

- 原文地址:You don’t know Node
- 原文作者:Samer Buna
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:lampui
- 校对者:smile、Yuuoniy
在今年的 Forward.js 大会(一个 JavaScript 峰会),我进行了一场主题为“你不知道的 Node” 的演讲,在那场演讲中,我问了现场观众一系列关于 Node.js 运行时的问题,然而大部分搞技术的听众都不能全部回答得上。
我当时并没有真的计算过,直到演讲完了才有一些勇敢的人过来跟我坦白说他们不会。
这个问题正是让我发表演讲的原因,我并不认为我们教授 Node 的方式是对的。大多数关于 Nodejs 的教材内容主要集中在 Node 包和 Node 运行时之外的地方,大多数这些包都在 Node 运行时封装好了模块(例如 http 或 stream),问题可能是藏在运行时里面,然而你不懂 Node 运行时的话,你就麻烦了。
问题:大多数关于 Nodejs 的教材内容主要集中在 Node 包和 Node 运行时之外的地方。
我挑选了几个问题并组织了一些答案来写成这篇文章,答案就在问题的下面,建议尝试先自己回答。
如果你发现了错误或误导性的回答,请跟我联系。
问题 #1:什么是调用栈?它是 V8 的一部分吗?
调用栈百分之百就是 V8 的一部分,它是 V8 用来追踪方法调用的数据结构。每一次我们调用一个方法,V8 在调用栈中放置一个该方法的引用,并且 V8 对每个其他方法的嵌套调用也这样操作,同时也包括那些自身递归调用的方法。

当方法的嵌套调用结束时,V8 会逐个地将方法从栈中 pop 出来,并在它的位置使用方法的返回值。
为什么这对于理解 Node 是如此关键?因为在每个 Node 进程中你只有一个调用栈。如果你令调用栈处于忙碌,你整个的 Node 进程也将变得忙碌。牢记这一点!
问题 #2:什么是事件循环?它是 V8 的一部分吗?
你觉得事件循环在这张图的哪个部分?
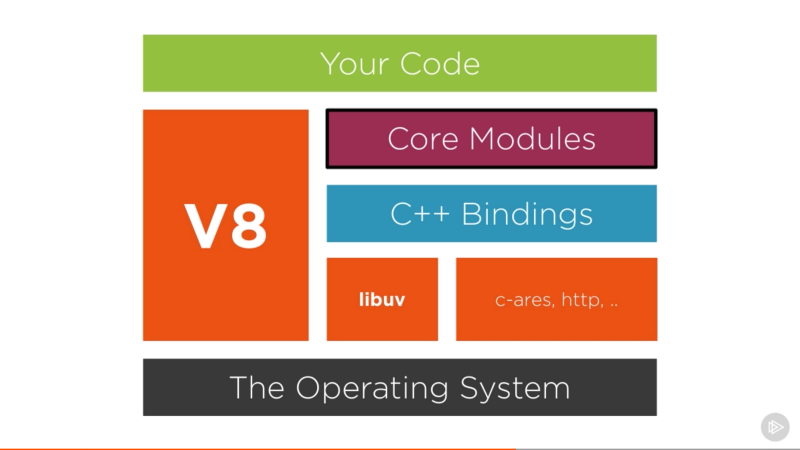
答案是 libuv 。事件循环不是 V8 的一部分!
事件循环是操控外部事件并将它们转换为回调调用的实体,它是从事件队列中取出事件并将事件的回调函数推进调用栈的一个循环。并且该循环过程中分为多个独立的阶段。
如果这是你第一次听说事件循环,这些概念对你可能帮助不大。事件循环是一副很大的轮廓图的其中一部分:
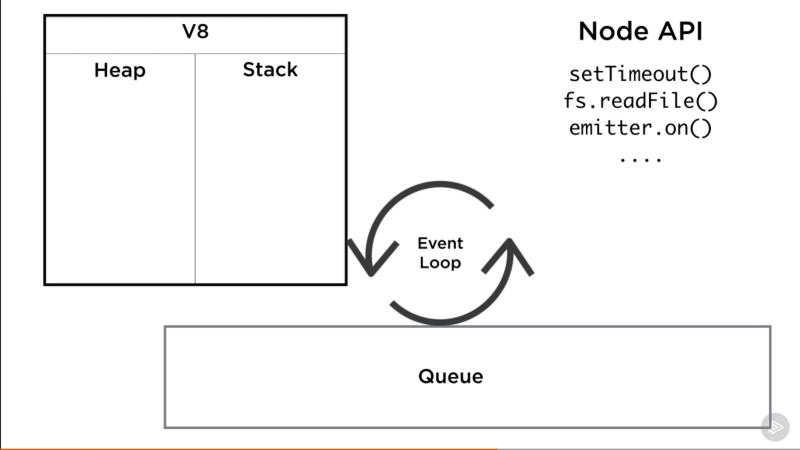
你需要先理解这幅轮廓图再理解事件循环,你需要先理解 V8 在这里面饰演的角色、理解 Node APIs 并知道事件是怎样进入队列并被 V8 处理的。
Node APIs 是像 setTimeout 或 fs.readFile的一些方法,它们不是 JavaScript 本身的一部分,它们就是 Node 提供的方法。
事件循环在这张图片的中间(一个更复杂的版本,真的)饰演一个组织者的角色。当 V8 调用栈为空的时候,事件循环可以决定接下来执行什么。
问题 #3:当调用栈和事件循环队列都为空时,Node 会做什么?
