

一,前言
深入学习golang,必须要了解内存这块,这次会仔细讲解下内存这块,包括内存分配,内存模型,逃逸分析。让我们在编程中能注意下这块。
二,内存分配
(1) 这里先了解四个相关数据结构
1,mspan
通过next和prev,组成一个双向链表,mspan负责管理从startAddr开始的N个page的地址空间。是基本的内存分配单位。是一个管理内存的基本单位。
//保留重要成员变量
type mspan struct {
next *mspan // 链表中下个span
prev *mspan // 链表中上个span startAddr uintptr // 该mspan的起始地址
freeindex uintptr // 表示分配到第几个块
npages uintptr // 一个span中含有几页
sweepgen uint32 // GC相关
incache bool // 是否被mcache占用
spanclass spanClass // 0 ~ _NumSizeClasses之间的一个值,比如,为3,那么这个mspan被分割成32byte的块
}
2,mcache
在go中,每个P都会被分配一个mcache,是私有的,从这里分配内存不需要加锁
type mcache struct {
tiny uintptr // 小对象分配器
tinyoffset uintptr // 小对象分配偏移
local_tinyallocs uintptr // number of tiny allocs not counted in other stats
alloc [numSpanClasses]*mspan // 存储不同级别的mspan
}
3,mcentral
当mcache不够时候,会向mcentral申请内存。该结构实际上是在mheap中的,所以在我看来,这起到桥梁的作用。
type mcentral struct {
lock mutex // 多个P会访问,需要加锁
spanclass spanClass // 对应了mspan中的spanclass
nonempty mSpanList // 该mcentral可用的mspan列表
empty mSpanList // 该mcentral中已经被使用的mspan列表
}
4,mheap
mheap是真实拥有虚拟地址的,当mcentral不够时候,会向mheap申请。
type mheap struct {
lock mutex // 是公有的,需要加锁
free [_MaxMHeapList]mSpanList // 未分配的spanlist,比如free[3]是由包含3个 page 的 mspan 组成的链表
freelarge mTreap // mspan组成的链表,每个mspan的 page 个数大于_MaxMHeapList
busy [_MaxMHeapList]mSpanList // busy lists of large spans of given length
busylarge mSpanList // busy lists of large spans length >= _MaxMHeapList
allspans []*mspan // 所有申请过的 mspan 都会记录在 allspans
spans []*mspan // 记录 arena 区域页号(page number)和 mspan 的映射关系
arena_start uintptr // arena是Golang中用于分配内存的连续虚拟地址区域,这是该区域开始的指针
arena_used uintptr // 已经使用的内存的指针
