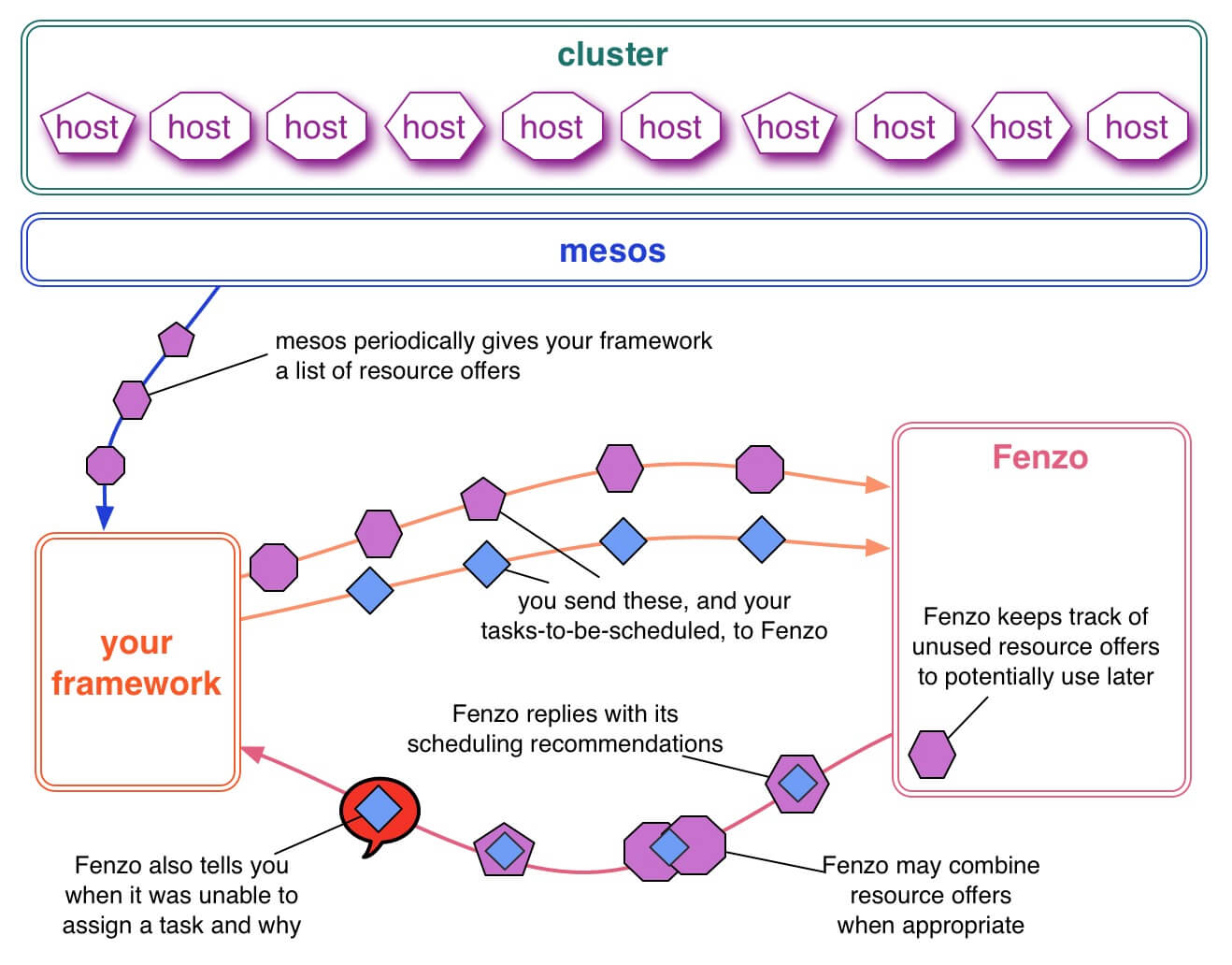
Elastic-Job-Cloud-Scheduler 基于 Fenzo 实现对 Mesos 的弹性资源分配。
例如,AppConstraintEvaluator,App 目标 Mesos Slave 适配度限制器,选择 Slave 时需要考虑其上是否运行有 App 的 Executor,如果没有运行 Executor 需要将其资源消耗考虑进适配计算算法中。它是 Fenzo ConstraintEvaluator 接口 在 Elastic-Job-Cloud-Scheduler 的自定义任务约束实现。通过这个任务约束,在下文调用 TaskScheduler#scheduleOnce(...) 方法调度任务所需资源时,会将 AppConstraintEvaluator 考虑进去。
那么作业任务请求( JobTaskRequest ) 是怎么关联上 AppConstraintEvaluator 的呢?
// JobTaskRequest.java
public final class JobTaskRequest implements TaskRequest {
@Override
public List<? extends ConstraintEvaluator> getHardConstraints() {
return Collections.singletonList(AppConstraintEvaluator.getInstance());
}
}- Fenzo TaskRequest 接口 是 Fenzo 的任务请求接口,通过实现
#getHardConstraints()方法,关联上 TaskRequest 和 ConstraintEvaluator。
关联上之后,任务匹配 Mesos Slave 资源时,调用 ConstraintEvaluator#evaluate(...) 实现方法判断是否符合约束:
public interface ConstraintEvaluator {
public static class Result {
private final boolean isSuccessful;
private final String failureReason;
}
/**
* Inspects a target to decide whether or not it meets the constraints appropriate to a particular task.
*
* @param taskRequest a description of the task to be assigned
* @param targetVM a description of the host that is a potential match for the task
* @param taskTrackerState the current status of tasks and task assignments in the system at large
* @return a successful Result if the target meets the constraints enforced by this constraint evaluator, or
* an unsuccessful Result otherwise
*/
public Result evaluate(TaskRequest taskRequest, VirtualMachineCurrentState targetVM,
TaskTrackerState taskTrackerState);
}OK,简单了解结束,有兴趣了解更多的同学,请点击《Fenzo Wiki —— Constraints》。下面来看看 Elastic-Job-Cloud-Scheduler 自定义实现的任务约束 AppConstraintEvaluator。
调用 AppConstraintEvaluator#loadAppRunningState() 方法,加载当前运行中的云作业App,为 AppConstraintEvaluator#evaluate(...) 方法提供该数据。代码实现如下:
// AppConstraintEvaluator.java
private final Set<String> runningApps = new HashSet<>();
void loadAppRunningState() {
try {
for (MesosStateService.ExecutorStateInfo each : facadeService.loadExecutorInfo()) {
runningApps.add(each.getId());
}
} catch (final JSONException | UniformInterfaceException | ClientHandlerException e) {
clearAppRunningState();
}
}调用
FacadeService#loadExecutorInfo()方法,从 Mesos 获取所有正在运行的 Mesos 执行器( Executor )的信息。执行器和云作业App有啥关系?每个云作业App 即是一个 Elastic-Job-Cloud-Executor 实例。。FacadeService#loadExecutorInfo()方法这里就不展开了,有兴趣的同学自己看下,主要是对 Mesos 的 API操作,我们来看下runningApps的结果:
调用 TaskScheduler#scheduleOnce(...) 方法调度提交任务所需资源时,会调用 ConstraintEvaluator#loadAppRunningState() 检查分配的资源是否符合任务的约束条件。AppConstraintEvaluator#loadAppRunningState() 实现代码如下:
// AppConstraintEvaluator.java
@Override
public Result evaluate(final TaskRequest taskRequest, final VirtualMachineCurrentState targetVM, final TaskTrackerState taskTrackerState) {
double assigningCpus = 0.0d;
double assigningMemoryMB = 0.0d;
final String slaveId = targetVM.getAllCurrentOffers().iterator().next().getSlaveId().getValue();
try {
// 判断当前分配的 Mesos Slave 是否运行着该作业任务请求对应的云作业App
if (isAppRunningOnSlave(taskRequest.getId(), slaveId)) {
return new Result(true, "");
}
// 判断当前分配的 Mesos Slave 启动云作业App 是否超过资源限制
Set<String> calculatedApps = new HashSet<>(); // 已计算作业App集合
List<TaskRequest> taskRequests = new ArrayList<>(targetVM.getTasksCurrentlyAssigned().size() + 1);
taskRequests.add(taskRequest);
for (TaskAssignmentResult each : targetVM.getTasksCurrentlyAssigned()) { // 当前已经分配作业请求
taskRequests.add(each.getRequest());
}
for (TaskRequest each : taskRequests) {
assigningCpus += each.getCPUs();
assigningMemoryMB += each.getMemory();
if (isAppRunningOnSlave(each.getId(), slaveId)) { // 作业App已经启动
continue;
}
CloudAppConfiguration assigningAppConfig = getAppConfiguration(each.getId());
if (!calculatedApps.add(assigningAppConfig.getAppName())) { // 是否已经计算该App
continue;
}
assigningCpus += assigningAppConfig.getCpuCount();
assigningMemoryMB += assigningAppConfig.getMemoryMB();
}
} catch (final LackConfigException ex) {
log.warn("Lack config, disable {}", getName(), ex);
return new Result(true, "");
}
if (assigningCpus > targetVM.getCurrAvailableResources().cpuCores()) { // cpu
log.debug("Failure {} {} cpus:{}/{}", taskRequest.getId(), slaveId, assigningCpus, targetVM.getCurrAvailableResources().cpuCores());
