

在前两篇文章中,我们分析了React组件的实现,挂载以及生命周期的流程。在阅读源码的过程中,我们经常会看到诸如transaction和UpdateQueue这样的代码,这涉及到React中的两个概念:事务和更新队列。因为之前的文章对于这些我们一笔带过,所以本篇我们基于大家都再熟悉不过的setState方法来探究事务机制和更新队列。
1.setState相关
在第一篇文章《React源码解析(一):组件的实现与挂载》中我们已经知道,通过class声明的组件原型具有setState方法:

该方法传入两个参数partialState和callBack,前者是新的state值,后者是回调函数。而updater是在构造函数中进行定义的:
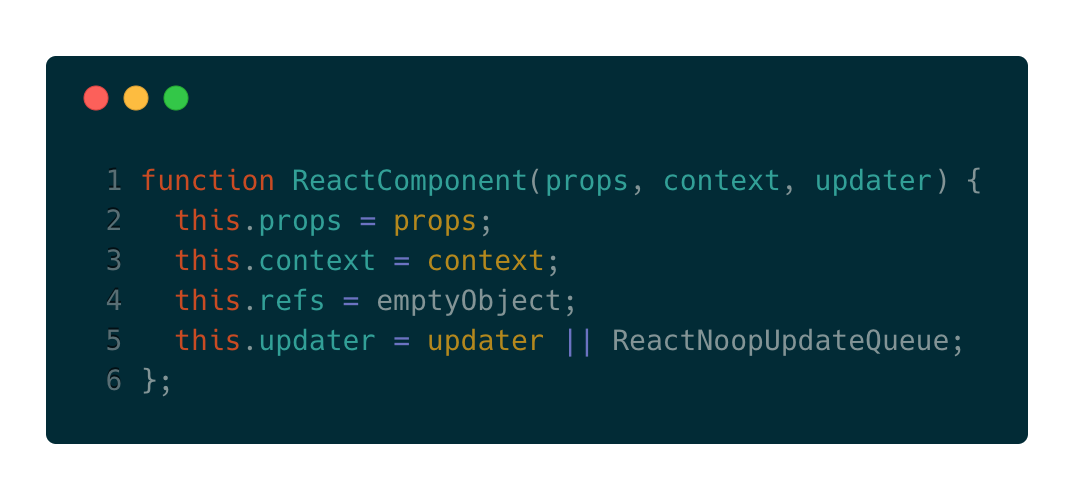
可以看出updater是构造函数传入的,所以找到哪里执行了new ReactComponent,就能找到updater是什么。以自定义组件ReactCompositeComponent为例,在_constructComponentWithoutOwner方法中,我们发现了它的踪迹:
return new Component(publicProps, publicContext, updateQueue);
对应参数发现updater其实就是updateQueue。接下来我们看看this.updater.enqueueSetState中的enqueueSetState是什么:
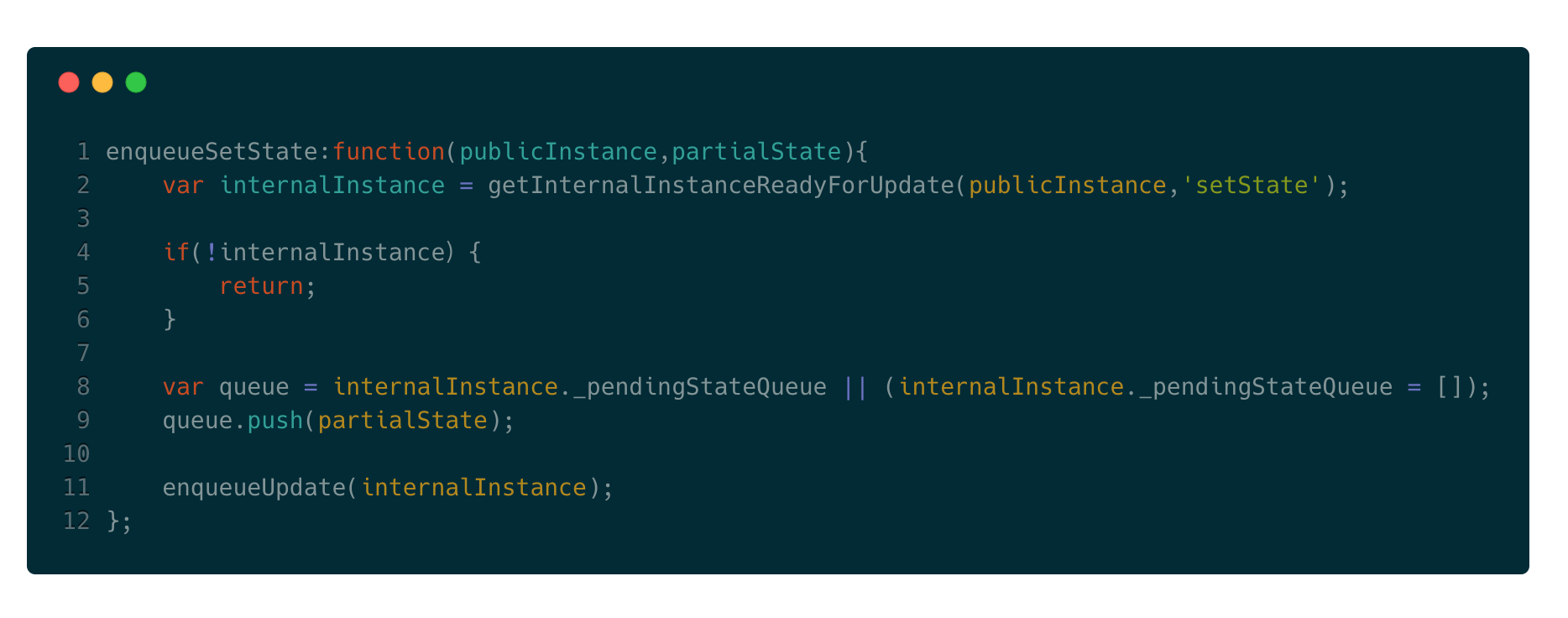
getInternalInstanceReadyForUpdate方法的目的是获取当前组件对象,将其赋值给internalInstance变量。接下来判断当前组件对象的state更新队列是否存在,如果存在则将partialState也就是新的state值加入队列;如果不存在,则创建该对象的更新队列,可以注意到队列是以数组形式存在的。我们看下最后调用的enqueueUpdate方法做了哪些事:

由代码可见,当batchingStrategy.isBatchingUpdates为false时,将执行batchedUpdates更新队列,若为true时,则将组件放入dirtyComponent中。我们看下batchingStrategy的源码:

大致地看下,isBatchingUpdates的初始值是false,且batchedUpdates内部执行传入的回调函数。
看到这么长的逻辑似乎有点懵,但从这些代码我们隐约意识到React并不是随随便便就进行组件的更新,而是通过状态(好像是true/false)的判断来执行。实际上,React内部采用了"状态机"的概念,组件处于不同的状态时,所执行的逻辑也并不相同。以组件更新流程为例,React以事务+状态的形式对组件进行更新,因此接下来我们探讨事务的机制。
