

什么是爬虫?
如果是没有接触过爬虫的人可能会有些许疑惑,爬虫是个什么东西呢?其实爬虫的概念很简单,在互联网时代,万维网已然是大量信息的载体,如何有效地利用并提取这些信息是一个巨大的挑战。当我们使用浏览器对某个网站发送请求时,服务器会响应HTML文本并由浏览器来进行渲染显示。爬虫正是利用了这一点,通过程序模拟用户的请求,来获得HTML的内容,并从中提取需要的数据和信息。如果把网络想象成一张蜘蛛网,爬虫程序则像是蜘蛛网上的蜘蛛,不断地爬取数据与信息。
爬虫的概念非常简单易懂,利用python内置的urllib库都可以实现一个简单的爬虫,下面的代码是一个非常简单的爬虫,只要有基本的python知识应该都能看懂。它会收集一个页面中的所有<a>标签(没有做任何规则判断)中的链接,然后顺着这些链接不断地进行深度搜索。
from bs4 import BeautifulSoup
import urllib
import os
from datetime import datetime
# 网页的实体类,只含有两个属性,url和标题
class Page(object):
def __init__(self,url,title):
self._url = url
self._title = title
def __str__(self):
return '[Url]: %s [Title]: %s' %(self._url,self._title)
__repr__ = __str__
@property
def url(self):
return self._url
@property
def title(self):
return self._title
@url.setter
def url(self,value):
if not isinstance(value,str):
raise ValueError('url must be a string!')
if value == '':
raise ValueError('url must be not empty!')
self._url = value
@title.setter
def title(self,value):
if not isinstance(value,str):
raise ValueError('title must be a string!')
if value == '':
raise ValueError('title must be not empty!')
self._title = value
class Spider(object):
def __init__(self,init_page):
self._init_page = init_page # 种子网页,也就是爬虫的入口
self._pages = []
self._soup = None # BeautifulSoup 一个用来解析HTML的解析器
def crawl(self):
start_time = datetime.now()
print('[Start Time]: %s' % start_time)
start_timestamp = start_time.timestamp()
tocrawl = [self._init_page] # 记录将要爬取的网页
crawled = [] # 记录已经爬取过的网页
# 不断循环,直到将这张图搜索完毕
while tocrawl:
page = tocrawl.pop()
if page not in crawled:
self._init_soup(page)
self._packaging_to_pages(page)
links = self._extract_links()
self._union_list(tocrawl,links)
crawled.append(page)
self._write_to_curdir()
end_time = datetime.now()
print('[End Time]: %s' % end_time)
end_timestamp = end_time.timestamp()
print('[Total Time Consuming]: %f.3s' % (start_timestamp - end_timestamp) / 1000)
def _init_soup(self,page):
page_content = None
try:
# urllib可以模拟用户请求,获得响应的HTML文本内容
page_content = urllib.request.urlopen(page).read()
except:
page_content = ''
# 初始化BeautifulSoup,参数二是使用到的解析器名字
self._soup = BeautifulSoup(page_content,'lxml')
def _extract_links(self):
a_tags = self._soup.find_all('a') # 找到所有a标签
links = []
# 收集所有a标签中的链接
for a_tag in a_tags:
links.append(a_tag.get('href'))
return links
def _packaging_to_pages(self,page):
title_string = ''
try:
title_string = self._soup.title.string # 获得title标签中的文本内容
except AttributeError as e :
print(e)
page_obj = Page(page,title_string)
print(page_obj)
self._pages.append(page_obj)
# 将爬取到的所有信息写入到当前目录下的out.txt文件
def _write_to_curdir(self):
cur_path = os.path.join(os.path.abspath('.'),'out.txt')
print('Start write to %s' % cur_path)
with open(cur_path,'w') as f:
f.write(self._pages)
# 将dest中的不存在于src的元素合并到src
def _union_list(self,src,dest):
for dest_val in dest:
if dest_val not in src:
src.append(dest_val)
@property
def init_page(self):
return self._init_page
@property
def pages(self):
return self._pages
def test():
spider = Spider('https://sylvanassun.github.io/')
spider.crawl()
if __name__ == '__main__':
test()但是我们如果想要实现一个性能高效的爬虫,那需要的复杂度也会增长,本文旨在快速实现,所以我们需要借助他人实现的爬虫框架来当做脚手架,在这之上来构建我们的图片爬虫(如果有时间的话当然也鼓励自己造轮子啦)。
本文作者为: SylvanasSun(sylvanas.sun@gmail.com).转载请务必将下面这段话置于文章开头处(保留超链接).