return new Result(false, String.format("cpu:%s/%s", assigningCpus, targetVM.getCurrAvailableResources().cpuCores()));
}
if (assigningMemoryMB > targetVM.getCurrAvailableResources().memoryMB()) { // memory
log.debug("Failure {} {} mem:{}/{}", taskRequest.getId(), slaveId, assigningMemoryMB, targetVM.getCurrAvailableResources().memoryMB());
return new Result(false, String.format("mem:%s/%s", assigningMemoryMB, targetVM.getCurrAvailableResources().memoryMB()));
}
log.debug("Success {} {} cpus:{}/{} mem:{}/{}", taskRequest.getId(), slaveId, assigningCpus, targetVM.getCurrAvailableResources()
.cpuCores(), assigningMemoryMB, targetVM.getCurrAvailableResources().memoryMB());
return new Result(true, String.format("cpus:%s/%s mem:%s/%s", assigningCpus, targetVM.getCurrAvailableResources()
.cpuCores(), assigningMemoryMB, targetVM.getCurrAvailableResources().memoryMB()));
}- 调用
#isAppRunningOnSlave()方法,判断当前分配的 Mesos Slave 是否运行着该作业任务请求对应的云作业App。若云作业App未运行,则该作业任务请求提交给 Mesos 后,该 Mesos Slave 会启动该云作业 App,App 本身会占用一定的CloudAppConfiguration#cpu和CloudAppConfiguration#memory,计算时需要统计,避免超过当前 Mesos Slave 剩余cpu和memory。 - 当计算符合约束时,返回
Result(true, ...);否则,返回Result(false, ...)。 - TODO 异常为啥返回true。
4.3 将任务请求分配到 Mesos Offer
我们先简单了解下 Elastic-Job-Cloud-Scheduler 实现的 Mesos Scheduler 类 com.dangdang.ddframe.job.cloud.scheduler.mesos.SchedulerEngine。调度器的主要职责之一:在接受到的 Offer 上启动任务。SchedulerEngine 接收到资源 Offer,先存储到资源预占队列( LeasesQueue ),等到作业被调度需要启动任务时进行使用。存储到资源预占队列实现代码如下:
public final class SchedulerEngine implements Scheduler {
@Override
public void resourceOffers(final SchedulerDriver schedulerDriver, final List<Protos.Offer> offers) {
for (Protos.Offer offer: offers) {
log.trace("Adding offer {} from host {}", offer.getId(), offer.getHostname());
LeasesQueue.getInstance().offer(offer);
}
}
}org.apache.mesos.Scheduler,Mesos 调度器接口,实现该接口成为自定义 Mesos 调度器。实现
#resourceOffers(...)方法,有新的资源 Offer 时,会进行调用。在 SchedulerEngine 会调用#offer(...)方法,存储 Offer 到资源预占队列,实现代码如下:public final class LeasesQueue { /** * 单例 */ private static final LeasesQueue INSTANCE = new LeasesQueue(); private final BlockingQueue<VirtualMachineLease> queue = new LinkedBlockingQueue<>(); /** * 获取实例. * * @return 单例对象 */ public static LeasesQueue getInstance() { return INSTANCE; } /** * 添加资源至队列预占. * * @param offer 资源 */ public void offer(final Protos.Offer offer) { queue.offer(new VMLeaseObject(offer)); } // ... 省略 #drainTo() 方法,下文解析。 }- VMLeaseObject,Netflix Fenzo 对 Mesos Offer 的抽象包装,点击链接查看实现代码,马上会看到它的用途。
另外,可能有同学对 Mesos Offer 理解比较生涩,Offer 定义如下:
FROM segmentfault.com/a/119000000…
Offer是Mesos资源的抽象,比如说有多少CPU、多少memory,disc是多少,都放在Offer里,打包给一个Framework,然后Framework来决定到底怎么用这个Offer。
OK,知识铺垫完成,回到本小节的重心:
// #runOneIteration()
Collection<VMAssignmentResult> vmAssignmentResults = taskScheduler.scheduleOnce(taskRequests, LeasesQueue.getInstance().drainTo()).getResultMap().values();
// LeasesQueue.java
public final class LeasesQueue {
private final BlockingQueue<VirtualMachineLease> queue = new LinkedBlockingQueue<>();
public List<VirtualMachineLease> drainTo() {
List<VirtualMachineLease> result = new ArrayList<>(queue.size());
queue.drainTo(result);
return result;
}
}调用 TaskScheduler#scheduleOnce(...) 方法,将任务请求分配到 Mesos Offer。通过 Fenzo TaskScheduler 实现对多个任务分配到多个 Mesos Offer 的合理优化分配。这是一个相对复杂的问题。为什么这么说呢?
FROM 《Mesos 框架构建分布式应用》 P76
将任务匹配到 offer 上,首次适配通常是最好的算法。你可能会想,如果在更多的工作里尝试计算出匹配该 offer 的优化组合,可能比首次适配更能高效地利用 offer。这绝对是正确的,但是要考虑如下这些方面:对于启动所有等待运行的任务来说,集群里要么有充足的资源要么没有。如果资源很多,那么首次适配肯定一直都能保证每个任务的启动。如果资源不够,怎么都无法启动所有任务。因此,编写代码选择接下来会运行哪个任务是很自然的,这样才能保证服务的质量。只有当资源刚够用时,才需要更为精细的打包算法。不幸的是,这里的问题 —— 通常称为背包问题( Knapsack problem ) —— 是一个众所周知的 NP 完全问题。NP 完全问题指的是需要相当长时间才能找到最优解决方案的问题,并且没有任何已知道技巧能够快速解决这类问题。
举个简单的例子,只考虑 memory 资源情况下,有一台 Slave 内存为 8GB ,现在要运行三个 1GB 的作业和 5GB 的作业。其中 5GB 的作业在 1GB 运行多次之后才执行。
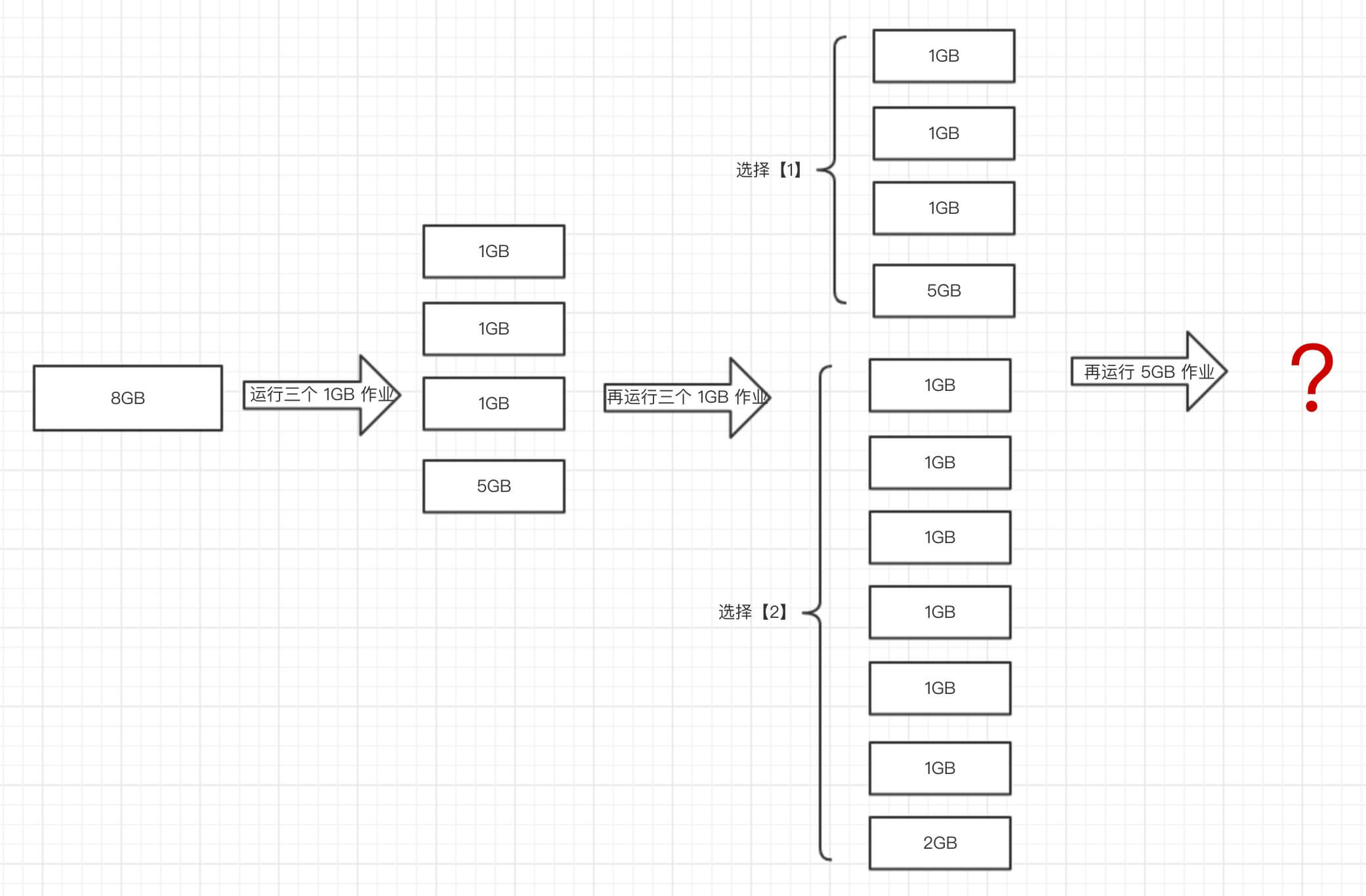
实际情况会比图更加复杂的多的多。通过使用 Fenzo ,可以很方便的,并且令人满意的分配。为了让你对 Fenzo 有更加透彻的理解,这里再引用一段对其的介绍:
FROM 《Mesos 框架构建分布式应用》 P80
调用库函数 Fenzo
Fenzo 是 Nettflix 在 2015 年夏天发布的库函数。Fenzo 为基于 java 的调度器提供了完整的解决方案,完成 offer 缓冲,多任务启动,以及软和硬约束条件的匹配。就算不是所有的,也是很多调度器都能够受益于使用 Fenzo 来完成计算任务分配,而不用自己编写 offer 缓冲、打包和放置路由等。
下面,来看两次 TaskScheduler#scheduleOnce(...) 的返回:
- 第一次调度:
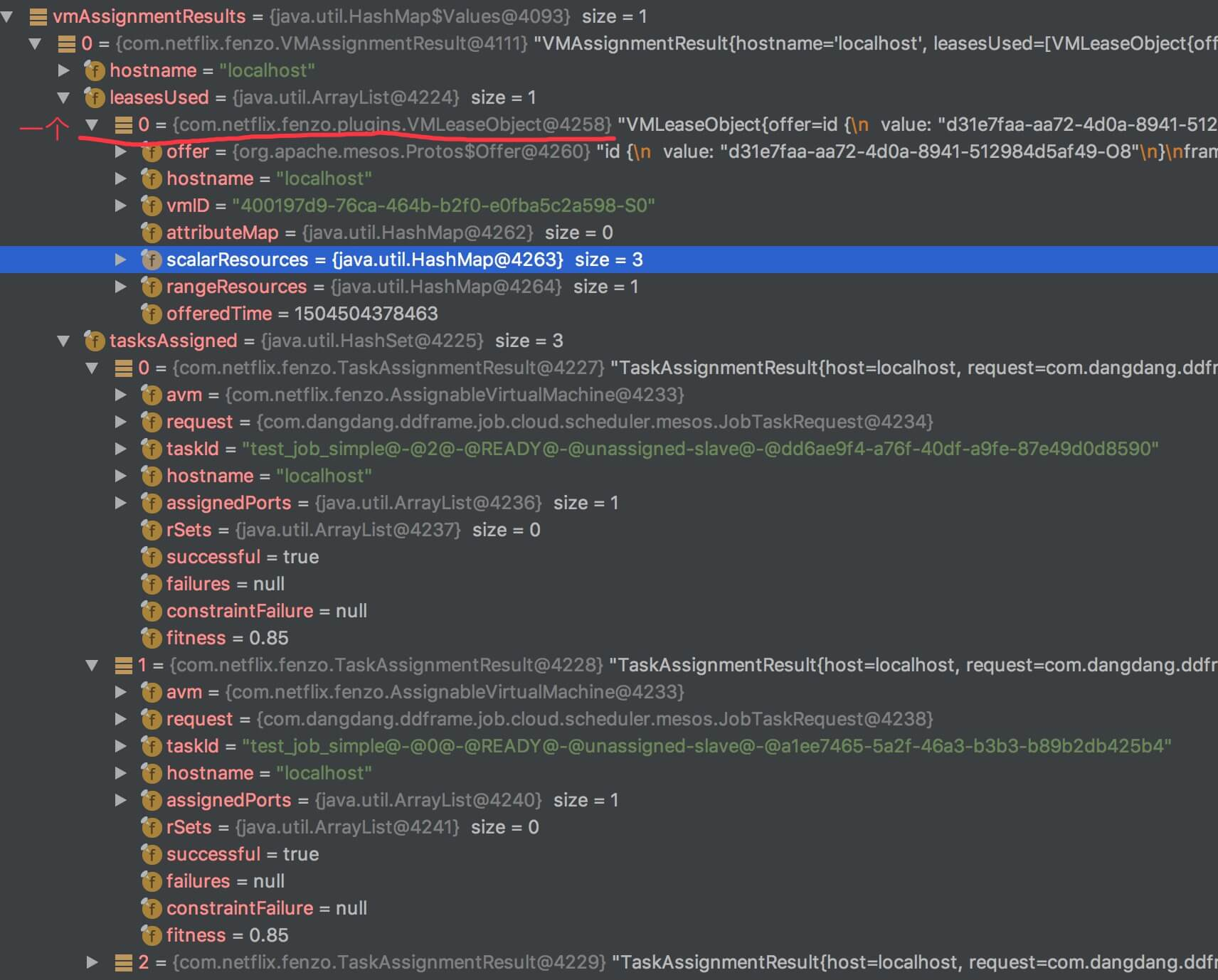
- 第二次调度:
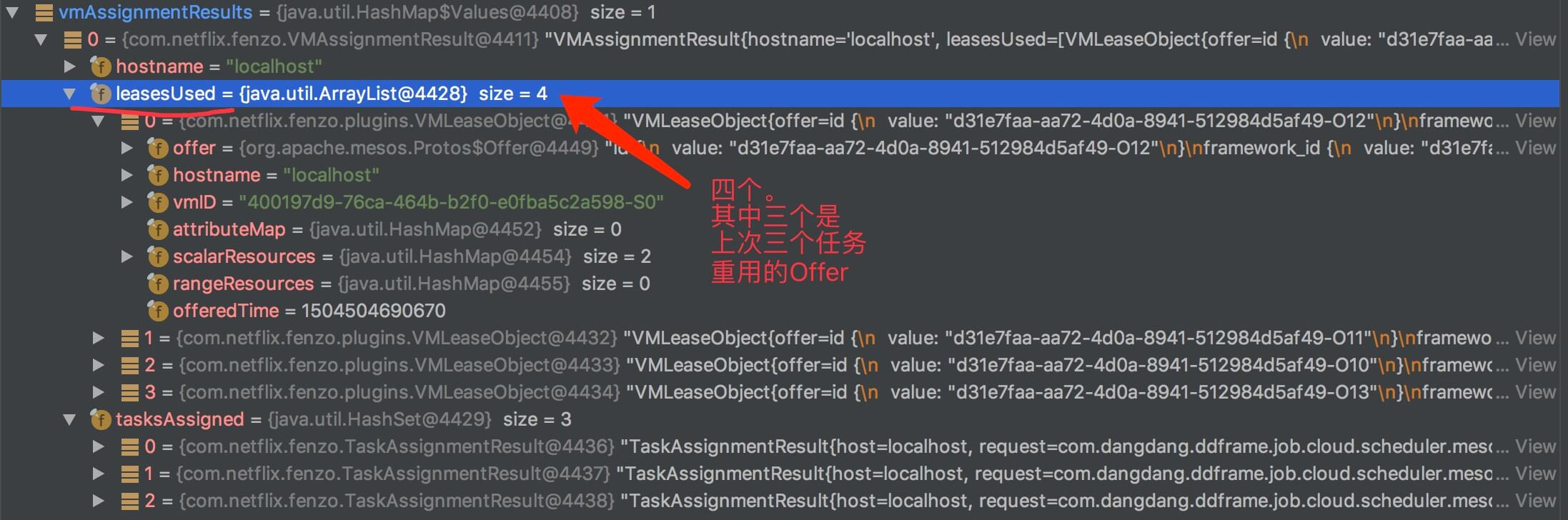
