

前不久,我们使用NLTK的贝叶斯分类模型垃圾对短信数据进行机器学习的垃圾短信识别。
其实除了使用NLTK,我们还可以使用Scikit-Learn这个集成了诸多机器学习算法的模块进行上述的实验。
Scikit-Learn的API设计非常合理和高效,对于初触机器学习的同学来说非常友好,值得大家尝试和使用。本人也经常在实验环境和工作环境中使用scikit-learn进行机器学习的建模。
下面,我们就使用scikit-learn模块,通过其朴素贝叶斯算法API对短信数据进行一次垃圾短信的识别。
导入短信数据
首先,我们需要对原始的短信数据进行处理,导入pandas模块和jieba模块。

pandas模块用于读取和处理数据,jieba模块用于对短信进行分词。
接着,我们导入短信数据:

查看一下部分短信数据:
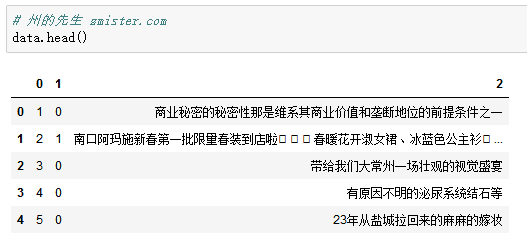
其中第一列为原始序号,第二列为短信的分类,0表示正常短信,1表示垃圾短信,第三列就是短信的正文。
我们只需要关注第二和第三列。
查看一下这个短信数据集的形状:
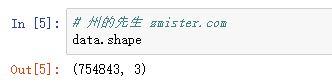
一共有七十余万条短信。
对短信进行分词
文本的分类,基本上是基于词袋模型,也就是一个文本中包含多少词以及各个词的频率。对于英文而已,其天生的句子空格可以很容易的分割单词出来,但是中文就得先进行分词处理,也就是将一个完整的中文分割为一个一个词。
在Python中,有第三方模块——jieba,结巴分词来提供对中文的分词。
我们使用jieba对短信的内容进行分词。
得到的结果如下:
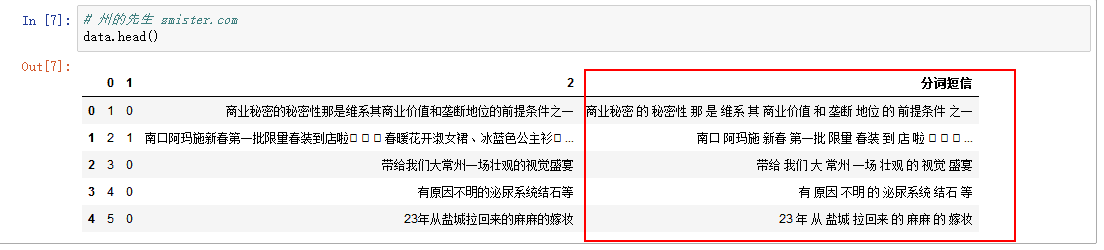
提取特征和目标数据
我们需要分别提取出特征数据和目标数据,特征数据表示输入的数据,目标数据则是输入数据的属性,在这里,短信内容就是特征数据,短信的分类就是目标数据。

X中都是特征数据,y中都是目标数据,便于下一步的分割训练集和测试集。
分割训练集和测试集
使用sklearn的分割模块对训练集和测试集进行分割:

提取文本特征
从文本中提取特征,需要利用到scikit-learn中的CountVectorizer()方法和TfidfTransformer()方法。
CountVectorizer()用于将文本从标量转换为向量,TfidfTransformer()则将向量文本转换为tf-idf矩阵。
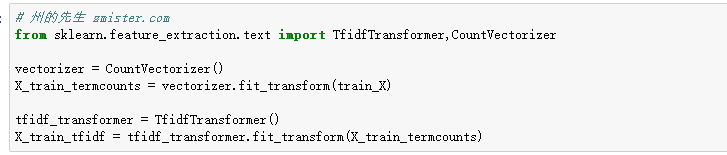
建立朴素贝叶斯分类器并进行训练
朴素贝叶斯是一个很经典同时准确率也很高的机器学习算法,用它来做分类器可以得到很好的效果。

在scikit-learn中,每一个模型都会有一个fit()方法用来模型训练,有一个predict()方法用来模型预测,在此我们就传入了训练特征和训练目标进行了模型的训练。
模型测试
模型训练好之后,我们可以使用模型的predict()方法来测试与预测数据。
在这之前,我们还得进行另外一步。
因为之前对文本提取特征只是针对于训练集,测试集并没有进行,所以我先对测试集进行文本特征提取:

再使用predict()方法进行预测:

变量predicted_categories中包含的就是所有的预测结果。
模型评估
scikit-learn模块中内置了很多模型评估的方法,对于分类问题,我们可以使用accuracy_score()方法,其返回一个数值,得分最高为1。
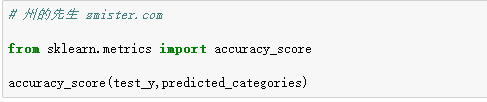
打印出来的结果显示:
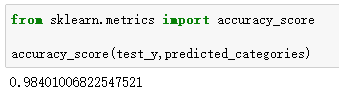
这个分类器的准确率达到了0.98,比上一次使用NLTK的贝叶斯算法高出了10%,很不错。
可以打印部分测试的短信数据以及预测的结果来看:


基本上正常短信和垃圾短信都被正确识别出来了。
文章首发:zmister.com/archives/17…
Python爬虫、数据分析、机器学习、渗透测试、Web开发、GUI开发
州的先生:zmister.com/