2.transaction事务
首先看下官方源码的解析图:
<pre>
* wrappers (injected at creation time)
* + +
* | |
* +-----------------|--------|--------------+
* | v | |
* | +---------------+ | |
* | +--| wrapper1 |---|----+ |
* | | +---------------+ v | |
* | | +-------------+ | |
* | | +----| wrapper2 |--------+ |
* | | | +-------------+ | | |
* | | | | | |
* | v v v v | wrapper
* | +---+ +---+ +---------+ +---+ +---+ | invariants
* perform(anyMethod) | | | | | | | | | | | | maintained
* +----------------->|-|---|-|---|-->|anyMethod|---|---|-|---|-|-------->
* | | | | | | | | | | | |
* | | | | | | | | | | | |
* | | | | | | | | | | | |
* | +---+ +---+ +---------+ +---+ +---+ |
* | initialize close |
* +-----------------------------------------+
* </pre>
从流程图上看很简单,每一个方法会被wrapper所包裹,必须用perform调用,在被包裹方法前后分别执行initialize和close。举例说明普通函数和被wrapper包裹的函数执行时有什么不同:
function method(){
console.log('111')
};
transaction.perform(method);
//执行initialize方法
//输出'111'
//执行close方法
我们知道在前面的batchingStrategy的代码中transaction.perform(callBack)实际调用的是transaction.perform(enqueueUpdate),但enqueueUpdate方法中仍然存在transaction.perform(enqueueUpdate),这样岂不是造成了死循环?