com.netflix.fenzo.VMAssignmentResult,每台主机分配任务结果。实现代码如下:public class VMAssignmentResult { /** * 主机 */ private final String hostname; /** * 使用的 Mesos Offer */ private final List<VirtualMachineLease> leasesUsed; /** * 分配的任务 */ private final Set<TaskAssignmentResult> tasksAssigned; }
受限于笔者的能力,建议你可以在阅读如下文章,更透彻的理解 TaskScheduler :
- 《Fenzo Wiki —— Constraints》
- 《Fenzo Wiki —— Building Your Scheduler》
- 《Fenzo Wiki —— Scheduling Tasks》
- 《Fenzo Wiki —— How to Learn Which Tasks Are Assigned to Which Hosts》
4.4 创建 Mesos 任务信息
// #runOneIteration()
List<TaskContext> taskContextsList = new LinkedList<>(); // 任务运行时上下文集合
Map<List<Protos.OfferID>, List<Protos.TaskInfo>> offerIdTaskInfoMap = new HashMap<>(); // Mesos 任务信息集合
for (VMAssignmentResult each: vmAssignmentResults) {
List<VirtualMachineLease> leasesUsed = each.getLeasesUsed();
List<Protos.TaskInfo> taskInfoList = new ArrayList<>(each.getTasksAssigned().size() * 10);
taskInfoList.addAll(getTaskInfoList(
launchingTasks.getIntegrityViolationJobs(vmAssignmentResults), // 获得作业分片不完整的作业集合
each, leasesUsed.get(0).hostname(), leasesUsed.get(0).getOffer()));
for (Protos.TaskInfo taskInfo : taskInfoList) {
taskContextsList.add(TaskContext.from(taskInfo.getTaskId().getValue()));
}
offerIdTaskInfoMap.put(getOfferIDs(leasesUsed), // 获得 Offer ID 集合
taskInfoList);
}offerIdTaskInfoMap,Mesos 任务信息集合。key 和 value 都为相同 Mesos Slave Offer 和 任务。为什么?调用SchedulerDriver#launchTasks(...)方法提交一次任务时,必须保证所有任务和 Offer 在相同 Mesos Slave 上。FROM FROM 《Mesos 框架构建分布式应用》 P61
组合 offer
latchTasks 接受 offer 列表为输入,这就允许用户将一些相同 slave 的 offer 组合起来,从而将这些 offer 的资源放到池里。它还能接受任务列表为输入,这样就能够启动适合给定 offer 的足够多的任务。注意所有任务和 offer 都必须是同一台 slave —— 如果不在同一台 slave 上,launchTasks 就会失败。如果想在多台 slave 上启动任务,多次调用 latchTasks 即可。调用
LaunchingTasks#getIntegrityViolationJobs(...)方法,获得作业分片不完整的作业集合。一个作业有多个分片,因为 Mesos Offer 不足,导致有部分分片不能执行,则整个作业都不进行执行。代码实现如下:// LaunchingTasks.java /** * 获得作业分片不完整的作业集合 * * @param vmAssignmentResults 主机分配任务结果集合 * @return 作业分片不完整的作业集合 */ Collection<String> getIntegrityViolationJobs(final Collection<VMAssignmentResult> vmAssignmentResults) { Map<String, Integer> assignedJobShardingTotalCountMap = getAssignedJobShardingTotalCountMap(vmAssignmentResults); Collection<String> result = new HashSet<>(assignedJobShardingTotalCountMap.size(), 1); for (Map.Entry<String, Integer> entry : assignedJobShardingTotalCountMap.entrySet()) { JobContext jobContext = eligibleJobContextsMap.get(entry.getKey()); if (ExecutionType.FAILOVER != jobContext.getType() // 不包括 FAILOVER 执行类型的作业 && !entry.getValue().equals(jobContext.getJobConfig().getTypeConfig().getCoreConfig().getShardingTotalCount())) { log.warn("Job {} is not assigned at this time, because resources not enough to run all sharding instances.", entry.getKey()); result.add(entry.getKey()); } } return result; } /** * 获得每个作业分片数集合 * key:作业名 * value:分片总数 * * @param vmAssignmentResults 主机分配任务结果集合 * @return 每个作业分片数集合 */ private Map<String, Integer> getAssignedJobShardingTotalCountMap(final Collection<VMAssignmentResult> vmAssignmentResults) { Map<String, Integer> result = new HashMap<>(eligibleJobContextsMap.size(), 1); for (VMAssignmentResult vmAssignmentResult: vmAssignmentResults) { for (TaskAssignmentResult tasksAssigned: vmAssignmentResult.getTasksAssigned()) { String jobName = TaskContext.from(tasksAssigned.getTaskId()).getMetaInfo().getJobName(); if (result.containsKey(jobName)) { result.put(jobName, result.get(jobName) + 1); } else { result.put(jobName, 1); } } } return result; }调用
#getTaskInfoList(...)方法,创建单个主机的 Mesos 任务信息集合。实现代码如下:private List<Protos.TaskInfo> getTaskInfoList(final Collection<String> integrityViolationJobs, final VMAssignmentResult vmAssignmentResult, final String hostname, final Protos.Offer offer) { List<Protos.TaskInfo> result = new ArrayList<>(vmAssignmentResult.getTasksAssigned().size()); for (TaskAssignmentResult each: vmAssignmentResult.getTasksAssigned()) { TaskContext taskContext = TaskContext.from(each.getTaskId()); String jobName = taskContext.getMetaInfo().getJobName(); if (!integrityViolationJobs.contains(jobName) // 排除作业分片不完整的任务 && !facadeService.isRunning(taskContext) // 排除正在运行中的任务 && !facadeService.isJobDisabled(jobName)) { // 排除被禁用的任务 // 创建 Mesos 任务 Protos.TaskInfo taskInfo = getTaskInfo(offer, each); if (null != taskInfo) { result.add(taskInfo); // 添加任务主键和主机名称的映射 facadeService.addMapping(taskInfo.getTaskId().getValue(), hostname); // 通知 TaskScheduler 主机分配了这个任务 taskScheduler.getTaskAssigner().call(each.getRequest(), hostname); } } } return result; }- 调用