本文首发自SylvanasSun Blog,原文链接: sylvanassun.github.io/2017/09/20/…
BeautifulSoup
BeautifulSoup是一个用于从HTML和XML中提取数据的python库。Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
利用好BeautifulSoup可以为我们省去许多编写正则表达式的时间,如果当你需要更精准地进行搜索时,BeautifulSoup也支持使用正则表达式进行查询。
BeautifulSoup3已经停止维护了,现在基本使用的都是BeautifulSoup4,安装BeautifulSoup4很简单,只需要执行以下的命令。
pip install beautifulsoup4然后从bs4模块中导入BeautifulSoup对象,并创建这个对象。
from bs4 import BeautifulSoup
soup = BeautifulSoup(body,'lxml')创建BeautifulSoup对象需要传入两个参数,第一个是需要进行解析的HTML内容,第二个参数为解析器的名字(如果不传入这个参数,BeautifulSoup会默认使用python内置的解析器html.parser)。BeautifulSoup支持多种解析器,有lxml、html5lib、html.parser。
第三方解析器需要用户自己安装,本文中使用的是lxml解析器,安装命令如下(它还需要先安装C语言库)。
pip install lxml下面以一个例子演示使用BeautifulSoup的基本方式,如果还想了解更多可以去参考BeautifulSoup文档。
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html,'lxml')
# 格式化输出soup中的内容
print(soup.prettify())
# 可以通过.操作符来访问标签对象
title = soup.title
print(title)
p = soup.p
print(p)
# 获得title标签中的文本内容,这2个方法得到的结果是一样的
print(title.text)
print(title.get_text())
# 获得head标签的所有子节点,contents返回的是一个列表,children返回的是一个迭代器
head = soup.head
print(head.contents)
print(head.children)
# 获得所有a标签,并输出每个a标签href属性中的内容
a_tags = soup.find_all('a')
for a_tag in a_tags:
print(a_tag['href'])
# find函数与find_all一样,只不过返回的是找到的第一个标签
print(soup.find('a')['href'])
# 根据属性查找,这2个方法得到的结果是一样的
print(soup.find('p',class_='title'))
