

关于作者
郭孝星,程序员,吉他手,主要从事Android平台基础架构方面的工作,欢迎交流技术方面的问题,可以去我的Github提issue或者发邮件至guoxiaoxingse@163.com与我交流。
文章目录
- 一 表的概念与应用场景
- 1.1 数组
- 1.2 链表
- 1.3 栈
- 1.4 队列
- 二 表的操作与源码实现
- 2.1 ArrayList实现原理
- 2.2 LinkedList实现原理
一 数据结构与应用场景
我们将形如A1,A2,A3,A4 ... AN称之为一个表,大小为0的表我们称之为空表。
常用的表如下:
- 数组
- 单向链表/双向链表
- 栈
- 队列/双端队列
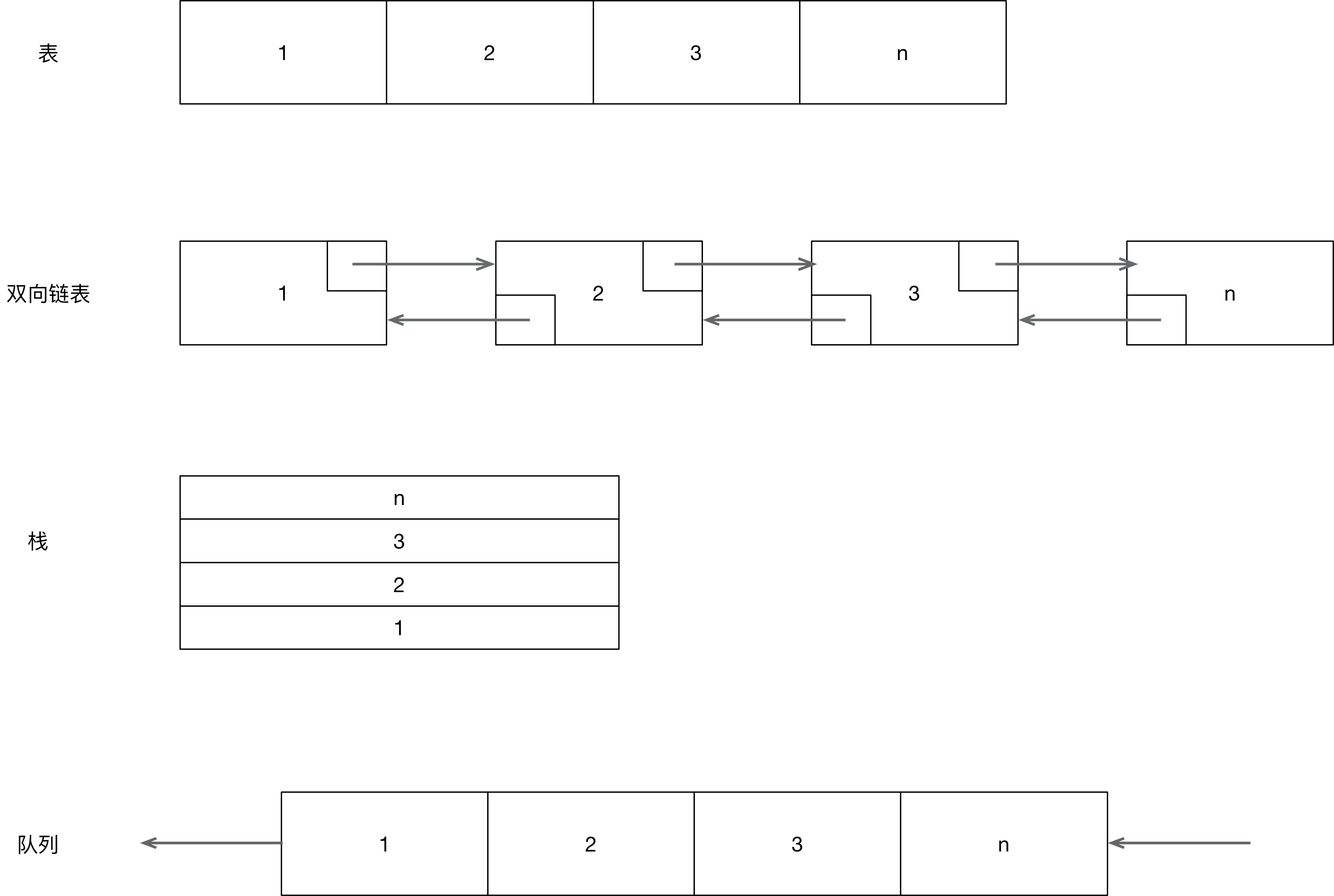
1.1 数组
数组是最为简单的一种表,它在查找操作是线性时间的,但是插入与删除则潜藏额外的开销。
- 如果插入的位置在第一个,则需要将后面的元素全部向后移动一位,时间复杂副为O(N)
- 如果插入的位置在最后一个,则无需移动其他元素,时间复杂副为O(1)
总结起来,插入/删除的时间时间复杂度为O(N)。
1.2 链表
链表由一系列节点组成,这些节点不必在内存中相连,每个节点均含有表元素和到包含该元素后继元的节点的链,称为next链。这样的链表
称为单链表,另外,如果节点还包含指向它在链表中的前驱节点的链,则成该链表为双链表。
链表是为了避免插入/删除带来的额外开销,我们又引入了链表,其中,链表又可以分为单链表与双链表。
1.3 栈
栈是限制插入和删除只能在表的末端进行的表,也就是出栈与入栈操作。
栈是为了在指定的位置就行插入和删除。
应用场景
平衡符号
在我们编写代码的时候,经常会遇写错了一个符号而报错,例如[()]是正确的,而[(])就是错误的。- 初始化一个空栈,读入字符到文件末尾。
- 如果字符是一个开放符号(例如:[),则入栈。
- 如果字符是一个封闭符号(例如:]),如果栈空则报错,否则将栈元素弹出,如果弹出的元素不是对应的开放符号,则报错。
- 在文件末尾,如果栈非空则报错。
方法调用
我们知道在Java中有个叫方法调用栈的东西,它会为每个执行的方法创建一个栈帧,用来存储局部变量表,操作数栈,动态链接和方法出口等信息。这种场景与上面提到
的平衡符号十分相似,因为方法的调用和放回和符号的开闭非常相似。
每次调用方法都会往栈里插入一个栈帧,方法返回是再将其出栈,如果我们将方法设计成递归调用,错误的结束条件或者过于庞大的数据量可能会引起栈溢出。