Node 会直接退出。
当你执行一个 Node 程序时,Node 会自动地开始事件循环,当没有事件处理时并且没有其他任务时,Node 则会退出进程。
为了保持一个 Node 进程持续运行,你需要把一些任务放入事件队列中。例如,当你创建一个计时器或一个 HTTP 服务器时,你基本上就是在告诉事件循环要保持并检测这些任务持续执行。
问题 #4:除了 V8 和 Libuv,Node 还有哪些外部依赖?
以下是一个 Node 进程可以使用的所有外部的库:
- http-parser
- c-ares
- OpenSSL
- zlib
对 Node 本身来说,上面这些库都是外部的,这些库都有自己的源代码、许可证,Node 只是使用它们而已。
你想记住它们是因为你想知道你的程序执行到哪里了,如果你在做一些数据压缩的工作,有可能是在 zlib 这个库遇到问题,Node 是无辜的。
问题 #5:不用 V8 有可能运行一个 Node 进程吗?
这可能是一个奇技淫巧的问题。你肯定是需要一个虚拟机去执行 Node 进程,但 V8 并不是唯一的虚拟机,你还可以使用 Chakra。
查看这个 Github 仓库来跟踪 node-chakra 项目的进度:
问题 #6:module.exports 和 exports 两者的区别?
你可以使用 module.exports 导出模块的 API,你也可以使用 exports,但有个值得注意的地方:
module.exports.g = ... // Ok
exports.g = ... // Ok
module.exports = ... // Ok
exports = ... // Not Ok为什么?
exports 只是一个对 module.exports 的引用或别名,当你修改 exports 时你其实是在无意中试图修改 module.exports,但修改对官方 API (即 module.exports)不会产生影响,你只是在模块作用域中得到一个局部变量。
问题 #7:为什么顶层变量不是全局变量?
如果你在 module1 定义了一个顶层变量 g:
// module1.js
var g = 42;而你在 module2 依赖 module1并试图访问这个变量 g,你会得到错误 g is not defined。
为什么? 如果你在浏览器执行相同的操作,你可以在所有脚本中访问顶层定义的变量。
每个 Node 文件在背后都有自己的 IIFE(立即调用函数表达式),所有在一个 Node 文件中声明的变量都被限制在这个 IIFE 的作用域中。
相关问题: 在一个 Node 文件中只有下面这一行代码,执行它会输出什么:
// script.js</pre>
console.log(arguments);你会看到一些参数!
为什么?
因为 Node 执行的是一个函数。Node 将你的代码包裹在一个函数中,这个函数明确地定义了你上面看到的那 5 个参数。
问题 #8:exports、require、和 module三个对象在每个文件中都是全局可用的,但他们在每个文件中又有区别,为什么呢?
当你需要使用 require 对象时,你只是像使用全局变量那样直接使用它,然而,如果你在 2 个不同的文件中比较 require 对象的区别,你会发现 2 个不同的对象,怎么回事?
还是因为一样的原因 IIFE(立即调用函数表达式):
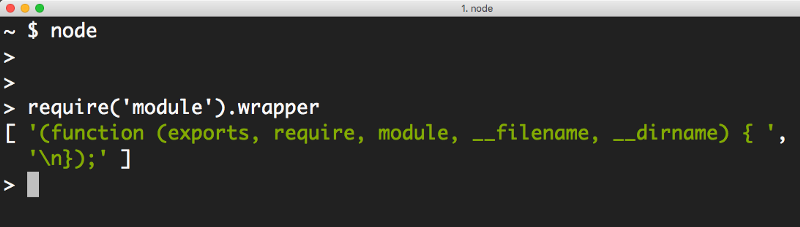
正如你所见,IIFF 将以下 5 个参数传递到你的代码中:exports, require, module, __filename, and __dirname。
当你在 Node 中使用这 5 个变量的时候似乎是在使用全局变量,但它们只是函数参数。
问题 #9: Node 中的循环依赖是什么?
如果你有一个 module1 依赖于 module2,而 module2 又反过来依赖于 module1,这将发生什么?一个错误?
// module1
require('./module2');
// module2
require('./module1');放心,不会报错,Node 允许这样做。
所以,module1 依赖于 module2,但因为 module2 又依赖于 module1,然而 module1 此时还没就绪,module1 只会得到 module2 的不完整版本。
系统已经发出警告了。
问题 #10:什么时候适合使用文件系统的同步方法(像 readFileSync)?
每个 Node 中的 fs 方法都有一个同步版本,为什么你要使用一个同步方法而不是一个异步方法?
有时使用同步方法挺好的,举个例子,可以在服务器还在一直加载的时候,将同步方法用到任何初始化工作中。通常情况下,在初始化工作完成之后,你接下来的工作是根据获得的数据继续进行作业而不是引入回调级别。使用同步方法是可以接受的,只要你使用的同步方法是一次性的。
然而,如果你在一个像是 HTTP 服务器的 on-request 回调函数里使用同步方法,那就真的是 100% 错误!别那样做。
我希望你能答上一部分或者所有的问题,以下是我写得比较深入 Node.js 细节的文章:
- Before you bury yourself in packages, learn the Node.js runtime itself
- Requiring modules in Node.js: Everything you need to know
- Understanding Node.js Event-Driven Architecture
- Node.js Streams: Everything you need to know
- Node.js Child Processes: Everything you need to know
- Scaling Node.js Applications
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、React、前端、后端、产品、设计 等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
