

本系列文章为《Node.js Design Patterns Second Edition》的原文翻译和读书笔记,在GitHub连载更新,同步翻译版链接。
欢迎关注我的专栏,之后的博文将在专栏同步:
Welcom to the Node.js Platform
Node.js 的发展
- 技术本身的发展
- 庞大的
Node.js生态圈的发展 - 官方组织的维护
Node.js的特点
小模块
以package的形式尽可能多的复用模块,原则上每个模块的容量尽量小而精。
原则:
- "Small is beautiful" ---小而精
- "Make each program do one thing well" ---单一职责原则
因此,一个Node.js应用由多个包搭建而成,包管理器(npm)的管理使得他们相互依赖而不起冲突。
如果设计一个Node.js的模块,尽可能做到以下三点:
- 易于理解和使用
- 易于测试和维护
- 考虑到对客户端(浏览器)的支持更友好
以及,Don't Repeat Yourself(DRY)复用性原则。
以接口形式提供
每个Node.js模块都是一个函数(类也是以构造函数的形式呈现),我们只需要调用相关API即可,而不需要知道其它模块的实现。Node.js模块是为了使用它们而创建,不仅仅是在拓展性上,更要考虑到维护性和可用性。
简单且实用
“简单就是终极的复杂” ————达尔文
遵循KISS(Keep It Simple, Stupid)原则,即优秀的简洁的设计,能够更有效地传递信息。
设计必须很简单,无论在实现还是接口上,更重要的是实现比接口更简单,简单是重要的设计原则。
我们做一个设计简单,功能完备,而不是完美的软件:
- 实现起来需要更少的努力
- 允许用更少的速度进行更快的运输资源
- 具有伸缩性,更易于维护和理解
- 促进社区贡献,允许软件本身的成长和改进
而对于Node.js而言,因为其支持JavaScript,简单和函数、闭包、对象等特性,可取代复杂的面向对象的类语法。如单例模式和装饰者模式,它们在面向对象的语言都需要很复杂的实现,而对于JavaScript则较为简单。
介绍Node.js 6 和 ES2015的新语法
let和const关键字
ES5之前,只有函数和全局作用域。
if (false) {
var x = "hello";
}
console.log(x); // undefined现在用let,创建词法作用域,则会报出一个错误Uncaught ReferenceError: x is not defined
if (false) {
let x = "hello";
}
console.log(x);在循环语句中使用let,也会报错Uncaught ReferenceError: i is not defined:
for (let i = 0; i < 10; i++) {
// do something here
}
console.log(i);使用let和const关键字,可以让代码更安全,如果意外的访问另一个作用域的变量,更容易发现错误。
使用const关键字声明变量,变量不会被意外更改。
const x = 'This will never change';
x = '...';这里会报出一个错误Uncaught TypeError: Assignment to constant variable.
但是对于对象属性的更改,const显得毫无办法:
const x = {};
x.name = 'John';上述代码并不会报错
但是如果直接更改对象,还是会抛出一个错误。
const x = {};
x = null;实际运用中,我们使用const引入模块,防止意外被更改:
const path = require('path');
let path = './some/path';上述代码会报错,提醒我们意外更改了模块。
如果需要创建不可变对象,只是简单的使用const是不够的,需要使用Object.freeze()或deep-freeze