print(soup.find('p',attrs={'class': 'title'}))Scrapy
Scrapy是一个功能强大的爬虫框架,它已经实现了一个性能高效的爬虫结构,并提供了很多供程序员自定义的配置。使用Scrapy只需要在它的规则上编写我们的爬虫逻辑即可。
首先需要先安装Scrapy,执行命令pip install scrapy。然后再执行命令scrapy startproject 你的项目名来生成Scrapy的基本项目文件夹。生成的项目结构如下。
你的项目名/
scrapy.cfg
你的项目名/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...scrapy.cfg: 项目的配置文件。items.py:物品模块,用户需要在这个模块中定义数据封装的实体类。pipelines.py:管道模块,用户需要在这个模块中定义处理数据的逻辑(如存储到数据库等)。settings.py:这个模块定义了整个项目中的各种配置变量。spiders/:在这个包中定义用户自己的爬虫模块。
启动Scrapy的爬虫也很简单,只需要执行命令scrapy crawl 你的爬虫名。下面介绍Scrapy中的关键模块的演示案例,如果想要了解有关Scrapy的更多信息,请参考Scrapy官方文档。
items
items模块主要是为了将爬取到的非结构化数据封装到一个结构化对象中,自定义的item类必须继承自scrapy.Item,且每个属性都要赋值为scrapy.Field()。
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()操作item对象就像操作一个dict对象一样简单。
product = Product()
# 对属性赋值
product['name'] = 'Sylvanas'
product['price'] = 998
# 获得属性
print(product['name'])
print(product['price'])pipelines
当一个Item经由爬虫封装之后将会到达Pipeline类,你可以定义自己的Pipeline类来决定将Item的处理策略。
每个Pipeline可以实现以下函数。
process_item(item, spider): 每个Pipeline都会调用此函数来处理Item,这个函数必须返回一个Item,如果在处理过程中遇见错误,可以抛出DropItem异常。open_spider(spider): 当spider开始时将会调用此函数,可以利用这个函数进行打开文件等操作。close_spider(spider):当spider关闭时将会调用此函数,可以利用这个函数对IO资源进行关闭。from_crawler(cls, crawler): 这个函数用于获取settings.py模块中的属性。注意这个函数是一个类方法。
