

如何构建高并发的网站
- 昨天的微博服务器又炸了,心疼微博三秒钟 。虽然网上各种嘲讽谩骂渣浪的,不过作为程序员细细想想感觉新浪还是很不容易的,毕竟它也没法知道哪个明星突然就出啥事了,面对突如其来的多出好几倍的访问量感觉无论是哪家公司也是没法马上应对的吧。
- 通过这件事,也让笔者认识到了构建一个在高并发环境下依旧高可用的系统是多么的重要,恰好最近一直在看这方面的东西,所以就蹭蹭热度和大家一起分享下。
初级阶段的架构
最简单的架构莫过于就只有一台服务器,无论是web程序,数据库还是文件都放在一起,就像下面的结构一样:
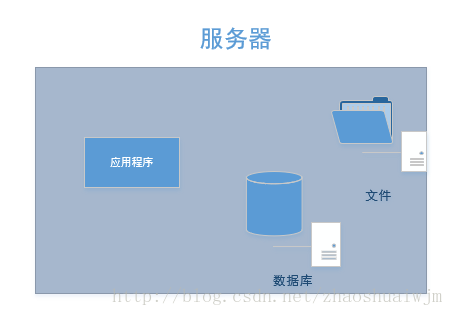
这里写图片描述 笔者在大二的时候做wakeup校园平台的时候就是采用的这种架构,用的阿里云最便宜的10块钱云服务器,20G存储+1G内存+1M的带宽。因为用的人比较少,总的注册用户也就几百人,每天签签到,发发分享基本也不会出什么问题。
但是随着网站用户的逐渐增加,用户量肯定也会越来越多,这时候如果把压力都交给同一台服务器,那也太残忍了,这时候就需要将压力分散开来。也就形成了下面这种架构:
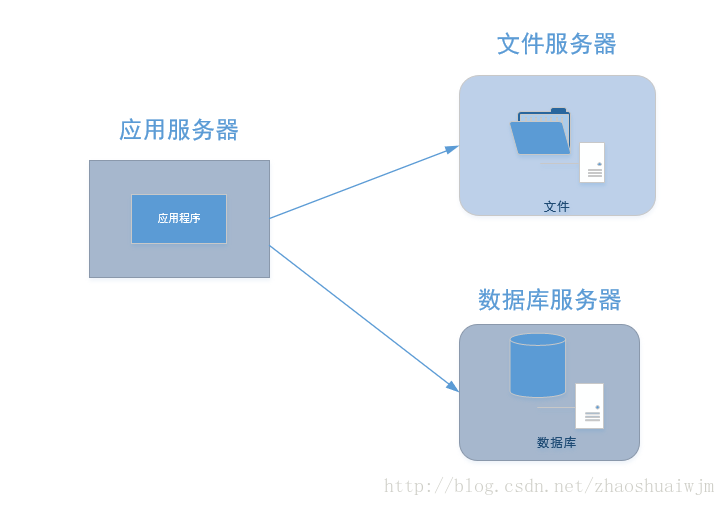
这里写图片描述 应用程序,文件服务器,数据库服务器分别部署到不同的服务器上,应用服务器与文件服务器,数据库服务器之间通过网络传输进行通信。
渐渐的,随着时间的推移,数据库里面的数据越来越多,导致的直接结果就是查询数据会变得越来越慢,因为每次查询数据我们都是直接从磁盘中读取的,众所周知,磁盘的访问速度是很慢的,所以这个时候我们就需要用到缓存了。(划重点,网站优化的第一定律:优先使用缓存提升网站的性能)。所以我们就需用使用缓存服务器了:
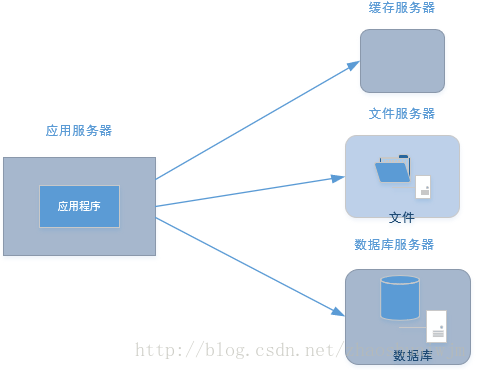
这里写图片描述 在这里,应用服务器优先先向缓存服务器请求数据,如果没有获取到再请求数据库。由于互联网访问的数据基本是遵守二八定律的(即:80%的请求中访问的往往是20%的热门数据,就像微博中最多人看的往往都是一些大V的微博,像我们这些小菜鸟发的微博基本都没人看>_<)。
虽然使用缓存可以极大提升网站的性能,不过也会带来一些问题的,例如加入数据库中的数据已经更新了,但是缓存中的数据还是之前的旧的那么用户不就会获取到不正确的数据了吗?对于这个问题,一般有这么两种解决方案:
- 对于缓存中的数据设定一个过期时间,数据过期之后就要从数据库中拉取最新数据,如果对数据一致性要求不是特别高的场景可以采用这种方案。