arena_alloc uintptr
arena_end uintptr
central [numSpanClasses]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte //避免伪共享(false sharing)问题
}
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // mcache分配器
}
接下来请细看下图,结合前面的讲解进行理解(务必看懂)。
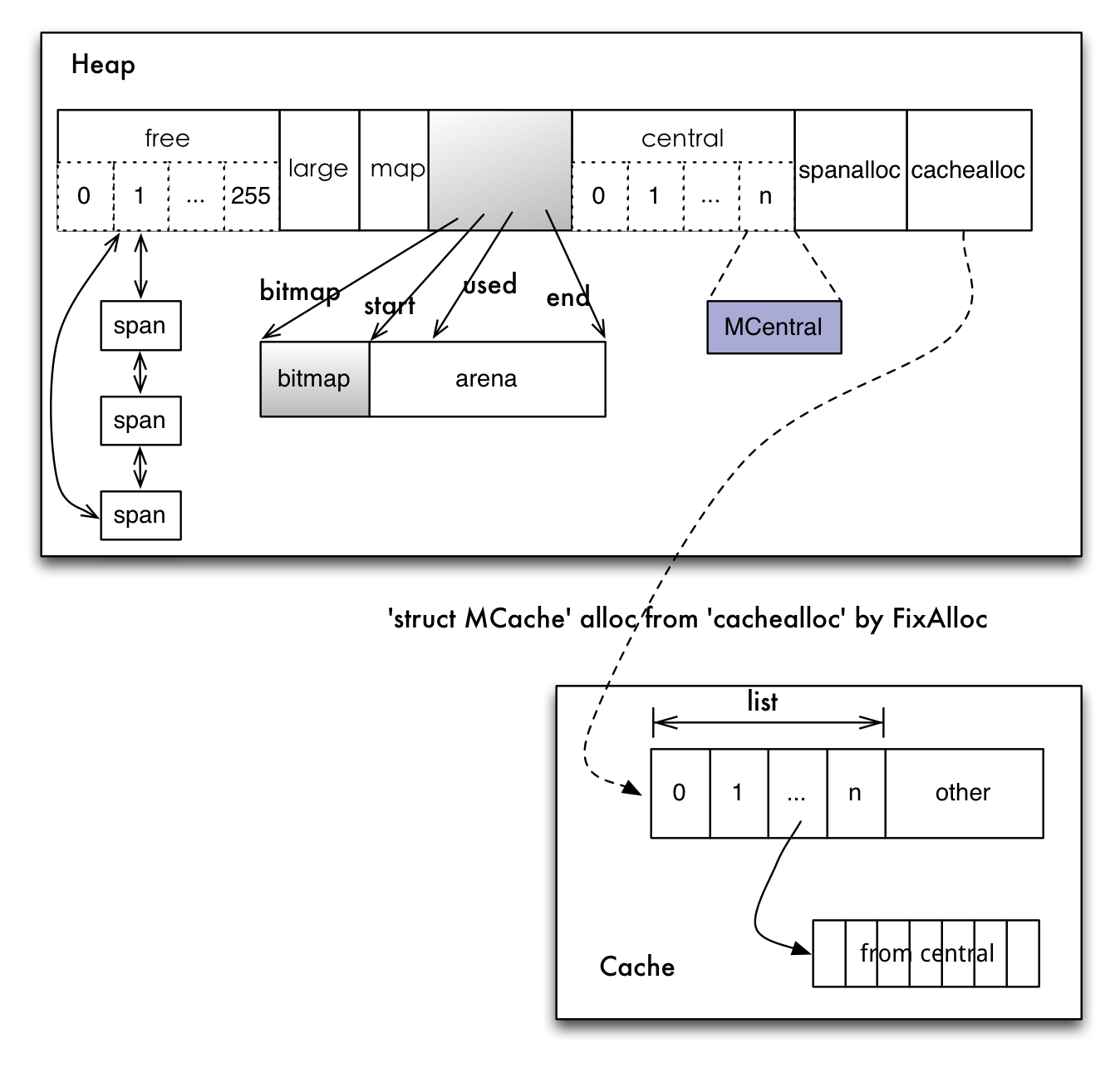
(2) 内存分配细节
这里不展开源代码,知道分配规则即可。(在golang1.10,MacOs 10.12中,下面的32K改为64K)
1, object size > 32K;则使用 mheap 直接分配。
2,object size < 16 byte;则使用 mcache 的小对象分配器 tiny 直接分配。
3,object size > 16 byte && size <= 32K byte时,先在mcache申请分配。如果 mcache对应的已经没有可用的块,则向mcentral请求,如果mcentral也没有可用的块,则向mheap申请,如果 mheap 也没有合适的span,则向操作系统申请。
三,内存模型
这里说下在golang中的happen-before(假设A和B表示一个多线程的程序执行的两个操作。如果A happens-before B,那么A操作对内存的影响将对执行B的线程(且执行B之前)可见)
(1) Init 函数
1, P1中导入了包P2,则P2中的init函数Happens BeforeP1中所有的操作
2, 所有的init函数Happens Before Main函数
(2) Channel
1, 对一个元素的send操作Happens Before对应的receive操作
2, 对channel的close操作Happens Before receive端的收到关闭通知操作
3, 对于无缓存的Channel,对一个元素的receive 操作Happens Before对应的send完成操作
4, 对于带缓存的Channel,假设Channel 的buffer 大小为C,那么对第k个元素的receive操作,Happens Before第k+C个send完成操作。 。
四,逃逸分析
为什么要做逃逸分析呢,因为在栈上分配的代价要远小于在堆上进行分配,这块是目前很多人缺乏的一个思维,包括我。最近看了一些这方面的文章,再回去看自己的代码,发现很多不合理的地方,希望通过这次讲解,能一起进步。
(1) 什么是内存逃逸
简单来说就是原本应在栈上分配内存的对象,逃逸到了堆上进行分配。如果能在栈上进行分配,那么只需要两个指令,入栈和出栈,GC压力也小了。所以相比之下,在栈上分配代价会小很多。
(2) 引起逃逸的情况
个人总结了一下,如果无法在编译期确定变量的作用域和占用内存大小,则会逃逸到堆上。
1,指针
我们平时会知道,传递指针可以减少底层值的拷贝,可以提高效率,在一般情况下是如此,但是如果拷贝的是少量的数据,那么传递指针效率不一定会高于值拷贝。
(1) 指针是间接访址,所指向的地址大多保存在堆上,因此考虑到GC,指针不一定是高效的。看个例子
type test struct{}
func main() {
t1 := test1()
t2 := test2()
println("t1", &t1, "t2", &t2)
}
func test1() test {