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def __init__(self, HELLO):
self.HELLO = HELLO
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings # 从crawler中获得settings
return cls(settings['HELLO']) # 返回settings中的属性,将由__init__函数接收当定义完你的Pipeline后,还需要在settings.py中对你的Pipeline进行设置。
ITEM_PIPELINES = {
# 后面跟的数字是优先级别
'pipeline类的全路径': 300,
}spiders
在spiders模块中,用户可以通过自定义Spider类来制定自己的爬虫逻辑与数据封装策略。每个Spider都必须继承自class scrapy.spider.Spider,这是Scrapy中最简单的爬虫基类,它没有什么特殊功能,Scrapy也提供了其他功能不同的Spider类供用户选择,这里就不多叙述了,可以去参考官方文档。
用户可以通过以下属性来自定义配置Spider:
name: 这是Spider的名称,Scrapy需要通过这个属性来定位Spider并启动爬虫,它是唯一且必需的。allowed_domains: 这个属性规定了Spider允许爬取的域名。start_urls:Spider开始时将抓取的网页列表。start_requests(): 该函数是Spider开始抓取时启动的函数,它只会被调用一次,有的网站必须要求用户登录,可以使用这个函数先进行模拟登录。make_requests_from_url(url): 该函数接收一个url并返回Request对象。除非重写该函数,否则它会默认以parse(response)函数作为回调函数,并启用dont_filter参数(这个参数是用于过滤重复url的)。parse(response): 当请求没有设置回调函数时,则会默认调用parse(response)。log(message[, level, component]): 用于记录日志。closed(reason): 当Spider关闭时调用。
import scrapy
class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
]
def parse(self, response):
self.log('A response from %s just arrived!' % response.url)其他依赖库
Requests
Requests也是一个第三方python库,它比python内置的urllib更加简单好用。只需要安装(pip install requests),然后导包后,即可轻松对网站发起请求。
import requests
# 支持http的各种类型请求
r = requests.post("http://httpbin.org/post")