我看了一下源码,其实很少,就是递归使用Object.freeze()
module.exports = function deepFreeze (o) {
Object.freeze(o);
Object.getOwnPropertyNames(o).forEach(function (prop) {
if (o.hasOwnProperty(prop)
&& o[prop] !== null
&& (typeof o[prop] === "object" || typeof o[prop] === "function")
&& !Object.isFrozen(o[prop])) {
deepFreeze(o[prop]);
}
});
return o;
};箭头函数
箭头函数更易于理解,特别是在我们定义回调的时候:
const numbers = [2, 6, 7, 8, 1];
const even = numbers.filter(function(x) {
return x % 2 === 0;
});使用箭头函数语法,更简洁:
const numbers = [2, 6, 7, 8, 1];
const even = numbers.filter(x => x % 2 === 0);如果不止一个return语句则使用=> {}
const numbers = [2, 6, 7, 8, 1];
const even = numbers.filter((x) => {
if (x % 2 === 0) {
console.log(x + ' is even');
return true;
}
});最重要是,箭头函数绑定了它的词法作用域,其this与父级代码块的this相同。
function DelayedGreeter(name) {
this.name = name;
}
DelayedGreeter.prototype.greet = function() {
setTimeout(function cb() {
console.log('Hello' + this.name);
}, 500);
}
const greeter = new DelayedGreeter('World');
greeter.greet(); // 'Hello'要解决这个问题,使用箭头函数或bind
function DelayedGreeter(name) {
this.name = name;
}
DelayedGreeter.prototype.greet = function() {
setTimeout(function cb() {
console.log('Hello' + this.name);
}.bind(this), 500);
}
const greeter = new DelayedGreeter('World');
greeter.greet(); // 'HelloWorld'或者箭头函数,与父级代码块作用域相同:
function DelayedGreeter(name) {
this.name = name;
}
DelayedGreeter.prototype.greet = function() {
setTimeout(() => console.log('Hello' + this.name), 500);
}
const greeter = new DelayedGreeter('World');
greeter.greet(); // 'HelloWorld'类语法糖
class是原型继承的语法糖,对于来自传统的面向对象语言的所有开发人员(如Java和C#)来说更熟悉,新语法并没有改变JavaScript的运行特征,通过原型来完成更加方便和易读。
传统的通过构造器 + 原型的写法:
function Person(name, surname, age) {
this.name = name;
this.surname = surname;
this.age = age;
}
