

arXiv 是当前最流行的预印本库。自 1991 年创办以来,arXiv 为研究者提供了一个在正式同行评议之前分享预印本文章的平台。新技术使文档创建和分发更加便捷,文化实践推动合作和数据共享,这使得 arXiv 快速发展,日渐流行。arXiv 在研究交流和 Web 历史上占据独特的位置,但是它自创建以来几乎很少改变。在此文章中,我们看一下 arXiv 的优势和缺点,进而探讨新技术可以给 arXiv 带来怎样的改变。
日前,在最新的 Google Scholar h5-index 排名中,我们可以看到在计算机视觉领域下,arXiv 以 137 分位列第二,仅次于业内顶会 CVPR。除了计算机视觉领域,在「机器学习」下,arXiv Machine Learning 同样位列第二,略低于 ICML。因此,可以到论文预印网站 arXiv 在人工智能、机器学习领域的重要性。
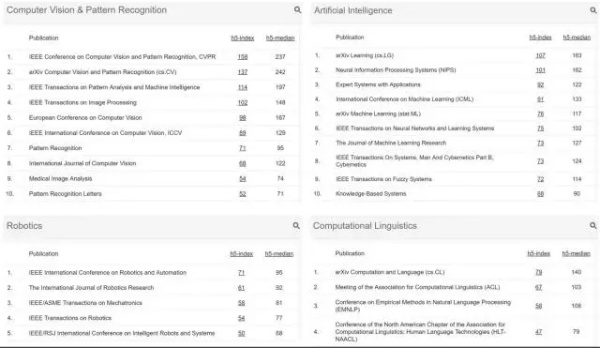
虽然 arXiv 越来越受欢迎,但围绕 arXiv 的争议也越来越多:学术论文是否应该引用 arXiv 文章等等。在这篇文章中,作者对 arXiv 的优缺点做了总结,同时给出了未来变革的建议,比如引入评论与同行评议机制。
引言
arXiv 是当前最流行的预印本库。该网站于 1991 年由物理学家 Paul Ginsparg 创立,为研究者提供了一个在正式同行评议之前分享预印本文章的平台。今天,arXiv 每个月发布文章超过 10000 篇,涉及高能物理学、计算机科学、定量生物学、统计学、计量金融等领域(见图 1)。arXiv 早期的成功来自于新技术的发展和合作共享文化的完善。的确,在 arXiv 之前,物理学家通过信件的方式分享近期完成的文章手稿,后来是通过邮件传递……
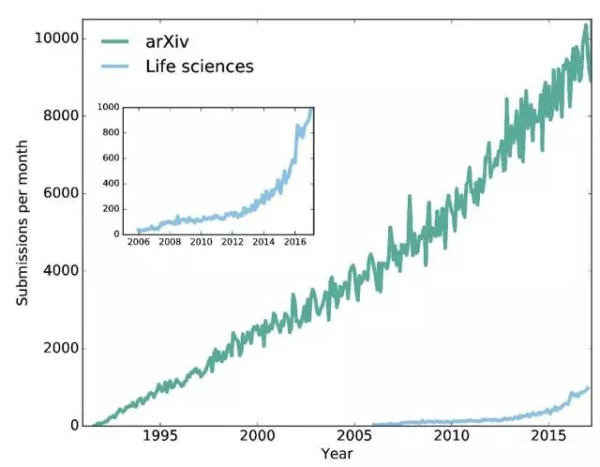
图 1. 1991 年到 2017 年发表在自然科学(arXiv)和 Life Sciences 上的预印本文章数量。这个时间段中,在 arXiv 和 Life sciences 上提交的预印本数量为别为 1,263,265、32,284。小图显示近期提交到 Life sciences 上的预印本数量(包括提交到『arXiv q-bio』, 『Nature Preceedings』, 『F1000Research』, 『PeerJ Preprints』, 『bioRxiv』, 『The Winnower』, 『preprints.org』 和『Wellcome Open Research』上的预印本)快速增长。
arXiv 的优势
arXiv 自创立以来,就提供最便捷和最强大的方式,使研究者能够共享研究成果。作者可以免费、快速、直接地与研究社区共享研究成果,同时也使公众可以免费地获取研究成果。arXiv 是一些世界上最重要研究的「故乡」,比如「庞加莱猜想的证明」(Perelman, 2002; Perelman, 2003; Perelman, 2003a)和「希格斯玻色子的发现」。1991 年之后的差不多 20 年内,大多数其他领域并未获得同样的信息自由交流待遇,直到近期大量 arXiv 的仿制品出现在新的领域(见图 1)。易用和实用恰恰贴合了 arXiv 所服务的研究社区(技术先进且具备长期分享和合作传统的研究者)的需求,还有网站的简洁性。下面我们列举了几项推动 arXiv 成功的关键技术和文化影响因素。下一章我们将介绍阻止新型、更优质的实践的局限性因素。
使用 LaTeX 进行排版
arXiv 上大部分论文都使用 LaTeX 进行排版。LaTeX 允许研究者轻松排版和分享文档。从一开始,这样的解决方案就对所有研究者可用,但是只有它服务的社区采用了该方案,即物理学家和数学家,他们的文档中包含大量公式。LaTeX 对早期预印本和同行共享的成功非常关键。今天,它仍然被物理学家、数学家、计算机科学家等研究者使用,因为它提供了表达复杂的数学符号的最佳解决方案。
精通技术的社区
从一开始,一个既知道如何从新技术中获益又愿意从中获益的社区(物理学)帮助 arXiv 迅速崛起。而化学、生物医学等其他领域具有更多的协作性质(Fanelli 2016),这些领域可能缺少使用 LaTeX 写作、创建和运行电子邮件和网络服务器的知识和兴趣,而这正是创建 arXiv 的两个必要基础。
arXiv 的劣势