#getTaskInfo(...)方法,创建单个 Mesos 任务,在「4.4.1 创建单个 Mesos 任务信息」详细解析。 调用
FacadeService#addMapping(...)方法,添加任务主键和主机名称的映射。通过该映射,可以根据任务主键查询到对应的主机名。实现代码如下:// FacadeService.java /** * 添加任务主键和主机名称的映射. * * @param taskId 任务主键 * @param hostname 主机名称 */ public void addMapping(final String taskId, final String hostname) { runningService.addMapping(taskId, hostname); } // RunningService.java /** * 任务主键和主机名称的映射 * key: 任务主键 * value: 主机名称 */ private static final ConcurrentHashMap<String, String> TASK_HOSTNAME_MAPPER = new ConcurrentHashMap<>(TASK_INITIAL_SIZE); public void addMapping(final String taskId, final String hostname) { TASK_HOSTNAME_MAPPER.putIfAbsent(taskId, hostname); }调用
TaskScheduler#getTaskAssigner()#call(...)方法,通知 TaskScheduler 任务被确认分配到这个主机。TaskScheduler 做任务和 Offer 的匹配,对哪些任务运行在哪些主机是有依赖的,不然怎么做匹配优化呢。在《Fenzo Wiki —— Notify the Scheduler of Assigns and UnAssigns of Tasks》可以进一步了解。
- 调用
调用
#getOfferIDs(...)方法,获得 Offer ID 集合。实现代码如下:private List<Protos.OfferID> getOfferIDs(final List<VirtualMachineLease> leasesUsed) { List<Protos.OfferID> result = new ArrayList<>(); for (VirtualMachineLease virtualMachineLease: leasesUsed) { result.add(virtualMachineLease.getOffer().getId()); } return result; }
4.4.1 创建单个 Mesos 任务信息
调用 #getTaskInfo() 方法,创建单个 Mesos 任务信息。实现代码如下:
如下会涉及大量的 Mesos API
private Protos.TaskInfo getTaskInfo(final Protos.Offer offer, final TaskAssignmentResult taskAssignmentResult) {
// 校验 作业配置 是否存在
TaskContext taskContext = TaskContext.from(taskAssignmentResult.getTaskId());
Optional<CloudJobConfiguration> jobConfigOptional = facadeService.load(taskContext.getMetaInfo().getJobName());
if (!jobConfigOptional.isPresent()) {
return null;
}
CloudJobConfiguration jobConfig = jobConfigOptional.get();
// 校验 作业配置 是否存在
Optional<CloudAppConfiguration> appConfigOptional = facadeService.loadAppConfig(jobConfig.getAppName());
if (!appConfigOptional.isPresent()) {
return null;
}
CloudAppConfiguration appConfig = appConfigOptional.get();
// 设置 Mesos Slave ID
taskContext.setSlaveId(offer.getSlaveId().getValue());
// 获得 分片上下文集合
ShardingContexts shardingContexts = getShardingContexts(taskContext, appConfig, jobConfig);
// 瞬时的脚本作业,使用 Mesos 命令行执行,无需使用执行器
boolean isCommandExecutor = CloudJobExecutionType.TRANSIENT == jobConfig.getJobExecutionType() && JobType.SCRIPT == jobConfig.getTypeConfig().getJobType();
String script = appConfig.getBootstrapScript();
if (isCommandExecutor) {
script = ((ScriptJobConfiguration) jobConfig.getTypeConfig()).getScriptCommandLine();
}
// 创建 启动命令
Protos.CommandInfo.URI uri = buildURI(appConfig, isCommandExecutor);
Protos.CommandInfo command = buildCommand(uri, script, shardingContexts, isCommandExecutor);
// 创建 Mesos 任务信息
if (isCommandExecutor) {
return buildCommandExecutorTaskInfo(taskContext, jobConfig, shardingContexts, offer, command);
} else {
return buildCustomizedExecutorTaskInfo(taskContext, appConfig, jobConfig, shardingContexts, offer, command);
}
}调用
#getShardingContexts(...)方法, 获得分片上下文集合。实现代码如下:private ShardingContexts getShardingContexts(final TaskContext taskContext, final CloudAppConfiguration appConfig, final CloudJobConfiguration jobConfig) { Map<Integer, String> shardingItemParameters = new ShardingItemParameters(jobConfig.getTypeConfig().getCoreConfig().getShardingItemParameters()).getMap(); Map<Integer, String> assignedShardingItemParameters = new HashMap<>(1, 1); int shardingItem = taskContext.getMetaInfo().getShardingItems().get(0); // 单个作业分片 assignedShardingItemParameters.put(shardingItem, shardingItemParameters.containsKey(shardingItem) ? shardingItemParameters.get(shardingItem) : ""); return new ShardingContexts(taskContext.getId(), jobConfig.getJobName(), jobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount(), jobConfig.getTypeConfig().getCoreConfig().getJobParameter(), assignedShardingItemParameters, appConfig.getEventTraceSamplingCount()); }- 当任务为瞬时的脚本作业时,使用 Mesos Slave 命令行调用即可,无需使用 Elastic-Job-Cloud-Executor。
调用