1.4 队列
队列也是一种表,使用队列时在一端进行插入而在另一端进行删除。
如同栈一样,对于队列而言任何表的实现都是合法的。
二 数据结构与源码实现
说完了关于表的基本概念,我们来聊一聊Java中对表的基本实现。Java中用接口List来定义表的基本功能,包括增、删、改、查等基本操作。
List接口定义如下:
注:链表、栈、队列都是表,因此对于实现了表方法的ArrayList/LinkedList都支持者三种数据结构。
public interface List<E> extends Collection<E> {
// Query Operations
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
// Modification Operations
boolean add(E e);
boolean remove(Object o);
// Bulk Modification Operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean addAll(int index, Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
// Comparison and hashing
boolean equals(Object o);
int hashCode();
// Positional Access Operations
E get(int index);
E set(int index, E element);
void add(int index, E element);
E remove(int index);
// Search Operations
int indexOf(Object o);
int lastIndexOf(Object o);
// List Iterators
ListIterator<E> listIterator();
ListIterator<E> listIterator(int index);
// View
List<E> subList(int fromIndex, int toIndex);
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.ORDERED);
}
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator();
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
default void sort(Comparator<? super E> c) {
Collections.sort(this, c);
}
}关于List接口,我们有两个常用的实现类。
- ArrayList:提供了一种List ADT的可增长的实现,优点在于get、set花费常量时间,缺点在于插入、删除代价昂贵。
- LinkedList:提供了一种List ADT的双链表的实现。优点在于插入、删除操作开销较小,缺点在于不用于做索引,get操作代价昂贵。
2.1 ArrayList实现原理
ArrayList提供了一种List ADT的可增长的实现,优点在于get、set花费常量时间,缺点在于插入、删除代价昂贵。
ArrayList是以数组为基础实现的线性数据结构,具体说来,它有以下特点:
- 快速查找,在物理内存上采用顺序存储结构,可以根据索引进行快速查找。
- 容量动态增长:当数组容量不够用时,创建一个比原来更大的数组,将原来数组的元素复制到新数组中。
- 可以插入null
- 没有做同步,非线程安全
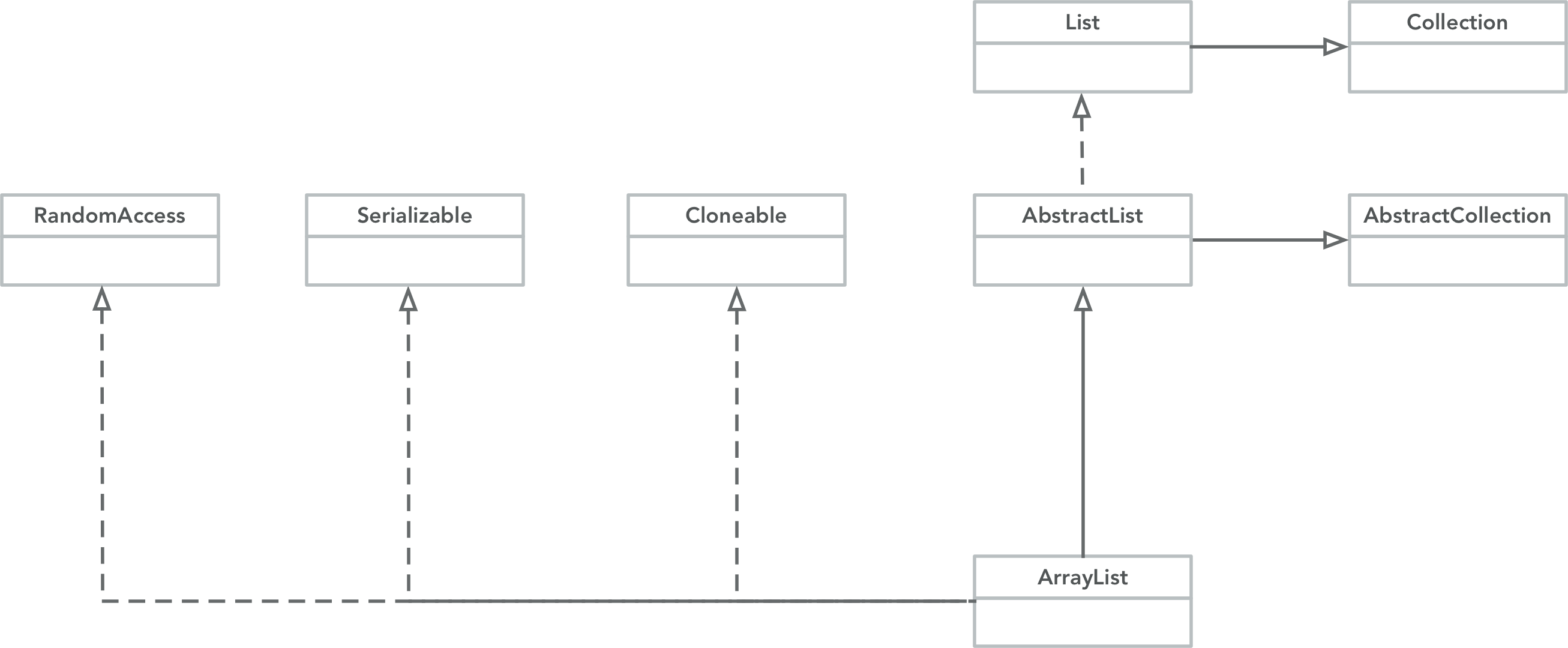
ArrayList类图如下所示:
实现了以下接口:
- List:List ADT相关方法。
- RandomAccess:随机访问功能,在ArrayList中通过索引快速获取元素,这就是随机访问功能。
- Cloneable:返回ArrayList的浅拷贝。
- Serialiable:实现了序列化功能。
ArrayList采用数组存取元素。
//保存ArrayList数据的数组,它采用transient关键字标记,说明序列化ArrayList忽略掉该字段
transient Object[] elementData;
//数据数量
private int size;我们接下来看看ArrayList关于增、删、改、查的实现。
add
时间复杂度:O(N)
实现原理:ArrayList可以在指定位置增加元素,增加元素后,当前元素后面的元素都要向后移动一位。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
ensureCapacityInternal(size + 1); // Increments modCount!!