为了避免可能死循环的问题,wrapper的作用就显现出来了。我们看下这两个wrapper是如何定义的:
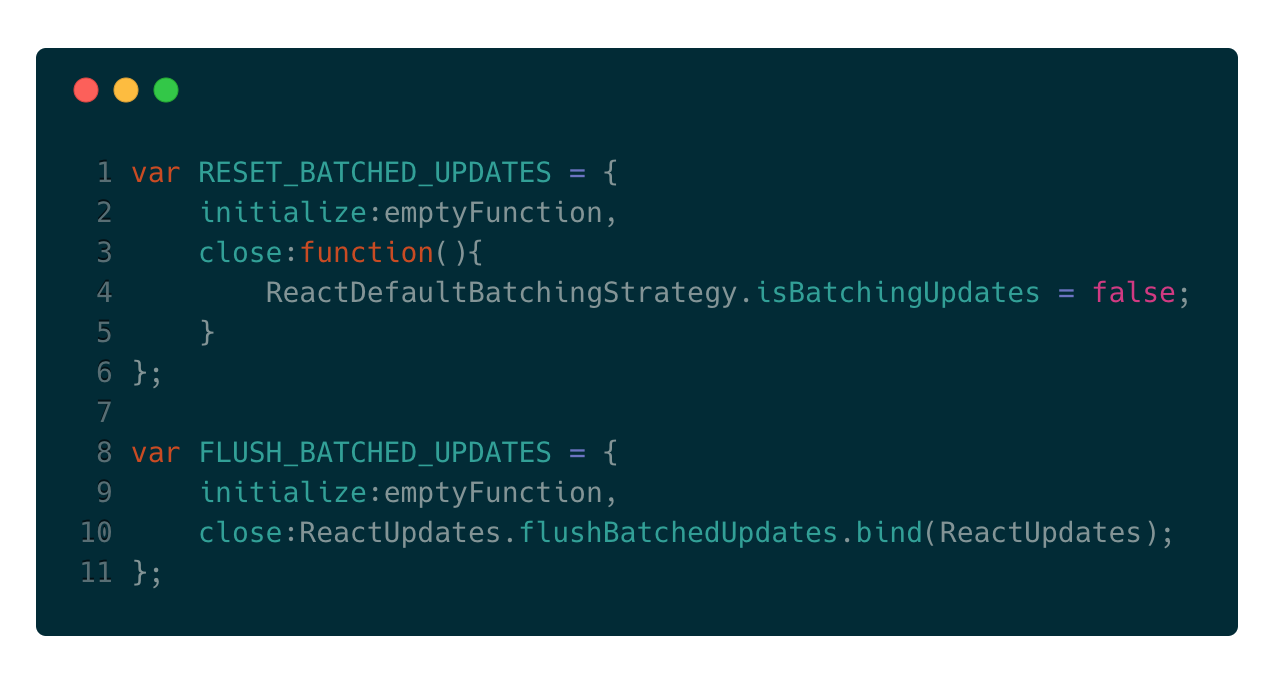
从上面的思维导图可知,isBatchingUpdates初始值为false,当以事务的形式执行transaction.perform(enqueueUpdate)时,实际上执行流程如下:
// RESET_BATCHED_UPDATES.initialize() 实际为空函数
// enqueue()
// RESET_BATCHED_UPDATES.close()
用流程图来说明:
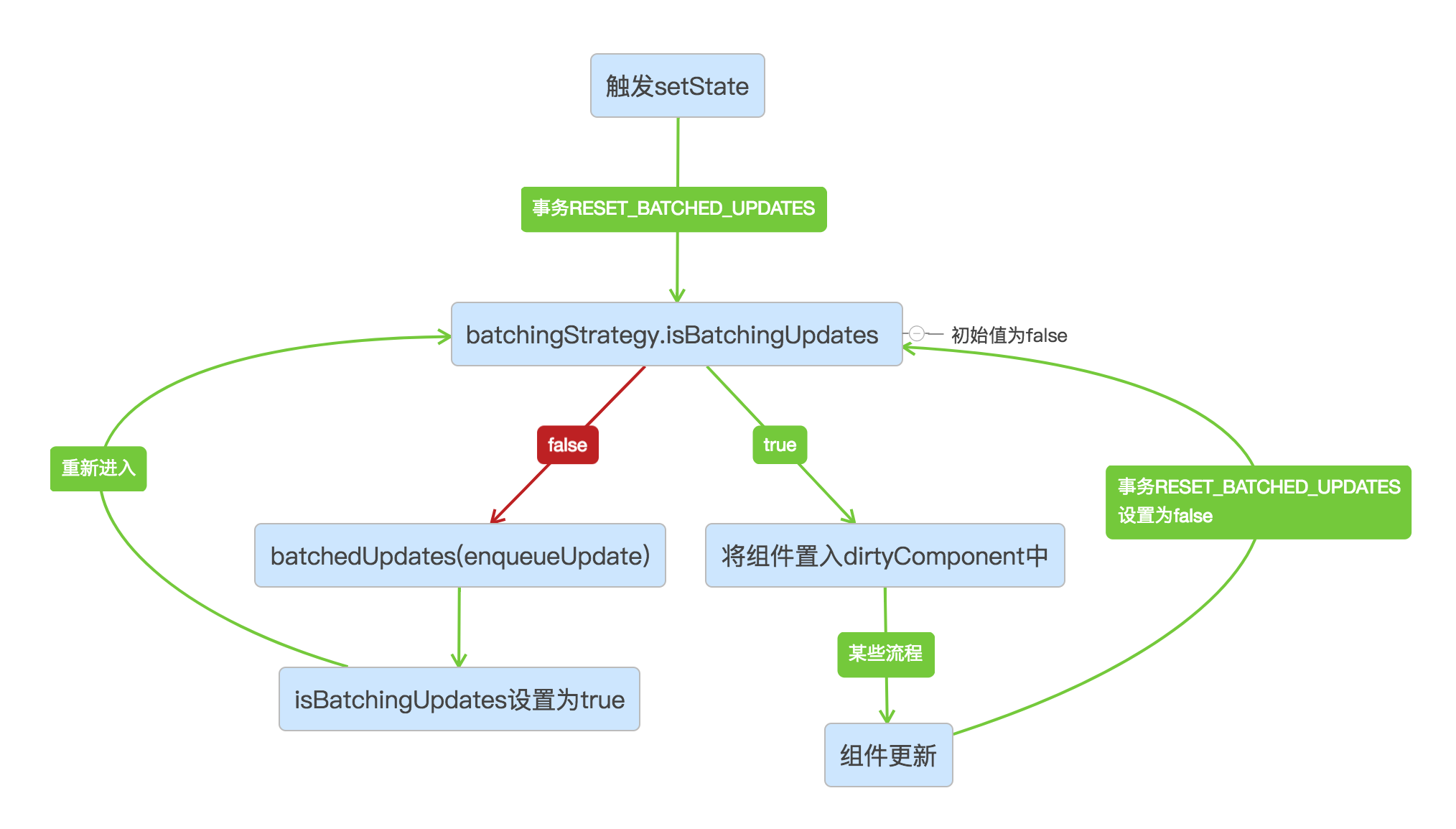
用文字说明的话,那就是RESET_BATCHED_UPDATES这个wrapper的作用是设置isBatchingUpdates也就是组件更新状态的值,组件有更新要求的话则设置为更新状态,更新结束后重新恢复原状态。