r = requests.put("http://httpbin.org/put")
r = requests.delete("http://httpbin.org/delete")
r = requests.head("http://httpbin.org/get")
r = requests.options("http://httpbin.org/get")
# 获得响应内容
r.text # 返回文本
r.content # 返回字节
r.raw # 返回原始内容
r.json() # 返回json关于更多的参数与内容请参考Requests文档。
BloomFilter
BloomFilter是一个用于过滤重复数据的数据结构,我们可以使用它来对重复的url进行过滤。本文使用的BloomFilter来自于python-bloomfilter,其他操作系统用户请使用pip install pybloom命令安装,windows用户请使用pip install pybloom-live(原版对windows不友好)。
分析
介绍了需要的依赖库之后,我们终于可以开始实现自己的图片爬虫了。我们的目标是爬https://www.deviantart.com/网站中的图片,在写爬虫程序之前,还需要先分析一下页面的HTML结构,这样才能针对性地找到图片的源地址。
为了保证爬到的图片的质量,我决定从热门页面开始爬,链接为https://www.deviantart.com/whats-hot/。
打开浏览器的开发者工具后,可以发现每个图片都是由一个a标签组成,每个a标签的class为torpedo-thumb-link,而这个a标签的href正好就是这张图片的详情页面(如果我们从这里就开始爬图片的话,那么爬到的可都只是缩略图)。
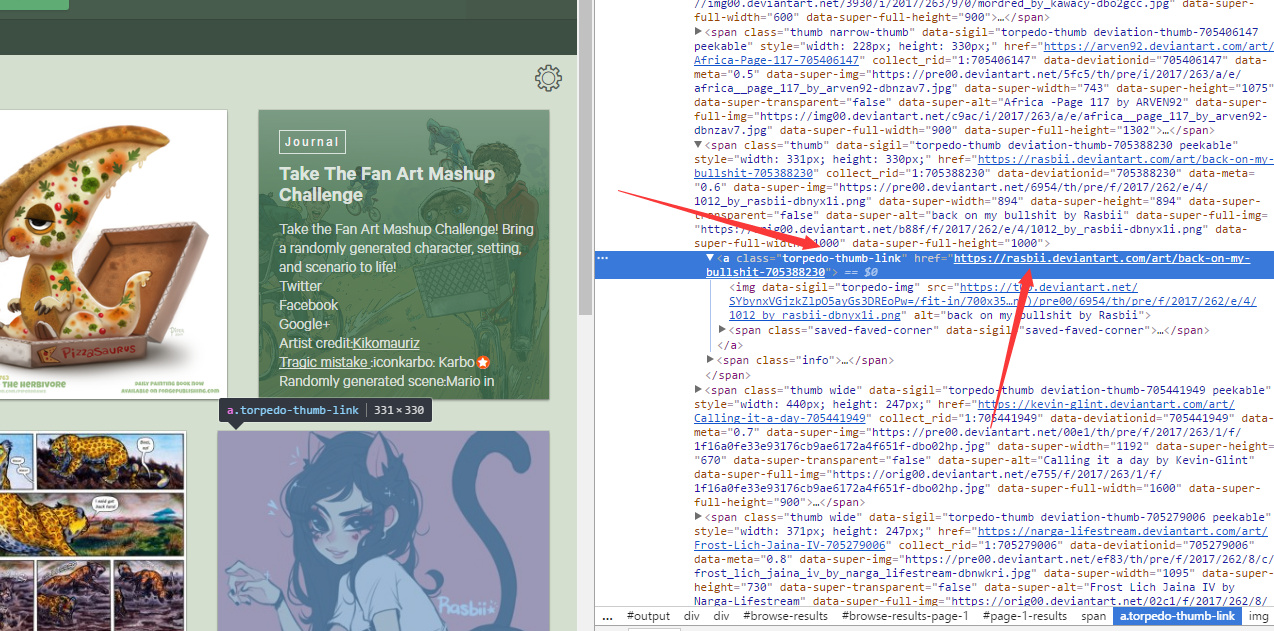
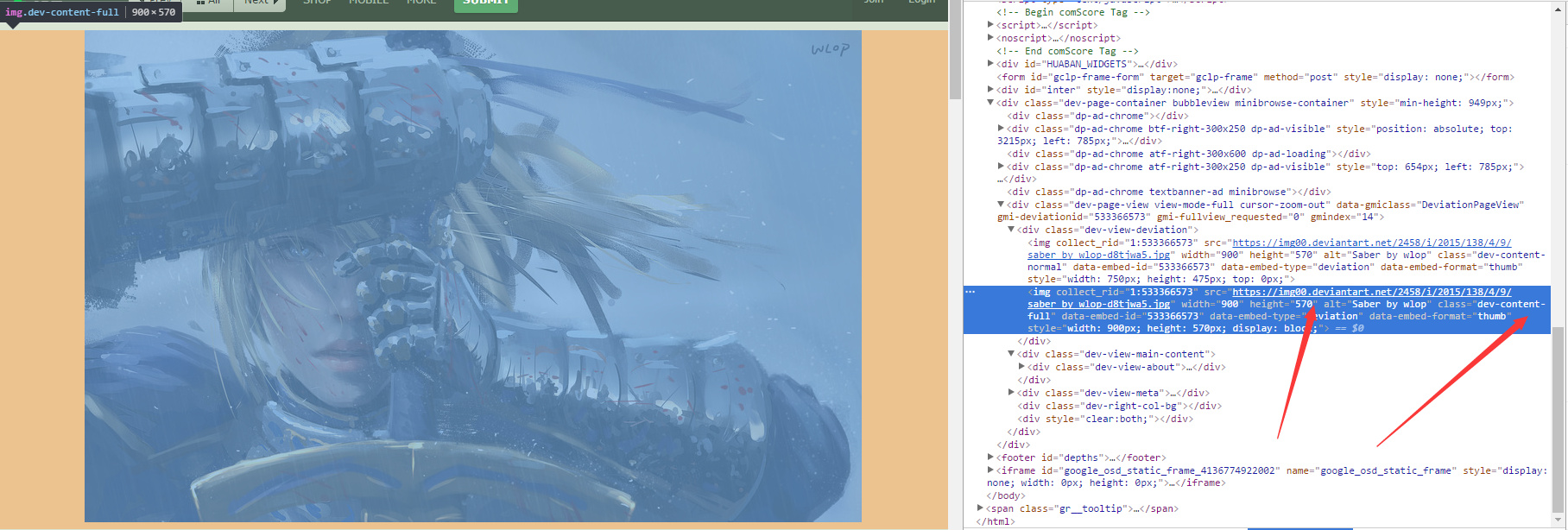
进入到详情页后,不要马上爬取当前图片的源地址,因为当前页显示的图片并不是原始格式,我们对图片双击放大之后再使用开发者工具抓到这个图片所在的img标签后,再让爬虫获取这个标签中的源地址。
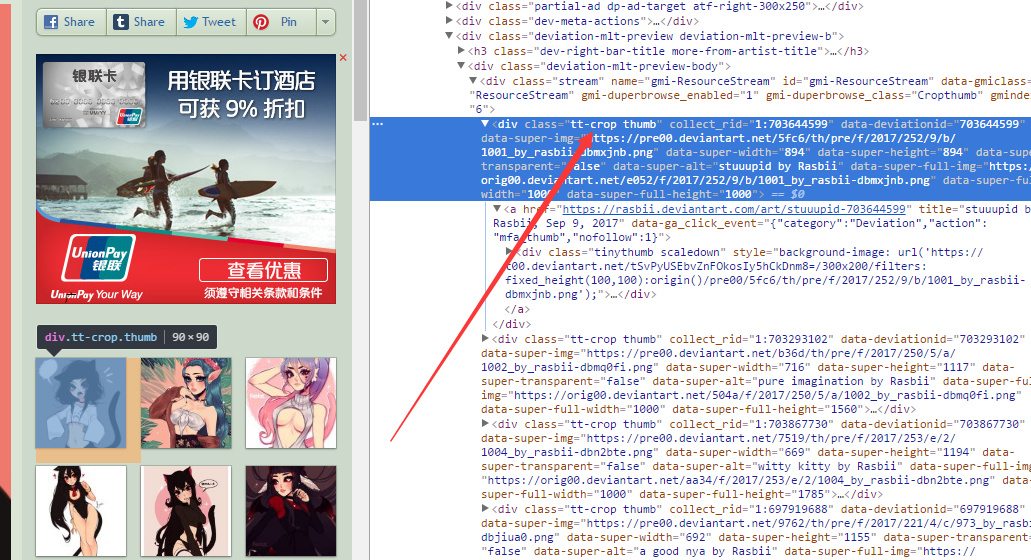
在获得图片的源地址之后,我的策略是让爬虫继续爬取该页中推荐的更多图片,通过开发者工具,可以发现这些图片都被封装在一个class为tt-crop thumb的div标签中,而该标签里的第一个a子标签正好就是这个图片的详情页链接。
初始配置
在对网页的HTML进行分析之后,可以开始写程序了,首先先用Scrapy的命令来初始化项目。之后在settings.py中做如下配置。
# 这个是网络爬虫协议,爬虫访问网站时都会检查是否有robots.txt文件,
# 然后根据文件中的内容选择性地进行爬取,我们这里设置为False即不检查robots.txt
ROBOTSTXT_OBEY = False
# 图片下载的根目录路径
IMAGES_STORE = '.'