//将数组elementData从index位置开始的所有元素,拷贝到elementData从index + 1位置开始的位置
//也就是index位置后面的元素全部向后移动一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
}ArrayList会调用ensureCapacityInternal()方法来保证数组容量的自动增长,我们先来看看它的实现。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//ArrayList内部数组的最大容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}可以看到ArrayList调用grow(int minCapacity)方法来增加容量,这里有个最小容量minCapacity,它等于当前数组大小size+1。该方法的
计算流程如下:
- 旧的容量 = 过去数组的大小
- 新的容量 = 过去容量 + 过去容量>>1
- 上一步计算的新容量如果小于最小容量则使用最小容量作为新的容量
- 如果上一步得到的容量大于最大数组容量,则使用最大数组容量作为新的容量
- 将原有数组的数据拷贝到新数组,并赋值给elementData。
这里我们还要提到一个数组拷贝的方法,它是一个native方法。
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);- Object src:源数组
- int srcPos:原数组开始拷贝的位置
- Object dest:目标数组
- int destPos:目标数组开始拷贝的位置
- int length:被拷贝元素的数量
remove
时间复杂度:O(N)
实现原理:删除指定位置的元素,删除元素后,把该元素后面的所有元素向前移动一位
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
public E remove(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
//当前删除index后面的元素全部向前移动一位
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
}ArrayList提供了两种移除元素的方法,按索引移除与按对象移除,按对象移除会先去遍历该对象的索引,然后再按索引移除。
set
时间复杂度:O(1)
实现原理:替换内部数组相应位置上的元素
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
public E set(int index, E element) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
E oldValue = (E) elementData[index];
elementData[index] = element;