#buildURI(...)方法,创建执行器的二进制文件下载地址。试下代码如下:private Protos.CommandInfo.URI buildURI(final CloudAppConfiguration appConfig, final boolean isCommandExecutor) { Protos.CommandInfo.URI.Builder result = Protos.CommandInfo.URI.newBuilder() .setValue(appConfig.getAppURL()) .setCache(appConfig.isAppCacheEnable()); // cache if (isCommandExecutor && !SupportedExtractionType.isExtraction(appConfig.getAppURL())) { result.setExecutable(true); // 是否可执行 } else { result.setExtract(true); // 是否需要解压 } return result.build(); }- 云作业应用配置
CloudAppConfiguration.appURL,通过 Mesos 实现文件的下载。 云作业应用配置
CloudAppConfiguration.appCacheEnable,应用文件下载是否缓存。FROM 《Mesos 框架构建分布式应用》 P99
Fetcher 缓存
Mesos 0.23 里发布称为 fetcher 缓存的新功能。fetcher 缓存确保每个 artifact 在每个 slave 只会下载一次,即使多个执行器请求同一个 artifact,也只需要等待单词下载完成即可。
- 云作业应用配置
调用
#buildCommand(...)方法,创建执行器启动命令。实现代码如下:private Protos.CommandInfo buildCommand(final Protos.CommandInfo.URI uri, final String script, final ShardingContexts shardingContexts, final boolean isCommandExecutor) { Protos.CommandInfo.Builder result = Protos.CommandInfo.newBuilder().addUris(uri).setShell(true); if (isCommandExecutor) { CommandLine commandLine = CommandLine.parse(script); commandLine.addArgument(GsonFactory.getGson().toJson(shardingContexts), false); result.setValue(Joiner.on(" ").join(commandLine.getExecutable(), Joiner.on(" ").join(commandLine.getArguments()))); } else { result.setValue(script); } return result.build(); }调用
#buildCommandExecutorTaskInfo(...)方法,为瞬时的脚本作业创建 Mesos 任务信息。实现代码如下:private Protos.TaskInfo buildCommandExecutorTaskInfo(final TaskContext taskContext, final CloudJobConfiguration jobConfig, final ShardingContexts shardingContexts, final Protos.Offer offer, final Protos.CommandInfo command) { Protos.TaskInfo.Builder result = Protos.TaskInfo.newBuilder().setTaskId(Protos.TaskID.newBuilder().setValue(taskContext.getId()).build()) .setName(taskContext.getTaskName()).setSlaveId(offer.getSlaveId()) .addResources(buildResource("cpus", jobConfig.getCpuCount(), offer.getResourcesList())) .addResources(buildResource("mem", jobConfig.getMemoryMB(), offer.getResourcesList())) .setData(ByteString.copyFrom(new TaskInfoData(shardingContexts, jobConfig).serialize())); // return result.setCommand(command).build(); }调用
#buildCustomizedExecutorTaskInfo(...)方法,创建 Mesos 任务信息。实现代码如下:private Protos.TaskInfo buildCustomizedExecutorTaskInfo(final TaskContext taskContext, final CloudAppConfiguration appConfig, final CloudJobConfiguration jobConfig, final ShardingContexts shardingContexts, final Protos.Offer offer, final Protos.CommandInfo command) { Protos.TaskInfo.Builder result = Protos.TaskInfo.newBuilder().setTaskId(Protos.TaskID.newBuilder().setValue(taskContext.getId()).build()) .setName(taskContext.getTaskName()).setSlaveId(offer.getSlaveId()) .addResources(buildResource("cpus", jobConfig.getCpuCount(), offer.getResourcesList())) .addResources(buildResource("mem", jobConfig.getMemoryMB(), offer.getResourcesList())) .setData(ByteString.copyFrom(new TaskInfoData(shardingContexts, jobConfig).serialize())); // ExecutorInfo Protos.ExecutorInfo.Builder executorBuilder = Protos.ExecutorInfo.newBuilder().setExecutorId(Protos.ExecutorID.newBuilder() .setValue(taskContext.getExecutorId(jobConfig.getAppName()))) // 执行器 ID .setCommand(command) .addResources(buildResource("cpus", appConfig.getCpuCount(), offer.getResourcesList())) .addResources(buildResource("mem", appConfig.getMemoryMB(), offer.getResourcesList())); if (env.getJobEventRdbConfiguration().isPresent()) { executorBuilder.setData(ByteString.copyFrom(SerializationUtils.serialize(env.getJobEventRdbConfigurationMap()))).build(); } return result.setExecutor(executorBuilder.build()).build(); }调用
Protos.ExecutorInfo.Builder#setValue(...)方法,设置执行器编号。大多数在 Mesos 实现的执行器,一个任务对应一个执行器。而 Elastic-Job-Cloud-Executor 不同于大多数在 Mesos 上的执行器,一个执行器可以对应多个作业。什么意思?在一个 Mesos Slave,相同作业应用,只会启动一个 Elastic-Job-Cloud-Scheduler。当该执行器不存在时,启动一个。当该执行器已经存在,复用该执行器。那么是如何实现该功能的呢?相同作业应用,在同一个 Mesos Slave,使用相同执行器编号。实现代码如下:/** * 获取任务执行器主键. * * @param appName 应用名称 * @return 任务执行器主键 */ public String getExecutorId(final String appName) { return Joiner.on(DELIMITER).join(appName, slaveId); }
4.5 将任务运行时上下文放入运行时队列
调用 FacadeService#addRunning(...) 方法,将任务运行时上下文放入运行时队列。实现代码如下:
// FacadeService.java
/**
* 将任务运行时上下文放入运行时队列.