这样做有什么好处呢?当然是为了避免组件的重复render,提升性能啦~
RESET_BATCHED_UPDATES是用于更改isBatchingUpdates的布尔值false或者true,那FLUSH_BATCHED_UPDATES的作用是什么呢?其实可以大致猜到它的作用是更新组件,先看下FLUSH_BATCHED_UPDATES.close()的实现逻辑:
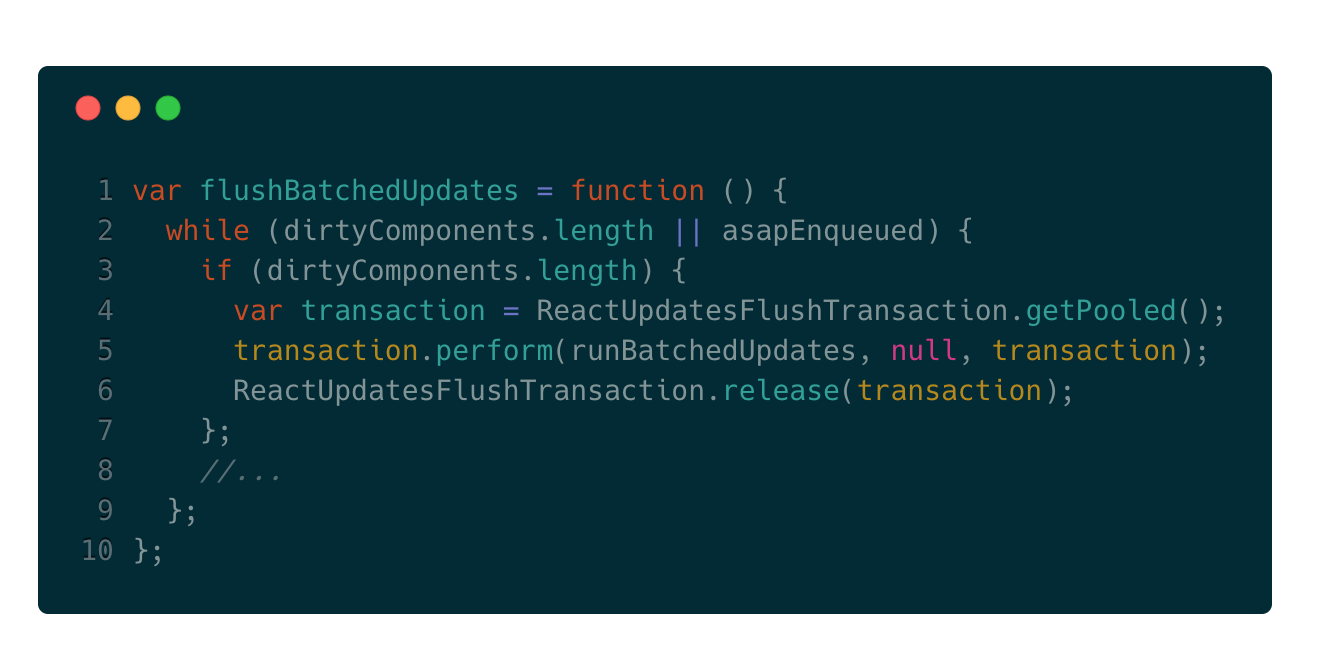
可以看到flushBatchedUpdates方法循环遍历所有的dirtyComponents,又通过事务的形式调用runBatchedUpdates方法,因为源码较长所以在这里直接说明该方法所做的两件事:
- 一是通过执行
updateComponent方法来更新组件 - 二是若
setState方法传入了回调函数则将回调函数存入callbackQueue队列。
看下updateComponent源码:
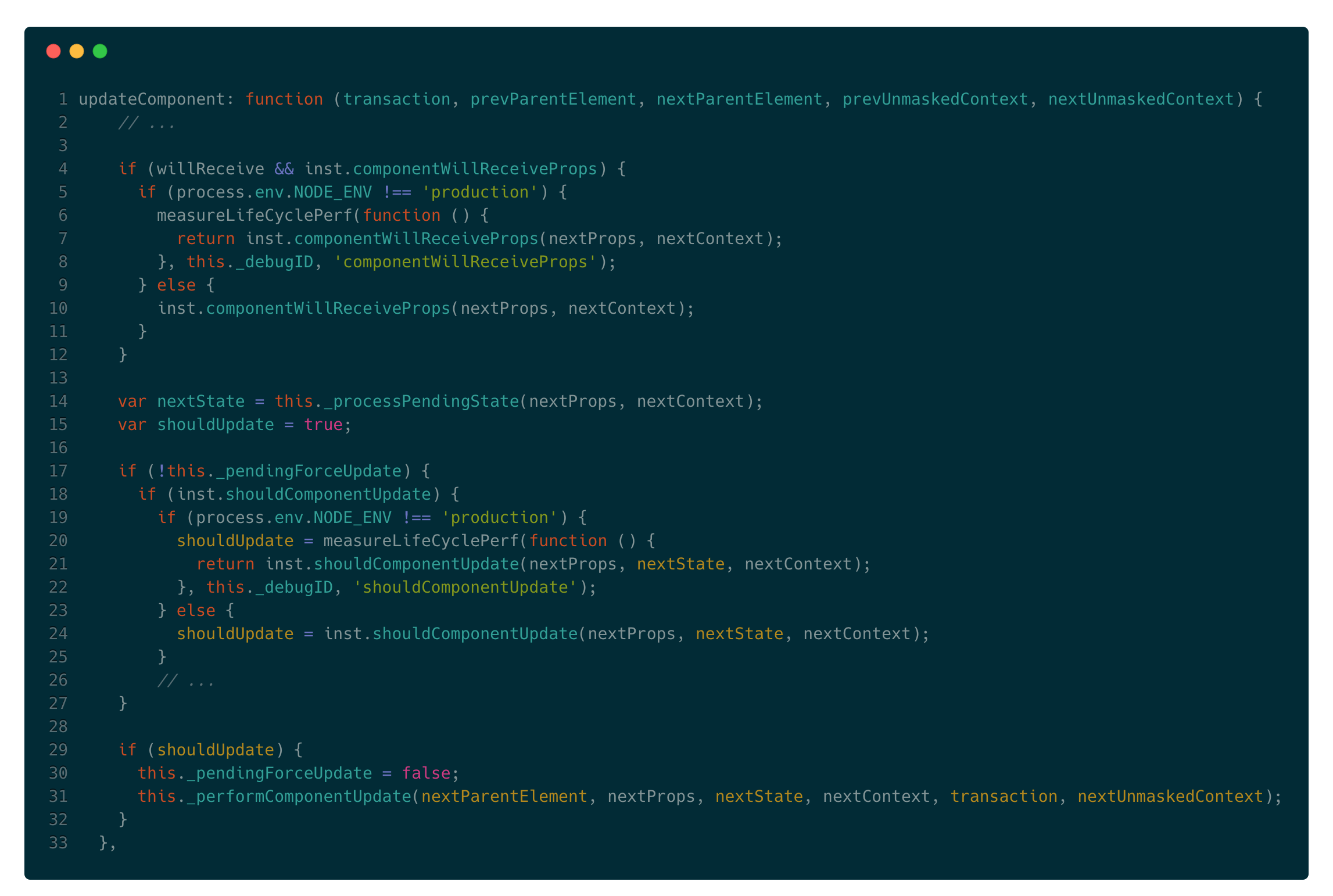
可以看到执行了componentWillReceiveProps方法和shouldComponentUpdate方法。其中不能忽视的一点是在shouldComponentUpdate之前,执行了_processPendingState方法,我们看下这个函数做了什么:
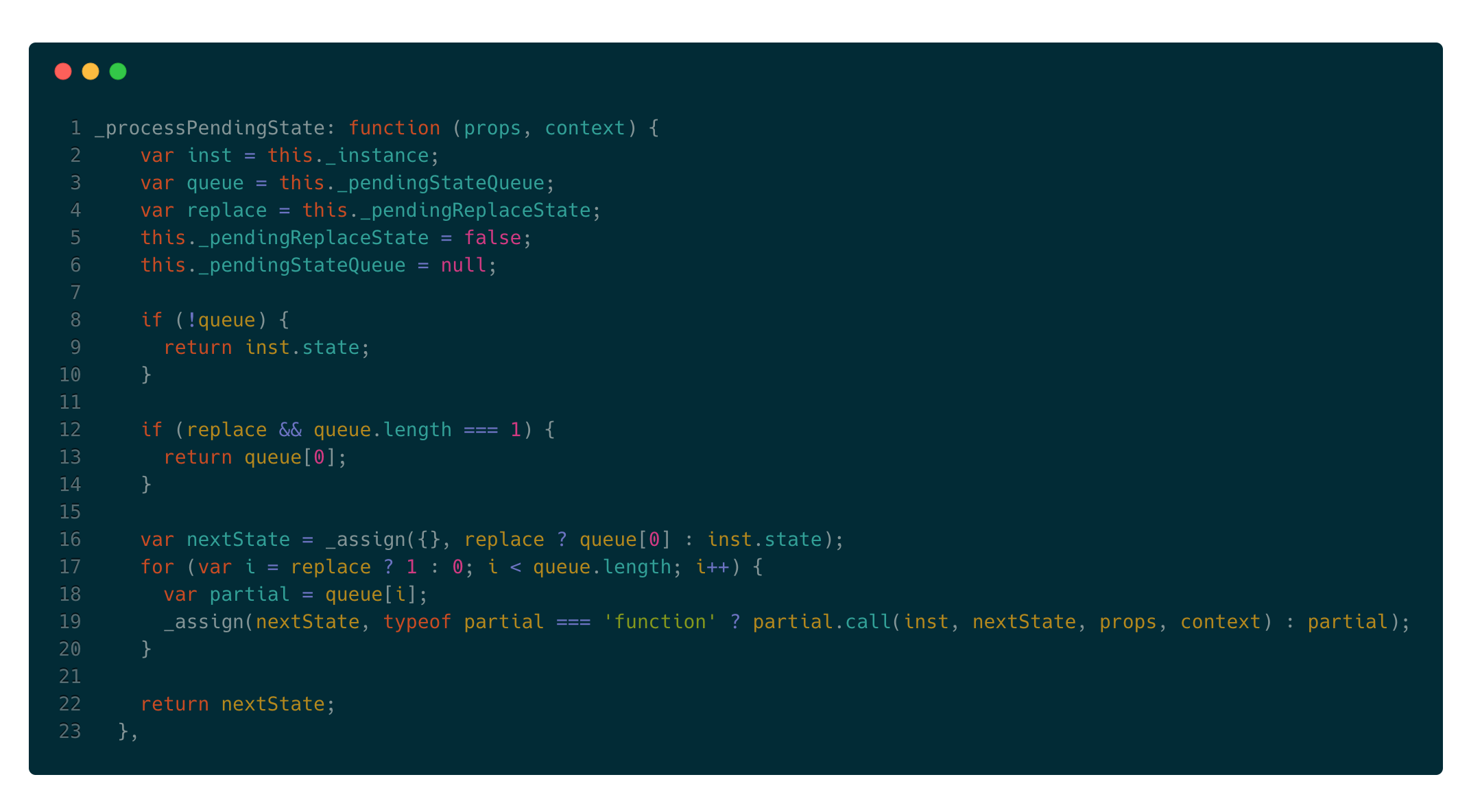
该函数主要对state进行处理:
1.如果更新队列为null,那么返回原来的state;
2.如果更新队列有一个更新,那么返回更新值;
3.如果更新队列有多个更新,那么通过for循环将它们合并;
综上说明了,在一个生命周期内,在componentShouldUpdate执行之前,所有的state变化都会被合并,最后统一处理。
回到_updateComponent,最后如果shouldUpdate为true,执行_performComponentUpdate方法:
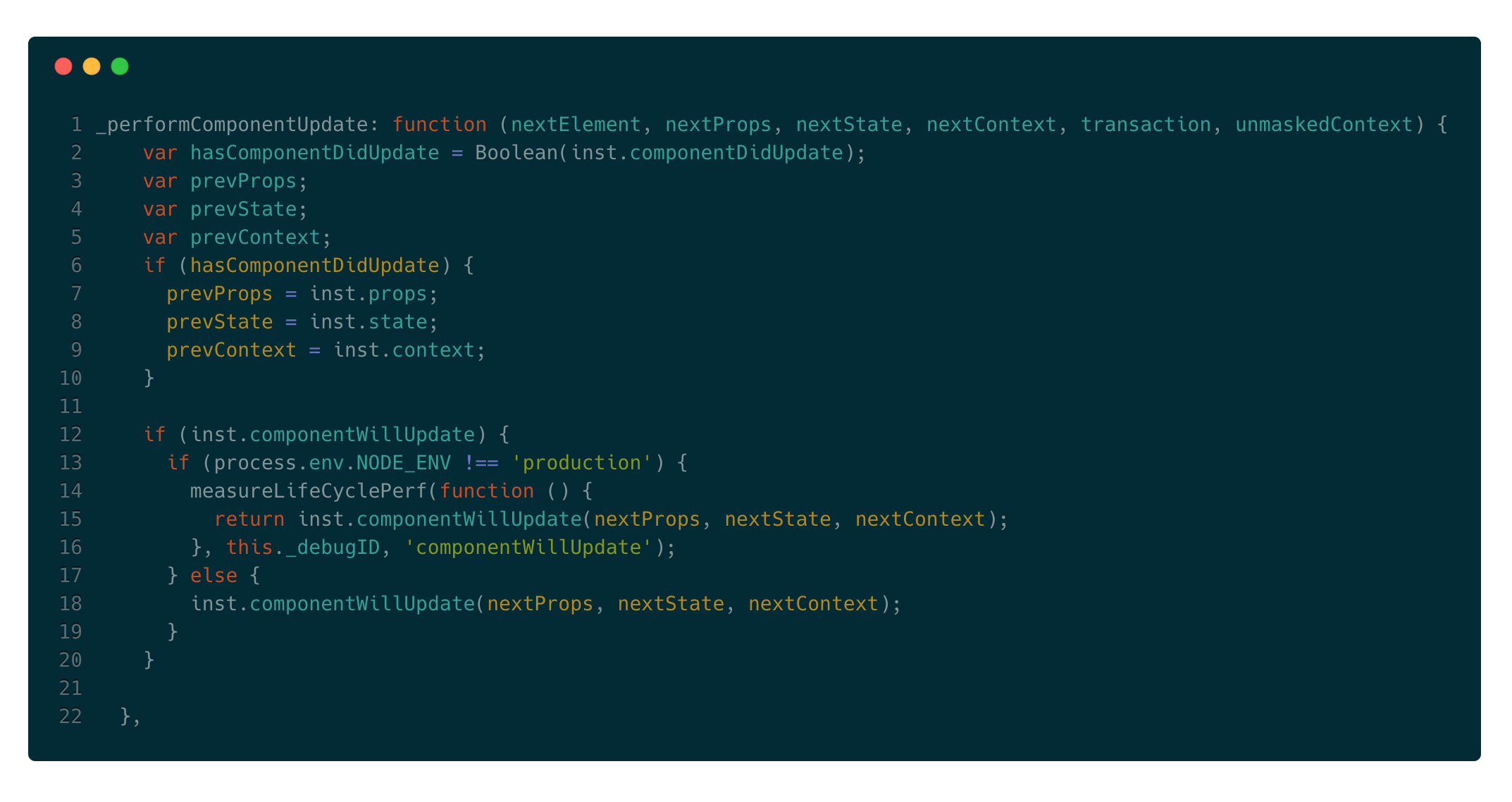
大致浏览下会发现还是同样的套路,执行componentWillUpdate生命周期方法,更新完成后执行componentDidUpdate方法。我们看下负责更新的_updateRenderedComponent方法:

这段代码的思路就很清晰了:
- 获取旧的组件信息
- 获取新的组件信息
shouldUpdateReactComponent是一个方法(下文简称should函数),根据传入的新旧组件信息判断是否进行更新。should函数返回true,执行旧组件的更新。should函数返回false,执行旧组件的卸载和新组件的挂载。
结合前面的流程图,我们对整个组件更新流程进行补充:
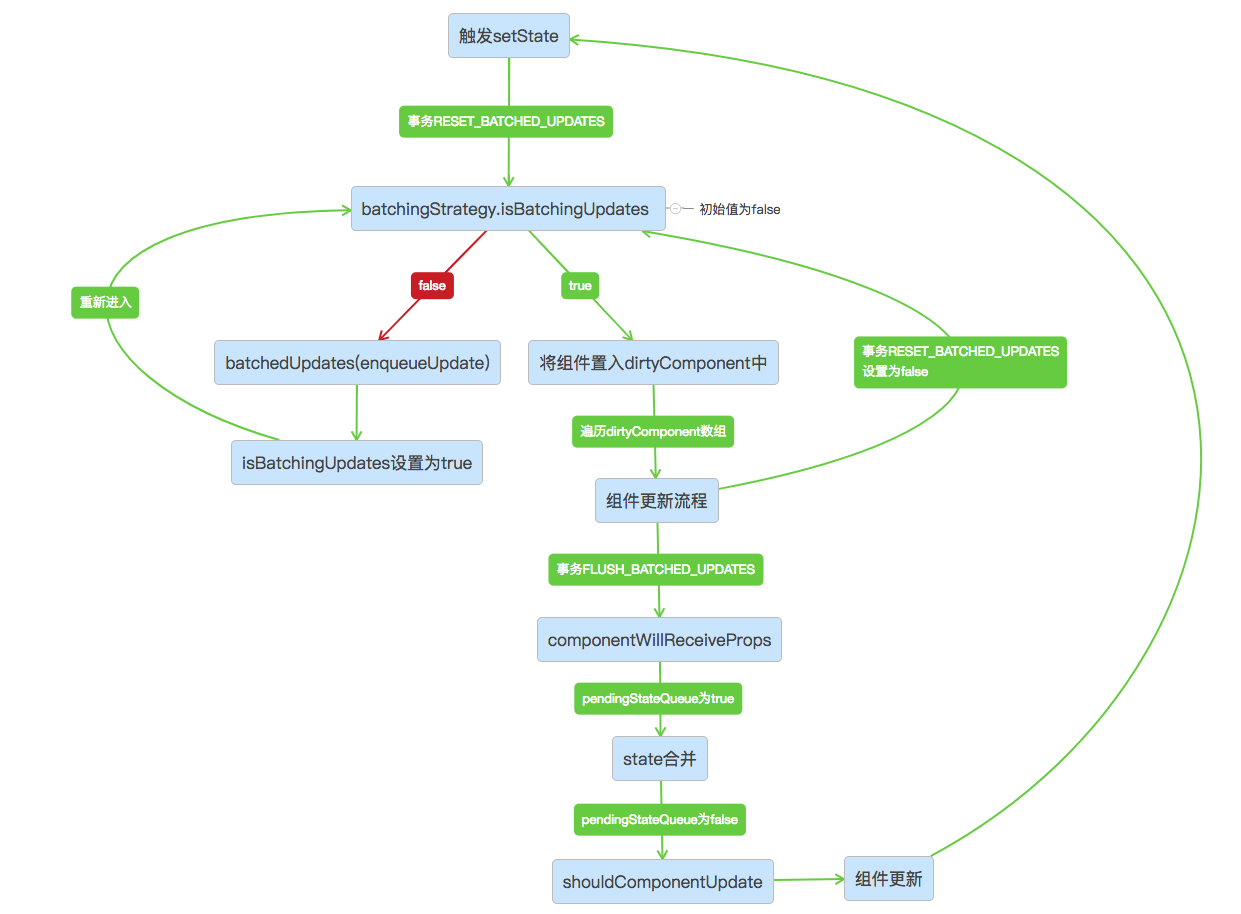
4.写在最后
(1)setState回调函数