- 当数据库中的数据更新之后,刷新缓存中的数据。对于一致性要求高的场景可以采用这种方案。
中级阶段的架构
如果小伙伴们的网站通过以上的架构还是顶不住了,说明这时候小伙伴网站的用户已经比较可观了,这时候就要考虑应付以下两个问题了:
- 用户高并发的访问了。我们知道,现代的web服务器很多都是通过多线程的技术实现的高并发,然而一个进程能够创建的线程是有限的,所以如果突然很多用户同时访问,我们的应用服务器就顶不住了。
- 由于高并发的问题,数据库的读写压力特别大,这时候我们就要考虑能否将数据库的读写分离,让读写操作分别在不同的服务器上。
我们首先来解决问题1,如何应对高并发的问题,这里我们就可以通过反向代理的技术,将用户的请求通过反向代理服务器分散不同的服务器中,让每台服务器的负载得到均衡,从而达到高并发的目的。那么问题来了,什么是反向代理呢?这里我们举两个栗子来形容下:

这里写图片描述 要想搞明白什么是反向代理,首先我们必须清楚的是什么叫做正向代理,也就是普通的代理模式,这里我们通过一个场景切入:
假如小明这时候正在创业,需要300万的创业资金,于是想去找马云爸爸帮帮忙。可是马云爸爸日理万机哪有空见你呀,于是就失败了。恰好这时候你无意中知道了自己的好哥们其实是马云爸爸失散多年的儿子,于是就通过他去向马云爸爸请求投资的事,然后就成功得到了300万。但其实马云爸爸并不知道这钱是投资给你的,这里你的好哥们就是代理,通过他你达到了目的。
在现实中,正向代理的栗子是很常见的,最常见的莫过于我们通过VPN进行科学上网了,我们就是通过一台可以访问到外网的服务器让它帮我们请求资源然后再将获得的资源返回给我们。
既然了解了什么是正向代理,我们也就很好解释什么是反向代理了,还是举一个栗子吧:
假如有一天你在二手东买到假货了,这时候你想打电话去投诉。京东的客服是有很多的,但是京东的投诉电话却只有一个,当我们打通这个电话之后。京东的系统会根据当前哪位客服是空闲的把你的电话转接到空闲的客服那去。这里的转接系统就是一个反向代理,因为它是帮服务器做代理的而不是帮客户端做代理的。
所以正向代理和反向代理最大的区别就是:正向代理是服务于客户端的,它使服务端不知道到底是谁才是真正的请求者。反向代理是服务于服务器端的,它使客户端不知道到底哪台服务器真正处理了自己的请求。
解决了第一个问题,我们再来看看第二个问题,第二个问题就很好解决了。要做到数据库的读写分离,对于用户的每次更新操作都将数据写到
写数据库中去,对于所有的读操作都直接去读数据库中去,所以这里可以有很多的读数据库。(但也不能太多,否则些数据库的同步压力会比较大。)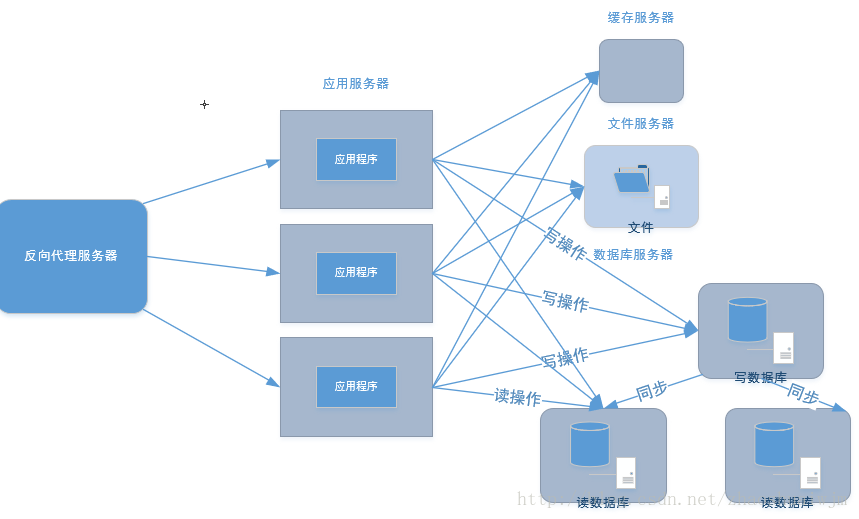