*
* @param taskContext 任务运行时上下文
*/
public void addRunning(final TaskContext taskContext) {
runningService.add(taskContext);
}
// RunningService.java
/**
* 将任务运行时上下文放入运行时队列.
*
* @param taskContext 任务运行时上下文
*/
public void add(final TaskContext taskContext) {
if (!configurationService.load(taskContext.getMetaInfo().getJobName()).isPresent()) {
return;
}
// 添加到运行中的任务集合
getRunningTasks(taskContext.getMetaInfo().getJobName()).add(taskContext);
// 判断是否为常驻任务
if (!isDaemon(taskContext.getMetaInfo().getJobName())) {
return;
}
// 添加到运行中队列
String runningTaskNodePath = RunningNode.getRunningTaskNodePath(taskContext.getMetaInfo().toString());
if (!regCenter.isExisted(runningTaskNodePath)) {
regCenter.persist(runningTaskNodePath, taskContext.getId());
}
}
// RunningNode.java
final class RunningNode {
static final String ROOT = StateNode.ROOT + "/running";
private static final String RUNNING_JOB = ROOT + "/%s"; // %s = ${JOB_NAME}
private static final String RUNNING_TASK = RUNNING_JOB + "/%s"; // %s = ${TASK_META_INFO}。${TASK_META_INFO}=${JOB_NAME}@-@${ITEM_ID}。
}- RunningService,任务运行时服务,提供对运行中的任务集合、运行中作业队列的各种操作方法。
调用
#getRunningTasks()方法,获得运行中的任务集合,并将当前任务添加到其中。实现代码如下:public Collection<TaskContext> getRunningTasks(final String jobName) { Set<TaskContext> taskContexts = new CopyOnWriteArraySet<>(); Collection<TaskContext> result = RUNNING_TASKS.putIfAbsent(jobName, taskContexts); return null == result ? taskContexts : result; }在运维平台,我们可以看到当前任务正在运行中:
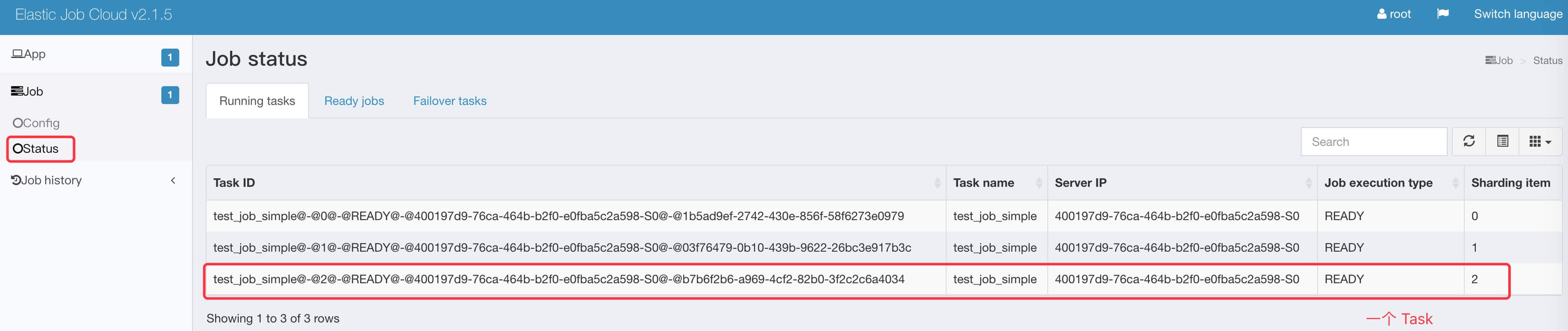
常驻作业会存储在运行中作业队列。运行中作业队列存储在注册中心( Zookeeper )的持久数据节点
/${NAMESPACE}/state/running/${JOB_NAME}/${TASK_META_INFO},存储值为任务编号。使用 zkClient 查看如下:[zk: localhost:2181(CONNECTED) 14] ls /elastic-job-cloud/state/running/test_job_simple [test_job_simple@-@0, test_job_simple@-@1, test_job_simple@-@2] [zk: localhost:2181(CONNECTED) 15] get /elastic-job-cloud/state/running/test_job_simple/test_job_simple@-@0 test_job_simple@-@0@-@READY@-@400197d9-76ca-464b-b2f0-e0fba5c2a598-S0@-@9780ed12-9612-45e3-ac14-feb2911896ff
4.6 从队列中删除已运行的作业
// #runOneIteration()
facadeService.removeLaunchTasksFromQueue(taskContextsList);
// FacadeService.java
/**
* 从队列中删除已运行的作业.
*
* @param taskContexts 任务上下文集合
*/
public void removeLaunchTasksFromQueue(final List<TaskContext> taskContexts) {
List<TaskContext> failoverTaskContexts = new ArrayList<>(taskContexts.size());
Collection<String> readyJobNames = new HashSet<>(taskContexts.size(), 1);
for (TaskContext each : taskContexts) {
switch (each.getType()) {
case FAILOVER:
failoverTaskContexts.add(each);
break;
case READY:
readyJobNames.add(each.getMetaInfo().getJobName());
break;
default:
break;
}
}
// 从失效转移队列中删除相关任务
failoverService.remove(Lists.transform(failoverTaskContexts, new Function<TaskContext, TaskContext.MetaInfo>() {
@Override
public TaskContext.MetaInfo apply(final TaskContext input) {
return input.getMetaInfo();
}
}));
// 从待执行队列中删除相关作业
readyService.remove(readyJobNames);
}4.7 提交任务给 Mesos
// #runOneIteration()
for (Entry<List<OfferID>, List<TaskInfo>> each : offerIdTaskInfoMap.entrySet()) {
schedulerDriver.launchTasks(each.getKey(), each.getValue());
}- 调用
SchedulerDriver#launchTasks(...)方法,提交任务给 Mesos Master。由 Mesos Master 调度任务给 Mesos Slave。Mesos Slave 提交执行器执行任务。
5. TaskExecutor 执行任务
TaskExecutor,实现了 Mesos Executor 接口 org.apache.mesos.Executor。执行器的主要职责之一:执行调度器所请求的任务。TaskExecutor 接收到 Mesos Slave 提交的任务,调用 #launchTask(...) 方法,处理任务。实现代码如下:
// DaemonTaskScheduler.java
@Override
public void launchTask(final ExecutorDriver executorDriver, final Protos.TaskInfo taskInfo) {
executorService.submit(new TaskThread(executorDriver, taskInfo));
}- 调用
ExecutorService#submit(...)方法,提交 TaskThread 到线程池,执行任务。
5.1 TaskThread
@RequiredArgsConstructor
class TaskThread implements Runnable {
private final ExecutorDriver executorDriver;
private final TaskInfo taskInfo;
@Override
public void run() {
// 更新 Mesos 任务状态,运行中。
executorDriver.sendStatusUpdate(Protos.TaskStatus.newBuilder().setTaskId(taskInfo.getTaskId()).setState(Protos.TaskState.TASK_RUNNING).build());
//
Map<String, Object> data = SerializationUtils.deserialize(taskInfo.getData().toByteArray());
ShardingContexts shardingContexts = (ShardingContexts) data.get("shardingContext");
@SuppressWarnings("unchecked")
JobConfigurationContext jobConfig = new JobConfigurationContext((Map<String, String>) data.get("jobConfigContext"));
try {
// 获得 分布式作业
ElasticJob elasticJob = getElasticJobInstance(jobConfig);
// 调度器提供内部服务的门面对象
final CloudJobFacade jobFacade = new CloudJobFacade(shardingContexts, jobConfig, jobEventBus);
// 执行作业
if (jobConfig.isTransient()) {
// 执行作业
JobExecutorFactory.getJobExecutor(elasticJob, jobFacade).execute();
// 更新 Mesos 任务状态,已完成。
executorDriver.sendStatusUpdate(Protos.TaskStatus.newBuilder().setTaskId(taskInfo.getTaskId()).setState(Protos.TaskState.TASK_FINISHED).build());
} else {
// 初始化 常驻作业调度器
new DaemonTaskScheduler(elasticJob, jobConfig, jobFacade, executorDriver, taskInfo.getTaskId()).init();
}
// CHECKSTYLE:OFF
} catch (final Throwable ex) {
// CHECKSTYLE:ON
log.error("Elastic-Job-Cloud-Executor error", ex);
executorDriver.sendStatusUpdate(Protos.TaskStatus.newBuilder().setTaskId(taskInfo.getTaskId()).setState(Protos.TaskState.TASK_ERROR).setMessage(ExceptionUtil.transform(ex)).build());
executorDriver.stop();
throw ex;
}
}
}- 从
TaskInfo.data属性中,可以获得提交任务附带的数据,例如分片上下文集合( ShardingContexts ),内部的作业配置上下文( JobConfigurationContext )。 调用