setState回调函数与state的流程相似,state由enqueueSetState处理,回调函数由enqueueCallback处理,感兴趣的读者可以自行探究。
(2)关于setState导致的崩溃问题
我们已经知道,this.setState实际调用了enqueueSetState,在组件更新时,因为新的state还未进行合并处理,故在下面performUpdateIfNecessary代码中this._pendingStateQueue为true:
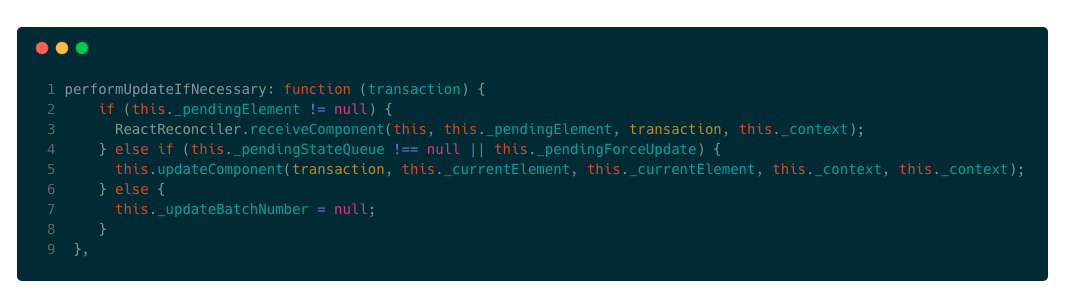
而合并state后React会会将this._pendingStateQueue设置为null,这样dirtyComponent进入下一次批量处理时,已经更新过的组件不会进入重复的流程,保证组件只做一次更新操作。
所以不能在componentWillUpdate中调用setState的原因,就是setState会令_pendingStateQueue为true,导致再次执行updateComponent,而后会再次调用componentWillUpdate,最终循环调用componentWillUpdate导致浏览器的崩溃。
(3)关于React依赖注入
我们在之前的代码中,对于更新队列的标志batchingStrategy,我们直接转向对ReactDefaultBatchingStrategy进行分析,这是因为React内部存在大量的依赖注入。在React初始化时,ReactDefaultInjection.js注入到ReactUpdates中作为默认的strategy。依赖注入在React的服务端渲染中有大量的应用,有兴趣的同学可以自行探索。
回顾:
《React源码解析(一):组件的实现与挂载》
《React源码解析(二):组件的生命周期》
《React源码解析(四):事件系统》
联系邮箱:ssssyoki@foxmail.com