# 图片最大下载数量,当下载的图片达到这个数字时,将会手动关闭爬虫
MAXIMUM_IMAGE_NUMBER = 10000然后定义我们的Item。
import scrapy
class DeviantArtSpiderItem(scrapy.Item):
author = scrapy.Field() # 作者名
image_name = scrapy.Field() # 图片名
image_id = scrapy.Field() # 图片id
image_src = scrapy.Field() # 图片的源地址创建自己的spider模块与Spider类。
import requests
from bs4 import BeautifulSoup
# this import package is right,if PyCharm give out warning please ignore
from deviant_art_spider.items import DeviantArtSpiderItem
from pybloom_live import BloomFilter
from scrapy.contrib.linkextractors.lxmlhtml import LxmlLinkExtractor
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.http import Request
class DeviantArtImageSpider(CrawlSpider):
name = 'deviant_art_image_spider'
# 我不想让scrapy帮助过滤所以设置为空
allowed_domains = ''
start_urls = ['https://www.deviantart.com/whats-hot/']
rules = (
Rule(LxmlLinkExtractor(
allow={'https://www.deviantart.com/whats-hot/[\?\w+=\d+]*', }),
callback='parse_page', # 设置回调函数
follow=True # 允许爬虫不断地跟随链接进行爬取
),
)
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36"
" (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "https://www.deviantart.com/"
}
# 初始化BloomFilter
filter = BloomFilter(capacity=15000)DeviantArtImageSpider继承自CrawlSpider,该类是Scrapy最常用的Spider类,它通过Rule类来定义爬取链接的规则,上述代码中使用了正则表达式https://www.deviantart.com/whats-hot/[\?\w+=\d+]*,这个正则表达式将访问每一页的热门页面。
解析热门页面
爬虫启动时将会先访问热门页面,请求得到响应之后会调用回调函数,我们需要在这个回调函数中获取上述分析中得到的<a class = 'torpedo-thumb-link'>标签,然后抽取出每张图片的详情页链接。
def parse_page(self, response):
soup = self._init_soup(response, '[PREPARING PARSE PAGE]')
if soup is None:
return None
# 找到所有class为torpedo-thumb-link的a标签
all_a_tag = soup.find_all('a', class_='torpedo-thumb-link')
if all_a_tag is not None and len(all_a_tag) > 0:
for a_tag in all_a_tag:
# 提取图片详情页,然后对详情页链接发起请求,并设置回调函数
detail_link = a_tag['href']
request = Request(
url=detail_link,
headers=self.headers,
callback=self.parse_detail_page
)
# 通过request与response对象来传递Item
request.meta['item'] = DeviantArtSpiderItem()
yield request
else:
self.logger.debug('[PARSE FAILED] get <a> tag failed')
return None
# 初始化BeautifulSoup对象
def _init_soup(self, response, log):
url = response.url
self.headers['Referer'] = url
self.logger.debug(log + ' ' + url)
body = requests.get(url, headers=self.headers, timeout=2).content
soup = BeautifulSoup(body, 'lxml')
if soup is None:
self.logger.debug('[PARSE FAILED] read %s body failed' % url)
return None
return soup解析详情页
parse_page()函数会不断地发送请求到详情页链接,解析详情页的回调函数需要处理数据封装到Item,还需要提取详情页中更多图片的详情链接然后发送请求。
def parse_detail_page(self, response):
if response.url in self.filter:
self.logger.debug('[REPETITION] already parse url %s ' % response.url)
return None
soup = self._init_soup(response, '[PREPARING DETAIL PAGE]')
if soup is None:
return None
# 包装Item并返回
yield self.packing_item(response.meta['item'], soup)
self.filter.add(response.url)
# 继续抓取当前页中的其他图片
all_div_tag = soup.find_all('div', class_='tt-crop thumb')
if all_div_tag is not None and len(all_div_tag) > 0:
for div_tag in all_div_tag:
detail_link = div_tag.find('a')['href']
request = Request(
url=detail_link,
headers=self.headers,
callback=self.parse_detail_page
)
request.meta['item'] = DeviantArtSpiderItem()
yield request
else:
self.logger.debug('[PARSE FAILED] get <div> tag failed')
return None
# 封装数据到Item
def packing_item(self, item, soup):
self.logger.debug('[PREPARING PACKING ITEM]..........')