t1 := test{}
println("t1", &t1)
return t1
}
func test2() *test {
t2 := test{}
println("t2", &t2)
return &t2
}
运行查看逃逸情况(禁止内联)
go run -gcflags '-m -l' main.go
# command-line-arguments
./main.go:36:16: test1 &t1 does not escape
./main.go:43:9: &t2 escapes to heap
./main.go:41:2: moved to heap: t2
./main.go:42:16: test2 &t2 does not escape
./main.go:31:16: main &t1 does not escape
./main.go:31:27: main &t2 does not escape
t1 0xc420049f50
t2 0x10c1648
t1 0xc420049f70 t2 0xc420049f70
从上面可以看出,返回指针的test2函数中的t2逃逸到堆上,等待它的将是残忍的GC。
2,切片
如果编译期无法确定切片的大小或者切片大小过大,超出栈大小限制,或者在append时候会导致重新分配内存,这时候很可能会分配到堆上。
// 切片超过栈大小
func main(){
s := make([]byte, 1, 64 * 1024)
_ = s
}
// 无法确定切片大小
func main() {
s := make([]byte, 1, rand2.Intn(10))
_ = s
}
看完上述的例子,我们来看个有意思的例子。我们知道,切片比数组高效,但是,确实是如此吗?
func array() [1000]int {
var x [1000]int
for i := 0; i < len(x); i++ {
x[i] = i
}
return x
}
func slice() []int {
x := make([]int, 1000)
for i := 0; i < len(x); i++ {
x[i] = i
}
return x
}
func BenchmarkArray(b *testing.B) {
for i := 0; i < b.N; i++ {
array()
}
}
func BenchmarkSlice(b *testing.B) {
for i := 0; i < b.N; i++ {
slice()
}
}
运行结果如下
go test -bench . -benchmem -gcflags "-N -l -m"
BenchmarkArray-4 30000000 52.8 ns/op 0 B/op 0 allocs/op
BenchmarkSlice-4 20000000 82.4 ns/op 160 B/op 1 allocs/op
可见,我们不一定是一定要用切片代替数组,因为切片底层数组可能会在堆上分配内存,而且小数组在栈上拷贝的消耗也未必比切片大。
3,interface
interface是我们在go中经常会用到的特性,非常好用,但是由于interface类型在编译期间,编译期很难确定其具体类型,因此也导致了逃逸现象。举个最简单的例子
func main() {
s := "abc"
fmt.Println(s)
}
上述代码会产生逃逸,原因是fmt.Println这个方法接收的参数是interface类型。但是这块只是作为科普,毕竟interface带来的好处要大于它这个缺陷