#getElasticJobInstance()方法,获得任务需要执行的分布式作业( Elastic-Job )。实现代码如下:private ElasticJob getElasticJobInstance(final JobConfigurationContext jobConfig) { if (!Strings.isNullOrEmpty(jobConfig.getBeanName()) && !Strings.isNullOrEmpty(jobConfig.getApplicationContext())) { // spring 环境 return getElasticJobBean(jobConfig); } else { return getElasticJobClass(jobConfig); } } /** * 从 Spring 容器中获得作业对象 * * @param jobConfig 作业配置 * @return 作业对象 */ private ElasticJob getElasticJobBean(final JobConfigurationContext jobConfig) { String applicationContextFile = jobConfig.getApplicationContext(); if (null == applicationContexts.get(applicationContextFile)) { synchronized (applicationContexts) { if (null == applicationContexts.get(applicationContextFile)) { applicationContexts.put(applicationContextFile, new ClassPathXmlApplicationContext(applicationContextFile)); } } } return (ElasticJob) applicationContexts.get(applicationContextFile).getBean(jobConfig.getBeanName()); } /** * 创建作业对象 * * @param jobConfig 作业配置 * @return 作业对象 */ private ElasticJob getElasticJobClass(final JobConfigurationContext jobConfig) { String jobClass = jobConfig.getTypeConfig().getJobClass(); try { Class<?> elasticJobClass = Class.forName(jobClass); if (!ElasticJob.class.isAssignableFrom(elasticJobClass)) { throw new JobSystemException("Elastic-Job: Class '%s' must implements ElasticJob interface.", jobClass); } if (elasticJobClass != ScriptJob.class) { return (ElasticJob) elasticJobClass.newInstance(); } return null; } catch (final ReflectiveOperationException ex) { throw new JobSystemException("Elastic-Job: Class '%s' initialize failure, the error message is '%s'.", jobClass, ex.getMessage()); } }- 当作业是瞬时作业时,调用
AbstractElasticJobExecutor#execute(...)执行作业逻辑,并调用ExecutorDriver#sendStatusUpdate(...)发送状态,更新 Mesos 任务已完成( Protos.TaskState.TASK_FINISHED )。AbstractElasticJobExecutor#execute(...)实现代码,在 Elastic-Job-Lite 和 Elastic-Job-Cloud 基本一致,在《Elastic-Job-Lite 源码分析 —— 作业执行》有详细解析。 - 当作业是常驻作业时,调用
DaemonTaskScheduler#init()方法,初始化作业调度,在「5.2 DaemonTaskScheduler」详细解析。
- 当作业是瞬时作业时,调用
5.2 DaemonTaskScheduler
瞬时作业,通过 Elastic-Job-Cloud-Scheduler 调度任务,提交 Elastic-Job-Cloud-Executor 执行后,等待 Elastic-Job-Scheduler 进行下次调度。
常驻作业,通过 Elastic-Job-Scheduler 提交 Elastic-Job-Cloud-Executor 进行调度。Elastic-Job-Cloud-Executor 使用 DaemonTaskScheduler 不断对常驻作业进行调度而无需 Elastic-Job-Cloud-Scheduler 参与其中。
这就是瞬时作业和常驻作业不同之处。
DaemonTaskScheduler,常驻作业调度器。调用 DaemonTaskScheduler#init() 方法,对一个作业初始化调度,实现代码如下:
/**
* 初始化作业.
*/
public void init() {
// Quartz JobDetail
JobDetail jobDetail = JobBuilder.newJob(DaemonJob.class)
.withIdentity(jobRootConfig.getTypeConfig().getCoreConfig().getJobName()).build();
jobDetail.getJobDataMap().put(ELASTIC_JOB_DATA_MAP_KEY, elasticJob);
jobDetail.getJobDataMap().put(JOB_FACADE_DATA_MAP_KEY, jobFacade);
jobDetail.getJobDataMap().put(EXECUTOR_DRIVER_DATA_MAP_KEY, executorDriver);
jobDetail.getJobDataMap().put(TASK_ID_DATA_MAP_KEY, taskId);
try {
scheduleJob(initializeScheduler(), jobDetail, taskId.getValue(), jobRootConfig.getTypeConfig().getCoreConfig().getCron());
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
private Scheduler initializeScheduler() throws SchedulerException {
StdSchedulerFactory factory = new StdSchedulerFactory();
factory.initialize(getBaseQuartzProperties());
return factory.getScheduler();
}
private Properties getBaseQuartzProperties() {
Properties result = new Properties();
result.put("org.quartz.threadPool.class", org.quartz.simpl.SimpleThreadPool.class.getName());
result.put("org.quartz.threadPool.threadCount", "1"); // 线程数:1
result.put("org.quartz.scheduler.instanceName", taskId.getValue());
if (!jobRootConfig.getTypeConfig().getCoreConfig().isMisfire()) {
result.put("org.quartz.jobStore.misfireThreshold", "1");
}
result.put("org.quartz.plugin.shutdownhook.class", ShutdownHookPlugin.class.getName());
result.put("org.quartz.plugin.shutdownhook.cleanShutdown", Boolean.TRUE.toString());
return result;
}
private void scheduleJob(final Scheduler scheduler, final JobDetail jobDetail, final String triggerIdentity, final String cron) {
try {
if (!scheduler.checkExists(jobDetail.getKey())) {
scheduler.scheduleJob(jobDetail, createTrigger(triggerIdentity, cron));
}
scheduler.start();
RUNNING_SCHEDULERS.putIfAbsent(scheduler.getSchedulerName(), scheduler);
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
private CronTrigger createTrigger(final String triggerIdentity, final String cron) {
return TriggerBuilder.newTrigger()
.withIdentity(triggerIdentity)
.withSchedule(CronScheduleBuilder.cronSchedule(cron)
.withMisfireHandlingInstructionDoNothing())
.build();
}- DaemonTaskScheduler 基于 Quartz 实现作业调度。这里大家看下源码,就不啰嗦解释啦。
- JobBuilder#newJob(...) 的参数是 DaemonJob,下文会讲解到。
DaemonJob 实现代码如下:
public static final class DaemonJob implements Job {
@Setter
private ElasticJob elasticJob;
@Setter
private JobFacade jobFacade;
@Setter
private ExecutorDriver executorDriver;
@Setter
private Protos.TaskID taskId;
@Override
public void execute(final JobExecutionContext context) throws JobExecutionException {
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
int jobEventSamplingCount = shardingContexts.getJobEventSamplingCount();
int currentJobEventSamplingCount = shardingContexts.getCurrentJobEventSamplingCount();
if (jobEventSamplingCount > 0 && ++currentJobEventSamplingCount < jobEventSamplingCount) {
shardingContexts.setCurrentJobEventSamplingCount(currentJobEventSamplingCount);
//
jobFacade.getShardingContexts().setAllowSendJobEvent(false);
// 执行作业
JobExecutorFactory.getJobExecutor(elasticJob, jobFacade).execute();
} else {
//
jobFacade.getShardingContexts().setAllowSendJobEvent(true);
//
executorDriver.sendStatusUpdate(Protos.TaskStatus.newBuilder().setTaskId(taskId).setState(Protos.TaskState.TASK_RUNNING).setMessage("BEGIN").build());
// 执行作业
JobExecutorFactory.getJobExecutor(elasticJob, jobFacade).execute();
//
executorDriver.sendStatusUpdate(Protos.TaskStatus.newBuilder().setTaskId(taskId).setState(Protos.TaskState.TASK_RUNNING).setMessage("COMPLETE").build());
//
shardingContexts.setCurrentJobEventSamplingCount(0);