这里写图片描述 大体的实现架构如上:主要通过读写分离与反向代理提高了网站的并发能力。笔者暑假去实习的那家公司基本就是用的上面这种架构,通过nignx做反向代理实现负载均衡,并对mysql数据库进行读写分离。
除此之外,我们还可以使用cdn加速网站的响应速度。这里的cdn其实原理就是一种缓存技术,使得用户在请求网站的时候可以从距离自己最近的网络提供商机房获取数据。
高级阶段的架构
如果小伙伴们的网站即使通过以上架构还是顶不住的话,那么用户量肯定已经达到一个比较可怕的数字了。这个时候就需要进行更深层次的改造了。不过笔者到目前刚刚大四,还没有接触过这么牛逼的系统。只能根据所学习到的分享一下了。
到这个阶段,由于数据量太过庞大,传统的单机式服务器已经不能满足需求了,这时候我们就需要用到分布式数据库(笔者接触过的是hbase)与分布式文件系统(例如hadoop的hdfs以及fastDfs)了。他们基本都是主从协调,网络通信以及数据冗余的方式达到数据分布式存放的目的的,从外界看来其和普通的数据库/文件系统并没有什么区别。有兴趣的小伙伴可以去深入了解下(这个图就比较复杂了,就盗用网上的图了)。
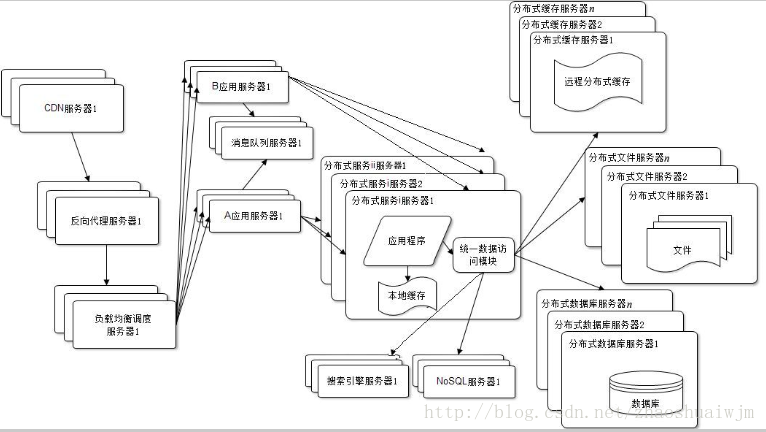
这里写图片描述 除了使用分布式系统之外,由于大型网站的业务逻辑一般比较复杂,所以常常需要进行业务划分,不同的部门负责不同的模块,但是不同的模块之间又会有很多公有的服务,例如百度的所有产品都可以通过百度账号进行登陆,所以这里的登陆模块就可以做成一个公共的服务供不同的业务模块调用。
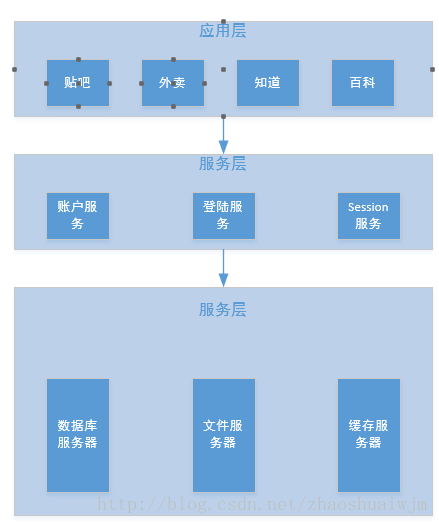
这里写图片描述
就像上图一样不同的业务有自己独立的业务系统,对于公有的服务可以进行复用。对于每一个服务又都可以单独通过负载均衡以及分布式集群实现高可用。
总结
无论多么庞大的系统都是一点一点不断的改进优化而来的,在当系统性能达到瓶颈的时候,我们首先想到的绝对不应该是增加服务器的性能,而是如何通过增加服务器的数量从而降低服务器的平均负载(昨天微博不就紧急购买了1000台服务器降低压力嘛)。同时为了数据的安全,我们也不得不对数据进行冗余备份防止意外事件的发生。笔者能力有限,讲到的也只是网站架构的冰山一角,其实内部还有很多细节的问题,例如如何发布共有的服务,客户端如何调用到发布的服务等待很多问题。如果发现文章有任何问题,欢迎私信或者留言交流,也可以关注笔者的微信公众号,一起学习交流一起进步。

img