return oldValue;
}
}get
时间复杂度:O(1)
实现原理:根据指定索引获取当前元素,无需额外的计算。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
public E get(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
return (E) elementData[index];
}
}2.1 LinkedList实现原理
LinkedList提供了一种List ADT的双链表的实现。优点在于插入、删除操作开销较小,缺点在于不用于做索引,get操作代价昂贵。
LinkedList基于双向链表实现的,它具有以特点:
- 基于双向链表实现,可以作为链表使用,也可以作为栈、队列和双端队列使用。
- 没有做同步,非线程安全
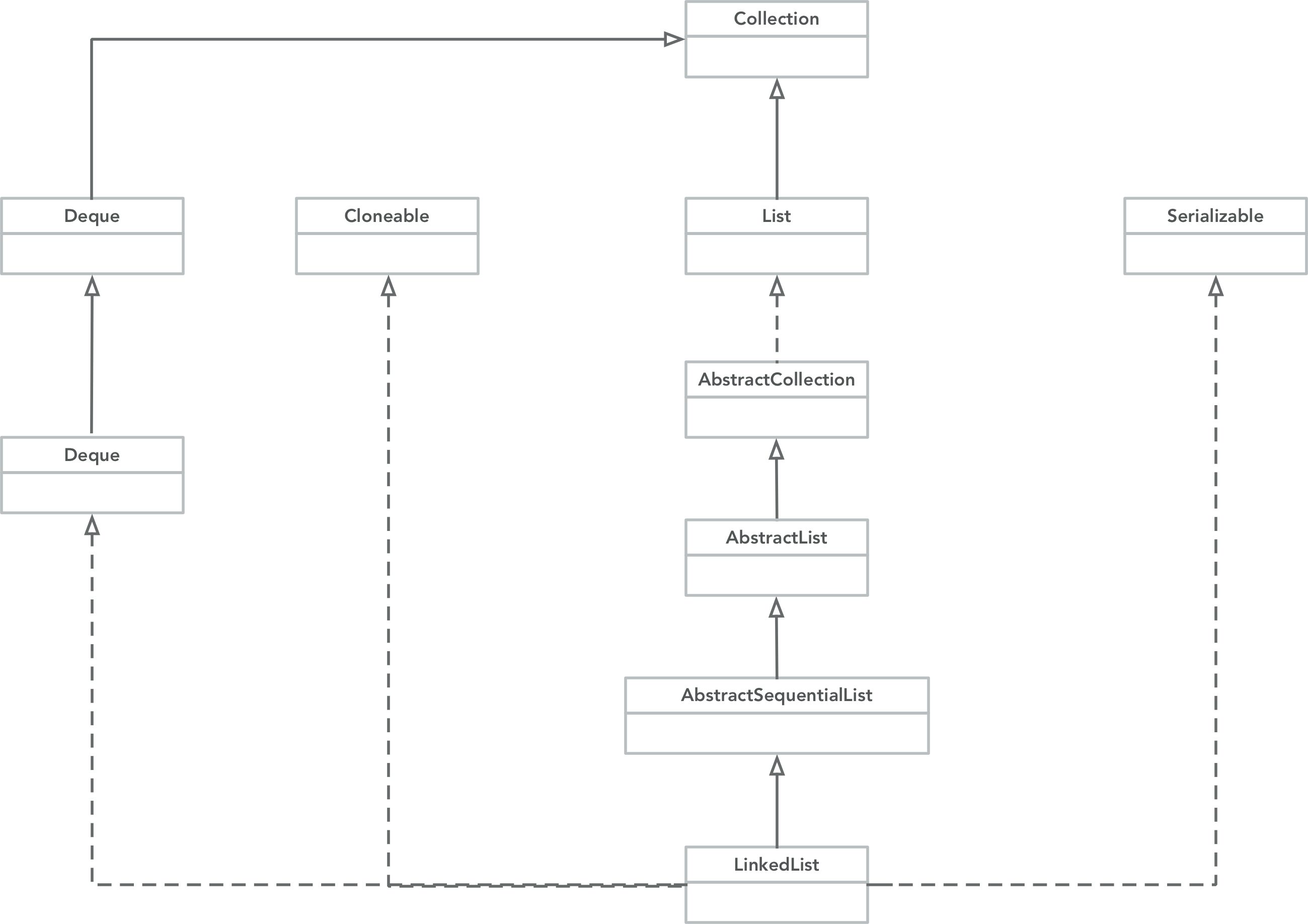
ArrayList类图如下所示:
实现了以下接口:
- List:List ADT相关方法。
- Deque:可以将LinkedList当做双端队列来使用。
- Cloneable:返回ArrayList的浅拷贝。
- Serialiable:实现了序列化功能。
LinkedList里用节点来描述里面的数据,如下所示:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}可以看到,每个节点包含了当前的元素以及它的前驱节点和后继节点。
LinkedList包含了三个成员变量:
//节点个数
transient int size = 0;
//第一个节点
transient Node<E> first;
//最后一个节点
transient Node<E> last;我们接下来看看ArrayList关于增、删、改、查的实现。
add
时间复杂度:add(E e) - O(1),add(int index, E element) - O(N)
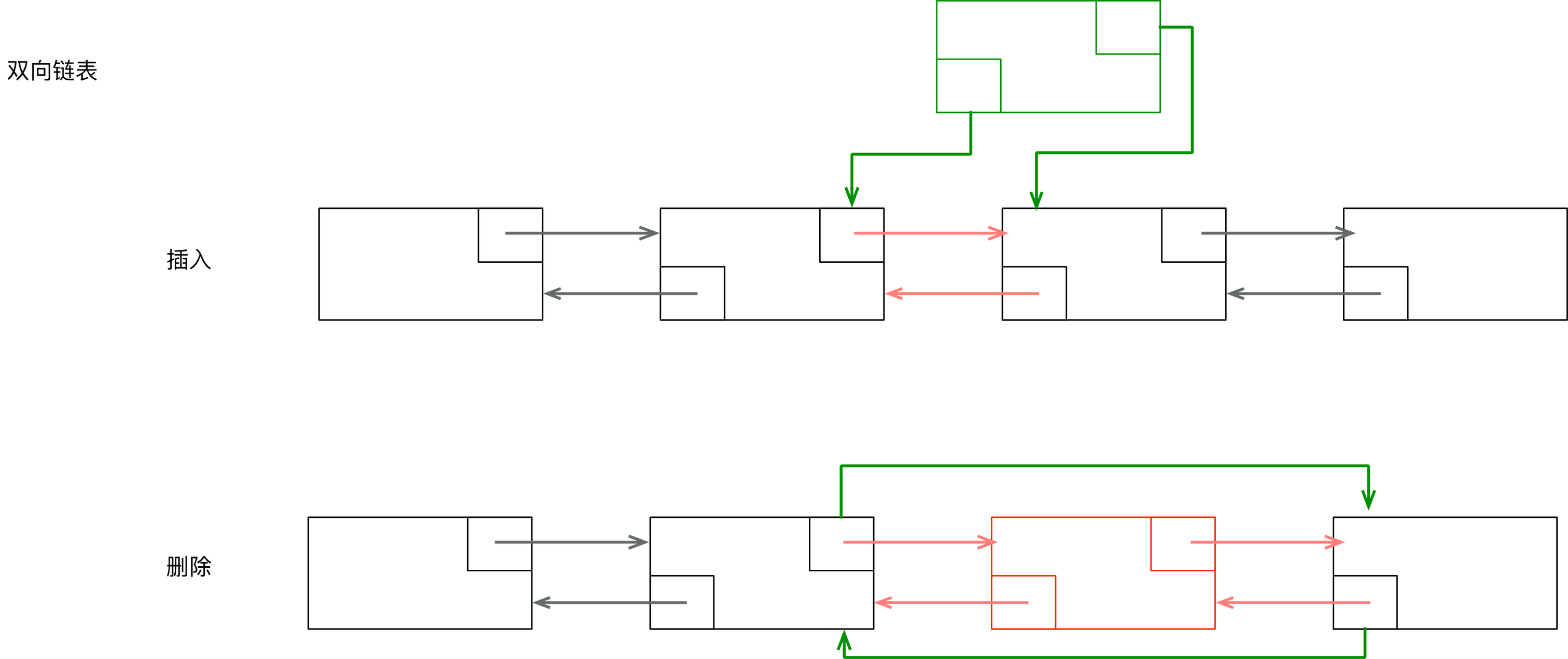
实现原理:增加和删除的过程都是一个针对指定节点进行前驱和后继关系修改的过程,如果是在起始节点和末尾节点插入、整个过程无需额外的遍历计算。
如果实在中间位置插入,则需要查找当前索引的节点。
原理图如下:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{
public boolean add(E e) {
linkLast(e);
return true;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
//查找指定索引的节点
Node<E> node(int index) {
//根据index的大小决定是从起始节点,还是从末尾节点开始查找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