Person.prototype.getFullName = function() {
return this.name + '' + this.surname;
}
Person.older = function(person1, person2) {
return (person1.age >= person2.age) ? person1 : person2;
}使用class语法显得更加简洁、方便、易懂:
class Person {
constructor(name, surname, age) {
this.name = name;
this.surname = surname;
this.age = age;
}
getFullName() {
return this.name + '' + this.surname;
}
static older(person1, person2) {
return (person1.age >= person2.age) ? person1 : person2;
}
}但是上面的实现是可以互换的,但是,对于class语法来说,最有意义的是extends和super关键字。
class PersonWithMiddlename extends Person {
constructor(name, middlename, surname, age) {
super(name, surname, age);
this.middlename = middlename;
}
getFullName() {
return this.name + '' + this.middlename + '' + this.surname;
}
}这个例子是真正的面向对象的方式,我们声明了一个希望被继承的类,定义新的构造器,并可以使用super关键字调用父构造器,并重写getFullName方法,使得其支持middlename。
对象字面量的新语法
允许缺省值:
const x = 22;
const y = 17;
const obj = { x, y };允许省略方法名
module.exports = {
square(x) {
return x * x;
},
cube(x) {
return x * x * x;
},
};key的计算属性
const namespace = '-webkit-';
const style = {
[namespace + 'box-sizing']: 'border-box',
[namespace + 'box-shadow']: '10px 10px 5px #888',
};新的定义getter和setter方式
const person = {
name: 'George',
surname: 'Boole',
get fullname() {
return this.name + ' ' + this.surname;
},
set fullname(fullname) {
let parts = fullname.split(' ');
this.name = parts[0];
this.surname = parts[1];
}
};
console.log(person.fullname); // "George Boole"
console.log(person.fullname = 'Alan Turing'); // "Alan Turing"
console.log(person.name); // "Alan"这里,第二个console.log触发了set方法。
模板字符串
其它ES2015语法
reactor模式
reactor模式是Node.js异步编程的核心模块,其核心概念是:单线程、非阻塞I/O,通过下列例子可以看到reactor模式在Node.js平台的体现。
I/O是缓慢的