img = soup.find('img', class_='dev-content-full')
img_alt = img['alt'] # alt属性中保存了图片名与作者名
item['image_name'] = img_alt[:img_alt.find('by') - 1]
item['author'] = img_alt[img_alt.find('by') + 2:]
item['image_id'] = img['data-embed-id'] # data-embed-id属性保存了图片id
item['image_src'] = img['src']
self.logger.debug('[PACKING ITEM FINISHED] %s ' % item)
return item处理Item
对于Item的处理,只是简单地将图片命名与下载到本地。我没有使用多进程或者多线程,也没有使用Scrapy自带的ImagePipeline(自由度不高),有兴趣的童鞋可以自己选择实现。
import requests
import threading
import os
from scrapy.exceptions import DropItem, CloseSpider
class DeviantArtSpiderPipeline(object):
def __init__(self, IMAGE_STORE, MAXIMUM_IMAGE_NUMBER):
if IMAGE_STORE is None or MAXIMUM_IMAGE_NUMBER is None:
raise CloseSpider('Pipeline load settings failed')
self.IMAGE_STORE = IMAGE_STORE
self.MAXIMUM_IMAGE_NUMBER = MAXIMUM_IMAGE_NUMBER
# 记录当前下载的图片数量
self.image_max_counter = 0
# 根据图片数量创建文件夹,每1000张在一个文件夹中
self.dir_counter = 0
def process_item(self, item, spider):
if item is None:
raise DropItem('Item is null')
dir_path = self.make_dir()
# 拼接图片名称
image_final_name = item['image_name'] + '-' + item['image_id'] + '-by@' + item['author'] + '.jpg'
dest_path = os.path.join(dir_path, image_final_name)
self.download_image(item['image_src'], dest_path)
self.image_max_counter += 1
if self.image_max_counter >= self.MAXIMUM_IMAGE_NUMBER:
raise CloseSpider('Current downloaded image already equal maximum number')
return item
def make_dir(self):
print('[IMAGE_CURRENT NUMBER] %d ' % self.image_max_counter)
if self.image_max_counter % 1000 == 0:
self.dir_counter += 1
path = os.path.abspath(self.IMAGE_STORE)
path = os.path.join(path, 'crawl_images')
path = os.path.join(path, 'dir-' + str(self.dir_counter))
if not os.path.exists(path):
os.makedirs(path)
print('[CREATED DIR] %s ' % path)
return path
def download_image(self, src, dest):
print('[Thread %s] preparing download image.....' % threading.current_thread().name)
response = requests.get(src, timeout=2)
if response.status_code == 200:
with open(dest, 'wb') as f:
f.write(response.content)
print('[DOWNLOAD FINISHED] from %s to %s ' % (src, dest))
else:
raise DropItem('[Thread %s] request image src failed status code = %s'
% (threading.current_thread().name, response.status_code))
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
return cls(settings['IMAGES_STORE'], settings['MAXIMUM_IMAGE_NUMBER'])在settings.py中注册该Pipeline
ITEM_PIPELINES = {
'deviant_art_spider.pipelines.DeviantArtSpiderPipeline': 300,
}IP代理池
有些网站会有反爬虫机制,为了解决这个问题,每次请求都使用不同的IP代理,有很多网站提供IP代理服务,我们需要写一个爬虫从云代理中抓取它提供的免费IP代理(免费IP很不稳定,而且我用了代理之后反而各种请求失败了Orz...)。
import os
import requests
from bs4 import BeautifulSoup
class ProxiesSpider(object):
def __init__(self, max_page_number=10):
self.seed = 'http://www.ip3366.net/free/'
self.max_page_number = max_page_number # 最大页数
self.crawled_proxies = [] # 爬到的ip,每个元素都是一个dict
self.verified_proxies = [] # 校验过的ip
self.headers = {
'Accept': '*/*',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/45.0.2454.101 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8'
}
self.tocrawl_url = []
def crawl(self):
self.tocrawl_url.append(self.seed)
page_counter = 1
while self.tocrawl_url:
if page_counter > self.max_page_number:
break
url = self.tocrawl_url.pop()
body = requests.get(url=url, headers=self.headers, params={'page': page_counter}).content
soup = BeautifulSoup(body, 'lxml')
if soup is None:
print('PARSE PAGE FAILED.......')