private void linkFirst(E e) {
final Node<E> f = first;
//创建一个以起始节点last为后继的节点
final Node<E> newNode = new Node<>(null, e, f);
//将新创建的节点重新设置为起始节点
first = newNode;
//如果起始节点为空,则将新节点设置为末尾,如果不为空,则将起始节点的前驱指向新创建的节点
if (f == null)
last = newNode;
else
f.prev = newNode;
//大小加自增1,修改字数自增1
size++;
modCount++;
}
//末尾插入元素
void linkLast(E e) {
final Node<E> l = last;
//创建一个以末尾节点last为前驱的节点
final Node<E> newNode = new Node<>(l, e, null);
//将新创建的节点重新设置为末尾节点
last = newNode;
//如果末尾节点为空,则将新节点设置为起始节点,如果不为空,则将末尾节点的后继指向新创建的节点
if (l == null)
first = newNode;
else
l.next = newNode;
//大小加自增1,修改字数自增1
size++;
modCount++;
}
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
//以原来节点的前驱作为自己的前驱,以原来节点作为自己的后继,创建新的节点
final Node<E> newNode = new Node<>(pred, e, succ);
//将新的节点作为原来节点的前驱
succ.prev = newNode;
//如果原来节点的前驱为空,即它原来是起始节点,则直接将新创建的节点作为新的起始节点,如果不为空,则将
//原来节点的前驱的后继设置为当前创建的新节点
if (pred == null)
first = newNode;
else
pred.next = newNode;
//大小加自增1,修改字数自增1
size++;
modCount++;
}
}我们可以在指定位置插入元素,如果没有指定位置,默认在链表末尾插入元素。可以看到add方法的实现是依赖于link方法来建立前驱与后继的联系。
具体说来:
linkFirst
- 创建一个以起始节点last为后继的节点
- 将新创建的节点重新设置为起始节点
- 如果起始节点为空,则将新节点设置为末尾,如果不为空,则将起始节点的前驱指向新创建的节点
- 大小加自增1,修改字数自增1
linkBefore
- 以原来节点的前驱作为自己的前驱,以原来节点作为自己的后继,创建新的节点
- 将新的节点作为原来节点的前驱
- 如果原来节点的前驱为空,即它原来是起始节点,则直接将新创建的节点作为新的起始节点,如果不为空,则将原来节点的前驱的后继设置为当前创建的新节点
- 大小加自增1,修改字数自增1
remove
时间复杂度:O(1)