}
}
}- 调用
AbstractElasticJobExecutor#execute(...)执行作业逻辑。AbstractElasticJobExecutor#execute(...)实现代码,在 Elastic-Job-Lite 和 Elastic-Job-Cloud 基本一致,在《Elastic-Job-Lite 源码分析 —— 作业执行》有详细解析。 jobEventSamplingCount来自应用配置 (CloudAppConfiguration.eventTraceSamplingCount) 属性,常驻作业事件采样率统计条数,默认采样全部记录。为避免数据量过大,可对频繁调度的常驻作业配置采样率,即作业每执行N次,才会记录作业执行及追踪相关数据。当满足采样条件时,调用
ShardingContexts#setAllowSendJobEvent(true),标记要记录作业事件。否则,调用ShardingContexts#setAllowSendJobEvent(false),标记不记录作业时间。作业事件追踪在《Elastic-Job-Lite 源码分析 —— 作业事件追踪》有详细解析。另外,当满足采样调试时,也会调用
ExecutorDriver#sendStatusUpdate(...)方法,更新 Mesos 任务状态为运行中,并附带"BEGIN"或"COMPLETE"消息。
6. SchedulerEngine 处理任务的状态变更
Mesos 调度器的职责之一,处理任务的状态,特别是响应任务和故障。因此在 Elastic-Job-Cloud-Executor 调用 ExecutorDriver#sendStatusUpdate(...) 方法,更新 Mesos 任务状态时,触发调用 Elastic-Job-Cloud-Scheduler 的 SchedulerEngine 的 #statusUpdate(...) 方法,实现代码如下:
@Override
public void statusUpdate(final SchedulerDriver schedulerDriver, final Protos.TaskStatus taskStatus) {
String taskId = taskStatus.getTaskId().getValue();
TaskContext taskContext = TaskContext.from(taskId);
String jobName = taskContext.getMetaInfo().getJobName();
log.trace("call statusUpdate task state is: {}, task id is: {}", taskStatus.getState(), taskId);
jobEventBus.post(new JobStatusTraceEvent(jobName, taskContext.getId(), taskContext.getSlaveId(), Source.CLOUD_SCHEDULER,
taskContext.getType(), String.valueOf(taskContext.getMetaInfo().getShardingItems()), State.valueOf(taskStatus.getState().name()), taskStatus.getMessage()));
switch (taskStatus.getState()) {
case TASK_RUNNING:
if (!facadeService.load(jobName).isPresent()) {
schedulerDriver.killTask(Protos.TaskID.newBuilder().setValue(taskId).build());
}
if ("BEGIN".equals(taskStatus.getMessage())) {
facadeService.updateDaemonStatus(taskContext, false);
} else if ("COMPLETE".equals(taskStatus.getMessage())) {
facadeService.updateDaemonStatus(taskContext, true);
statisticManager.taskRunSuccessfully();
}
break;
case TASK_FINISHED:
facadeService.removeRunning(taskContext);
unAssignTask(taskId);
statisticManager.taskRunSuccessfully();
break;
case TASK_KILLED:
log.warn("task id is: {}, status is: {}, message is: {}, source is: {}", taskId, taskStatus.getState(), taskStatus.getMessage(), taskStatus.getSource());
facadeService.removeRunning(taskContext);
facadeService.addDaemonJobToReadyQueue(jobName);
unAssignTask(taskId);
break;
case TASK_LOST:
case TASK_DROPPED:
case TASK_GONE:
case TASK_GONE_BY_OPERATOR:
case TASK_FAILED:
case TASK_ERROR:
log.warn("task id is: {}, status is: {}, message is: {}, source is: {}", taskId, taskStatus.getState(), taskStatus.getMessage(), taskStatus.getSource());
facadeService.removeRunning(taskContext);
facadeService.recordFailoverTask(taskContext);
unAssignTask(taskId);
statisticManager.taskRunFailed();
break;
case TASK_UNKNOWN:
case TASK_UNREACHABLE:
log.error("task id is: {}, status is: {}, message is: {}, source is: {}", taskId, taskStatus.getState(), taskStatus.getMessage(), taskStatus.getSource());
statisticManager.taskRunFailed();
break;
default:
break;
}
}当更新 Mesos 任务状态为
TASK_RUNNING时,根据附带消息为"BEGIN"或"COMPLETE",分别调用FacadeService#updateDaemonStatus(false / true)方法,更新作业闲置状态。实现代码如下:// FacadeService.java /** * 更新常驻作业运行状态. * * @param taskContext 任务运行时上下文 * @param isIdle 是否空闲 */ public void updateDaemonStatus(final TaskContext taskContext, final boolean isIdle) { runningService.updateIdle(taskContext, isIdle); } // RunningService.java /** * 更新作业闲置状态. * @param taskContext 任务运行时上下文 * @param isIdle 是否闲置 */ public void updateIdle(final TaskContext taskContext, final boolean isIdle) { synchronized (RUNNING_TASKS) { Optional<TaskContext> taskContextOptional = findTask(taskContext); if (taskContextOptional.isPresent()) { taskContextOptional.get().setIdle(isIdle); } else { add(taskContext); } } }若作业配置不存在时,调用
SchedulerDriver#killTask(...)方法,杀死该 Mesos 任务。在《Elastic-Job-Cloud 源码分析 —— 作业调度(二)》进一步解析。当更新 Mesos 任务状态为
TASK_FINISHED时,调用FacadeService#removeRunning(...)方法,将任务从运行时队列删除。实现代码如下:// FacadeService.java /** * 将任务从运行时队列删除. * * @param taskContext 任务运行时上下文 */ public void removeRunning(final TaskContext taskContext) { runningService.remove(taskContext); } // RunningService.java /** * 将任务从运行时队列删除. * * @param taskContext 任务运行时上下文 */ public void remove(final TaskContext taskContext) { // 移除运行中的任务集合 getRunningTasks(taskContext.getMetaInfo().getJobName()).remove(taskContext); // 判断是否为常驻任务 if (!isDaemonOrAbsent(taskContext.getMetaInfo().getJobName())) { return; } // 将任务从运行时队列删除 regCenter.remove(RunningNode.getRunningTaskNodePath(taskContext.getMetaInfo().toString())); String jobRootNode = RunningNode.getRunningJobNodePath(taskContext.getMetaInfo().getJobName()); if (regCenter.isExisted(jobRootNode) && regCenter.getChildrenKeys(jobRootNode).isEmpty()) { regCenter.remove(jobRootNode); } }当该作业对应的所有 Mesos 任务状态都更新为
TASK_FINISHED后,作业可以再次被 Elastic-Job-Cloud-Scheduler 调度。调用
#unAssignTask(...)方法,通知 TaskScheduler 任务被确认未分配到这个主机。TaskScheduler 做任务和 Offer 的匹配,对哪些任务运行在哪些主机是有依赖的,不然怎么做匹配优化呢。在《Fenzo Wiki —— Notify the Scheduler of Assigns and UnAssigns of Tasks》可以进一步了解。实现代码如下:private void unAssignTask(final String taskId) { String hostname = facadeService.popMapping(taskId); if (null != hostname) { taskScheduler.getTaskUnAssigner().call(TaskContext.getIdForUnassignedSlave(taskId), hostname); } }
当更新 Mesos 任务状态为
TASK_KILLED时,调用FacadeService#addDaemonJobToReadyQueue(...)方法,将常驻作业放入待执行队列。在《Elastic-Job-Cloud 源码分析 —— 作业调度(二)》进一步解析。TODO另外会调用
FacadeService#removeRunning(...)、#unAssignTask(...)方法。当更新 Mesos 任务状态为
TASK_ERROR等等时,调用FacadeService#recordFailoverTask(...)方法,在 《Elastic-Job-Cloud 源码分析 —— 作业失效转移》详细解析。另外会调用
FacadeService#removeRunning(...)和#unAssignTask(...)方法。
666. 彩蛋
旁白君:真的真的真的,好长好长好长啊。但是真的真的真的,干货!
芋道君:那必须的!

道友,赶紧上车,分享一波朋友圈!