continue
self.parse_page(soup)
print('Parse page %s done' % (url + '?page=' + str(page_counter)))
page_counter += 1
self.tocrawl_url.append(url)
self.verify_proxies()
self.download()
# 解析页面并封装
def parse_page(self, soup):
table = soup.find('table', class_='table table-bordered table-striped')
tr_list = table.tbody.find_all('tr')
for tr in tr_list:
ip = tr.contents[1].text
port = tr.contents[3].text
protocol = tr.contents[7].text.lower()
url = protocol + '://' + ip + ':' + port
self.crawled_proxies.append({url: protocol})
print('Add url %s to crawled_proxies' % url)
# 对ip进行校验
def verify_proxies(self):
print('Start verify proxies.......')
while self.crawled_proxies:
self.verify_proxy(self.crawled_proxies.pop())
print('Verify proxies done.....')
def verify_proxy(self, proxy):
proxies = {}
for key in proxy:
proxies[str(proxy[key])] = key # requests的proxies的格式必须为 协议 : 地址
try:
if requests.get('https://www.deviantart.com/', proxies=proxies, timeout=2).status_code == 200:
print('verify proxy success %s ' % proxies)
self.verified_proxies.append(proxy)
except:
print('verify proxy fail %s ' % proxies)
# 保存到文件中
def download(self):
current_path = os.getcwd()
parent_path = os.path.dirname(current_path)
with open(parent_path + '\proxies.txt', 'w') as f:
for proxy in self.verified_proxies:
for key in proxy.keys():
f.write(key + '\n')
if __name__ == '__main__':
spider = ProxiesSpider()
spider.crawl()得到了IP代理池之后,还要在Scrapy的middlewares.py模块定义代理中间件类。
import time
from scrapy import signals
import os
import random
class ProxyMiddleware(object):
# 每次请求前从IP代理池中选择一个IP代理并进行设置
def process_request(self, request, spider):
proxy = self.get_proxy(self.make_path())
print('Acquire proxy %s ' % proxy)
request.meta['proxy'] = proxy
# 请求失败,重新设置IP代理
def process_response(self, request, response, spider):
if response.status != 200:
proxy = self.get_proxy(self.make_path())
print('Response status code is not 200,try reset request proxy %s ' % proxy)
request.meta['proxy'] = proxy
return request
return response
def make_path(self):
current = os.path.abspath('.')
parent = os.path.dirname(current)
return os.path.dirname(parent) + '\proxies.txt'
# 从IP代理文件中随机获得一个IP代理地址
def get_proxy(self, path):
if not os.path.isfile(path):
print('[LOADING PROXY] loading proxies failed proxies file is not exist')
while True:
with open(path, 'r') as f:
proxies = f.readlines()
if proxies:
break
else:
time.sleep(1)
return random.choice(proxies).strip()最后在settings.py中进行注册。
DOWNLOADER_MIDDLEWARES = {
# 这个中间件是由scrapy提供的,并且它是必需的
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 543,
# 我们自定义的代理中间件
'deviant_art_spider.middlewares.ProxyMiddleware': 540
}End
我们的图片爬虫已经完成了,执行命令scrapy crawl deviant_art_image_spider,然后尽情搜集图片吧!
想要获得本文中的完整源代码与P站爬虫请点我,顺便求个star...
最近心血来潮想要写爬虫,所以花了点时间过了一遍
python语法便匆匆上手了,代码写的有点丑也不够pythonic,各位看官求请吐槽。