自创办以来,arXiv 迅速且持续的成功源于它乐于利用新技术(LaTex、电子邮件、网页服务器),且它本就是服务于协作、开放、共享的技术社区。然而,随着时间变化,arXiv 并未改进、反思自我,未能追随科学领域技术与社区实践的变化。阻碍 arXiv 迅速创新的最主要因素是什么?我们认为是 LaTex。LaTex 促使 arXiv 迅速发展,难以置信,它竟然成为 arXiv 最大的短板。事实上,arXiv 对 LaTex 的过分依赖导致了下列劣势:
限制于单个社区
物理学领域之外的大部分研究人员(也因此不了解 arXiv),用 Microsoft Word 或其他 WYSIWYG 编辑器写草稿。使用 LaTex 渗透进了大部分研究领域(数学、统计学、物理学、天文、计算机科学),据统计,用 LaTex 编写的学术文章比例大约为 18%(2016,Pepe)。LaTex 不仅学习曲线陡峭,它的界面、语言、使用方式对不会编程或者只用过 WYSIWYG 编辑器的人来说都是陌生的。
以打印为主的「PDF」垃圾场
当你上传一个 LaTex 文件时,arXiv 会压缩它并创建一个 PDF 文档。这是标准的程序。在学术界,数十年来都是用 PDF 或 Postscript 格式交换、阅读文章的。PDF 是印刷手稿的一种有效、简单的方式,但它并不适合在网页上阅读、讨论和共享。PDF 文档(大多数)是静态、二维且不可编辑的,甚至可以说 PDF 只是纸质论文的数字图片。
低可发现性
arXiv 支持的研究成果均为 PDF 格式。作者提交论文时提供的题目、摘要和作者名单是元数据,PDF 文档中包含这些内容,同时 HTML 文件中也有这些内容,以提高文章的可发现性。搜索引擎在 PDF 文本挖掘中的效果越来越好,但现在或以后的搜索引擎从稠密的两列论文中抽取和理解文本的可能性仍然很低。重点是,逆向工程对于 PDF 文档是无效的。那么我们为什么要把内容锁在机器不可读的格式中呢?
数据
数据共享已经成为所有学科的基础惯例了。简单来说,如果公开的研究论文建立在数据之上,作者需要提供他们的研究所基于的资源(数据和代码)最小集。但这在 arXiv 的「LaTex to PDF」机制下不可能实现。从 2010 年到 2013 年,arXiv 尝试过在论文侧边处放置数据,但失败了。虽然该项目遇到了政府支持中断的情况,但我们认为失败的部分原因在于论文和数据独立存在。
现在人们如何共享数据呢?使用 kludgy 策略。例如天文和物理学领域的一种增长趋势是在发表或预印论文中添加数据集链接。这种做法使得数据更可见、更可信,因为数据集是链接到论文的。但最近的调查显示,加链接容易过期。
未来的 arXiv
如果能够重建 arXiv 以展望 arXiv 未来的样子,那么以上所列出来的与其说是挑战,不如说是机会,为了构建更好的 arXiv,我们将给出几个建议。
网页原生性的和网页优先的
学术交流圈中越来越多的人一致认为学术出版需要超越 PDF 格式的限制,而且我们都相信未来的论文将是网页原生性的(web-native)(Goodman 2016)。照此,未来的 arXiv 将不得不允许以 HTML 的格式接收作品和论文。将学术论文转化为 HTML 是为未来的学术知识库铺平道路的第一步。你阅读的论文,无论是 PDF 还是 HTML 的格式,都将是网页优先的(web-first)。未来的 arXiv 将以网页原生性的原稿为主。
多格式的和格式中性的
ArXiv 过分依赖于 LaTeX。你正在看的这篇文章是由三个作者使用 LaTeX 和 Rich Text 的组合在 Authrea 上写的。LaTeX 只不过是用来插入数学符号、公式、表格的一种格式,而不能用来排版和格式化整篇原稿。用 LaTeX 排版原稿是很费时的 (Brischoux 2009),最重要的是它将文件锁定在一个格式上从而不能使用灵活的现代技术(比如,语义分析并嵌入知识网络促进论文的可发现性,提升影响力)。未来的 arXiv 将是格式中性的,并且可以按不同的内容使用不同的格式。
数字对象标识符
数字对象标识符(digital object identifier,DOI)是专用于学术出版的标识符,用以识别和追踪其它的著作。很多杂志都强制规定必须对引文使用 DOIs,以指定对应的数据集、预印本、研究文献、网站以及其它的学术著作。由于预印本的出版率上升很快(Berg 2016),并且基金机构也终于意识到了预印本的重要性 (https://grants.nih.gov/grants/guide/notice-files/NOT-OD-17-050.html%EF%BC%89),因此使用可靠的标准识别预印本是很关键的,即 DOI。你正在阅读的这篇文章是在 Authorea 上写的,并且使用 DOI 标注,做了预印本。未来的 arXiv 将是以 DOI 标识的预印本数据库。