实现原理:增加和删除的过程都是一个针对指定节点进行前驱和后继关系修改的过程,整个过程无需额外的遍历计算。
原理图如下:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{
public E remove() {
return removeFirst();
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
E unlink(Node<E> x) {
//找出要删除节点的前驱与后继
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//如果前驱为空,则将要删除节点的后继设置为起始节点,否则将删除节点的前驱的后继指向删除节点的后继
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
//如果后继为空,则直接将删除节点的前驱作为末尾节点,否则将删除节点的后继的前驱指向删除节点的前驱
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
//删除元素置空,大小加自增1,修改字数自增1
x.item = null;
size--;
modCount++;
return element;
}
}可以看出,删除的过程就是一个接触前驱和后继的过程。主要的有unlink方法来实现,具体说来:
unlink
- 找出要删除节点的前驱与后继
- 如果前驱为空,则将要删除节点的后继设置为起始节点,否则将删除节点的前驱的后继指向删除节点的后继
- 如果后继为空,则直接将删除节点的前驱作为末尾节点,否则将删除节点的后继的前驱指向删除节点的前驱
- 删除元素置空,大小加自增1,修改字数自增1
这么描述有点绕,就是删除原来的前驱后继关系,重新建立连接。
set
时间复杂度:O(N)
实现原理:查找指定index对应节点,替换掉节点里的元素,set操作也有个查找过程。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
//查找指定索引的节点
Node<E> node(int index) {
//根据index的大小决定是从起始节点,还是从末尾节点开始查找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
}get
时间复杂度:O(N)
实现原理:根据index的位置决定是从起始节点开始查找,还是从末尾节点开始查找。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//查找指定索引的节点
Node<E> node(int index) {
//根据index的大小决定是从起始节点,还是从末尾节点开始查找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
}关于表、栈与队列的内容我们就讲到这里,后续有新的内容还会在这篇文章更新。