在计算机的基本操作中,输入输出肯定是最慢的。访问内存的速度是纳秒级(10e-9 s),同时访问磁盘上的数据或访问网络上的数据则更慢,是毫秒级(10e-3 s)。内存的传输速度一般认为是GB/s来计算,然而磁盘或网络的访问速度则比较慢,一般是MB/s。虽然对于CPU而言,I/O操作的资源消耗并不算大,但是在发送I/O请求和操作完成之间总会存在时间延迟。除此之外,我们还必须考虑人为因素,通常情况下,应用程序的输入是人为产生的,例如:按钮的点击、即时聊天工具的信息发送。因此,输入输出的速度并不因网络和磁盘访问速率慢造成的,还有多方面的因素。
阻塞I/O
在一个阻塞I/O模型的进程中,I/O请求会阻塞之后代码块的运行。在I/O请求操作完成之前,线程会有一段不定长的时间浪费。(它可能是毫秒级的,但甚至有可能是分钟级的,如用户按着一个按键不放的情况)。以下例子就是一个阻塞I/O模型。
// 直到请求完成,数据可用,线程都是阻塞的
data = socket.read();
// 请求完成,数据可用
print(data);我们知道,阻塞I/O的服务器模型并不能在一个线程中处理多个连接,每次I/O都会阻塞其它连接的处理。出于这个原因,对于每个需要处理的并发连接,传统的web服务器的处理方式是新开一个新的进程或线程(或者从线程池中重用一个进程)。这样,当一个线程因 I/O操作被阻塞时,它并不会影响另一个线程的可用性,因为他们是在彼此独立的线程中处理的。
通过下面这张图:
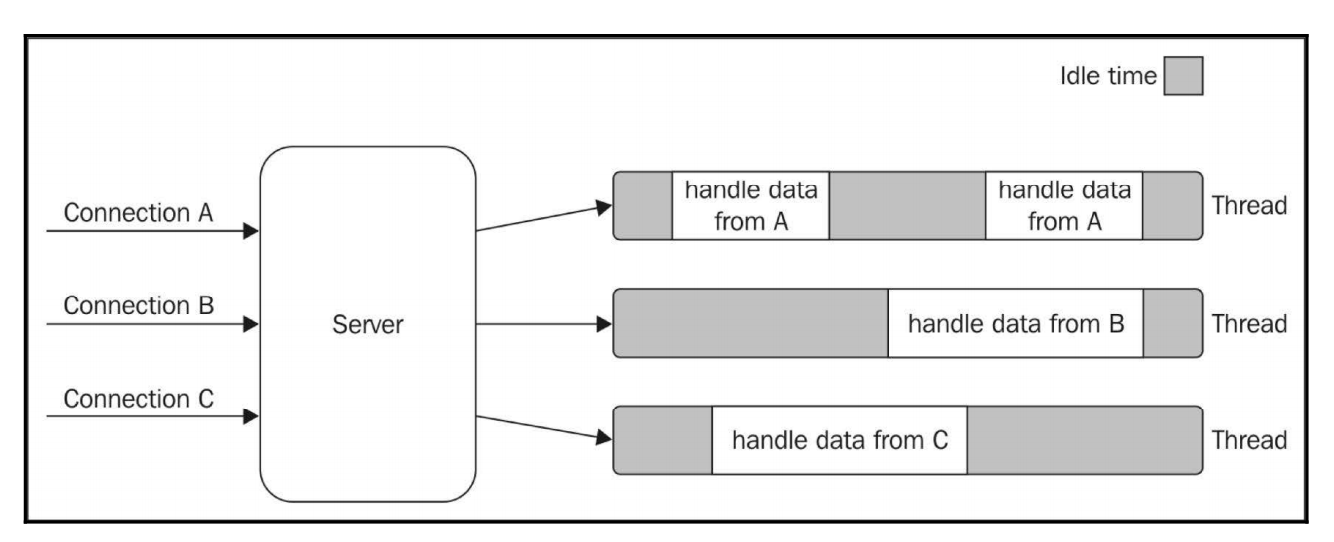
通过上面的图片我们可以看到每个线程都有一段时间处于空闲等待状态,等待从关联连接接收新数据。如果所有种类的I/O操作都会阻塞后续请求。例如,连接数据库和访问文件系统,现在我们能很快知晓一个线程需要因等待I/O操作的结果等待许多时间。不幸的是,一个线程所持有的CPU资源并不廉价,它需要消耗内存、造成CPU上下文切换,因此,长期占有CPU而大部分时间并没有使用的线程,在资源利用率上考虑,并不是高效的选择。
非阻塞I/O
除阻塞I/O之外,大部分现代的操作系统支持另外一种访问资源的机制,即非阻塞I/O。在这种机制下,后续代码块不会等到I/O请求数据的返回之后再执行。如果当前时刻所有数据都不可用,函数会先返回预先定义的常量值(如undefined),表明当前时刻暂无数据可用。
例如,在Unix操作系统中,fcntl()函数操作一个已存在的文件描述符,改变其操作模式为非阻塞I/O(通过O_NONBLOCK状态字)。一旦资源是非阻塞模式,如果读取文件操作没有可读取的数据,或者如果写文件操作被阻塞,读操作或写操作返回-1和EAGAIN错误。
非阻塞I/O最基本的模式是通过轮询获取数据,这也叫做忙-等模型。看下面这个例子,通过非阻塞I/O和轮询机制获取I/O的结果。
resources = [socketA, socketB, pipeA];
while(!resources.isEmpty()) {
for (i = 0; i < resources.length; i++) {
resource = resources[i];
// 进行读操作
let data = resource.read();
if (data === NO_DATA_AVAILABLE) {
// 此时还没有数据
continue;
}
if (data === RESOURCE_CLOSED) {
// 资源被释放,从队列中移除该链接
resources.remove(i);
} else {
consumeData(data);
}
}
}我们可以看到,通过这个简单的技术,已经可以在一个线程中处理不同的资源了,但依然不是高效的。事实上,在前面的例子中,用于迭代资源的循环只会消耗宝贵的CPU,而这些资源的浪费比起阻塞I/O反而更不可接受,轮询算法通常浪费大量CPU时间。
事件多路复用
对于获取非阻塞的资源而言,忙-等模型不是一个理想的技术。但是幸运的是,大多数现代的操作系统提供了一个原生的机制来处理并发,非阻塞资源(同步事件多路复用器)是一个有效的方法。这种机制被称作事件循环机制,这种事件收集和I/O队列源于发布-订阅模式。事件多路复用器收集资源的I/O事件并且把这些事件放入队列中,直到事件被处理时都是阻塞状态。看下面这个伪代码:
socketA, pipeB;
wachedList.add(socketA, FOR_READ);
wachedList.add(pipeB, FOR_READ);
while(events = demultiplexer.watch(wachedList)) {
// 事件循环
foreach(event in events) {
// 这里并不会阻塞,并且总会有返回值(不管是不是确切的值)
data = event.resource.read();
if (data === RESOURCE_CLOSED) {
// 资源已经被释放,从观察者队列移除
demultiplexer.unwatch(event.resource);
} else {
// 成功拿到资源,放入缓冲池
consumeData(data);
}
}
}事件多路复用的三个步骤:
- 资源被添加到一个数据结构中,为每个资源关联一个特定的操作,在这个例子中是
read。 - 事件通知器由一组被观察的资源组成,一旦事件即将触发,会调用同步的
watch函数,并返回这个可被处理的事件。 - 最后,处理事件多路复用器返回的每个事件,此时,与系统资源相关联的事件将被读并且在整个操作中都是非阻塞的。直到所有事件都被处理完时,事件多路复用器会再次阻塞,然后重复这个步骤,以上就是
event loop。

上图可以很好的帮助我们理解在一个单线程的应用程序中使用同步的时间多路复用器和非阻塞I/O实现并发。我们能够看到,只使用一个线程并不会影响我们处理多个I/O任务的性能。同时,我们看到任务是在单个线程中随着时间的推移而展开的,而不是分散在多个线程中。我们看到,在单线程中传播的任务相对于多线程中传播的任务反而节约了线程的总体空闲时间,并且更利于程序员编写代码。在这本书中,你可以看到我们可以用更简单的并发策略,因为不需要考虑多线程的互斥和同步问题。
在下一章中,我们有更多机会讨论Node.js的并发模型。
介绍reactor模式
现在来说reactor模式,它通过一种特殊的算法设计的处理程序(在Node.js中是使用一个回调函数表示),一旦事件产生并在事件循环中被处理,那么相关handler将会被调用。
它的结构如图所示:
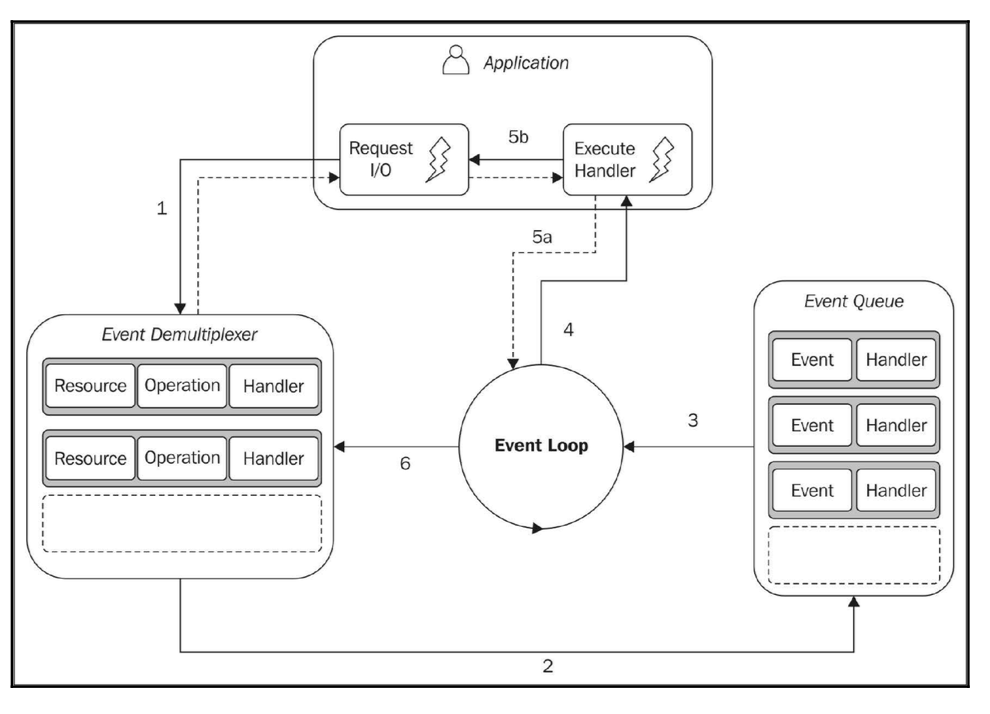
reactor模式的步骤为:
- 应用程序通过提交请求到时间多路复用器产生一个新的
I/O操作。应用程序指定handler,handler在操作完成后被调用。提交请求到事件多路复用器是非阻塞的,其调用所以会立马返回,将执行权返回给应用程序。 - 当一组
I/O操作完成,事件多路复用器会将这些新事件添加到事件循环队列中。 - 此时,事件循环会迭代事件循环队列中的每个事件。
- 对于每个事件,对应的
handler被处理。 handler,是应用程序代码的一部分,handler执行结束后执行权会交回事件循环。但是,在handler执行时可能请求新的异步操作,从而新的操作被添加到事件多路复用器。- 当事件循环队列的全部事件被处理完后,循环会在事件多路复用器再次阻塞直到有一个新的事件可处理触发下一次循环。
我们现在可以定义Node.js的核心模式:
模式(反应器)阻塞处理I/O到在一组观察的资源有新的事件可处理,然后以分派每个事件对应handler的方式反应。
OS的非阻塞I/O引擎
每个操作系统对于事件多路复用器有其自身的接口,Linux是epoll,Mac OSX是kqueue,Windows的IOCP API。除外,即使在相同的操作系统中,每个I/O操作对于不同的资源表现不一样。例如,在Unix下,普通文件系统不支持非阻塞操作,所以,为了模拟非阻塞行为,需要使用在事件循环外用一个独立的线程。所有这些平台内和跨平台的不一致性需要在事件多路复用器的上层做抽象。这就是为什么Node.js为了兼容所有主流平台而
编写C语言库libuv,目的就是为了使得Node.js兼容所有主流平台和规范化不同类型资源的非阻塞行为。libuv今天作为Node.js的I/O引擎的底层。