支持开放数据和开放研究
未来的 arXiv 不仅是带有文本和图像的 PDF 文档的集合,而是整合了数据、代码和所有重现研究结果所需资源的论文数据库。解决重现性危机的唯一方式就是使论文变成数据驱动性的。这篇文章有一幅图,我们已经设置,使所有读者可以获取这幅图背后的数据。如果你在线阅读本文,你将能够点击图 1 中数据中的 Data 标记,查看、下载和研读该图表中的数据;点击 Code 标记,查看我们用来分析和可视化该图表的代码(Jupyter Notebook 格式)。未来的 arXiv 将在论文中同时容纳数据和代码。
评论和开放性的同行评议
arXiv 目前不支持读者和作者评论。其理念在于 arXiv 不是同行评议性质的,同行评议发生在其他地方,比如期刊级别。因此,评论和评议系统较难维护和运营,而且未必有用。而预印本提供了一个前所未有的机会来开放评论和评议系统,并借此提高手稿接受的评议和评论数量。我们不提倡替代传统的同行评议,而是用预印本开放的评议对其进行补充。我们认为(1)更多的学者应该参与同行评议中,(2)同行评议应该开放进行,这样评议才能成为发表(预印)研究的关键组成部分。鉴于论文发表数量的不断增加和每篇论文的平均作者人数,这看起来不仅自然而然,而且必要。这也表明当前的同行评议制度不可持续。未来的 arXiv 将在传统的同行评议之外支持开放的评论和评议。
替代指标
学术界目前用来评估研究论文影响力的唯一权威指标是引用(或其他基于引用的指标)。arXiv 不公开替代指标(替代引用)的信息,如论文的下载量、tweet 转发量,或者博客转发量。不公开替代指标的一个重要但可疑的原因是这些指标易于操纵。如果这些指标成为确定研究者地位的权威系统,那么我们面临的是一个易于操纵的系统。我们认为这些指标对评估研究的影响力有重要的价值,作为传统的指标的添加,而不是取代。重要的是,有研究显示论文的下载量和转推量与引用次数有很强的相关。未来的 arXiv 将变得透明,并公开能够反映研究论文真实影响力的替代指标。
可发现、结构化、语义、机器可读
用于一个基于 web 的知识库而不是 PDF 文档的最后一个重要优势是可发现性(discoverability)。论文的全部文本(不只是标题和摘要)可以通过搜索引擎和学术资料库进行检索,提升了内容的可见性。此外,基于 web 的文章具备更明确的语义结构,使之能够完全被机器阅读。未来的 arXiv 将重新思考,将论文作为访问语义结构化内容的 API。
结论
从 arXiv 的历史来看,我们发现了其成为最流行的在线预印本知识库的一系列决定性因素。我们认为 arXiv 兴盛的原因之一在于它迎合了技术从业人员长久以来共享与合作的传统。该网站的简单性与 LaTex 中心的提交流程,保证了它在社区内的快速增长,被用于完全把控排字流程、编写含有大量公式的文档。
我们认为虽然 arXiv 很早就适应了科技行业,但从发布以来变化极小。这种不情愿或者没能力发展新技术和实用方式的态度,对社区更好的交流实践来说是种障碍。
我们建议未来的 arXiv 应该是纯网页或者以网页为主的,多格式或者格式中性的,以便于适应整个研究社区。为了发展其透明性与可重现性,它要建立在开放数据与开放研究之上,也要允许评论、开放同行审议。未来的 arXiv 将会成为一个由数字对象标识符(DOI)工具标识的预印论文的数据库,有极好的语义结构,便于机器读取,易于发现。未来,arXiv 也会是透明的,会公布关于某项研究的所有信息,包含决定该研究影响力的所有参数。
我们认为 arXiv 如果继续保持不变,将会被其他服务所取代,就像 arXiv 曾取代过其他服务一样。我们鼓励研究人员对该平台有更多的需求,且相信在网页时代,通过 PDF 共享研究的时代必将终结。未来,让我们创造更好的共享研究的新方式。
原文链接:https://www.authorea.com/users/3/articles/173764-the-arxiv-of-the-future-will-not-look-like-the-arxiv
